模型訓練越多反而越差?多團隊聯合揭示「災難性過度訓練」現象,模型擴展需被重新審視
模型訓練,並非越多越好?近日,來自美國卡內基梅隆大學、史丹福大學、哈佛大學和普林斯頓大學的研究人員發現一種名為「災難性過度訓練」現象。
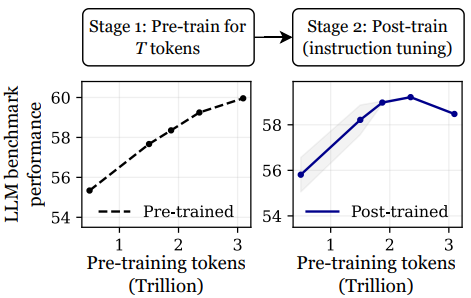
他們發現在多個標準大語言模型基準測試中,OLMo-1B 模型在 3T tokens 上進行預訓練後的性能水平,不如在 2.3T tokens 上進行預訓練後的性能水平,甚至下降到了僅用 1.5T tokens 預訓練後的性能水平。
結合實驗結果和理論分析研究團隊證明:之所以出現災難性過度訓練的現象,是因為預訓練參數對於各種修改的廣義敏感度出現了系統性增加。
(來源:arXiv)
大語言模型的預訓練基於不斷增長的 token 規模,其核心假設是——預訓練階段的性能提升,將會直接轉化為下遊模型的效果改進。
而本次研究團隊不僅挑戰了這一假設,並證明長時間的預訓練會使模型更加難以進行微調,進而會導致模型最終性能的下降。
這說明:人們有必要針對預訓練設計方案進行批判性重估,以便將模型的下遊適應能力納入核心考量。

核心發現:訓練數據並非越多越好
此前,在「數據越多越好」的準則下,大模型廠商在擴展預訓練和後訓練方面投入了大量資金。
2022 年,曾有研究人員指出:每個模型參數大約分配 20 個 token 是最優比例。但是,當前模型的訓練規模已經遠遠超過這一標準。
例如,Llama-2-7B 的訓練使用 1.8T 的 tokens,這是上述推薦比例的 13 倍之多。而 Llama-3-8B 則在此基礎上進一步擴大到 15T tokens。
這一趨勢是由零樣本性能的持續提升所推動的。然而,除了少數情況之外,事實上擴大規模並沒有起到作用。
本次研究表明,當前廣泛採用的語言模型預訓練規模擴展策略,無法百分百地確保在後訓練階段提升模型性能。
 (來源:arXiv)
(來源:arXiv)研究人員指出,災難性過度訓練並非一種孤立存在的現象。相反,大量的實證評估表明,這一現像在現有模型中普遍存在。
 (來源:arXiv)
(來源:arXiv)為了理解災難性過度訓練現象為何會發生,研究團隊設計了一些精心控制的實驗。
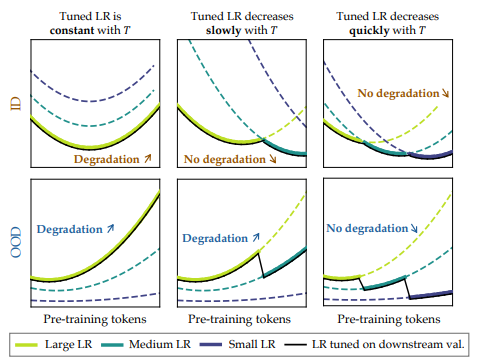
其發現,在修改預訓練模型的參數之後,會導致先前習得的能力被遺忘,這種遺忘程度取決於參數修改幅度的大小。
然而,影響遺忘的另一個關鍵因素則是漸進敏感性:即對於同等幅度的修改,經過更長時間預訓練的模型表現出更大的遺忘幅度。
 (來源:arXiv)
(來源:arXiv)當訓練後修改所導致的總遺忘數量,超過訓練前取得的總進步數量時,就會出現災難性過度訓練。
儘管針對訓練後參數修改的幅度加以限制,可以在一定程度上緩解這種退化,但是這也會導致預訓練模型的適應能力和學習能力遭到限制。
 (來源:arXiv)
(來源:arXiv)同時,研究團隊針對線性遷移學習設置進行了理論分析,以便精確地描述災難性過度訓練和漸進敏感性的特徵。
通過研究增量式特徵學習到底是如何引發漸進敏感性的,以及研究為何無法避免災難性過度訓練現象的背後原因,研究人員發現:微調過程中的正則化可以延遲模型的啟動時間,但是會以犧牲下遊性能為代價。
總體而言,本次發現挑戰了「擴大預訓練數據規模是絕對有益的」的這一普遍性假設。
首先,研究團隊證明在現有語言模型和任務中普遍存在災難性過度訓練,這表明較長的預訓練會在指令調優和多模態微調之後降低模型的性能。
其次,研究團隊發現漸進敏感性是導致災難性過度訓練的關鍵機制,其中長時間的預訓練會增加模型參數對於後續更新的脆弱性。
再次,研究團隊在線性遷移學習框架下,針對災難性過度訓練進行了形式化表徵,借此證明增量式特徵學習會引發漸進敏感性,最終會導致模型性能的必然性退化。

長時間預訓練或給後續訓練造成負面影響
研究中,為了分析過度訓練所帶來的影響,研究團隊針對三個具有開源中間檢查點的語言模型開展實驗,這三個語言模型分別是:OLMo-1B、OLMo-2-7B 和 LLM360-Amber-7B。
對於每個模型,他們都會在中間檢查點上進行訓練後處理。同時,他們使用 Anthropic-HH 和 TULU 這兩個數據集來進行指令調優,並使用 LLaVA 視覺指令調優框架進行多模態微調,然後在每個數據集上訓練每個中間檢查點。
研究團隊從以下兩個關鍵維度評估模型性能:一是評估域內性能(ID,In-Distribution Performance),即基於一些微調任務進行評估;二是評估域外性能(ODD,Out-of-Distribution Performance),即基於一套包含推理、問答、常識和知識提取等十個常見大語言模型評估基準進行計算。
對於每個檢查點研究團隊都會調整學習率,並選擇域內性能最佳的模型。需要說明的是,學習率指的是控制模型參數更新步長的超參數。
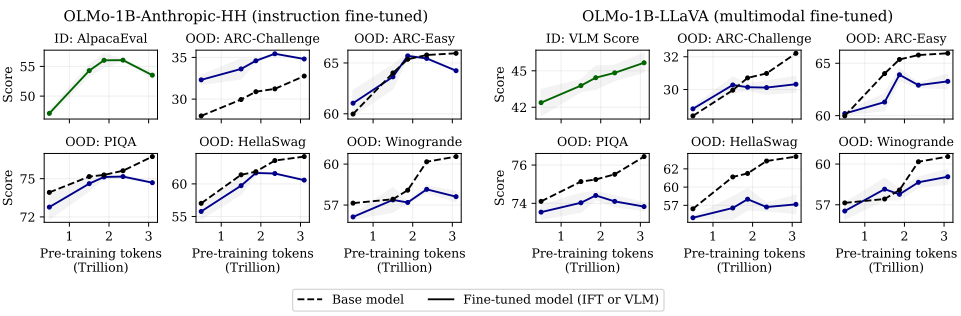
隨後,在不同的預訓練預算之下,他們比較了所訓練的 OLMo-1B 模型的性能。
借此發現:當延長預訓練時間的時候,確實會讓基礎模型性能得到持續提高。比如,在其所評估的所有下遊任務中,模型性能均能得到持續性提升。
而過長的預訓練,反而會損害模型在後續訓練階段的性能表現。
具體來說,在 Anthropic-HH 數據集上進行指令跟隨微調後,與僅預訓練 2.3T tokens 的模型相比,預訓練 3T tokens 的基礎模型的響應率降低了 3%。
在諸如 ARC-Easy、ARC-Challenge、HellaSwag 和 PIQA 等基準測試上評估時,研究團隊發現在推理和問答等各種開放域對話任務上,模型性能也出現了類似的下降。
而對於多模態微調,其發現通過延長預訓練時間,能夠持續提高視覺語言模型性能分數。
然而,那些在更多 tokens 上進行預訓練的模型,在各種域外性能基準測試中,表現出更大的遺忘幅度和性能下降。
在 PIQA 等數據集上,模型性能會出現嚴重下降,以至於在延長預訓練時間之後,反而會損害後訓練之後的模型性能。
這說明,雖然延長預訓練時間確實能夠提高預訓練性能,但是這些提升並不都能轉化為後訓練性能的提升。

何時以及為何發生災難性過度訓練?
為了釐清為何在更多 tokens 上進行預訓練、為何消耗了更多計算資源反而會降低性能的這一問題,以及這種情況到底何時會發生,研究團隊深入探討了這一現象。
研究團隊將性能首次開始下降時的 token 訓練量臨界值稱為「拐點」。需要注意的是,在各種下遊評估任務中,即使是同一個模型其性能下降的具體表現也可能有所不同。
當研究團隊針對 OLMo-1B 進行後訓練以便進行指令調優和多模態微調,進而將其放在標準基準上進行評估時,他們觀察到了災難性過度訓練現象。
於是,他們重點探討了以下兩個問題:災難性過度訓練發生於何時以及為何會發生?哪些因素會影響「拐點」的出現?
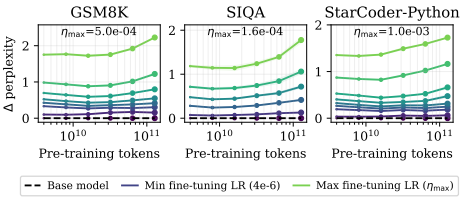
研究中,他們聚焦於針對不同數據集進行微調來修改預訓練模型,同時還向模型權重添加了獨立高斯噪聲。需要說明的是,高斯噪聲——是一種符合正態分佈的隨機擾動,常用於模型訓練和魯棒性測試之中。
研究中,他們研究了在高斯噪聲擾動之下的過度訓練效應,並構建了一個直觀的理論圖示。隨後,在受控實驗環境中將這一分析拓展至微調場景。
根據實驗結果,其給出這樣的總結:在 Anthropic-HH 和 TULU 等數據集上進行指令調優時,當 tokens 預算超過 2.5T tokens 時,OLMo-1B 模型會出現災難性過度訓練現象,這表現為模型在域內性能任務和域外性能任務上的性能下降。
對於多模態微調,OLMo-1B 模型在超過 2.5T tokens 時也出現了災難性過度訓練。然而,這種退化具有一定的任務依賴性,即儘管在某些泛化任務上模型的性能有所下降,但是在超過一定的 tokens 閾值後,模型的域內性能並未出現退化。
在相同的微調設置和評估設置之下,針對預訓練 tokens 預算高達 3T tokens 的 OLMo-7B 模型,研究團隊並未觀察到災難性過度訓練現象。
基於這些觀察結果,他們探索了以下問題:在預訓練 tokens 預算更大的情況下,OLMo-7B 模型是否會出現災難性過度訓練現象?為什麼在特定數據集上進行微調時某些下遊任務更有可能出現災難性過度訓練現象?一些微調數據集是否更有可能導致災難性過度訓練?
為了回答這些問題,研究團隊使用了單次訓練運行中公開可用的檢查點。由於退火調度策略,每個預訓練預算都對應於不同的最終學習率。(註:退火調度,在物理學中是一種熱處理工藝。但在大模型領域它是一種優化策略,通過逐漸降低某些參數來幫助模型實現更穩定的收斂。)
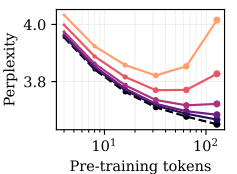
為了消除這一混淆因素,研究團隊在由此前 Google 團隊打造的 C4 數據集上,從零開始針對模型進行預訓練。這些模型的大小從 15M 到 90M 參數不等,覆蓋的 token 預算從 4B 到 128B 不等。
研究團隊採用餘弦退火調度策略進行訓練,從而將每個模型的學習率逐漸退火至零,並基於多個數據集針對模型進行微調,同時在預訓練權重上添加高斯擾動作為預熱。
微調——是針對基於大量數據訓練而來的預訓練模型進行的某種修改,這些修改旨在提升某些特定的性能指標。然而,正如前人論文中所描述的:這類修改可能會無意中扭曲預訓練知識,導致模型的域外性能出現下降。
因此,研究團隊主要測量了修改後的下遊模型的 C4 困惑度,以此作為衡量原始預訓練知識保留程度的指標。困惑度,是衡量語言模型在預測下一個詞時的不確定程度的一個指標。其發現,C4 困惑度的下降可能預示了這種知識的丟失,因此這可能會導致模型域外性能的下降。
與此同時,研究團隊還通過困惑度指標,來評估模型在微調數據同分佈測試集上的性能表現。
借此發現:在擾動量固定的情況之下,基礎模型和擾動模型之間的困惑度變化,會隨著預訓練 tokens 的數量而出現單調遞增。基於此,他們繪製了基礎模型的絕對 C4 困惑度示意圖。
 (來源:arXiv)
(來源:arXiv)其還觀察到,基礎模型的困惑度會隨著預訓練 tokens 數量的增加而降低。
在這一實驗設定下,災難性過度訓練的產生源於兩種效應的相互作用:即「噪聲敏感性的漸進增強」與「基礎模型隨預訓練進程的性能單調遞增」。

警示:模型擴展需要被重新審視
總的來說,本次研究證明隨著預訓練 token 數量的增加,模型對擾動的敏感性會系統性增強,這一規律導致了災難性過度訓練的發生。
當預訓練任務與微調任務存在目標偏差時,這種適應能力的退化會變得尤為嚴重。在此情況下,即便對微調過程施加正則化,災難性過度訓練仍然可能無法避免。
同時,研究團隊證明災難性過度訓練有時只能通過正則化來緩解,但一些其他策略比如數據重播或線性探測微調可能會給保持預訓練性能帶來幫助。
此外,類似於 WiseFT 等方法在也有可能在出現災難性過度訓練情況時發揮作用。
最後,儘管本次工作主要關注在微調和簡單擾動背景之下的災難性過度訓練,但這一現象也適用於語言模型參數受到擾動的其他情況,比如模型編輯或模型遺忘等。
因此,研究人員指出災難性過度訓練對於語言建模的未來發展具有重大影響。
那些為了高效部署模型而減少模型參數的做法,可能會加劇災難性過度訓練的負面影響,因為這會讓模型對於參數變換越來越敏感。
此外,隨著推理時動態推理(inference-time reasoning)技術、驗證方法以及其他新興後訓練範式的面世,會讓推理時間成本不斷上升,也會加劇災難性過度訓練情況的出現。
總之,本次研究表明人們需要重新審視模型擴展,同時也需要認真考慮模型的整個訓練流程。
參考資料:
https://arxiv.org/abs/2503.19206
運營/排版:何晨龍