在GSM8K上比GRPO快8倍!廈大提出CPPO,讓強化學習快如閃電
機器之心報導
編輯:Panda
DeepSeek-R1 的成功離不開一種強化學習算法:GRPO(組相對策略優化)。
不同於 PPO(近端策略優化),GRPO 是直接根據組分數估計基線,因此消除了對 critic 模型的需求。但是,這又需要為每個問題都采樣一組完成結果,進而讓訓練過程的計算成本較高。
之後,GRPO 會使用一個基於規則的獎勵函數來計算每個完成結果的獎勵,並計算每個完成結果的相對優勢。
為了保證訓練的穩定性,GRPO 還會計算一組完成結果的策略模型、參考模型和舊策略模型的預測概率之比作為策略目標函數的一部分,這又會進一步提升強化學習的訓練開銷。GRPO 巨大的訓練開銷限制了其訓練效率和可擴展性。而在實踐中,提高訓練效率是非常重要的。
總結起來,GRPO 訓練的計算成本主要源自其核心設計:為了進行組內比較,會為每個提示詞生成一大組完成結果。此外,GRPO 的前向計算會以完成數量的 3 倍的尺度擴展。
那麼,問題來了:在這個強化學習過程中,每個完成結果的貢獻都一樣嗎?
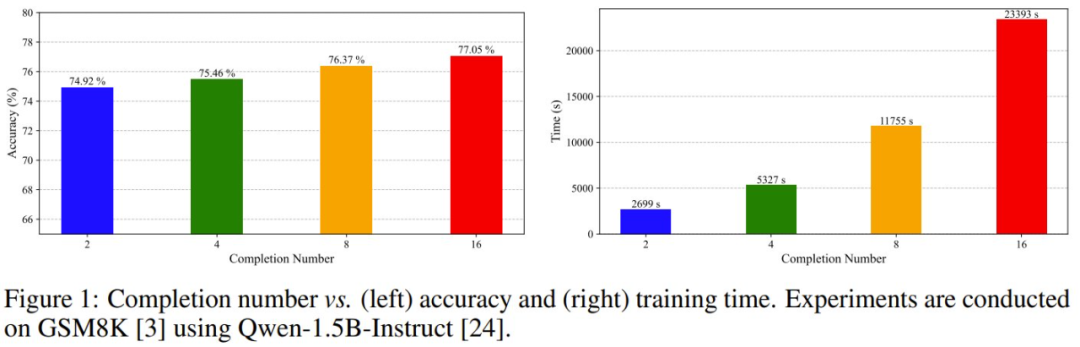
近日,廈門大學紀榮嶸團隊研究發現,每個完成結果的貢獻與其相對優勢有關。也就是說,每個完成結果對策略模型訓練的貢獻並不相等。如圖 1 所示,完成結果的數量增大時,準確度提升並不非常顯著,但訓練時間卻會迅速增長。
基於這一見解,他們發現可以通過對完成結果進行剪枝來加速 GRPO。然後,他們提出了一種加速版的 GRPO:CPPO(Completion Pruning Policy Optimization / 完成剪枝策略優化)。並且他們也已經開源發佈了該算法的代碼。

-
論文標題:CPPO: Accelerating the Training of Group Relative Policy Optimization-Based Reasoning Models
-
論文地址:https://arxiv.org/pdf/2503.22342
-
項目地址:https://github.com/lzhxmu/CPPO
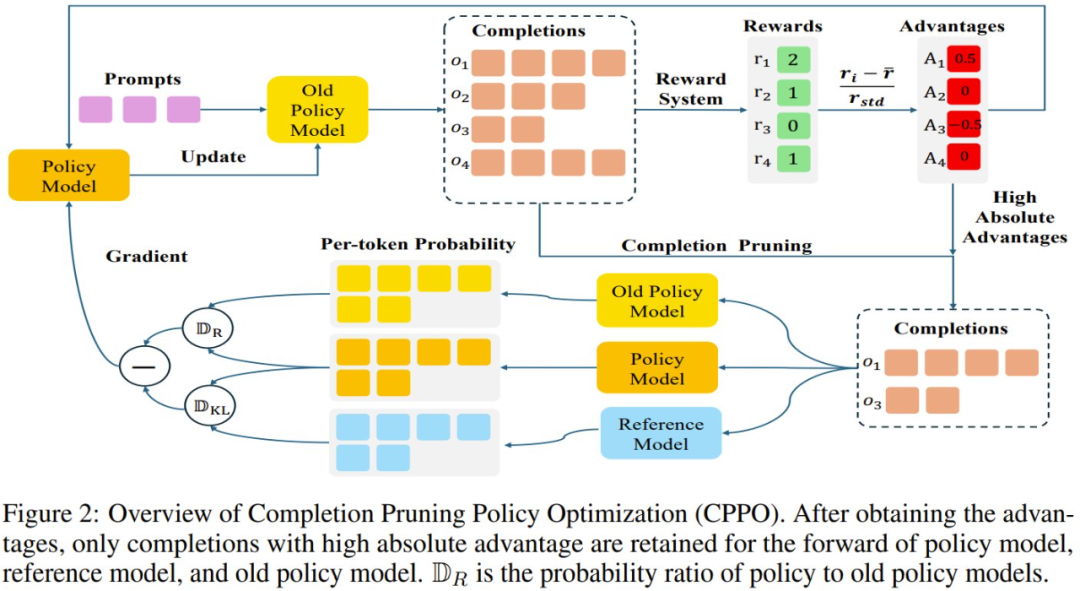
顧名思義,CPPO 會根據優勢對完成結果進行剪枝,這樣一來就可以提升強化學習過程的速度。
具體來說,一開始,策略模型會針對每個問題采樣一組完成結果。隨後,通過獎勵函數計算每個完成結果的相對優勢。然後,CPPO 會修剪掉絕對優勢值較低的完成結果,僅保留絕對優勢較高的完成結果來計算損失。此過程可大大減少訓練所需的完成結果數量,從而加快訓練過程。
此外,他們還觀察到,由於完成剪枝會導致 GPU 資源利用率不足,從而導致資源浪費。為瞭解決這個問題,他們引入了一種動態完成結果分配策略。該策略會用新問題的完成結果填充每個設備,從而充分利用 GPU 資源並進一步提高訓練效率。
實驗證明,他們的方法是有效的。當使用 Qwen-2.5 系列模型時(包括 Qwen-2.5-1.5B-Instruct 和 Qwen-2.5-7B-Instruct),在保證了準確度相當的基礎上,CPPO 在 GSM8K 基準上的速度比 GRPO 快 8.32 倍,在 MATH 基準上快 3.51 倍。
或者用網民的話來說,快如閃電!

CPPO:完成剪枝策略優化
要瞭解 CPPO,首先必須知道 GRPO,其公式如下:
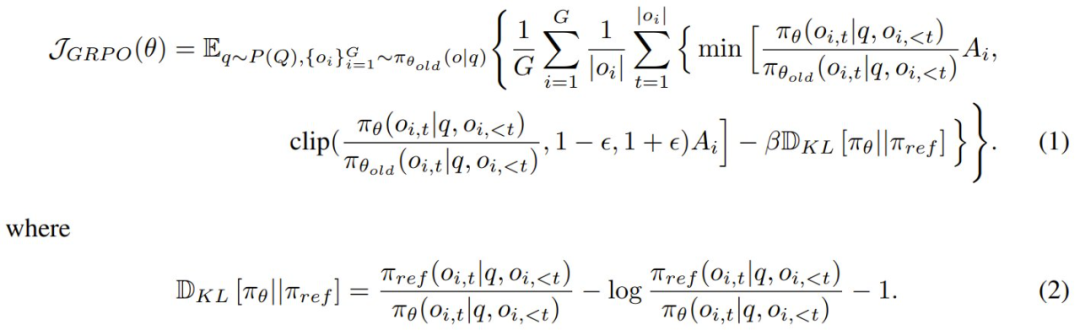
其中,q 是從數據集分佈 P (Q) 中采樣的問題,{o_1, o_2, … , o_G} 是 G 個完成結果,π_θ 是策略模型,π_θ_old 是舊策略模型,π_θ_ref 是參考模型,ϵ 和 β 是超參數,A_i 是使用一組獎勵 {r_1, r_2, … , r_G} 計算的優勢。
相比於 GRPO,CPPO 引入了一個選擇性條件,該條件僅會包括表現出足夠高優勢的完成結果。CPPO 的目標公式如下:
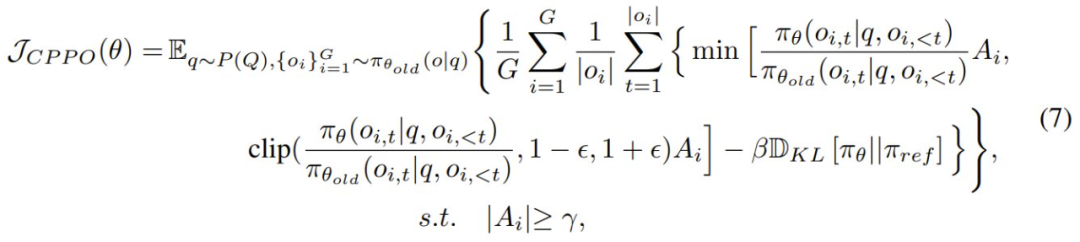
其中 γ 是一個預定義的閾值,用於確保在梯度更新中僅保留絕對優勢高於 γ 的完成結果。需要注意的是,當
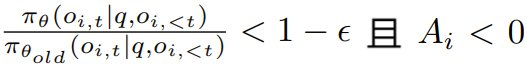
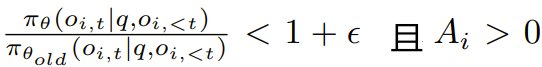
時,clip 函數會被激活。
,或者
圖 2 展示了 CPPO 的概況:
統一單/多 GPU 設置
在多 GPU 訓練場景中,該團隊觀察到具有顯著優勢的完成結果的數量因設備而異。在這種情況下,整體訓練效率會有設備處理最多完成結果數量的瓶頸 —— 這種現象稱為「木桶效應(bucket effect)」。為了緩解這種情況,對於每台 GPU,該團隊的選擇是只保留每個問題具有最大絕對優勢的 k 個完成結果,其中
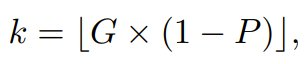
其中 P ∈ (0, 1] 表示剪枝率。在此策略下修改後的 CPPO 為:
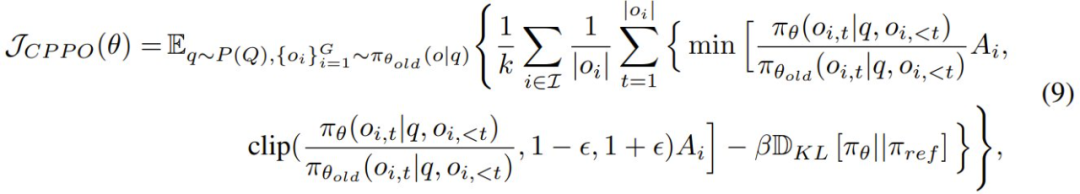
其中僅在具有最高絕對優勢值的 k 個完成結果對應的索引集 I 上進行求和,即
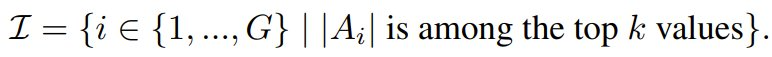
CPPO 算法的流程如下:
舊策略模型為每個問題采樣一組完成結果;
獎勵函數計算每個完成結果的獎勵;
計算每個完成結果的相對優勢;
CPPO 保留 k 個具有最高絕對優勢的完成結果;
根據選定的完成結果更新策略模型。
CPPO 和 GRPO 之間的關鍵區別是:CPPO 不會將所有完成結果用於策略模型、參考模型和舊策略模型的前向計算。相反,通過僅保留具有高絕對優勢的完成結果進行梯度更新,CPPO 可顯著降低前向傳遞期間的計算開銷,從而加速了訓練過程。
通過動態完成結果分配進行並行處理
該團隊還提出了一種新的動態完成結果分配策略,以進一步優化 CPPO 的訓練效率。
由於 GPU 內存限制,傳統方法(如 GRPO 採用的方法)面臨固有的局限性。具體而言,單台設備每批最多可以處理 B 個問題,每個問題生成 G 個候選完成結果。剪枝操作之後,每台設備保留的完成結果總數減少到 B × k,進而導致 GPU 利用率不理想,並行計算能力未得到充分利用。
為瞭解決這種低效率問題,該團隊的方法是將來自其他問題的剪枝後的完成結果動態分配到設備的處理管道中,如圖 3 所示。
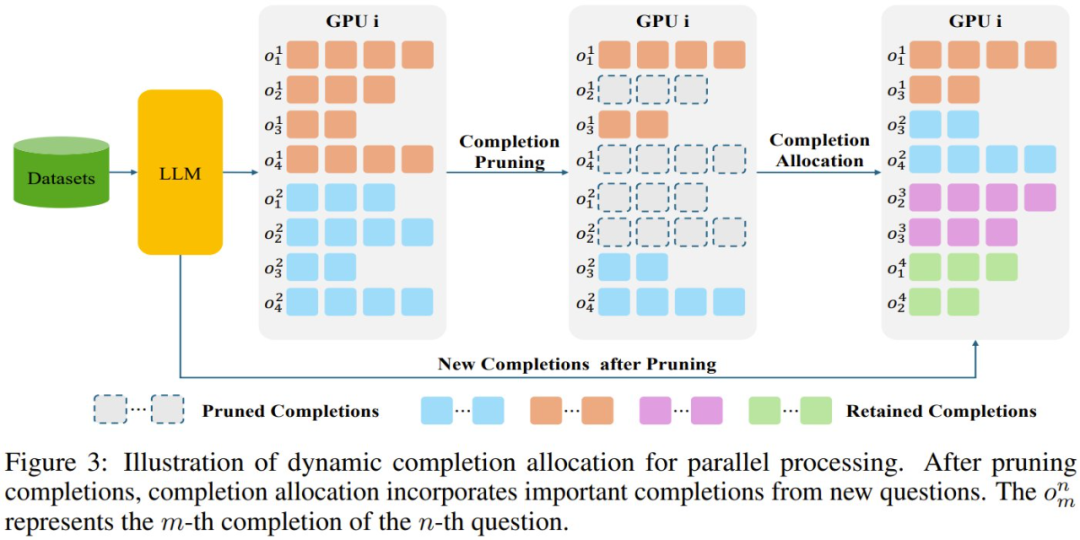
此策略通過不斷用來自原始問題和新引入問題的高質量完成結果填充其內存,確保每個設備都能以滿負荷運行。至關重要的是,所有新合併的完成結果都經過相同的嚴格剪枝過程,以保持一致性和相關性。
這種方法的好處有兩個:
-
通過充分利用設備的並行計算潛力,它能最大化 GPU 利用率。
-
它能使每台設備每批處理更多的問題,從而減少實現收斂所需的總訓練步驟數。
有這兩大優勢,CPPO 便可在保證訓練質量的同時提高訓練效率。
CPPO 的實驗效果
使用 Qwen2.5-1.5B-Instruct 和 Qwen2.5-7B-Instruct 模型,該團隊在 GSM8K 和 MATH 數據集上對 CPPO 進行了實驗評估。此外,為了評估模型的分佈外推理能力,他們還引入了 AMC2023 和 AIME2024 作為測試基準。
在 GSM8K 上的結果如表 1 所示,CPPO 在準確度和加速比上都明顯優於 GRPO。值得注意的是,CPPO 在各種剪枝率下都達到了與 GRPO 相當甚至更高的準確度。在 87.50% 的剪枝率下,CPPO 的準確度達到 80.41%,比 GRPO 的 77.05% 高出 3.36%。
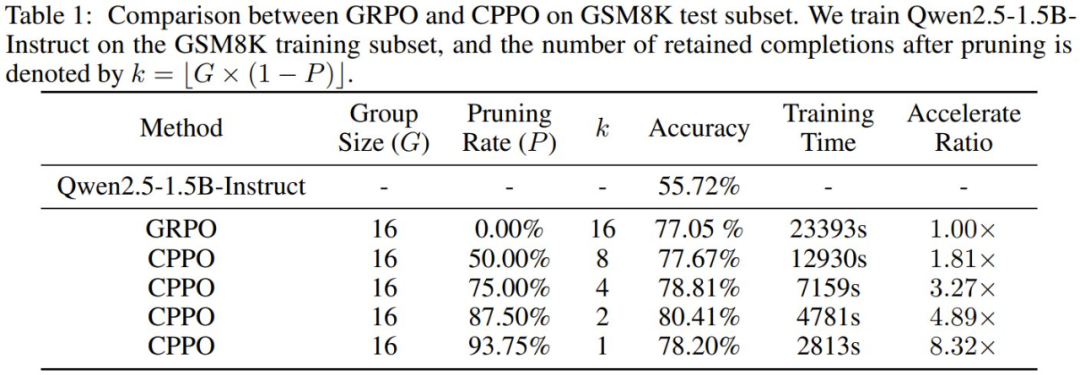
在效率方面,CPPO 大大加快了訓練速度。在 93.75% 的剪枝率下,其加速比達到 8.32倍。這些結果表明,CPPO 不僅能保持或提高準確度,還可顯著提高訓練效率。因此,CPPO 有潛力成為大規模推理模型訓練的實用有效解決方案。
在 MATH 上的表現見表 2。可以看到,CPPO 可以很好地擴展到更大的模型 —— 在不犧牲準確度的情況下在 MATH 上實現了高達 3.51 倍的加速。例如,在 87.5% 的修剪率下,CPPO 保持了與 GRPO (75.20%) 相當的準確度,同時還將訓練時間減少了 3.51 倍。
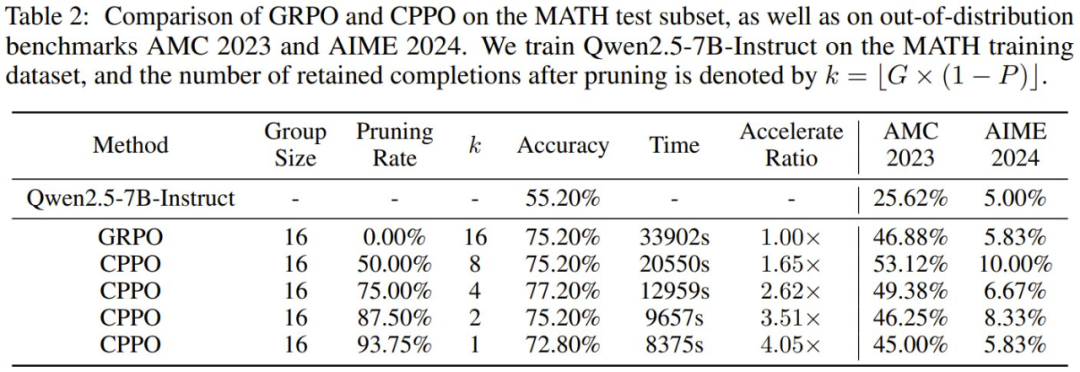
此外,在 AMC2023 和 AIME2024 基準上的評估表明,儘管 CPPO 僅在高絕對優勢完成結果上進行訓練,但它仍保留了模型在分佈外任務上的泛化能力。因此,CPPO 不僅在增強推理能力方面匹敵甚至超越了 GRPO,而且還很好地減少了訓練時間,使其成為一種更有效的替代方案。
該團隊也研究了 CPPO 的穩定性和收斂性。圖 4 展示了在 GSM8K 和 MATH 數據集上訓練時的獎勵曲線。
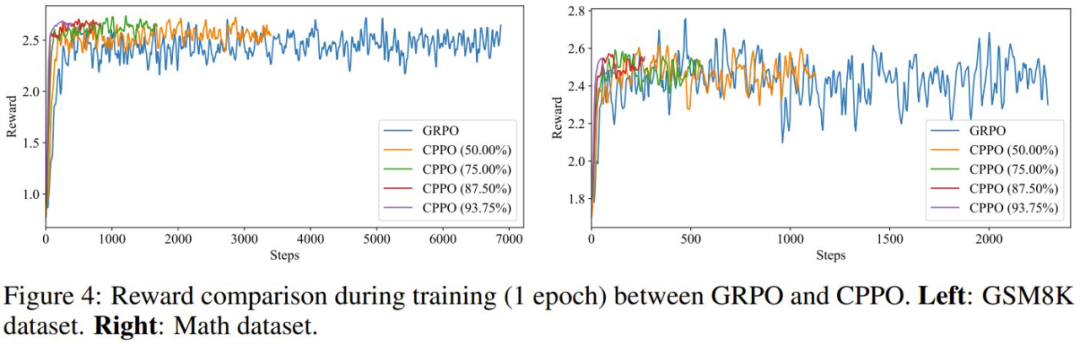
總體而言,獎勵曲線證明 CPPO 在提高收斂速度的同時可保證 GRPO 的訓練穩定性:CPPO 的獎勵曲線不會崩潰或出現劇烈波動,這對於穩定訓練至關重要。這些結果表明 CPPO 具有穩健而穩定的訓練穩定性。此外,CPPO 的獎勵曲線顯示出了明顯的上升趨勢,能比 GRPO 更快地達到更高的獎勵值。獎勵值的更快增長表明 CPPO 的收斂速度更快。
你有興趣在自己的強化學習訓練流程中嘗試這種更快的 CPPO 嗎?