ICLR 2025 Oral | IDEA聯合清華北大提出ChartMoE:探究下遊任務中多樣化對齊MoE的表徵和知識

最近,全球 AI 和機器學習頂會 ICLR 2025 公佈了論文錄取結果:由 IDEA、清華大學、北京大學、香港科技大學(廣州)聯合團隊提出的 ChartMoE 成功入選 Oral (口頭報告) 論文。據瞭解,本屆大會共收到 11672 篇論文,被選中做 Oral Presentation(口頭報告)的比例約為 1.8%

-
論文鏈接:https://arxiv.org/abs/2409.03277
-
代碼鏈接:https://github.com/IDEA-FinAI/ChartMoE
-
模型鏈接:https://huggingface.co/IDEA-FinAI/chartmoe
-
數據鏈接:https://huggingface.co/datasets/Coobiw/ChartMoE-Data
研究動機與主要貢獻:
-
不同於現階段使用 MoE 架構的原始動機,ChartMoE 的目標不是擴展模型的容量,而是探究 MoE 這種 Sparse 結構在下遊任務上的應用,通過對齊任務來增強模型對圖表的理解能力,同時保持在其他通用任務上的性能。
-
不同於之前依賴 ramdom 或 co-upcycle 初始化的方法,ChartMoE 利用多樣的對齊任務進行專家初始化。這種方法加大了專家間的異質性,使 ChartMoE 可以學習到更全面的視覺表徵,展現出顯著的解釋性。

ChartMoE 是一個以 InternLM-XComposer2 模型為訓練起點、引入 MoE Connector 結構的多模態大語言模型,具有先進的圖表理解、圖表重繪、圖表編輯、重要部分高亮、轉換圖表類型等能力。ChartMoE 為圖表(Chart)這種獨特於自然圖像的輸入,設計了多階段的圖文對齊方式,每一個階段產物都是 MoE Connector 中的一個專家,這樣的訓練方式和模型設計不僅能獲得更全面的視覺表徵、顯著提高 MLLM 的圖表理解能力,還可以在不加入通用數據的情景下,減少模型對通用知識的遺忘。
多階段對齊訓練的 MoE
-
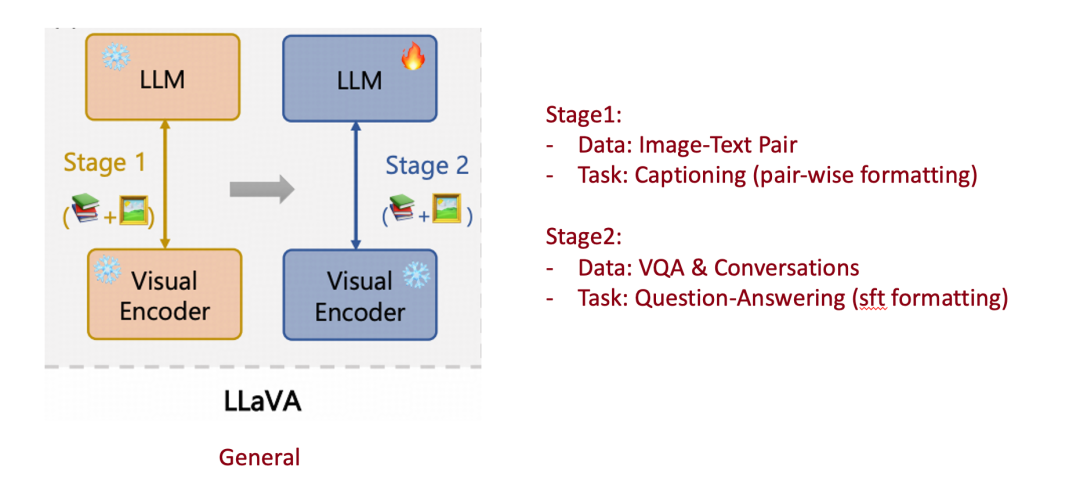
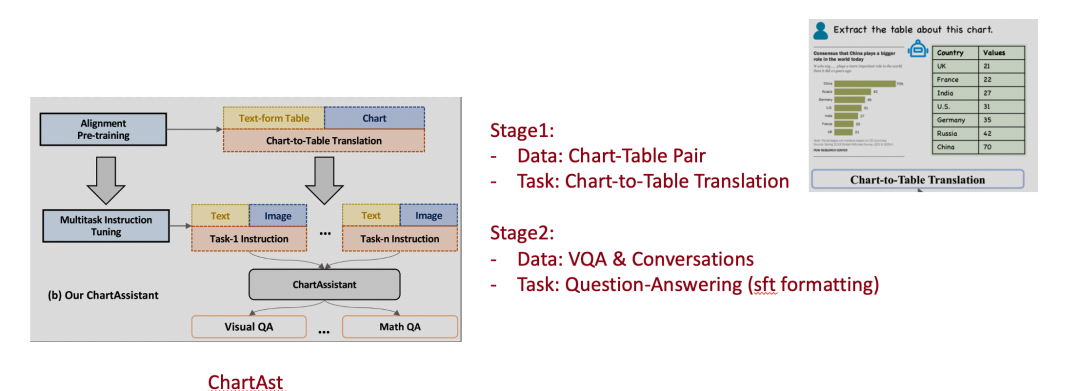
通用 MLLM,如 LLaVA,他們的 training recipe 通常分為兩個階段,第一個階段使用圖文對(image-text pair)訓練 MLP Connector,第二階段 SFT 訓練 MLP Connector + LLM。
-
這種範式可以很自然的遷移到 Chart MLLM 中,如:ACL24 的 ChartAst,使用成對的 Chart-Table 進行第一階段的圖文對齊。
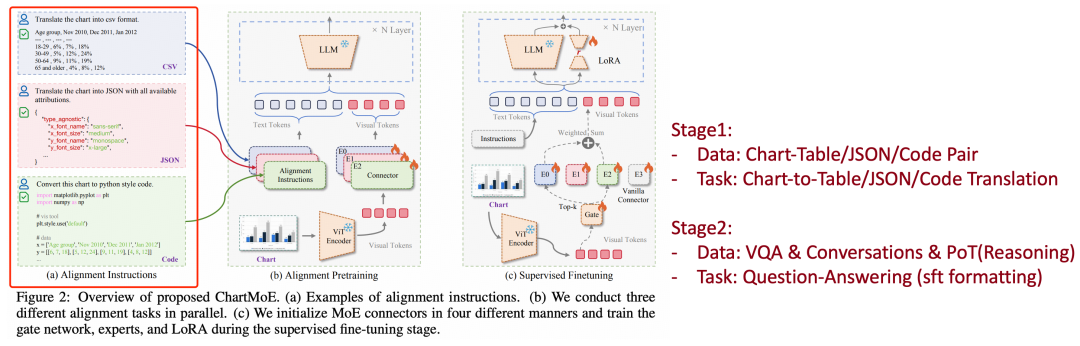
然而,Table 這種結構化文本格式,其中僅包含了每個數據點的數值,以及 xy 軸的含義等信息,幾乎不保留視覺元素信息,如:顏色、圖表類型、圖形元素的相對關係等。所以,ChartMoE 希望採用更多樣、更全面的對齊方式,將 Chart 轉譯成三種結構化文本格式:Table、JSON、Python Code。
我們以開源數據集(ChartQA、PlotQA、ChartY)中的表格數據作為起始點,為每個圖表類型人為定義了 JSON 鍵,通過 random 生成、GPT 生成等方式為每個鍵填上對應的值,從而構建出 JSON 數據。此後可以將 JSON 中的鍵值對填入到每個圖表類型預定義好的代碼模板中得到 Python 代碼來生成圖表,從而構成 (Chart, Table, JSON, Code) 四元組,通過這種方式,採集了約 900k 數據,稱為 ChartMoE-Align。

獲取到數據後,ChartMoE 採用 chart-to-table、chart-to-json、chart-to-code 三種方式進行圖文對齊,每個任務分別訓練一個獨立的 MLP Connector,拚上初始的通用 MLLM 中的 MLP Connector,再加上一個隨機初始化的 learnable router,就可以構成一個亟待吃下 SFT 數據的 MoE Connector,即:Diversely Aligned MoE。
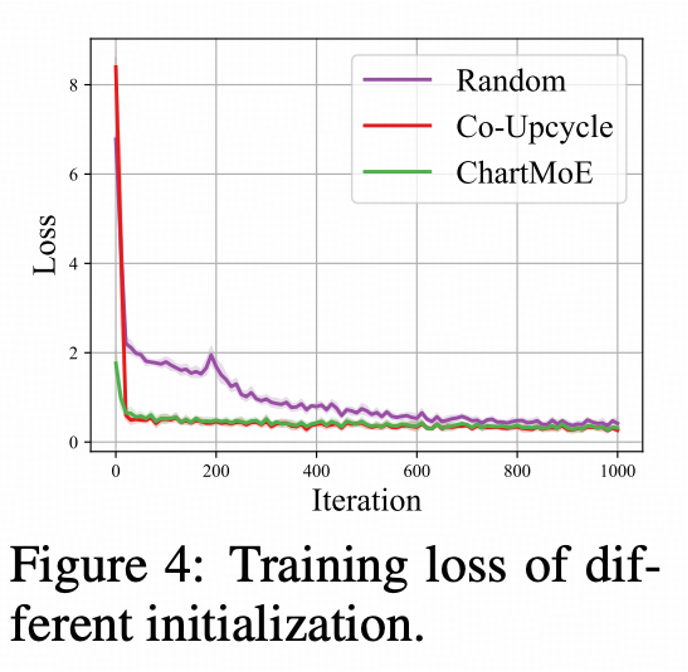
對比 Diversely Aligned MoE 與 Random 初始化、Co-Upcycle 初始化(即把通用 Connector 複製 N 份)的 Training Loss,我們發現,Diversely Aligned MoE 能夠有更低的初始 loss(因為已經更好地學到了對齊到後續 LLM 的 chart 表徵),以及整體更平滑的訓練曲線。
Training Recipes
ChartMoE 訓練分為三個階段:
-
多階段對齊(數據:ChartMoE-Align,Table 500k + JSON 200k + Code 100k),僅訓練 MLP Connector,最後拚成 MoE Connector。
-
廣泛學習高質量知識(使用 MMC-Instruct 數據集,包含很多 Chart 相關的任務,如:Chart Summarization),訓練 MoE Connector(尤其是 Learnable Router,亟待學習)以及 LLM Lora。
-
Chart 領域 SFT(ChartQA + ChartGemma):訓練 MoE Connector 以及 LLM Lora;
-
PoT(Program-of-Thought):即輸出 python 代碼來解決問題,可以讓模型將計算交給代碼,提高解題準確率,如:一個利潤柱狀圖,問最高利潤和最低利潤差多少,就會輸出代碼:
profits = [5, 7, 9, 1, 11, -3]
print (max (profits) – min (profits))
ChartMoE 表徵可視化
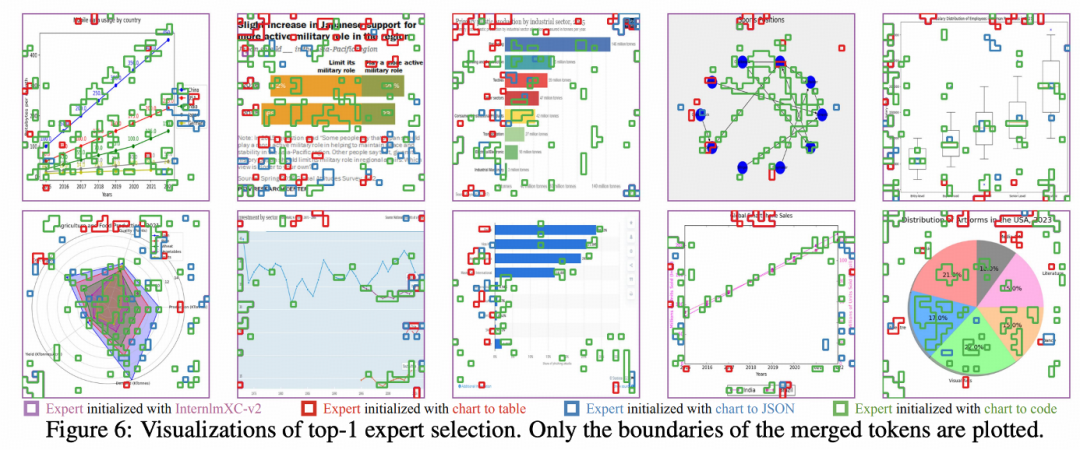
按每個 Visual Patch Token 選擇的專家序號進行可視化,觀察 Visual Patch 的 Top-1 的專家選擇分佈:

-
背景 tokens 傾向於選擇通用通用專家,也說明通用專家選擇佔比非常高。
-
數據點、圖像元素、圖像元素間的 interaction(如第一行第四列的 graph 圖的 edges)非常傾向於選擇 code 專家(儘管 chart-to-code 數據中並沒有包含這種 graph 圖表)。
-
標題、xy 軸標註、xy 軸刻度、圖例等文本信息,傾向於選擇 table/JSON 專家。
-
類似的現象也可以泛化到通用場景,儘管我們整個 training 中完全沒有包含這樣的數據。
ChartMoE 專家分佈可視化
我們分析了完全讓模型自由學習,不加入 MoE balance loss 下的專家選擇分佈,和上文所述符合,模型傾向於選擇通用專家和最富含信息的 Code 專家 Random 初始化、Co-Upcycle 初始化、加入 balance loss 的 Diversely-Aligned 初始化,我們均有進行專家選擇分佈的分析,以及嚴格控制變量下的 ChartQA 性能比較:
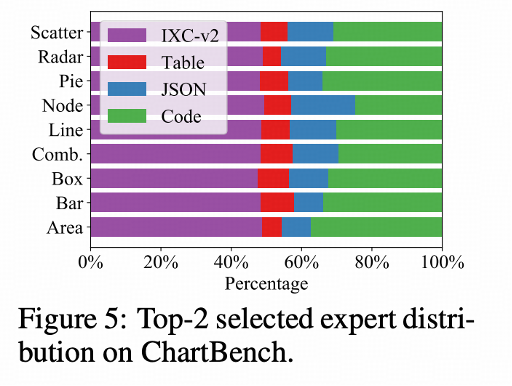
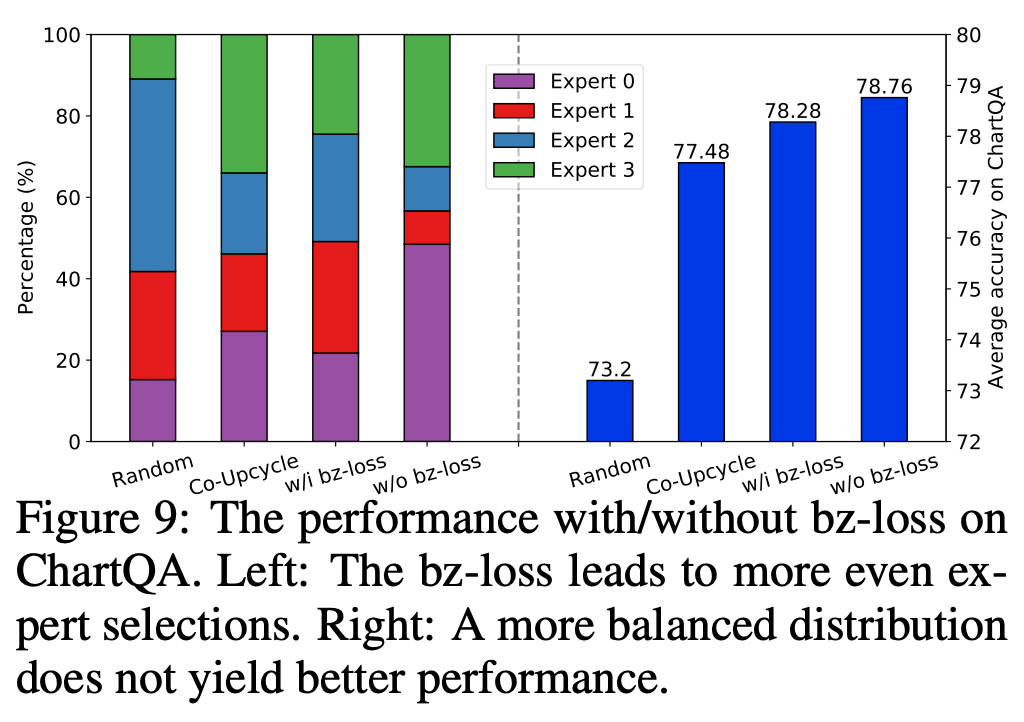
儘管前三者都會獲得更均衡的專家分佈,但性能是不如完全不加 balance loss 自由學習 Divesely-Aligned MoE 的,可能是因為:
對於視覺信息,本就是分類不均衡的,信息相對少的背景 tokens 佔全部視覺 tokens 的大多數。
balance loss 本身目的並非在於性能的提升,而是專家選擇更均衡後,配合專家並行 (Expert Parallel) 技術,可以提高訓練 / 推理的效率。
我們額外分析了最終的 ChartMoE checkpoint,強行固定選擇某個專家的性能:
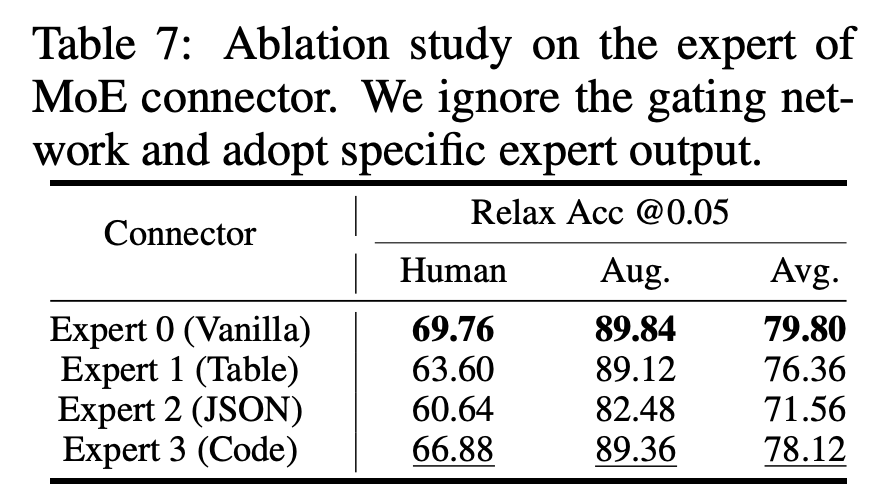
可以看到,和專家選擇分佈基本保持一致,模型自己最知道哪個專家能獲得好性能了。
ChartMoE Performance(Chart & 通用)
這裏想先 show 一下通用領域,因為 chart 領域的 sota 在進行了細粒度的多樣化對齊後,相對來說更加可以預見。在不使用通用領域數據的情況下,在通用領域中遺忘更少,可能是做下遊領域 MLLM 更關注的事情。這會讓我們有更好的預期:比如加入通用數據後,通用能力不掉!
我認為通用領域遺忘更少有兩個原因:
(顯而易見)插入了通用專家,儘管通用專家也更新了。
(可能更本質)MoE Connector 的結構,由於 learnable router 的存在,通用專家的更新相比普通的 MLP Connector 是更少的(比如有些 token 可能確實沒選到通用專家,它就不會對通用專家的更新產生貢獻),某種程度上,可以認為 MoE Connector 這種 sparse 結構本身就帶有一定的正則作用。
通用領域
我們選擇了 MME 和 MMBench 兩個比較有代表性的通用領域的 benchmark,比較了 baseline(InternLM-XComposer2)、用 chart 數據 directly SFT、以及 ChartMoE 的性能,可以看到,Directly SFT 模型在通用領域掉點嚴重,ChartMoE 幾乎不會掉性能,且在有些細分領域上還有增點
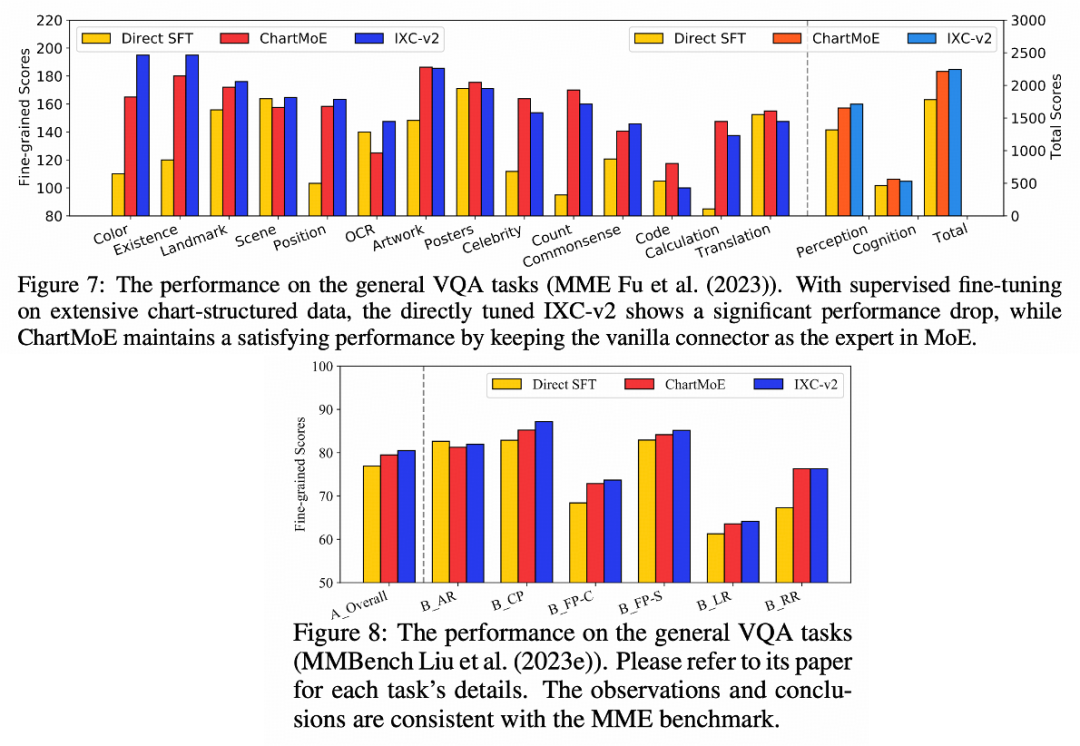
Chart 領域
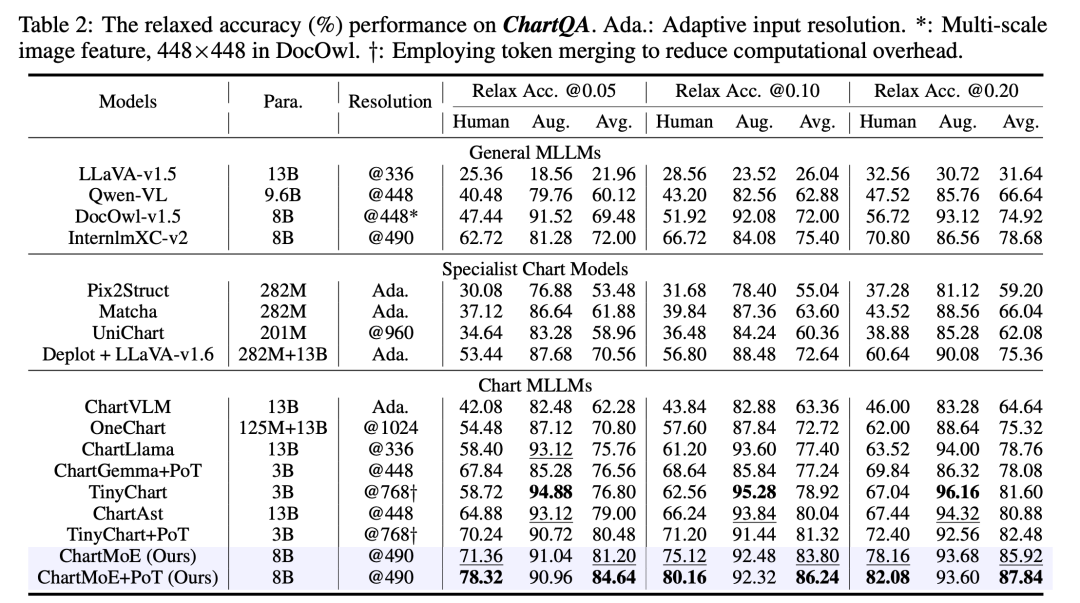
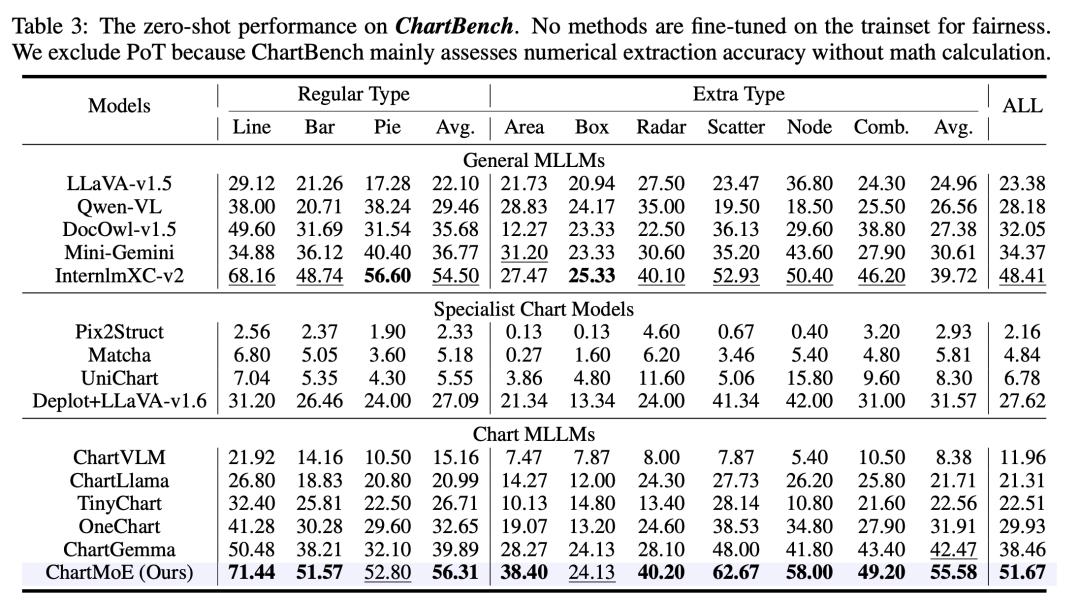
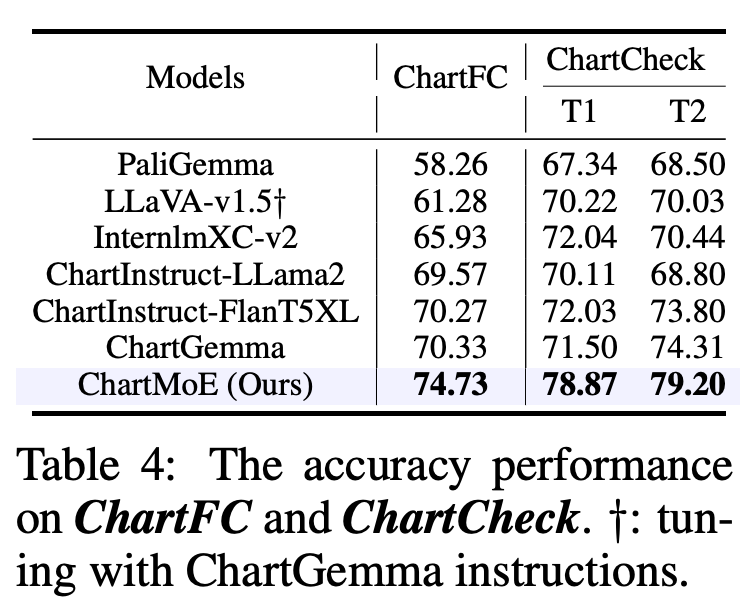
對於 Chart 領域,我們選擇了 ChartQA、ChartBench(主要是無數值標註的 Chart)、ChartFC&ChartCheck(Fact Checking 任務,回答支持或不支持),在這些 Benchmark 上,ChartMoE 都能達到非常好的性能,尤其是相對初始的 baseline 模型(InternLM-XComposer2)提升非常顯著
Conclusion
在 ChartMoE 這個工作中,我們探索了通用 MLLM 使用 MoE 這種 sparse 的結構後在下遊任務上的表現:
從 Representation 角度:專家異質化的 MoE 可以獲得更加多樣、更加全面的視覺表徵,從而在下遊任務上達到更好的性能。
從 Knowledge 角度:MoE 這種 Sparse 結構,可以等價於加入了適量的正則項,既能顯著提高下遊任務性能,也能緩解下遊領域模型在通用任務上遺忘。
ChartMoE 是一個拋磚引玉的工作,我們相信後續也會有更多工作去探索下遊任務中 Sparse 結構的表現!