LLM如何高效理解用戶?淘天發佈首個基於用戶表徵的問答基準UQABench

新智元報導
編輯:編輯部
【新智元導讀】LLM正推動推薦系統革新,以用戶表徵為「軟提示」的範式開闢了高效推薦新路徑。在此趨勢下,淘天團隊發佈了首個基於用戶表徵的個性化問答基準UQABench,系統評估了用戶表徵的提示效能。
在「千人千面」的個性化服務浪潮中,大語言模型(LLM)憑藉強大的語義理解與生成能力,正在重塑推薦系統與個性化問答的產業格局。
研究背景:當推薦系統遇見大模型,如何突破效率與效果的雙重挑戰?
傳統方案通過將用戶點擊歷史轉化為文本提示注入LLM上下文,雖能提升相關性,卻面臨兩大硬傷:
-
效率瓶頸:單用戶行為序列動輒數萬token,遠超LLM上下文窗口限制,推理延遲與成本飆升;
-
噪聲干擾:冗餘點擊、誤操作等噪聲易誤導模型,削弱個性化效果。
破局之道:將用戶行為序列壓縮為高密度的表徵向量(user embeddings),以「軟提示」形式驅動LLM生成精準回覆。
然而,這一路徑的核心爭議在於——用戶表徵能否真正承載關鍵信息並有效引導LLM?UQABench應運而生,成為首個系統化評估用戶表徵質量的權威基準。
核心創新:三階評估體系 + 三維任務設計,直擊產業痛點
1. 標準化評估流程:從預訓練到場景化對齊
-
預訓練:基於海量行為數據訓練用戶編碼器(如SASRec、HSTU),捕獲興趣模式;
-
對齊微調:通過輕量Adapter(線性映射/Q-Former)橋接推薦空間與LLM語義空間,破解「表徵-語義」鴻溝;
-
場景化評估:設計多粒度任務驗證用戶表徵的實用價值 。
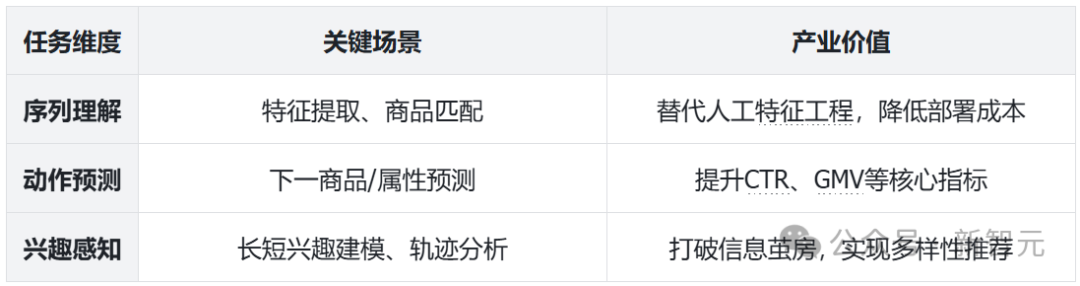
2. 三維任務體系:覆蓋傳統需求與LLM新願景
重磅發現:用戶表徵的效能密碼與工業啟示
-
模型架構:Transformer類模型(如HSTU)顯著優於RNN類模型(如GRU4Rec,Mamba),序列建模能力更適配LLM需求;
-
信息融合:商品側ID特徵(類目/品牌)與文本描述(標題)聯合編碼,可提升LLM對用戶興趣的解讀精度;
-
效率革命:最優表徵模型效果逼近純文本方案,推理token數減少90%+,成本效益比突破性提升;
-
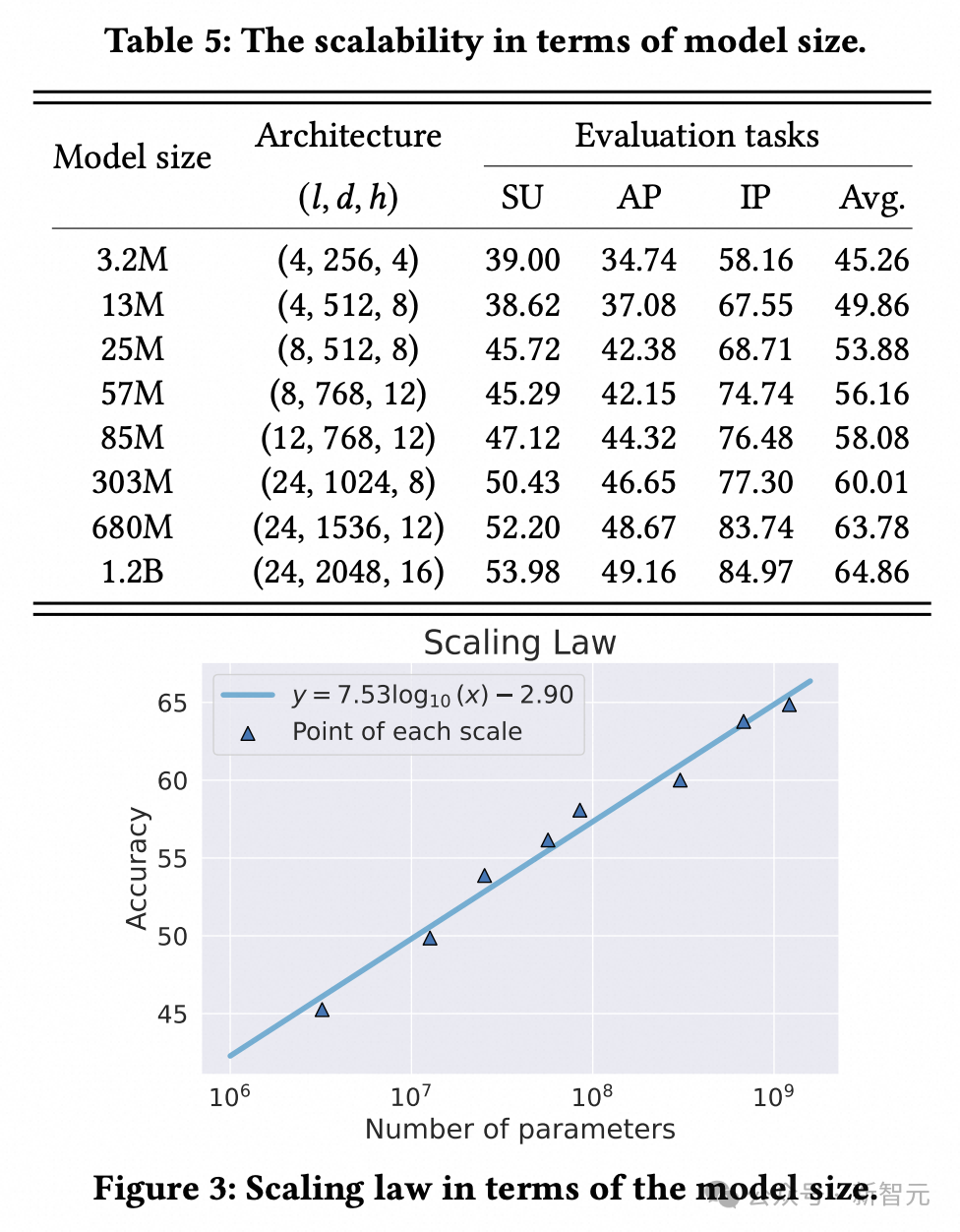
擴展定律:編碼器參數量從3M增至1.2B,LLM個性化性能持續提升,為「離線訓練強化+在線高效推理」提供理論支撐 。

論文鏈接:
https://arxiv.org/abs/2502.19178
代碼庫倉庫:https://github.com/OpenStellarTeam/UQABench
數據集下載:https://www.kaggle.com/datasets/liulangmingliu/uqabench
接下來,我們來詳細介紹論文的內容。
論文詳解
研究背景
大語言模型(LLM)近年來在推薦系統和個性化問答中被廣泛應用。為了追求更加個性化的用戶體驗,實現「千人千面」,將用戶的歷史點擊序列融入LLM的輸入中變得至關重要。最常見結合的方式是,將用戶點擊歷史,利用特定的規則轉化為自然語言文本,作為LLM的用戶背景提示(context)。
然而,從工業應用的角度來看,噪聲以及超長序列帶來的性能和開銷問題,對直接將序利雲本用作用戶context提出了挑戰。一種自然的解決方案是,將用戶交互歷史壓縮和提煉為表徵向量(或向量組),作為軟提示(soft prompt)輔助LLM生成個性化的回覆。
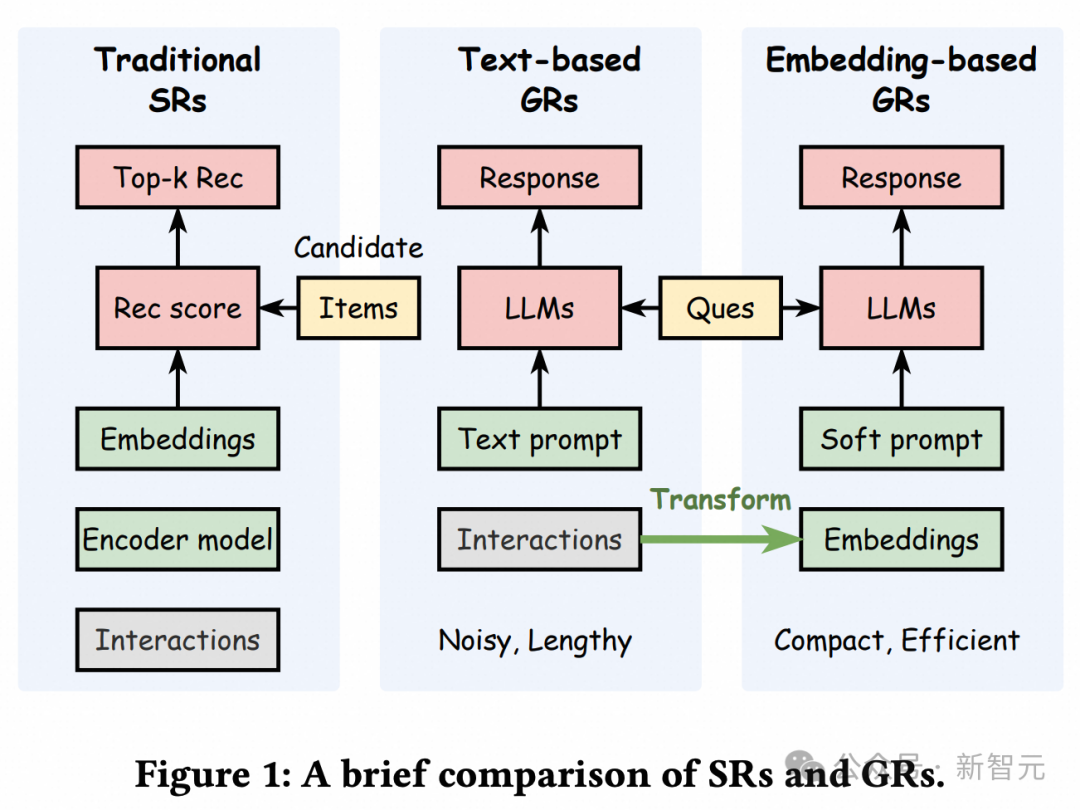
雖然這種方法提高了效率,但一個關鍵問題隨之而來:用戶嵌入能否充分捕獲用戶交互歷史中有價值的信息並提示LLM?為瞭解決這一問題,研究人員提出了UQABench,一個專為評估用戶嵌入在提示LLM進行個性化時的有效性而設計的基準。研究人員建立了一個公平和標準化的評估流程,涵蓋了預訓練、微調和評估階段。
為了全面評估用戶嵌入,研究人員設計了三種維度的任務:序列理解、動作預測和興趣感知。這些評估任務覆蓋了傳統推薦任務中提高召回/排序指標等行業需求,以及基於LLM方法的願景,如準確理解用戶興趣和提升用戶體驗。
研究人員對用於建模用戶的多種經典方法(如SASRec)和SOTA方法(如HSTU、Mamba4Rec)進行了廣泛實驗和評估。此外,研究人員揭示了利用用戶嵌入來提示LLM的scaling law。
相關工作
用戶歷史行為序列中提取的user embeddings作為個性化場景的核心特徵載體,其應用價值與演化前景已得到廣泛驗證。
當前研究趨勢表明,深度融合LLM的語義理解能力來增強用戶表徵的語義泛化性,正成為提升embedding質量的重要技術路徑。
研究人員在淘寶搜索廣告場景中創新性地構建了基於大規模用戶模型(LUM)的三階段訓練範式,實現了用戶意圖建模的顯著提升。該方法在線上實驗中獲得CTR和RPM的顯著增益。
具體方法論與實驗細節可參考原論文:「Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model」。
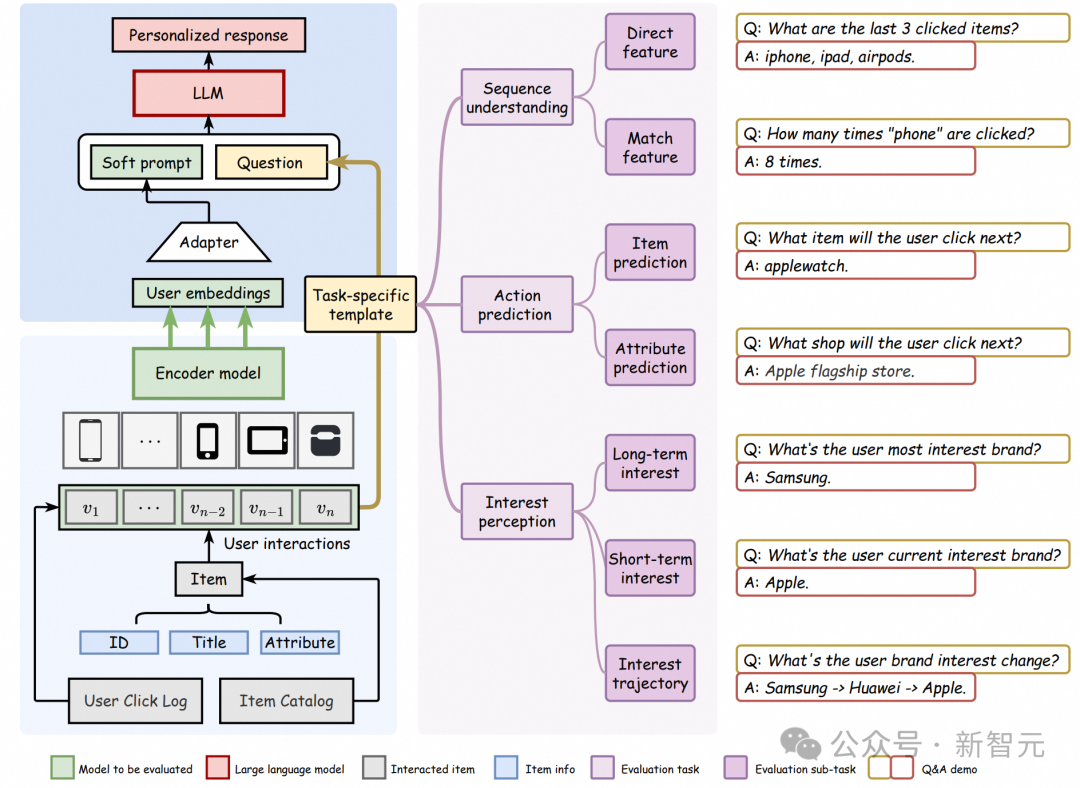
任務類型
UQABench由淘寶電商系統中18萬個用戶對100萬個商品的點擊的行為數據構建而來,要求LLM基於給定用戶的表徵向量,回答一個自然文本形式問題。問題類型有三大類共七個子任務,用以評估推薦系統中最關鍵的幾類問題。
1. 序列理解:
分為直接特徵理解和match類特徵理解。前者要求模型回答用戶序列中一些顯而易見的特徵,例如「用戶最近點擊的三個商品的品牌分別是什麼」,而後者要求模型回答一些交叉類的特徵,例如「用戶共點擊過多少次手機類商品」。序列理解任務涉及使用LLM從用戶嵌入中提取和恢復歷史用戶信息。目標是評估用戶嵌入在多大程度上可以作為橋樑,將用戶交互序列中的必要信息傳遞給LLM。這個任務關係到在LLM時代用戶嵌入是否可以替代大量的用戶側特徵工程。
2. 動作預測:
預測用戶下一個要點擊的商品和要點擊商品的屬性,例如「基於用戶的瀏覽歷史,該用戶下一個要點擊的商品的標題是什麼」。該任務的目標是評估用戶嵌入如何能夠幫助LLM完成諸如Top-k推薦和點擊率(CTR)預測等傳統工業推薦系統任務,這與電商平台的收入密切相關。
3. 興趣感知:
預測用戶的短期興趣、長期興趣以及興趣的變化軌跡,例如「用戶最喜歡的品牌是什麼」或是「用戶近期最喜歡什麼類目的商品」。這反映了基於LLM做推薦的方法的願景:準確理解用戶興趣和提升用戶體驗。基於LLM的推薦系統相比傳統推薦系統的一個革命性進步是在引入顯著的多樣性方面。受限於訓練範式和協同過濾框架,傳統推薦系統往往集中在熱門項目和頻繁互動的用戶上。研究人員希望用戶嵌入能夠幫助基於LLM的方法召回多樣的用戶興趣項目,從而提高個性化並增強用戶體驗。
數據構造
首先,隨機圈定18萬個近期有較活躍行為的淘寶用戶,並獲取他們的商品點擊行為序列。出於對合規性的需要,需要對各種ID類信息進行了脫敏、並移除了用戶行為序列中的敏感商品。除此之外,研究人員還在不損傷效果的前提下,對用戶行為序列做了一定程度的改寫,以保護用戶的隱私。
針對每一類問題,研究人員都為其設計了提問的模版。給定一個任務特定的模板和用戶數據,便可以基於用戶交互自動生成相應的問題和答案。例如,為直接特徵理解任務設計的模板可能是「用戶最近點擊的 k個商品的類目分別是什麼」,只需要將用戶行為序列的後k個item的類目作為答案即可。
由於讓LLM生成高度專業化問題的完整答案是不切實際的,所以UQABench以選擇題的形式評測。此外,研究人員還採用了一些過濾規則,以避免簡單或過於繁瑣的問題。
評測流程
研究人員提供了三份數據,待評測的模型需要在前兩份數據上進行訓練,並在第三份數據上做預測,並執行評測。整個評測流程分為三個階段:
1. 預訓練:
將待評測的用戶建模模型(例如SASRec或HSTU),在研究人員提供的用戶行為序列數據上進行預訓練,訓練任務可以自由設置,預設使用 next item prediction。
2. 對齊:
預訓練後的encoder可以產出捕捉用戶興趣的表徵,但是還需要引入一個adapter,用來橋接協同過濾空間和LLM語義空間。常見的adapter有簡單的線性映射(維度對齊)加mean-pooling(長度壓縮),或是稍微複雜一點的q-former。Adapter是隨機初始化、未經訓練的。所以需要在研究人員提供的對齊數據上進一步finetune。
3. 評估:
用對齊後的用戶表徵模型,生產對應的用戶表徵,並回答測試集中的7000個問題,然後使用打分腳本獲得評價指標。
實驗發現
1. 總體實驗:
研究人員評價了幾個廣泛流行的用戶建模模型,在整體對比實驗中,以HSTU 為代表的Transformer類模型在用戶超長週期興趣的表徵的能力上表現出強勁的效果,超越了RNN類模型(GRU4Rec和Mamba4Rec)。
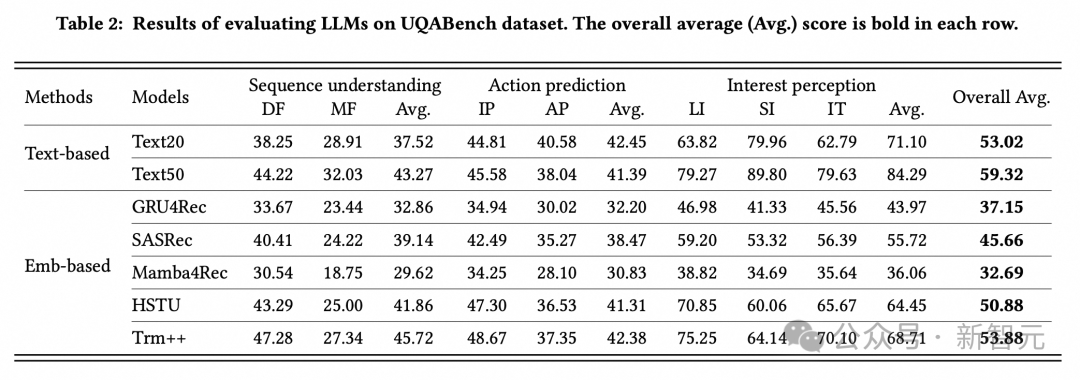
2. 消融實驗:
a. 在對用戶序列進行編碼時,商品信息中的side info(例如類目ID、店舖ID和品牌ID)等和文本信息(例如標題),都會有助於LLM對用戶表徵的理解,在建模時需要將它們考慮在內。
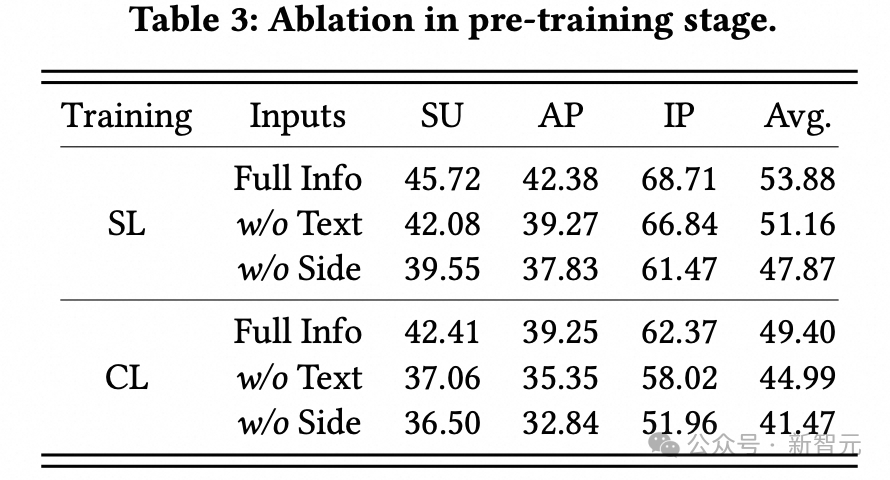
b. 即使使用最簡單的線性映射與平均池化 (linear + mean pooling)作為adapter,將用戶的表徵壓縮為一個單一向量(輸入給LLM時僅僅佔用一個token的位置),也能取得不錯的效果,這說明單一向量的表達能力也很強。Q-former的訓練穩定性比較差,對參數比較敏感,使用未經細調的超參數效果不佳。

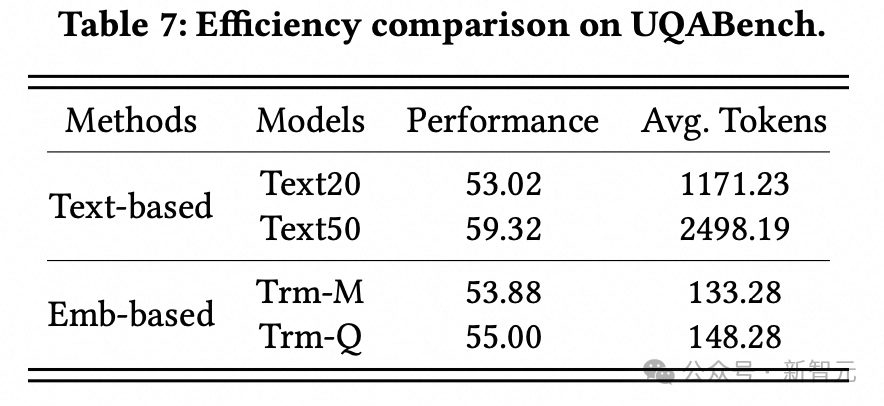
3. 效率實驗:
研究人員也比較了基於純文本context的模型的效果(TextN表示用戶行為序列截斷到近期的N個item),可以看出,最優秀的基於embedding的模型,效果可以接近文本模型,但其輸入給LLM的token數隻有前者的5%左右,推理開銷要小得多,性價比很高。
4. 放縮實驗:
研究人員將用戶編碼器的參數量,從3M逐漸擴大到1.2B,並逐個進行完整評測流程(預訓練-微調-評測),可以從評測結果看出性能與模型大小之間呈現的明顯擴展規律。這一結果對工業場景應用具有重要意義:可以通過在離線環境強化編碼器模型(即擴大模型規模),持續提升LLM在在線環境中的個性化性能,而不會影響推理效率。
最後,歡迎廣大研究者使用評測集進行實驗和研究。淘天集團算法技術-未來生活實驗室團隊將持續為中文社區的發展貢獻力量。
作者介紹
核心作者包括劉朗鳴,劉石磊,袁愈錦,蘇文博。作者團隊來自淘天集團的算法技術-未來生活實驗室團隊和阿里媽媽-搜索廣告團隊。
為了建設面向未來的生活和消費方式,進一步提升用戶體驗和商家經營效果,淘天集團集中算力、數據和頂尖的技術人才,成立未來生活實驗室。
實驗室聚焦大模型、多模態等AI技術方向,致力於打造大模型相關基礎算法、模型能力和各類AI Native應用,引領AI在生活消費領域的技術創新。
參考資料:
https://arxiv.org/abs/2502.19178
https://github.com/OpenStellarTeam/UQABench
https://www.kaggle.com/datasets/liulangmingliu/uqabench