自動學會工具解題,RL擴展催化奧數能力激增17%

在大模型推理能力提升的探索中,工具使用一直是克服語言模型計算局限性的關鍵路徑。不過,當今的大模型在使用工具方面還存在一些局限,比如預先確定了工具的使用模式、限制了對最優策略的探索、實現透明度不足等。
為瞭解決這些難題,來自上海交通大學、SII 和 GAIR 的研究團隊提出了一種全新框架 ToRL(Tool-Integrated Reinforcement Learning),該方法允許模型直接從基座模型開始,通過強化學習自主探索最優工具使用策略,而非受限於預定義的工具使用模式。

-
論文標題:ToRL: Scaling Tool-Integrated RL
-
論文地址:https://arxiv.org/pdf/2503.23383
-
代碼地址:https://github.com/GAIR-NLP/ToRL
-
數據集地址:https://github.com/GAIR-NLP/ToRL/tree/main/data/torl_data
-
模型地址:https://huggingface.co/GAIR/ToRL-7B
實驗表明,這種方法在數學推理任務上取得了顯著突破:ToRL-7B 在 AIME24 上達到了 43.3% 的準確率,比不使用工具的基線 RL 模型提高了 14%,比現有的工具集成大模型提高了 17%。
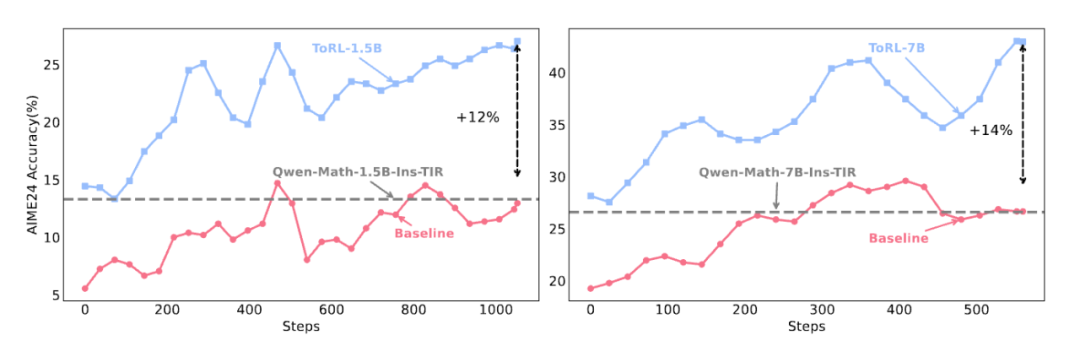 圖 1: ToRL 在 AIME24 等基準中的性能對比,優於基線和現有 TIR 系統
圖 1: ToRL 在 AIME24 等基準中的性能對比,優於基線和現有 TIR 系統一、為什麼要直接從基座模型擴展工具集成強化學習?
在傳統工具集成推理(TIR)領域,研究者們長期遵循著一條看似不可撼動的鐵律:必須先通過監督微調(SFT)教會模型使用工具,才能進行強化學習優化。這種 “先 SFT 再 RL” 的範式,就像給 AI 套上預設的思維枷鎖,雖然能獲得穩定的性能提升,卻可能永遠無法發現最優的工具使用策略。
正當大家沿著這條既定路線堆砌數據和算力時,該研究團隊卻大膽提出了一個假設:如果讓模型完全自主探索工具使用方式,會怎樣?他們開發的 ToRL 框架就像打開了一扇全新的大門 —— 直接從基座模型出發,單純通過擴展強化學習讓 AI 自主掌握工具使用的精髓。
實驗結果令人驚喜:ToRL 不僅打破了傳統 TIR 方法的性能天花板,更讓模型自發湧現出三大重要能力:
像人類專家般的工具選擇直覺
自我修正無效代碼的元能力
動態切換計算與推理的解題智慧
這些能力完全由獎勵信號驅動自然形成,沒有任何人為預設的痕跡。
這不禁讓人思考:ToRL 證明了大模型可能早已具備強大的工具使用能力,只是需要更開放的學習方式去釋放。當主流研究還在為數據規模和算法複雜度較勁時,ToRL 用事實告訴我們:有時候,少一些人為干預,反而能收穫更多意外之喜。
 圖 2: ToRL 使用自然語言和代碼工具交叉驗證,並在發現不一致後進一步使用使用工具驗證
圖 2: ToRL 使用自然語言和代碼工具交叉驗證,並在發現不一致後進一步使用使用工具驗證二、技術解析:ToRL 如何賦予模型自主工具能力
工具集成推理 (TIR) 的基本框架
工具集成推理 (TIR) 使大語言模型能夠通過編寫代碼,利用外部工具執行計算,並基於執行結果迭代生成推理過程。這一過程可以用簡單的語言描述為:
當語言模型面對一個問題時,TIR 允許模型構建一個包含多個步驟的推理軌跡。在每一步中,模型首先用自然語言進行推理,然後生成相關代碼,接著獲取代碼的執行結果,並將這三部分內容組合起來形成完整的推理過程。隨著推理的深入,模型會不斷參考之前的推理內容、代碼及其執行結果,進一步調整自己的思路。
ToRL: 直接從基座模型的強化學習
ToRL 框架將 TIR 與直接從基座語言模型開始的強化學習相結合,而不需要先進行監督微調。這使得模型能夠自主發現有效的工具使用策略。
在模型的推理過程中,當檢測到代碼終止標識符 (“`output) 時,系統會暫停文本生成,提取最新的代碼塊執行,並將結構化執行結果插入上下文中。系統會繼續生成後續的自然語言推理,直到模型提供最終答案或生成新的代碼塊。
設計選擇與考量:
-
工具調用頻率控制:為了平衡訓練效率,引入超參數 C,表示每次響應生成允許的最大工具調用次數;
-
執行環境選擇:選擇穩定、準確和響應迅速的代碼解釋器實現;
-
錯誤消息處理:提取關鍵錯誤信息,減少上下文長度;
-
沙盒輸出掩碼:在損失計算中掩蓋沙盒環境的輸出,提高訓練穩定性。
獎勵設計:實現了基於規則的獎勵函數,正確答案獲得 + 1 獎勵,錯誤答案獲得 – 1 獎勵。此外,研究還嘗試探究了基於執行的懲罰:含有不可執行代碼的響應會導致 – 0.5 的獎勵減少。在預設實驗設置中,僅使用了答案正確性的 reward。
三、實驗驗證:ToRL 的性能優勢
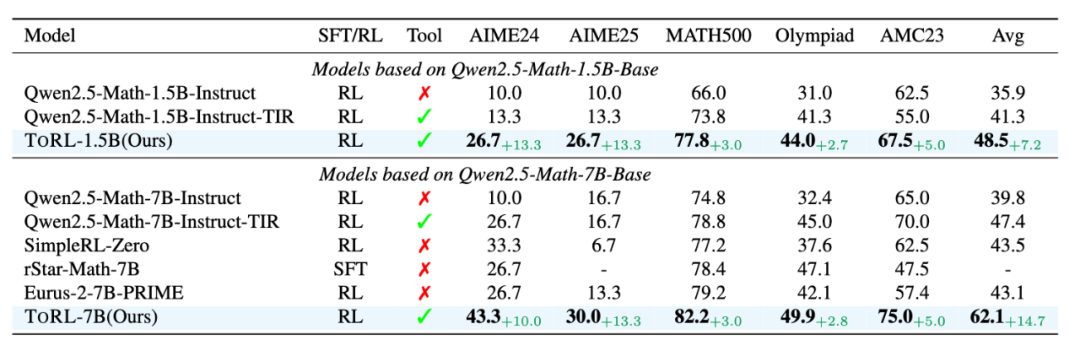 圖 3: ToRL 在數學基準測試上的準確率比較
圖 3: ToRL 在數學基準測試上的準確率比較實驗結果表明,ToRL 在所有測試基準上的表現始終優於基線模型。對於 1.5B 參數模型,ToRL-1.5B 的平均準確率達到了 48.5%,超過了 Qwen2.5-Math-1.5B-Instruct (35.9%) 和 Qwen2.5-Math-1.5B-Instruct-TIR (41.3%)。在 7B 參數模型中,性能提升更加顯著,ToRL-7B 達到了 62.1% 的平均準確率,比具有相同基礎模型的其他開源模型高出 14.7%。
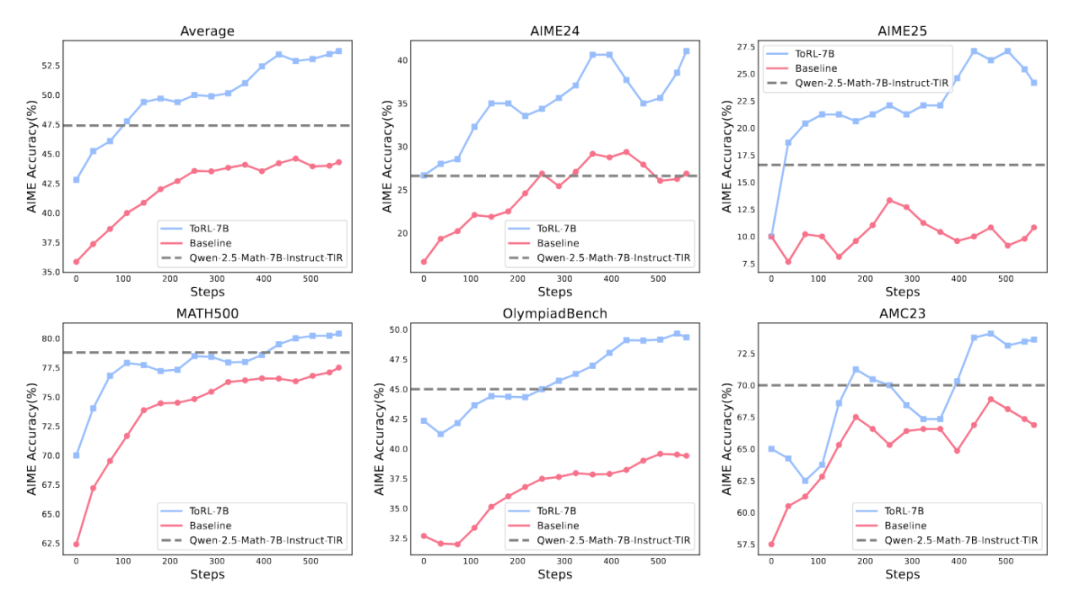 圖 4: ToRL 在數學基準測試上的訓練動態
圖 4: ToRL 在數學基準測試上的訓練動態圖 4 展示了在五個不同數學基準上的訓練動態。ToRL-7B 在訓練步驟中顯示出持續改進,並保持明顯優勢。這種性能差距在具有挑戰性的基準上尤為顯著,如 AIME24 (43.3%)、AIME25 (30.0%) 和 OlympiadBench (49.9%)。
四、行為探索:模型使用工具的認知模式
訓練中的工具使用進化
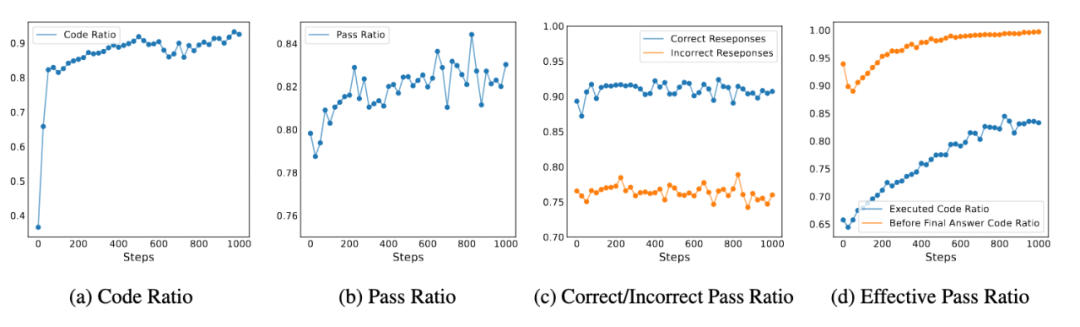 圖 5: 訓練步數增延長,ToRL 的代碼使用率與有效性變化
圖 5: 訓練步數增延長,ToRL 的代碼使用率與有效性變化圖 5 提供了訓練過程中工具使用模式的深入洞察:
-
代碼比率:模型生成的包含代碼的響應比例在前 100 步內從 40% 增加到 80%,展示了整個訓練過程中的穩定提升
-
通過率:成功執行的代碼比例呈現持續上升趨勢,反映了模型增強的編碼能力
-
正確 / 錯誤響應的通過率:揭示了代碼執行錯誤與最終答案準確性之間的相關性,正確響應表現出更高的代碼通過率
-
有效代碼比率:檢查有效代碼比例的變化,包括成功執行的代碼和在模型提供最終答案前生成的代碼,兩者都隨著訓練時間增加而提高
關鍵發現:隨著訓練步驟的增加,模型解決問題使用代碼的比例以及可以正確執行的代碼比例持續增長。同時,模型能夠識別並減少無效代碼的生成。
關鍵參數設置的影響
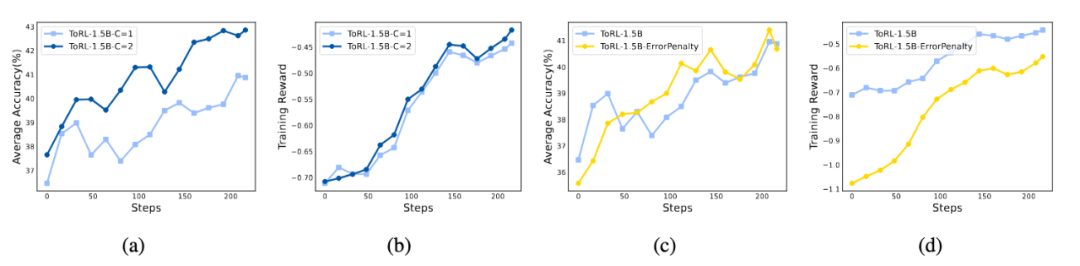 圖 6: 探索相應最大次數(左 2 圖)和可執行(右 2 圖)對模型性能的影響
圖 6: 探索相應最大次數(左 2 圖)和可執行(右 2 圖)對模型性能的影響研究團隊探索了關鍵 ToRL 設置對最終性能和行為的影響:
首先,實驗探究了增加 C(單次響應生成中可調用的最大工具數)的影響。將 C 從 1 增加到 2 顯著提高了性能,平均準確率提高約 2%。然而,增加 C 會大幅降低訓練速度,需要在性能和效率之間進行權衡。
此外,分析了將代碼可執行性獎勵納入獎勵塑造的影響。結果表明,這種獎勵設計並未提高模型性能。研究團隊推測,對執行錯誤進行懲罰可能會激勵模型生成過於簡單的代碼以最小化錯誤,從而可能阻礙其正確解決問題的能力。
通過強化學習擴展湧現的認知行為
模型訓練後期出現了一些有趣的現象,這些現象幫助我們深入理解模型使用工具解決問題的認知行為。
例如,模型能夠根據代碼解釋器的執行反饋調整其推理。在一個案例中,模型首先編寫了代碼,但由於不當處理導致索引錯誤。在收到 “TypeError: ‘int’ object is not subscriptable” 的反饋後,它迅速調整併生成了可執行代碼,最終推斷出正確答案。
 圖 7: 案例 1-ToRL 通過執行器報錯反饋重新構建推理代碼
圖 7: 案例 1-ToRL 通過執行器報錯反饋重新構建推理代碼另一個案例展示了模型的反思認知行為。模型最初通過自然語言推理解決問題,然後通過工具進行驗證,但發現不一致。因此,模型進一步進行修正,最終生成正確答案。
 圖 8: 案例 2-ToRL 使用代碼工具驗證修正推理結果
圖 8: 案例 2-ToRL 使用代碼工具驗證修正推理結果關鍵發現:ToRL 產生了多種認知行為,包括從代碼執行結果獲取反饋,以及通過代碼和自然語言進行交叉檢查。
五、前景與意義:超越數學的工具學習
ToRL 使大語言模型能夠通過強化學習將工具整合到推理中,超越預定義的工具使用約束。研究結果顯示了顯著的性能提升和湧現的推理能力,展示了 ToRL 在複雜推理方面推進大語言模型發展的潛力。
這種直接從基座模型擴展的方法不僅在數學領域表現出色,還為需要精確計算、模擬或算法推理的其他領域開闢了新的可能性,如科學計算、經濟建模和算法問題解決。
研究團隊已開源實現代碼、數據集和訓練模型,使社區能夠在 ToRL 的基礎上進一步拓展工具增強語言模型的研究。
項目鏈接:https://github.com/GAIR-NLP/ToRL