AI理解27分鐘長影片超越GPT-4o,港理工新國立開源新框架:角色化推理+鏈式LoRA
VideoMind團隊 投稿
量子位 | 公眾號 QbitAI
AI能像人類一樣理解長影片。
港理工、新加坡國立團隊推出VideoMind框架,核心創新在於角色化推理(Role-based Reasoning)和鏈式LoRA(Chain-of-LoRA)策略。
相關論文已上傳arXiv,代碼和數據全部開源。

隨著影片數據量的激增,如何理解和推理長影片中的複雜場景和事件成為了多模態人工智能研究的熱點。不同於靜態圖像,影片不僅包含視覺信息,還包含時間維度上的動態變化,這要求模型在理解影片時不僅要識別畫面中的物體和場景,還要理解這些物體和場景如何隨時間變化和相互作用。
傳統的基於文本和圖像的推理模型(如OpenAI o1, DeepSeek R1等)往往無法應對這種複雜的時間維度推理任務。
VideoMind框架
區別於文本和圖片,長影片理解難以用傳統的單次感知 + 純文字推理實現。
相比之下,人類在理解長影片(如教學影片、故事類影片)時往往會尋找相關片段並反復觀看,以此獲取更可靠的結論。
受該現象啟發,作者根據影片理解所需要的4種核心能力(製定計劃、搜索片段、驗證片段、回答問題),為VideoMind定義了4個角色,並構建了一個角色化的工作流,有效地解決了長影片中的時序推理問題。
-
規劃者(Planner)
根據問題動態製定計劃,決定如何調用其他角色(如先定位,再驗證,最後回答問題);
-
定位器(Grounder)
根據給定的問題或查詢,精確定位與之相關的影片片段;
-
驗證器(Verifier)
對定位得到的多個時間片段進行驗證,確保其準確性;
-
回答者(Answerer)
基於選定的影片片段進行理解,生成最終答案。

△圖1:傳統純文字推理和VideoMind的角色化推理
為了高效整合以上角色,作者進一步提出了鏈式LoRA(Chain-of-LoRA)策略,在一個統一的Base模型(如Qwen2-VL)上同時加載多個輕量的LoRA Adapter,並在推理時根據需要進行動態切換,以實現不同角色間的轉換。該策略僅需要在Base模型上添加少量可學習參數,即可實現多個角色/功能間的無縫切換,既獲得了比單一模型顯著更優的性能,也避免了多模型並行帶來的計算開銷,從而在確保性能的同時大幅提高了計算效率。
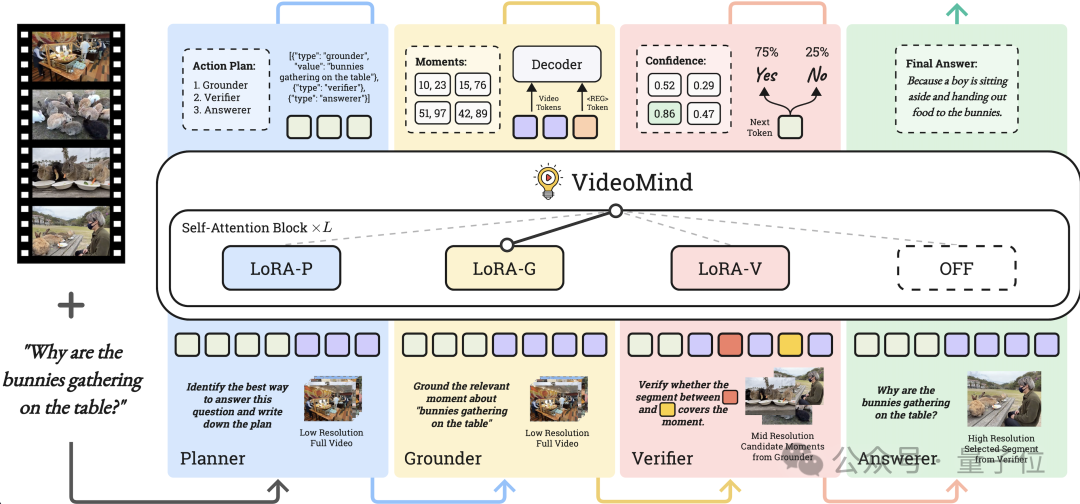 △圖2: VideoMind的整體架構和推理流程
△圖2: VideoMind的整體架構和推理流程VideoMind推理流程
如圖2所示,模型接收一個影片和一個用戶提出的問題作為輸入,通過切換多個角色來推理出最終答案。其中,Planner首先對影片和問題進行分析,執行後續推理的計劃,其結果以JSON list的形式呈現。推理計劃主要可分為以下三種:
 △圖3:VideoMind的三種推理模式
△圖3:VideoMind的三種推理模式其中(i)主要針對長影片問答任務(Grounded VideoQA),需要使用Grounder + Verifier + Answerer三個角色進行作業;(ii)針對影片時序定位任務(Video Temporal Grounding),使用Grounder + Verifier來進行相關片段的精準查找;(iii)針對短影片問答,該場景下由於影片較短,無需對其進行裁剪,故直接使用Answerer進行推理。
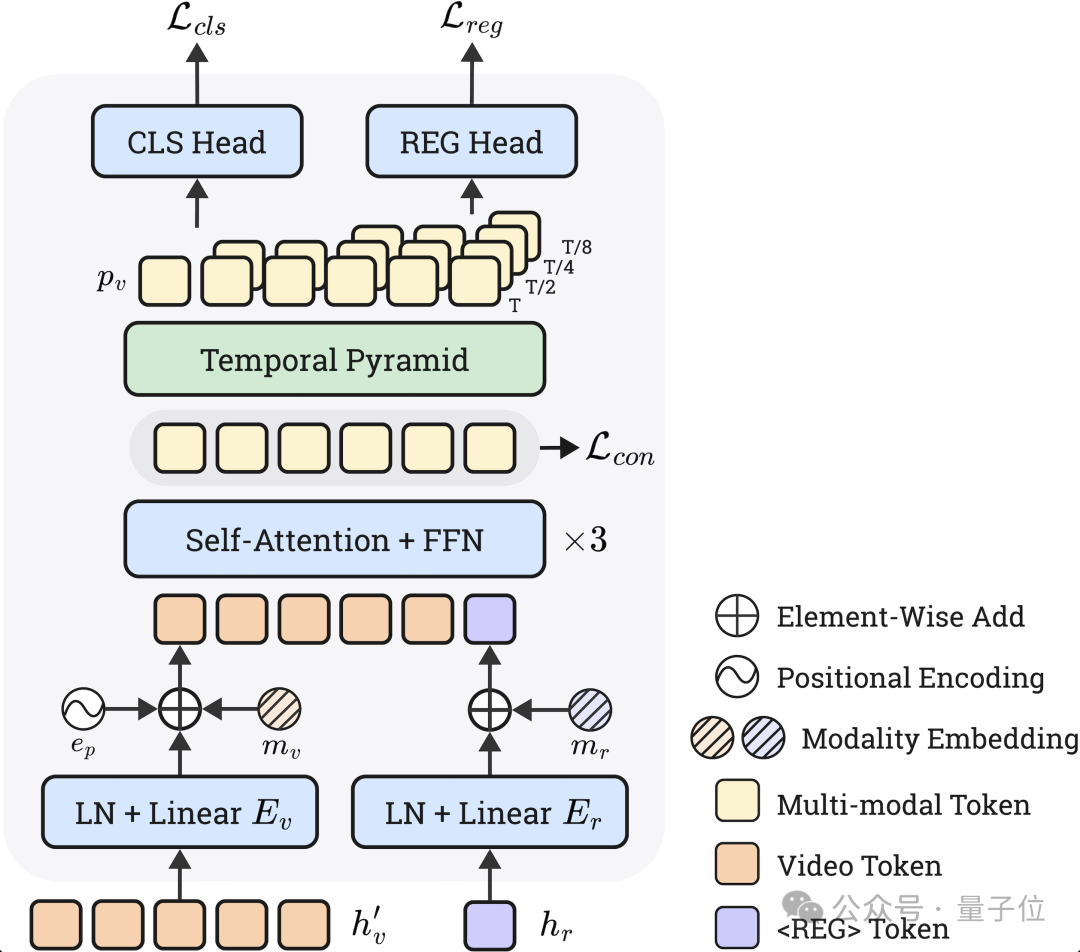 △圖4:Timestamp Decoder模塊
△圖4:Timestamp Decoder模塊Grounder負責接收一個自然語言查詢,並在影片中定位相關片段。針對這一複雜任務,研究團隊提出了Timestamp Decoder模塊,將離散的Token預測任務和連續的時間回歸任務解耦開來,並使LLM通過Special Token進行調用,實現了強大的Zero-shot時序定位性能。
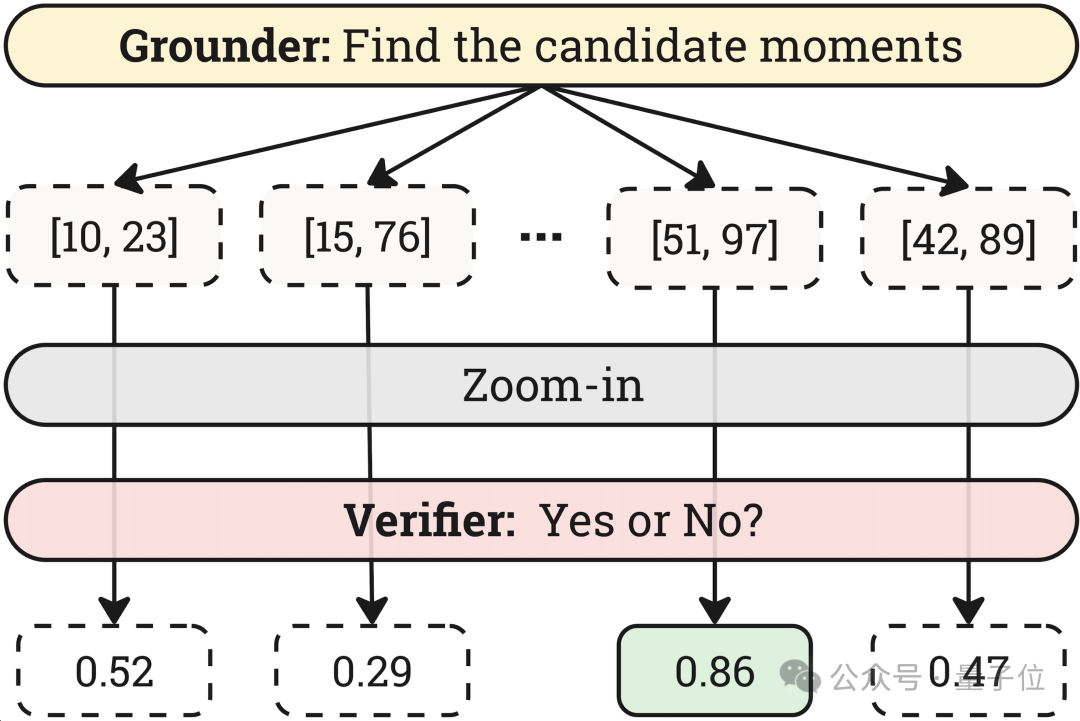 △圖5:Verifier的驗證策略
△圖5:Verifier的驗證策略為保證時間解像度,Grounder往往工作在較低的空間解像度下,因此獲得的時間片段可能會不準確。針對此問題,作者設計了Verifier角色來對每個片段進行放大驗證,並從多個候選片段中選取置信度最高的作為目標片段。試驗證明該策略可以進一步顯著提高Temporal Grounding任務的性能。
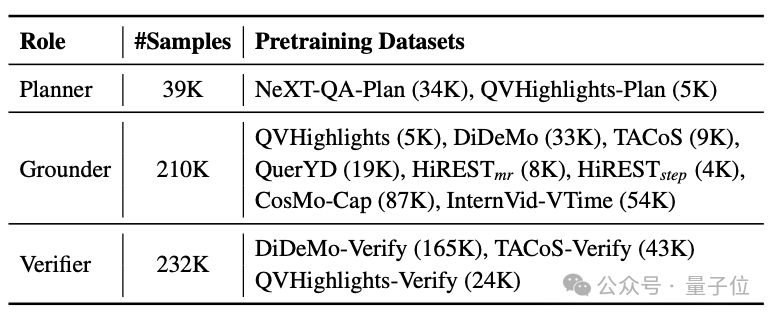 △表1:VideoMind的訓練數據集
△表1:VideoMind的訓練數據集為訓練VideoMind,作者針對不同角色收集/製作了多個數據集,共計包含接近50萬個樣本。不同角色使用不同數據集進行訓練,並在推理時合併加載,以確保每個角色的性能最大化。所有訓練數據(包括前期探索使用的更多數據集)全部公開可用。
實驗與評估
為了驗證VideoMind的有效性,作者在14個公開基準測試集上進行了廣泛的實驗,涵蓋了長影片定位 + 問答(Grounded VideoQA)、影片時序定位(Video Temporal Grounding)和普通影片問答(General VideoQA)等任務。
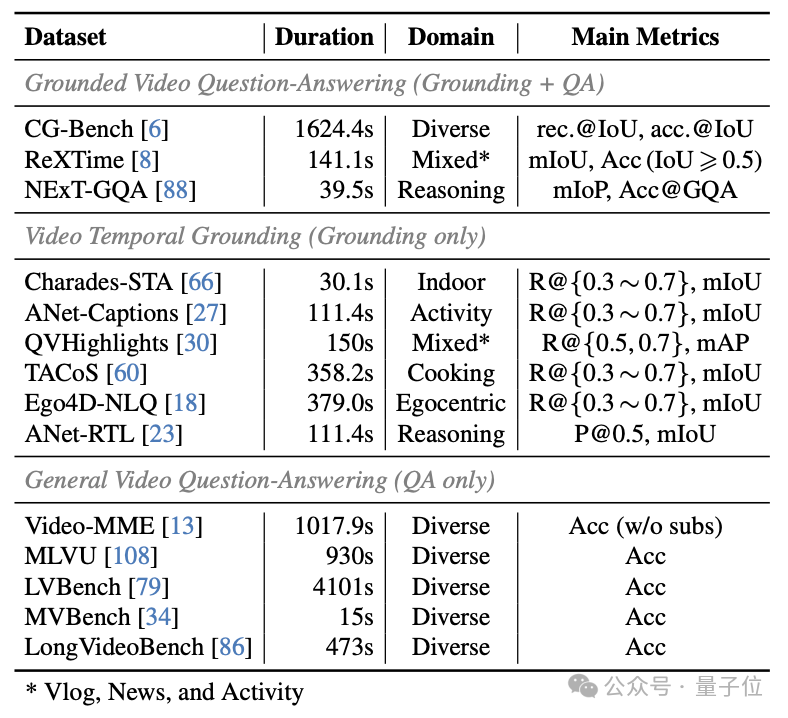 △表2:用於VideoMind評測的基準測試集
△表2:用於VideoMind評測的基準測試集(1)影片定位 + 問答(Grounded VideoQA)
在CG-Bench、ReXTime、NExT-GQA等長影片基準上,VideoMind在答案精確度和時序定位準確性方面表現出了領先優勢。特別的,在平均影片長度約為27分鐘的CG-Bench中,較小的VideoMind-2B模型在時序定位和問答任務上超越了GPT-4o、Gemini-1.5-Pro等最先進的模型。
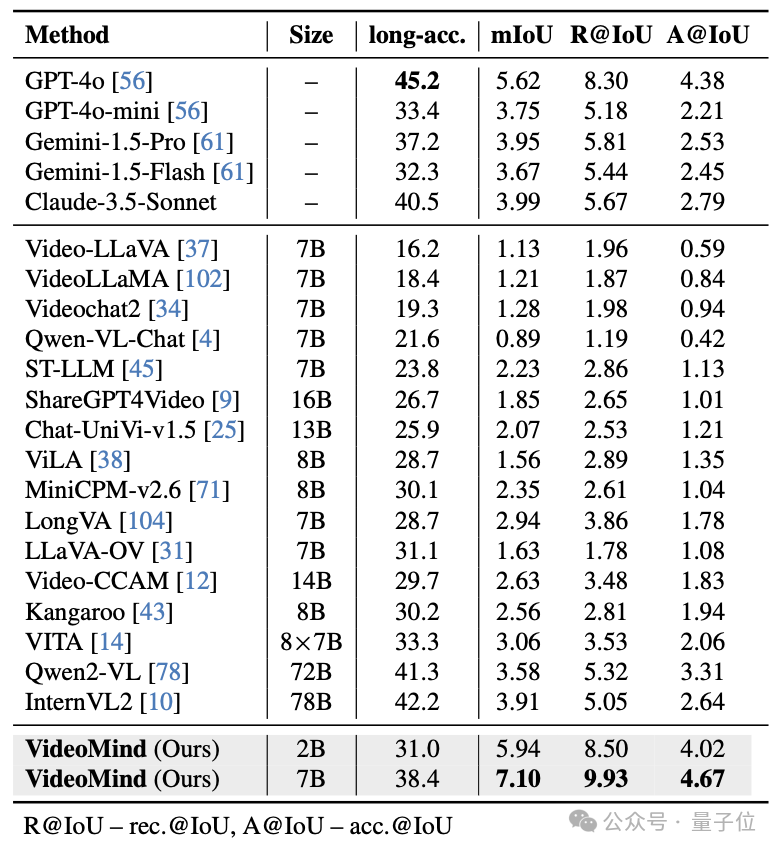 △表3:CG-Bench數據集的測試結果
△表3:CG-Bench數據集的測試結果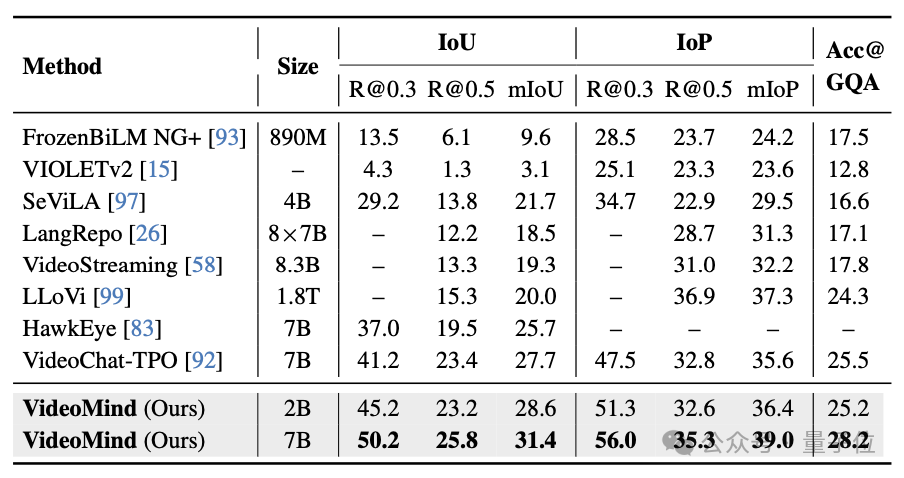 △表4:NExT-GQA數據集的測試結果
△表4:NExT-GQA數據集的測試結果(2)影片時序定位(Video Temporal Grounding)
VideoMind的Grounder通過創新的Timestamp Decoder和Temporal Feature Pyramid設計,顯著提高了影片時序定位的準確性。Verifier的設計進一步提升了高精度定位的性能。VideoMind在Charades-STA、ActivityNet-Captions、QVHighlights等基準上都取得了最佳性能。此外,VideoMind也是首個支持多片段grounding的多模態大模型,因此可以在QVHighlights數據集上跟現有模型公平對比。
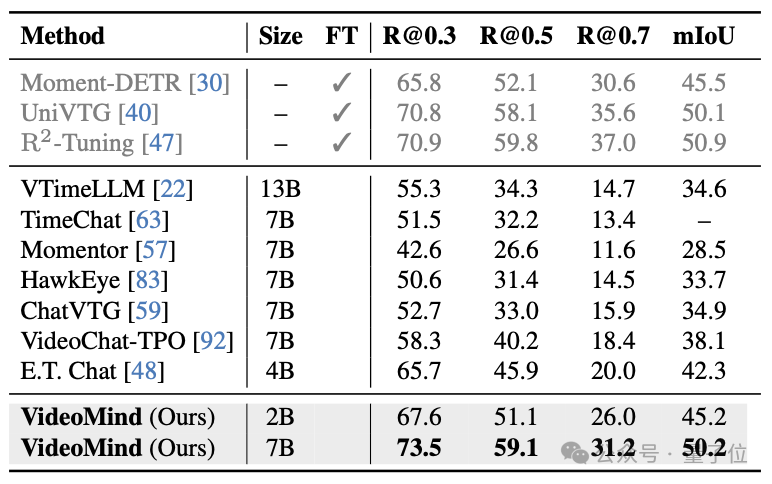 △表5:Charades-STA數據集的測試結果
△表5:Charades-STA數據集的測試結果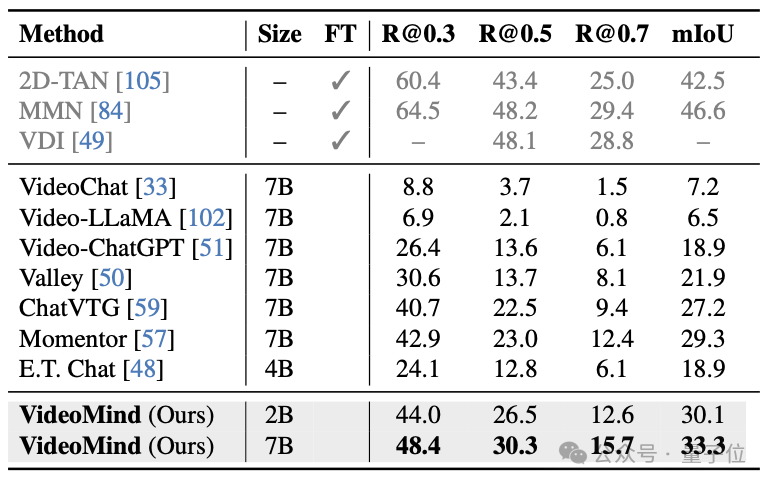 △表6:ActivityNet Captions數據集的測試結果
△表6:ActivityNet Captions數據集的測試結果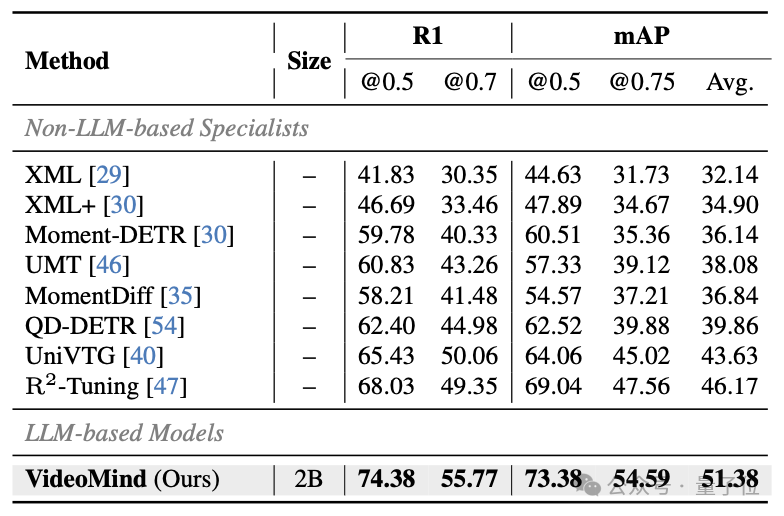 △表7:QVHighlights數據集的測試結果
△表7:QVHighlights數據集的測試結果(3)一般影片問答(General VideoQA)
對於通用的影片理解問題,VideoMind也表現出了強大的泛化能力。在Video-MME、MVBench、MLVU、LVBench、LongVideoBench等基準上,VideoMind得益於其Planner的設計,可以自適應地決定是否需要grounding,其性能超越了許多先進的影片問答模型,顯示了其在不同影片長度下的優越表現。
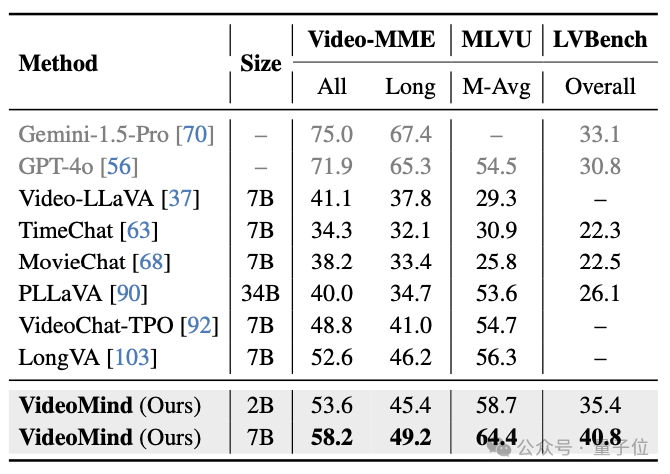 △表8:Video-MME、MLVU和LVBench數據集的測試結果
△表8:Video-MME、MLVU和LVBench數據集的測試結果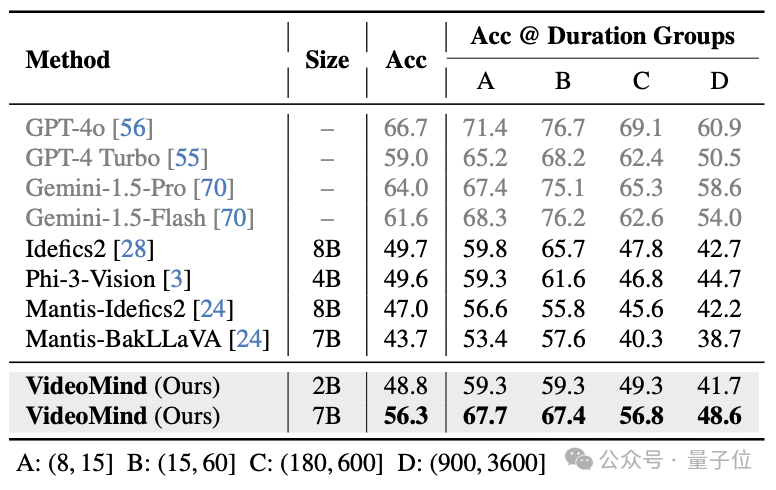 △表9:LongVideoBench數據集的測試結果
△表9:LongVideoBench數據集的測試結果以下例子展現了VideoMind在實際場景中的推理流程。給定一個影片和一個問題,該模型可以拆解問題、指定計劃、搜索片段、驗證結果,並根據獲取的片段推理最終答案。該策略相比傳統的純文字推理(左下部分)更加符合人類行為,結果也更加可靠。
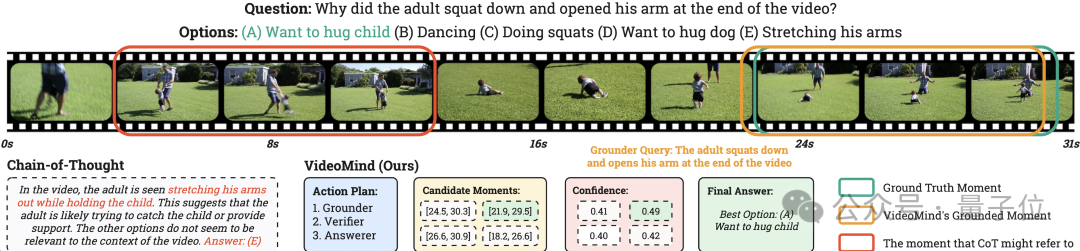 △圖6:VideoMind的推理流程可視化
△圖6:VideoMind的推理流程可視化總結
VideoMind的提出不僅在於影片理解性能的突破,更在於提出了一個模塊化、可擴展、可解釋的多模態推理框架。該框架首次實現了類似人類行為的「指定計劃、搜索片段、驗證結果、回答問題」流程,真正讓AI能「像人類一樣理解影片」,為未來的影片理解和多模態智能系統領域奠定了基礎。
項目主頁:https://videomind.github.io/
論文鏈接:https://arxiv.org/abs/2503.13444
開源代碼:https://github.com/yeliudev/VideoMind
開源數據:https://huggingface.co/datasets/yeliudev/VideoMind-Dataset
在線Demo:https://huggingface.co/spaces/yeliudev/VideoMind-2B
一鍵三連「點讚」「轉發」「小心心」
歡迎在評論區留下你的想法!