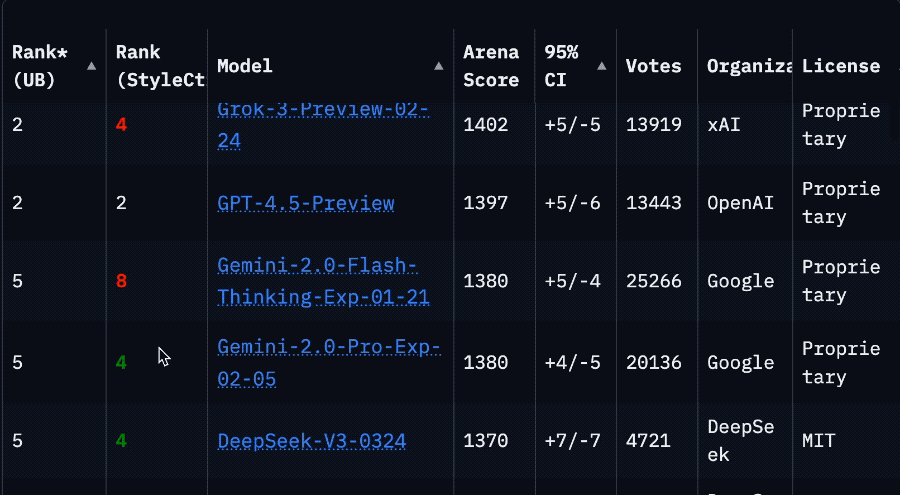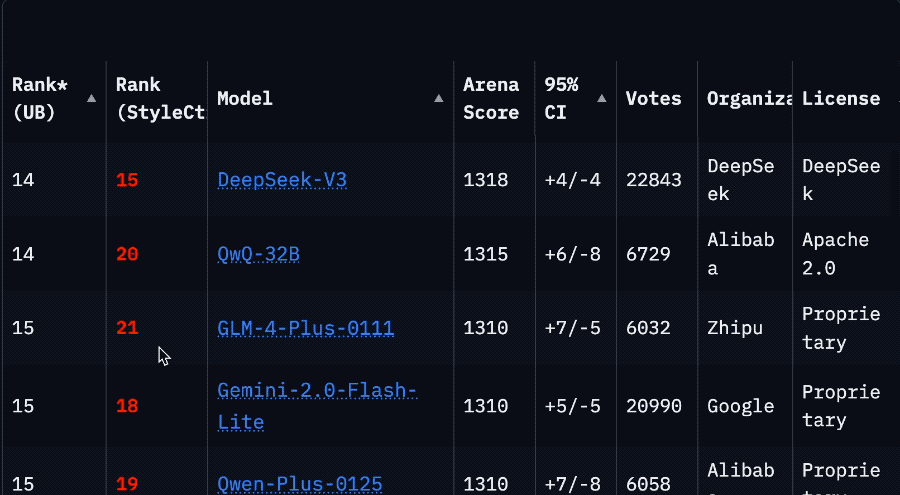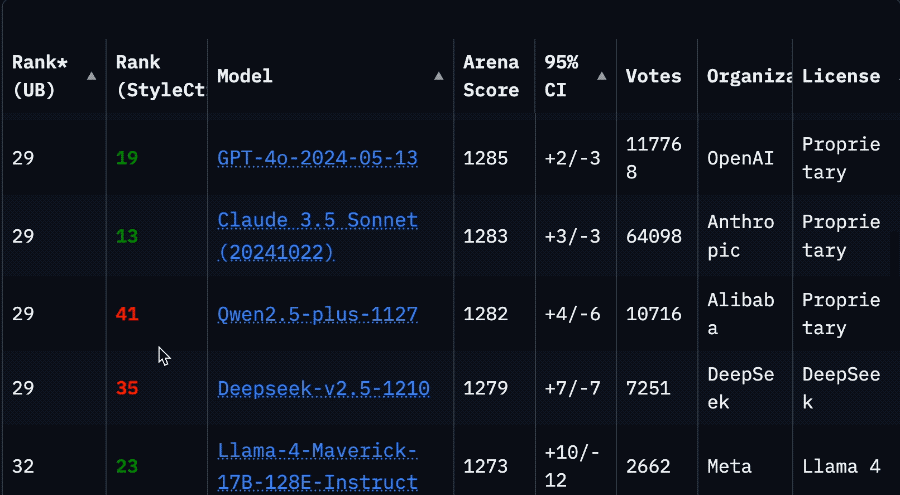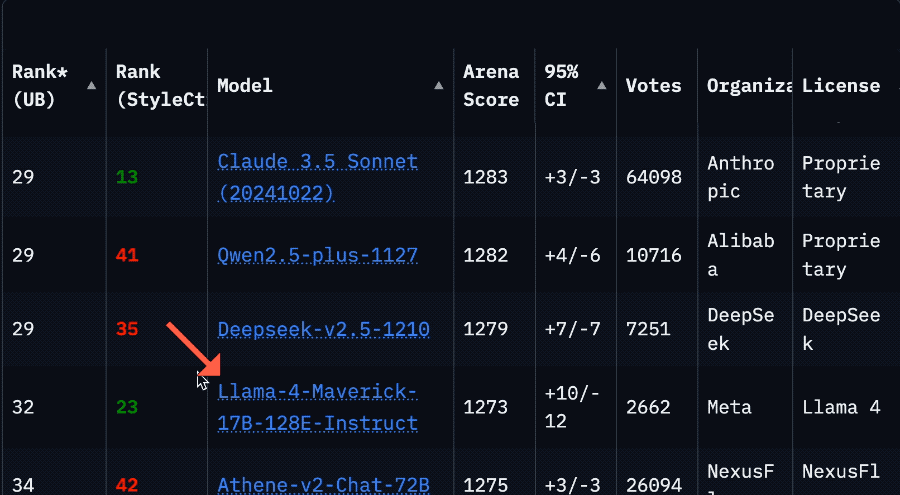
「再造一個CUDA」:英偉達的第二護城河與「超級碗」陽謀
英偉達2025年3月18日的GTC大會看似平淡,但魔鬼和驚喜都藏在細節中。
英偉達創始人兼CEO黃仁勳發佈的各項更新,包括芯片路線圖,此前已經被市場預期消化。在本次GTC之前,英偉達股價已經承壓多時,華爾街對接下來AI芯片需求的可持續性存在懷疑。而在整場演講中,黃仁勳也試圖打消外界的疑慮,但在當天,英偉達股價仍然下跌3.3%。

我們剛聽完黃仁勳的Keynote演講之後,第一反應也覺得好像不如去年那麼震撼和精彩,再加上演講中間PPT和流程還出現了各種小錯誤,讓整個演講不如去年那麼完美。
但結束之後我們跟一些機構投資人和芯片從業者深聊的時候發現,很多人對英偉達的發展路線和佈局還是非常看好,認為英偉達正繼續和競爭對手們甩開差距,雖然在宏觀層面上股價確實在近期受到多方面因素承壓。

這篇文章我們就和嘉賓們一起來聊聊在此次GTC上的觀察,並試圖來回答以下幾個問題:
1. 英偉達如何繼續擴寬它的護城河?
2. 在AI市場邁入「推理inferencing」階段,英偉達還能是市場上獨佔鼇頭的贏家嗎?AMD、Groq、ASIC芯片還有Google的TPU等等玩家有機會反勝嗎?
3. 英偉達如何佈局全市場生態,讓所謂的「每個人都成為贏家」?
4. 對於目前承壓的股價,英偉達的下一個故事是什麼?是機器人、還是量子計算呢?
一、橫向拓展與縱向拓展
黃仁勳在Keynote演講中數次強調:英偉達不是單張GPU芯片的敘事,而是所謂「Scale Up and Scale Out」更宏大的敘事。
黃仁勳說的Scale Up指的是「縱向擴展」,也就是通過NVLink通信互聯技術將單個系統的功能推到極致。

而Scale Out指的是「橫向擴展」,也就是通過這次發佈的矽光技術CPO(Co-packaged Optics,光電一體封裝交換機)等革命性技術更新,來進一步實現數據中心(data center)的巨大算力集群的快速擴張和提效。

而在AI邁入「推理」時代而對算力愈加渴望之際,英偉達「縱向」和「橫向」的擴展將打造新一代AI強大的算力生態和架構,這就是黃仁勳想講的新故事。
任揚
濟容投資聯合創始人:
老黃幾年前其實也在反復強調這個概念:以後計算單元不是GPU,甚至不是服務器,而是整個數據中心是一個計算單元。這是黃仁勳一直在試圖去推動的方向吧。
Chapter 1.1 Scale Up
在講縱向擴展前,我們先聊聊黃仁勳公佈的之後幾代芯片的路線圖。
在Keynote中,黃仁勳給出了非常清晰的英偉達長期路線圖,包括從當前的Blackwell到未來的Blackwell Ultra、Vera Rubin、Rubin Ultra,最終到2028年的Feynman架構。
每一代更新的芯片架構名字最後的數字,代表的是GPU的芯片數量,而每一個架構代表的是一個機架的整個性能。這個新命名方式也印證了黃仁勳想強調的敘事,已經從單個GPU變成了數據中心的算力集群系統。

2025年下半年出貨的Blackwell Ultra NVL72連接了72塊Blackwell Ultra GPU,它的性能提升是前代GB200的1.5倍(這裏要注意一下,黃仁勳在Keynote中又重新定義了「黃氏算法」:從Rubin開始,GPU數量是根據「封裝中的GPU數量」,而不是「封裝數量」來計算的;所以按新的定義,Blackwell Ultra NVL72算是有144個GPU)。
以天文學家Vera Rubin命名的新一代GPU將於2026年下半年推出。Vera Rubin NVLink144的性能將是Blackwell Ultra(GB300) NVL72的3.3倍。
英偉達預計Vera Rubin之後,下一代Rubin Ultra NVL576將於2027年下半年推出,其性能將是Blackwell Ultra(GB300) NVL72的14倍。

Rubin之後的架構代號為「Feynman」,以理論物理學家查德・費曼命名,這已經是2028年之後的故事了。
芯片從業人士告訴我們,英偉達的路線圖和性能提升幅度並沒有出乎外界的預期範圍,但黃仁勳傳達出的信號仍然非常積極,這就是:英偉達正在以及在未來幾年都會穩健地給客戶交付更好性能的產品。
David Xiao
CASPA主席
資深芯片從業者
ZFLOW AI創始人兼CEO:
其實在我們芯片行業,以英偉達這樣的節奏發佈產品,已經是執行力非常強了。一般芯片公司從一款產品到下一款產品,芯片研發可能需要兩年時間,再加上軟件適配,可能就需要3到4年才能推出下一代芯片和系統,所以英偉達的這個節奏已經非常厲害。
但這也會讓公眾的期望更高。比如去年年底的時候,Blackwell出現了散熱和良率的問題,股市上的反應是非常強烈的。但對我們業內人士來說,這些問題是非常正常的。重新mask tap out(掩膜流片),再修正就可以了。
任揚
濟容投資聯合創始人:
我覺得不管從產品的規劃、定義,到最後的落地執行,英偉達都是非常穩健、且領先對手的。但是如果和投資人的預期相比,確實沒有驚喜,也沒有意外。
以上就是黃仁勳所說的Scale Up(縱向拓展)的部分,也是嘉賓口中的與預期相同、沒有驚喜的部分。接下來我們聊聊讓大家驚喜的部分,也就是Scale Out(橫向擴展)的佈局。
Chapter 1.2 Scale Out
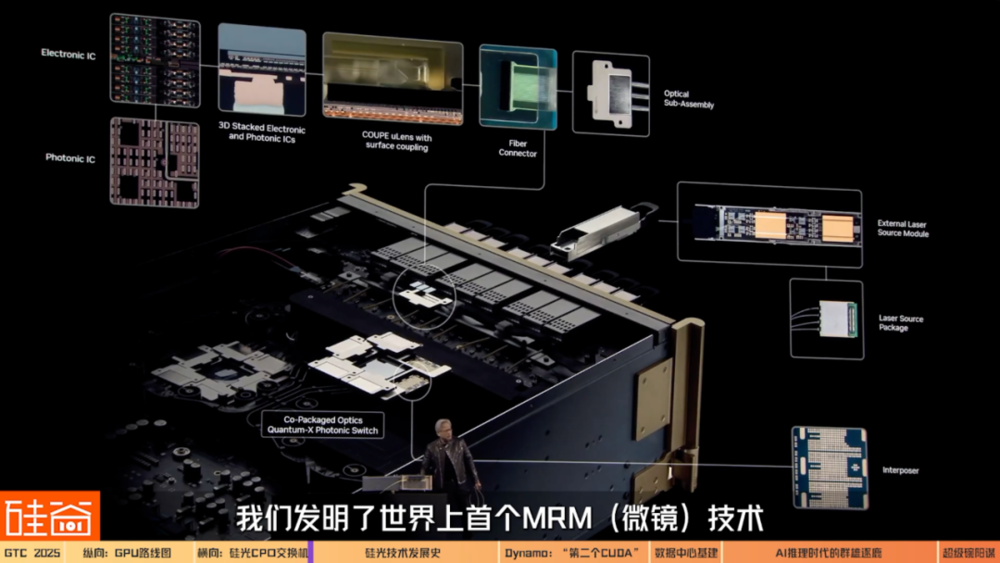
最能表現黃仁勳對「規模擴展」野心的,是採用集成矽光技術的NVIDIA CPO(Co-packaged Optics,光電一體封裝交換機)。

雖然老黃在演講中展示的時候這些黃色的線被纏在了一起,弄了好久才弄開,但也是挺有話題度的,讓大家對這幾根線更好奇了。
接下來我們聊聊,這幾根線是怎麼運作的?如何能讓英偉達的數據中心縱向擴展呢?

David Xiao
CASPA主席
資深芯片從業者
ZFLOW AI創始人兼CEO:
現在所有的Blackwell的機器,還是基於銅的互聯(Copper),之後會轉向光的互聯。

按照英偉達的說法,CPO交換機的創新技術,是將插拔式的光模塊替換為與ASIC(專用集成電路)一體化封裝的矽光器件。
與傳統網絡相比,可將現有能效提高3.5倍,網絡可靠性提高10倍,部署時間縮短1.3倍。這能極大程度增強英偉達數據中心的互聯性能,對於實現未來百萬級GPU的AI工廠的大規模部署來說至關重要。

匿名採訪
早期CPO光學科研人員:
OpenAI去年訓練4o的時候經常會訓練失敗,因為當時的Frontier model(前沿模型)已經基本窮盡了大部分的數據,所以訓練失敗的次數很多。訓練GPT-5失敗的次數也非常多,因為失敗的次數更多了,所以做需要做更多實驗,而且每次實驗的時間要儘可能短,公司是不能忍受一個實驗做兩個禮拜沒消息的。如何能縮短時間?那就是提高通訊的速度。

除了速度快之外,CPO交換機也能在能耗和價格上帶來很多成本的節省。在GTC現場,英偉達的工作人員展示了CPO實物是如何運作的。
Brian Sparks
英偉達工作人員:
這就是我們的新產品:Quantum-X光子交換機。 這款交換機採用了ASIC(專用集成電路),也是我們首次能夠實現矽光子技術的CPO(光電混合封裝)。過去需要一個光纖收發器用於連接網卡。但現在,光信號可以直接進入交換機的接口,不再需要光纖收發器。這樣做有兩個好處:首先降低了成本,因為光纖收發器價格相當昂貴;其次減少了功耗,因為傳統光纖收發器大約消耗30到33瓦的功率,而我們現在能夠將功耗降低到9瓦。

我們的採訪嘉賓認為,訓練側客戶在意的是時間,推理側客戶在意的是成本。而CPO技術能在一定程度上同時這兩種需求,提高訓練與推理的效率。
孫田浩
美國二級市場投資人
某新加坡聯闔家辦資深分析師:
你如果只有一個芯片,把它打造得再厲害也是沒有用的。本質原因是我們現在做推理、訓練,都是用幾萬個卡在一起的集群,比如Grok可能就一下就用 20 萬個卡一起訓練。重要的是怎麼能讓幾萬個、十萬個 芯片高效地協同運作。在這個互聯領域英偉達又再一次地領先了全球,因為它有CPO,它的機櫃上有各種各樣的新花樣。所以我覺得從長線來看,英偉達在推理集群領域的優勢也是更明顯的。
Brian Sparks
英偉達工作人員:
當進行推理時需要大量的計算資源,需要更多的計算能力,因此網絡需要具備儘可能高的帶寬,能夠在每個端口上提供更多的性能,同時保持極低的延遲。通過去掉光纖收發器,就能離這個目標更進一步,並能減少功耗。

Chapter 1.3 CPU發展史和早期八卦
關於CPO,我們在採訪期間還挖出一點點小八卦:黃仁勳在Keynote期間說CPO是他們發明的,但光學工程師們可能會有一些不同的意見。
我們採訪了非常早期的矽光技術CPO的研究者和業內從業者,他們表示,CPO這個技術從2000年左右在業界就已經開始研究了,而最開始主導這個技術的是英特爾。
匿名採訪
早期CPO光學科研人員:
當時我們提出來的這個技術叫做 Monolistic Integrated Phontonic IC(單片集成光子集成電路),那時候還不叫 Co-packaged Optics 。當時做這個事情是因為英特爾對Big Data(大數據)很感興趣。

這位資深的光學研究者告訴我們,大數據業務的驅動下,英特爾是20年前的矽光子學(Silicon Photonics)最大的研究支持機構。而之後發展出的CPO(Co-packaged optics)技術最早開始研發是為瞭解決光電系統短距離通信,也是光纖通信研究發展的必然結果。
而在行業發展過程中,除了英特爾,其它小型企業也在嘗試研發這項技術。但矽光子學技術的研發非常耗錢耗力,需要先有市場需求,才能倒逼技術研發。
以上是Nathan評測的一部分節選,想看完整版的觀眾可以收看矽谷101影片或Nathan的微信影片號「矽谷AI領航」。
匿名採訪
早期CPO光學科研人員:
最開始的時候,CPO應用是大數據,就是數據中心之間的通信。但數據中心之間的通信不需要那麼高的碼率,100G之內都不需要CPO。直到2012年,當時Apache Spark(開源集群運算框架)出現了,而且Snowflake開始快速發展,在這一年數據庫開始上雲了。這就意味著大量數據存在一個地方,而讀取和使用在另外一個地方,你需要做query(查詢),數據的移動就變得非常得複雜,量也變得非常大。這時100G在數據中心之間的溝通已經不夠用了,所以從2012年開始,Google提升到400G,到2020年疫情之前提到了800G。
如果現在同樣大的connector(連接器)要做 800G ,裡面的集成度就要高很多。當集成度高了後,光纖系統設計就非常複雜。需要解決功耗、一致性等等問題。但這兩個問題解決了以後,良率基本上是0。從100G到200G、 200G到400G、 400G到800G,每一代一出來良率都是0。而研發費用是非常貴的,基本是5個億以上。
以前沒有新的應用就不會去研發,現在有了新的應用,數據倉庫出現了,所以開始研發。在400G發展到800G的時候,Meta和Google的報告中已經開始廣泛地使用POP(package on package)和PIP(package in package)這兩個詞,其實跟今天Co-package的概念基本上很接近了。

為什麼矽光子技術的良率會這麼低,需要花費的研發費用又這麼高呢?
Cathy
光學工程師:
我們人的頭髮的尺寸大概是一個0.01平方毫米,已經是一個非常小的尺寸了。但在現實使用的Silicon Photonics Engine(矽光子引擎)裡面,Microring resonator(微環諧振器)的尺寸比人的頭髮還要再小十倍。
在製作的時候,哪怕是用非常先進的工藝,也很容易造成納米級別的誤差。而且即使是納米級別的誤差,都會使得通過的光的波長有所誤差。所以稍微一個不留神,就會導致本來該通過的光完全徹底通不過。
除此之外,我們需要精細到納米級別的加工精度的控制,降到一個納米基度的級別是非常困難的一件事情。
另外因為需要控制溫度,所以每一個Ring resonator(環形諧振器)都有自己的一個Heating Pad(加熱墊)。然後加熱墊連上一個精密的、有feedback(反饋)的溫度調控。而同時溫度調控又是一個時間的參數,因為光的通過速度非常快,所以需要一個非常精確、非常智能的溫度控制系統。而且每一個小的Micro resonator(微型諧振器)都需要這樣去調控,可以想像在一整個package(套件)裡面有這麼多的激光器,就需要非常複雜的一個溫度調控的算法。最終這一切加起來導致的效果就是,矽基光子的良率非常的低。

一位多年的從業者Mehdi Asghari和我提到過一句話:在電子製造之中,你不用提良率,因為良率都非常高,是99.999…(無數個9),只有良率高了大家才能賺錢。但在矽基光子的行業中也不用提良率,因為大家都知道良率非常低,稍微不小心就會導致良率崩盤。正是因為需要各種精確的控制,會讓良率非常低,這也導致了矽基光子的成本下不來。所以必須有個行業,既需要快速、精確的控制,又能接受高成本,才能讓矽基光子學發展起來。
陳茜
矽谷101影片主理人:
後來是怎麼把良率給提上去的呢?
Cathy
光學工程師:
行業一點一點的磨合。英特爾在2000年就開始做了,在這方面像行業的先驅。雖然老黃在矽基光子學並不是最早的,但是老黃為大家找到了非常好的應用,能讓這個技術應用在數據中心、AI大模型裡面,有了實在的用武之地。
根據嘉賓的說法,英偉達的光學通信系統技術,來自2019年收購的以色列芯片廠商Mellanox,而Mellanox的技術又源自於2013年收購矽光子公司Kotura。
以上我們大概講了講CPO技術的發展史,和業內從業者對老黃說「CPO是英偉達發明的」一點challenge(挑戰)。 也歡迎如果有矽光子產業的從業人員給我們留言說說你們對這個技術發展的八卦和故事。
不過,正是因為黃仁勳看到了CPO在AI數據中心大規模的應用,才又一次通過市場應用來支持技術研發,將這個技術帶到了大眾的面前。
匿名採訪
早期CPO光學科研人員:
如果LLM(大語言模型)只是千億美元級的市場的話,老黃根本就不會幹這個事,因為研發太貴了。但現在LLM到了萬億美元級的市場,老黃就認為有市場了,就跟我之前說的800G數據倉庫是一樣的。既然LLM來了(市場來了),且這是一個不違反物理定律的事情,那隻要錢堆得足夠多,不違反物理定律的事情都是能做成的。
雖然CPO技術不是英偉達獨家的,很多大公司都掌握了這個技術。但我們的嘉賓認為,英偉達在內部大力推進CPO技術整合到生態中,將CPO做到競品roadmap(路線圖)的數倍,用快速的執行和研發效率,進一步加深了生態的護城河和壁壘。

David Xiao
CASPA主席
資深芯片從業者
ZFLOW AI創始人兼CEO:
英偉達在光這塊其實投入也很大,招了很多人,也從各大公司都挖了不少人,會進一步加深壁壘。
因為其實有很多做矽光的公司可以做CPO的Module(模塊),但是如果要跟AI芯片合在一起做,那一定要找這些AI芯片出貨量最大的廠去合作。因為這裡面涉及到芯片跟矽光模塊codesign(共同設計) 的問題。而英偉達是in house(內部研發)的話,相比其他矽光公司跟AMD、Sarabas、Groq合作,會有很多的know-how(實際知識和性能)的優勢。

二、第二個CUDA
我們再來說說英偉達在軟件生態上的另外一個重要更新:Dynamo。這被我們的嘉賓認為是英偉達想在推理側造就的「第二個CUDA」。
黃仁勳
英偉達創始人兼CEO:
Blackwell NVLink72搭配Dynamo,使AI工廠的性能相比Hopper提升40倍。在未來十年,隨著AI的橫向擴展,推理將成為其最重要的工作內容之一。

黃仁勳宣佈在軟件方面,英偉達推出了Nvidia Dynamo。這是一款開源的AI推理服務軟件,被視為Nvidia Triton推理服務器的「接班人」,旨在簡化推理部署和擴展。而它的設計目標也很明確:以更高效和更低的成本來加速並擴展AI模型的推理部署。
簡單來說,Dynamo就像AI工廠中的「大腦和中樞」,負責協調成百上千張GPU的協同工作,確保每一次AI模型的推理請求都能用最少的資源、最快的速度得到處理,從而讓部署這些模型的企業花更少的錢去辦更多的事。
一些美股分析師認為:如果說CUDA是英偉達最強大的軟件生態護城河,那麼Dynamo就是英偉達在推理側想搭建的第二道護城河。

孫田浩
美國二級市場投資人
某新加坡聯闔家辦資深分析師:
英偉達60%以上的護城河都來自於軟件。這一次推出的Dynamo,相當於是在大模型AI領域又再造了一個CUDA。因為Dynamo是能給推理降本的,而且還開源了。Dynamo早期在未來新方向的佈局上和CUDA是一樣的;從長線來說,可能英偉達能再造一個CUDA,這對於它的在AI這個領域的護城河的幫助是非常強的。這是我比較看好的一個更新。
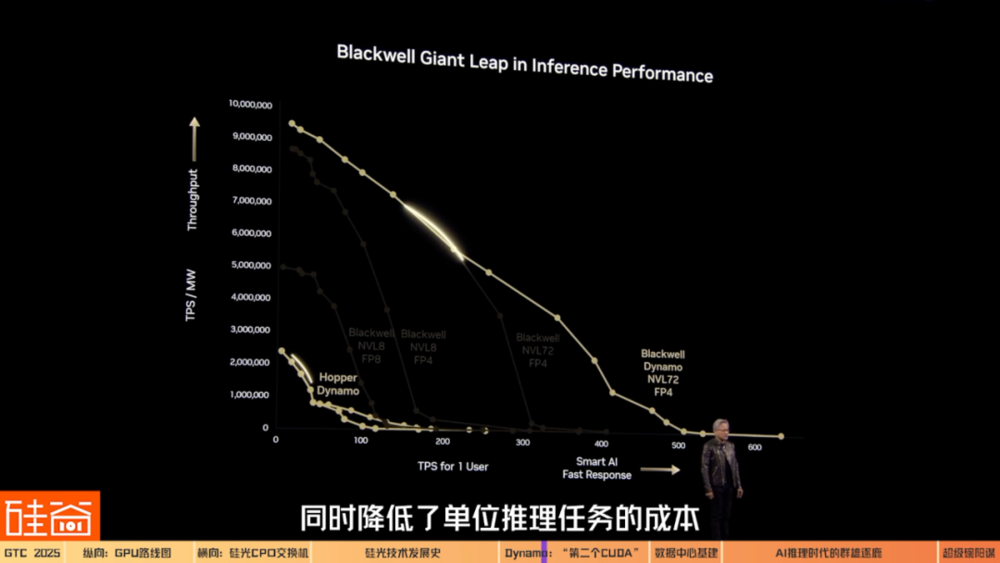
Dynamo帶來的最大亮點之一,就是大幅提升了推理性能和資源利用率,同時降低了單位推理任務的成本。
做一個類比,Dynamo就像一家餐廳的智能調度經理,在忙時能迅速增派更多廚師(也就是GPU)上灶,在閑時又讓多餘的廚師休息,不讓人力閑置,從而做到高效又節約。
根據英偉達官網,Dynamo包含了四項關鍵創新,來降低推理服務成本並改善用戶體驗。

1.GPU 規劃器 (GPU Planner):這是一種規劃引擎,可動態地添加和移除GPU,以適應不斷變化的用戶需求,從而避免GPU配置過度或不足。這就像我們剛才說的廚房遇到就餐高峰的時候,就加派廚師人手、加開新的廚房,而客人少的時候就關掉部分廚房,Dynamo希望確保GPU不閑著也不堵車,始終在最佳負載下運行。這樣每一塊 GPU 都被充分利用,集群整體吞吐量隨之提高。
2.智能路由器 (Smart Router):這是一個具備大語言模型 (LLM) 感知能力的路由器,它可以在大型 GPU 集群中引導請求的流向,從而最大程度減少因重覆或重疊請求,而導致的代價高昂的GPU重覆計算,釋放出GPU資源以響應新的請求。這有點像客服中心裡把老客戶直接轉接給之前服務過他的座席員,因為那位座席員已經有客戶的記錄(緩存),可以免去重覆詢問,更快給出回答。而Dynamo正是利用這種機制,將過往推理中產生並存儲在顯存里的「知識」 (KV緩存) 在潛在的數千塊 GPU 間建立索引映射,新請求來了就路由到握有相關緩存的 GPU 上。這樣一來,大量重覆的中間計算被省略,讓GPU 算力主要服務新的獨立請求。
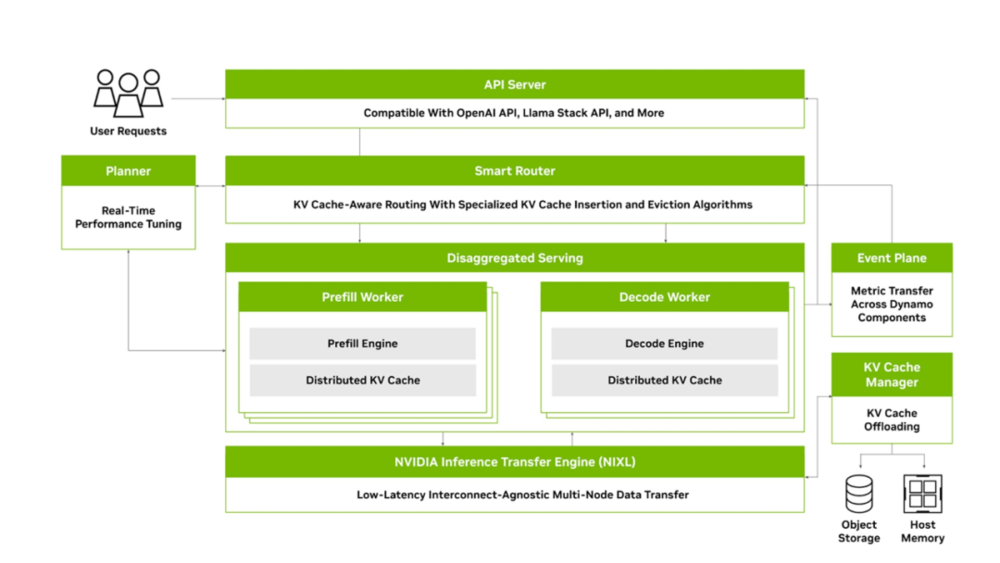
3.低延遲通信庫 (Low-Latency Communication Library):這個推理優化庫支持先進的GPU到GPU通信,並簡化異構設備之間的複雜數據交換,從而加速數據傳輸。
4.顯存管理器 (Memory Manager):這是一種可在不影響用戶體驗的情況下,以智能的方式在低成本顯存和存儲設備上,卸載及重新加載推理數據的引擎。這類似於把不常用的工具先放入倉庫,需要時再拿出來,留出昂貴的工作台空間(高性能顯存)給當前最緊要的工作。這種分層存儲和快速調取的策略,讓GPU顯存的利用更高效,推理成本能隨之下降。

而有了以上的這些優化路徑,黃仁勳想在AI逐漸轉向推理時代之際,讓英偉達依然保持AI芯片的霸主地位。
根據英偉達的官方數據,在相同數量的 GPU 下,使用NVIDIA Hopper架構的GPU跑的Llama大模型,在採用Dynamo後的整體推理性能和產生的結果數量直接翻倍,在由GB200 NVL72機架組成的大型集群上運行DeepSeek-R1模型時,Dynamo讓每張 GPU每秒能生成的token數量提升了超過30倍。

孫田浩
美國二級市場投資人
某新加坡聯闔家辦資深分析師:
英偉達在這條路上走得比其他人越來越遠了,所以我覺得它傳遞的Key Message(重要信息) 就是all in推理。它把所有的精力都花在推理這條線上,然後讓其他人追不上它。
在今年的Keynote中,老黃的名句也變了:從「The more you buy, the more you save」(買得越多,省得越多),變成了「The more you buy, the more you make」(買得越多,賺得越多)。

這意味著英偉達的AI數據中心已經準備好服務推理側的客戶,幫助客戶慳錢提效。也意味著,英偉達想在推理側繼續成為算力霸主。
三、數據中心基建
要配合這樣更大規模集群的建設,相關的數據中心基建和上下遊也需要隨之更新了。
上文我們提到過,芯片架構的取名方式更新,代表著黃仁勳對「集群」生態的強調,而非單芯片。而對應的,數據中心中的機架架構也將升級為「Kyber」,通過計算托盤旋轉90度,從而實現更高的機架密度。
Kyber 現場展示
這個是我們未來的Kyber Generation,是下一代產品。這就是一個72個GPU的GB200,總共有288個GPU(72*4) 。

除了機架的更新之外,整個數據中心的製冷、供電也都需要為新一代的芯片升級。
Mark Luxford
Vertiv工作人員:
正如黃仁勳在主題演講中宣佈的,我們將推出Vera Rubin和Vera Rubin Ultra(配套基建設施)。我們平時與英偉達的合作非常緊密,我個人每週與他們溝通四次,來共同製定了這代產品的參考設計。

每代產品都這意味著需要更高功率,會需要更強的冷卻能力,我們正在響應這一需求,同時確保系統架構和冷卻管道能夠正常運行,CDU(冷卻分配單元)能夠擴展以滿足新的需求。就比如我們已經把CDU從1兆瓦升級到了2.3兆瓦,這將非常適合Vera Rubin Ultra,能毫無壓力地處理600千瓦功率的機架。

這隻是系統的一部分,我們還需要重新設計風冷系統。我們會在機架級別的服務器中提取熱量,並通過CDU與設施電路進行熱量交換。然後通過雪藏機、冷卻塔、乾式冷卻器甚至通過熱泵將熱量排放到空氣或大氣中,或者將其用於城市供暖等用途。

矽谷101真正密切關注著數據中心的基建、電力系統、上下遊供應鏈等方向,未來會更深度地聊聊。
四、推理時代:群雄逐鹿還是單一霸主?
在AI訓練側,英偉達是絕對的霸主地位,但在AI進入推理側之際,AMD、Groq、GoogleTPU還有ASIC這些玩家有機會分掉英偉達的蛋糕嗎?
David Xiao
CASPA主席
資深芯片從業者
ZFLOW AI創始人兼CEO:
在2023年的時候,我們請黃教主到華美半導體協會,我當時還挑戰性地問了一個問題。因為我自己做AI芯片很多年,我就問他:GPU架構在很多應用場景下的效率其實不高,而我們在做各種定製的AI芯片,比如稀疏化的(Sparsity)、基於RISC-V的,或者像Cerebras這種基於wafer-scaling(晶圓微縮)的大芯片等,那我們是不是還有機會?老黃對於我這個問題的回答是:「大家都有機會,但是你們的機會不大。」
在我們採訪的嘉賓中,無論是投資人、還是芯片領域的人,對於「大家都有機會,但機會不大」這個結論都基本讚同。
原因是英偉達目前的生態已經太完整,護城河已經太高了,不僅僅是單個GPU的性能,而是整個大集群的高效聯通,以及CUDA軟件層面的優化和支持。並且如我們上文所說的,英偉達在領先對手的情況下,還在不停地加固新的護城河。

比如說大家非常關注的「千年老二」AMD,一直沒有能在AI GPU這方面取得突破性的市場份額,在過去一年,股價也下滑了超過40%。歸根結底,還是軟件方面追趕不上英偉達。
孫田浩
美國二級市場投資人
某新加坡聯闔家辦資深分析師:
AMD的MI300發的時候,對標的是英偉達的H100、H200。H100的內存是80G,但MI300直接是128G;MI350是192G,英偉達的B卡才190G。AMD不僅卡的內存高,而且還比英偉達便宜40%。雖然它參數看起來都很厲害,但我去測試的時候發現,AMD的實際的性能遠低於它寫的參數。
原因有兩個:第一,真的去開發、測試ROCm(AMD的軟件,CUDA的對標品)的時候,軟件全是bug(故障),根本就跑不通模型,推不出來。第二,AMD目前做得比較成熟的就是8張卡互聯,我都沒見到過64個卡互聯。但英偉達在2027年都要576個卡互聯了,這之間的差距已經沒辦法去彌補了。
更何況英偉達有NV Switch,AMD是沒有相應的芯片的,沒有做出類似成型的東西。AMD雖然有替代NVLink的東西,但是它穩定的效率是NVLink的二分之一。而沒有NV Switch它又做不了集群,只能8個卡互聯,所以我覺得在互聯的差距更大,更趕不上。
但並不是說AMD在一些特定的市場沒有機會。二級市場投資人們認為,客戶們不可能接受一家獨大,一定會給予AMD和其它芯片廠商一些機會。但在端模型起來之前,最大的份額可能依然會被英偉達所佔據。
而至於ASIC這樣的專用集成電路,雖然也會有它們特定的市場,但可能也佔據不了太多英偉達的份額。
David Xiao
CASPA主席
資深芯片從業者
ZFLOW AI創始人兼CEO:
AMD在大力推AI PC,包括也在推它的GPU。但是它推的方式,可能是去跟一些大模型的廠商直接合作,比如說某一個大模型在它這個場景下用得很好,而且這個應用場景又非常廣,那在這種情況下也是有機會的。

孫田浩
美國二級市場投資人
某新加坡聯闔家辦資深分析師:
AMD的故事是在三到五年以後,當端側的東西都起來了,C端的應用大模型的成本已經非常低的時候,比如一個電腦、一個GPU也可以去訓練大模型、做AI的時候。可以這麼理解,在GPU這個領域,除了英偉達以外,只有AMD配在這個市場上活著,所以它就能吃那些中長尾的份額。
陳茜
矽谷101影片主理人:
Groq呢?ASIC呢?他們不配活著嗎?

孫田浩
美國二級市場投資人
某新加坡聯闔家辦資深分析師:
ASIC落地的難度是非常高的,而且通用性很窄。第一是它量產很難,Google的TPU核心計算單元的transistor(晶體管),大小比英偉達要大2~4倍,背後的原因是它設計能力的不足,而芯片做大後,會導致良率下降,所以Google的TPU的良率90%都不到,英偉達的可能是99%,結果就是TPU量產很難,很多時候只能滿足大廠一兩個需求。
第二,ASIC的核心是根據客戶的業務來設計芯片,當然中間很複雜,需要先瞭解客戶的業務、知道客戶的是代碼怎麼寫的,再根據這些代碼去設計硬件的芯片。Google的芯片只能在Google的生產里用,亞馬遜的芯片只能在亞馬遜的生產里用。

所以我覺得未來的推演,ASIC和GPU是共存的。英偉達會拿絕大部分通用的計算需求,然後ASIC它可能會拿走一些大廠部分的業務場景。比如Google有那麼多TPU,但是它也採購了大量的英偉達的卡,因為它那些英偉達的卡是要用到它自己的雲上面給客戶用的,它的TPU只用在訓練或者搜索上,應用場景還是比較局限的。
所以看起來,就像老黃說的,無論在訓練側還是在推理側,「大家都有機會,但機會不大」。英偉達不可能吃掉整個算力蛋糕,特別是當我們進入推理時代,出現越來越杜特定環境的應用需求,越來越多端側的需求,這時候市場是足夠大的,能容忍多個玩家。

任揚
濟容投資聯合創始人:
如果咱們只從這個算力的一個角度來說,我覺得Inference(推理)的競爭會比Training(訓練) 更激烈。如果把這個視角放大一點的話,Nvidia其實不是在和AMD、Groq或者ASIC這些去競爭,它其實是在和雲計算廠商去競爭,比如Amazon、Microsoft,而算力是這裡面非常重要的一個子戰場。
David Xiao
CASPA主席
資深芯片從業者
ZFLOW AI創始人兼CEO:
老黃有個策略是,可以用上一代的舊卡做推理,新一代卡做訓練。因為舊卡有折扣了,跟其他AI芯片公司在推理場景中競爭時是有優勢的。同時對很多人來說,如果訓練跟推理的軟件框架是一致的,後面軟件部署的成本也會降低,這也是英偉達舊卡在推理市場的優勢。
英偉達有很多的打法,它可以去定製推理卡。也可以在產能受限的情況下,只用舊卡來做推理,針對訓練做這種又大、又能夠橫向拓展的新卡。老黃手裡面的牌還是非常多的,完全可以選擇做或者不做ASIC。
業內人士們依然對英偉達的護城河和市場優勢抱有非常大的信心,但同時我們確實也感覺到,英偉達的股價在最近受到不少壓力。有美股機構投資人對我們表示,除了宏觀大環境的壓力之外,GPT-5這樣的大模型性能表現依然是影響市場的重大因素。
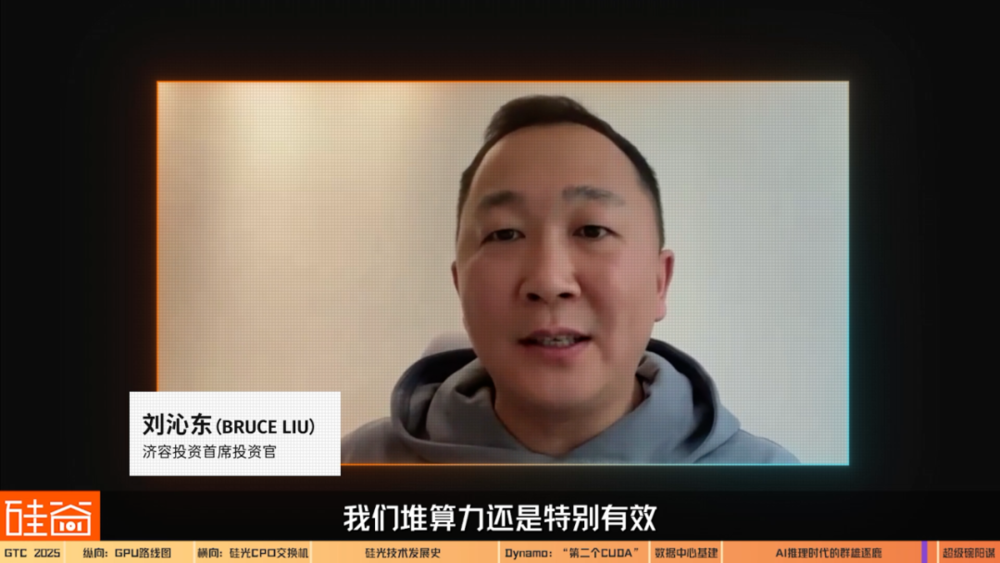
劉沁東
濟容投資首席投資官:
因為投資人都是一幫簡單粗暴的人,我覺得能夠給投資人信心的,就是GPT-5出來後,讓大家看到:堆算力還是有效,而且把模型帶到了下一個境界。那英偉達的股價可能就又都衝回來了。如果沒有的話,我覺得要花相當長一段時間,讓世界理解了英偉達在生態鏈中的重要性,英偉達的股價才會慢慢到它該有的位置。

五、全生態超級碗模式
我們此前的數期節目都提到,黃仁勳是一個眼光非常長遠的CEO。而他這次傳遞出的一個重要信號,就是「全生態佈局」:今後任何一個需要加速計算的領域,他都不會錯過。

讓我們記憶很深刻的是:在這一次的演講當中,黃仁勳背後出現這一排像塔羅牌一樣的全生態佈局,標題是「為每一個產業服務的CUDA-X」。包括數值計算、計算光刻、5G/6G 信號處理、決策優化、基因測序、醫學成像、天氣分析、量子計算、量子化學、深度學習、計算機輔助工程、數據科學和處理、物理學等等。
其中,量子計算、自動駕駛和機器人賽道中的仿真平台和算法,也是英偉達目前著重佈局的方向。總的結論是:黃仁勳不會放過任何一個需要算力的市場。
而黃仁勳也發出了很強勁的信號,他說2024年GTC大會就像一個Rock Concert,一個秀肌肉、炫酷的搖滾音樂會。而2025年的GTC大會是美國橄欖球Super Bowl(超級碗)。因為Super Bowl號稱「美國春晚」,裡面的所有人,包括兩個參賽的隊伍、廣告商、轉播商、觀賽遊客,每個人都是贏家。
黃仁勳講的「全生態超級碗模式」的故事是「Nvidia is gonna make everyone a winner.」也就是說,在英偉達生態中每個人都是贏家。

黃仁勳
英偉達創始人兼CEO:
我們製定了一套年度路線規劃圖供大家參考,以便大家更好地規劃建設AI基礎設施。同時,我們正在構建三大AI基礎設施:雲端AI基礎設施、企業級AI基礎設施以及機器人AI基礎設施。

黃仁勳預測2028年數據中心支出將會突破1萬億美元,而到那時,AI生態會如何發展?英偉達的霸主地位,是否如我們節目中嘉賓們預測的那樣將持續保持?而剩下的蛋糕中又會有什麼新機會?矽谷101會持續為大家關注未來的動向。
本文來自微信公眾號:矽谷101,作者:陳茜