雙人動作生成新SOTA!浙大提出TIMotion框架 | CVPR 2025
TIMotion團隊 投稿
量子位 | 公眾號 QbitAI
雙人動作生成新SOTA!
針對Human-human motion generation問題,浙江大學提出了一種對雙人運動序列進行時序和因果建模的架構TIMotion,論文已發表於CVPR 2025。

具體來說,通過分別利用運動序列時間上的因果關係和兩人交互過程中的主動被動關係,TIMotion設計了兩種有效的序列建模方式。
此外還設計了局部運動模式增強,使得生成的運動更加平滑自然。
同一提示詞下,使用TIMotion和當前SOTA方法Intergen對比如下:
(翻譯版)這兩個人傾斜著身子,面對面,玩起了石頭剪刀布。與此同時,有一個人選擇出布。

仔細對比手部動作,可以看出TIMotion的生成效果更好。
除此之外,實驗結果顯示,TIMotion在InterHuman和InterX數據集上均達到了SOTA效果。
下面具體來看。
全新瞄準雙人動作生成
在生成式計算機視覺領域,人類動作生成對計算機動畫、遊戲開發和機器人控制都具有重要意義。
近年來,在用戶指定的各種條件的驅動下,人類動作生成技術取得了顯著進步。其中,許多利用大語言模型和擴散模型的方法得益於其強大的建模能力,在生成逼真而多樣的動作方面取得了令人矚目的成果。
儘管取得了這一進展,但現有的大多數方法主要是針對單人運動場景而設計的,因此忽略了人體運動的一個關鍵因素:人與人之間複雜而動態的互動。
為了更好地探索雙人動作生成,研究團隊首先抽像出了一個通用框架MetaMotion,如圖1左側所示,它由兩個階段組成:時序建模和交互混合。
以往的方法優先考慮的是交互混合而非時序建模,主要分為以下兩類:
-
基於單人生成方法的擴展
-
基於單人建模的方法
如圖(a)所示,基於單人生成方法的擴展會將兩個人合併成一個人,然後將其輸入現有的單人運動生成模塊之中。基於單人建模的方法如圖(b)所示,是對兩個個體單獨建模,然後分別使用自我注意和交叉注意機制,從兩個個體自身和對方身上提取運動信息。
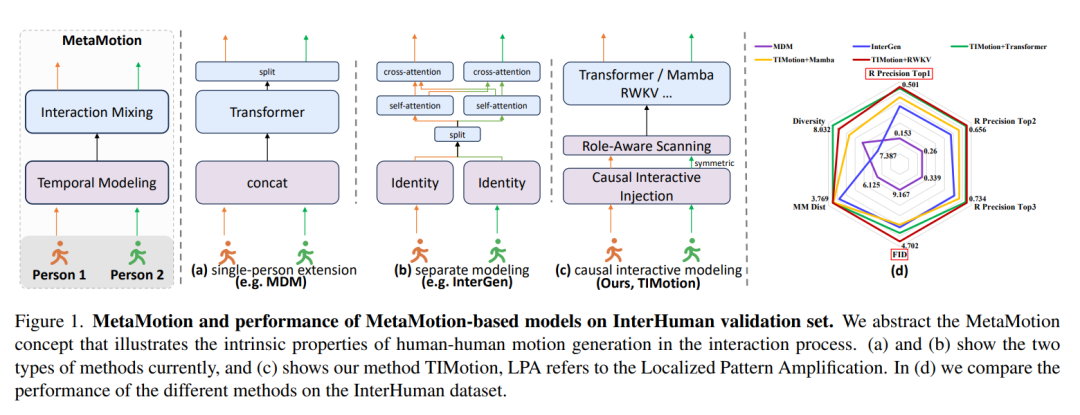
按照MetaMotion的一般邏輯,團隊提出了 「時空交互框架」(Temporal and Interactive Framework),如圖(c)所示,該框架模擬了人與人之間的因果互動,這種有效的時序建模方法可以簡化交互混合模塊的設計,減少可學習參數的數量。
提出雙人動作生成架構TIMotion
團隊首次提出了用於雙人動作生成的核心概念 「MetaMotion」。
如上圖所示,他們將雙人運動生成過程抽像為兩個階段:時序建模和交互混合。
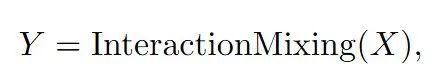
其中,InteractionMixing通常是Transformer結構,包括自注意和交叉注意機制。
值得注意的是,InteractionMixing也可以是一些新興結構,比如Mamba、RWKV等等。
TIMotion
TIMotion的整體架構如下圖所示,主要包含三個部分:(1) Causal Interactive Injection; (2) Role-Evolving Scanning; (3) Localized Pattern Amplification。
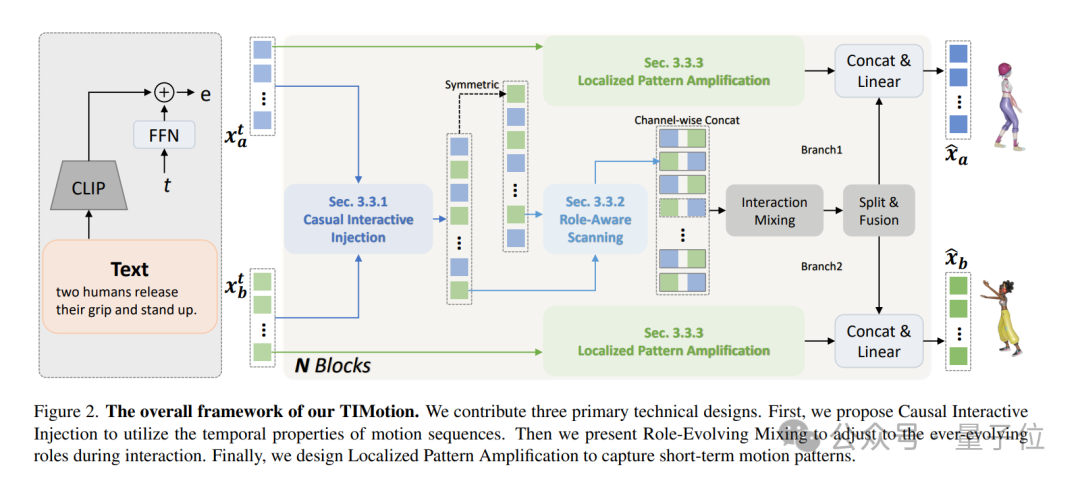
Causal Interactive Injection
運動的自我感知以及與他人運動的交互感知是雙人運動生成的關鍵要素。
考慮到運動的因果屬性,團隊提出了 「因果互動注入」(Causal Interactive Injection)這一時序建模方法,以同時實現對自我運動的感知和兩人之間的互動。
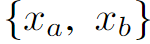
表示兩個單人運動序列,其中
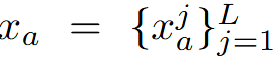
和
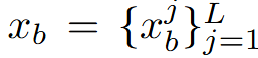
是各自的運動序列,L是序列的長度。
由於兩個人在當前時間步的運動是由他們在之前時間步的運動共同決定的,因此團隊將兩個人的運動序列建模為一個因果交互序列
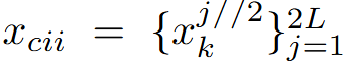
,符號 // 表示除法後四捨五入,k可以通過下式獲得:
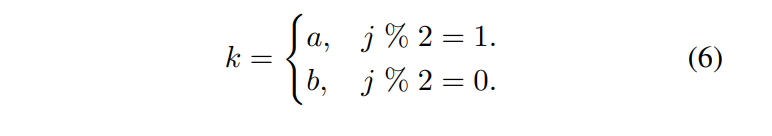
然後,團隊可以將它們注入交互混合模塊,並根據k的定義將兩個個體的動作特徵從輸出結果中分離出來。
Role-Evolving Scanning
人類在交互過程中通常存在一定的內在順序,例如,「握手」通常由一個人先伸出手,這意味著交互動作可以被分為主動運動和被動運動。
一些方法將文本描述分為主動和被動語態。
然而,隨著互動的進行,「主動方」和「被動方」不斷在兩人之間交換,如圖3所示。
為了避免冗餘的文本預處理並且適應角色的不斷變化,論文設計了一種高效且有效的方法:角色演變掃瞄(Role-Evolving Scanning)。
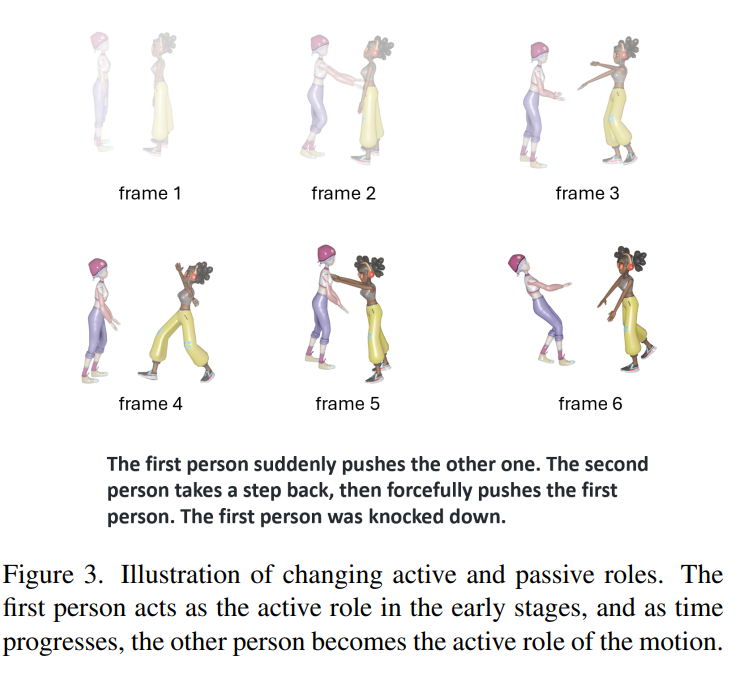
對於在Causal Interactive Injection中定義的因果交互序列x,顯然a和b分別代表了主動方運動序列和被動方運動序列。然而這種關於主動和被動序列的假設並不總是符合實際順序。
為了應對角色的變化,論文將因果交互序列重新建模為對稱因果交互序列
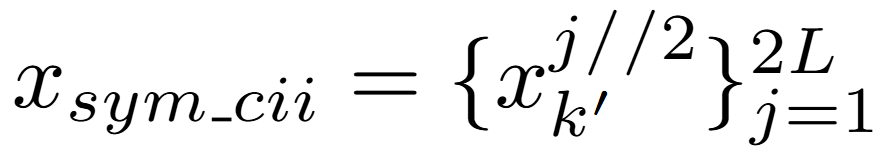
,k’由下式得到:
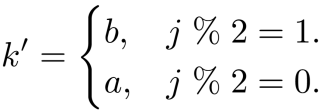
給定因果交互序列和對稱因果交互序列,論文通過角色演變掃瞄得到最終的雙人交互序列:
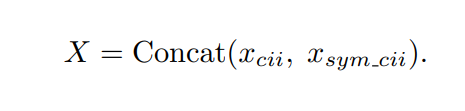
然後序列X被送入交互混合模塊得到動作的特徵。
接下來,分別按照特徵通道和時間的維度將兩個人的特徵取出,並按照元素相加得到兩人交互後的最終特徵,特徵split和fuse過程如下式:
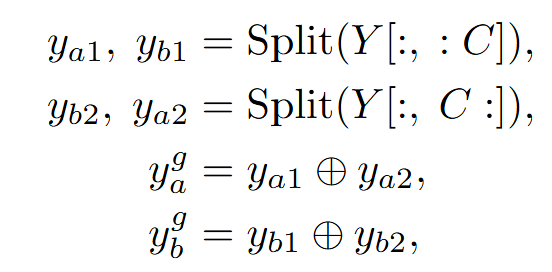
其中表示按元素相加。
通過利用 「角色演變掃瞄 」技術讓兩個人同時扮演主動和被動角色,網絡可以根據文本的語義和動作的上下文動態調整兩個人的角色。
Localized Pattern Amplification
因果交互注入和角色演變掃瞄主要基於雙人互動之間的因果關係來建模整體運動,但忽視了對局部運動模式的關注。
為瞭解決這個問題,論文提出了局部運動模式增強(Localized Pattern Amplification),通過捕捉每個人的短期運動模式,使得生成更加平滑和合理的運動。
具體來說,論文利用一維卷積層和殘差結構來實現局部運動模式增強。給定條件嵌入和兩個單人的運動序列,可以建立下式的結構:
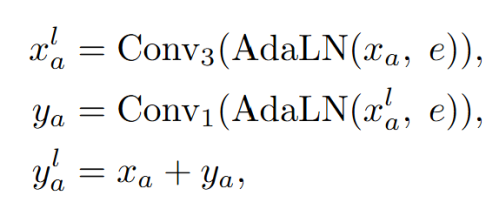
其中Convk表示卷積核為k的一維卷積,AdaLN為自適應層正則化。
和局部輸出
後,兩者通過特徵通道維度的進行Concat,然後通過線性層對特徵進行轉換,得到最終輸出特徵:
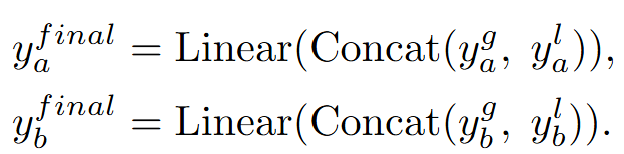
通過這種方式,能夠捕捉每個人的短期動作模式,並將其與條件嵌入結合,從而生成更平滑和更合理的動作序列。
目標函數
論文採用了常見的單人動作損失函數,包括足部接觸損失和關節速度損失。
此外,還使用了與InterGen相同的正則化損失函數,包括骨長度損失、掩碼關節距離圖損失和相對方向損失。
最終,總體損失定義為:
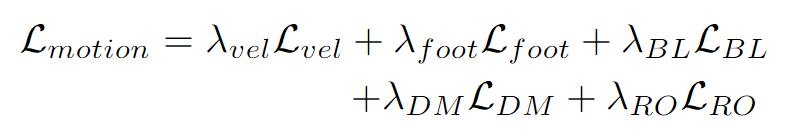
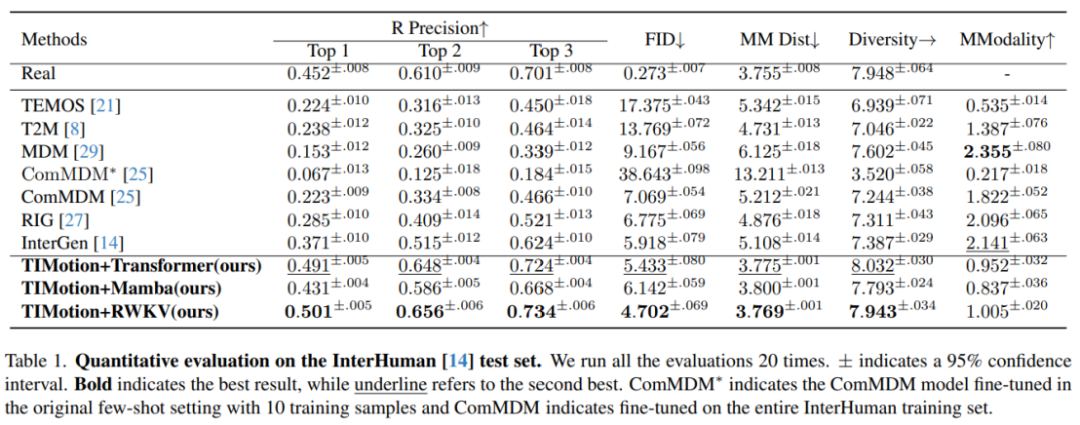
實驗結果
在InterHuman數據集上,TIMotion在三個不同的交互混合結構(Transformer, Mamba, RWKV)上都獲得了較好的表現,其中TIMotion和RWKV結構相結合FID達4.702,Top1 R precision達到0.501,達到了SOTA。
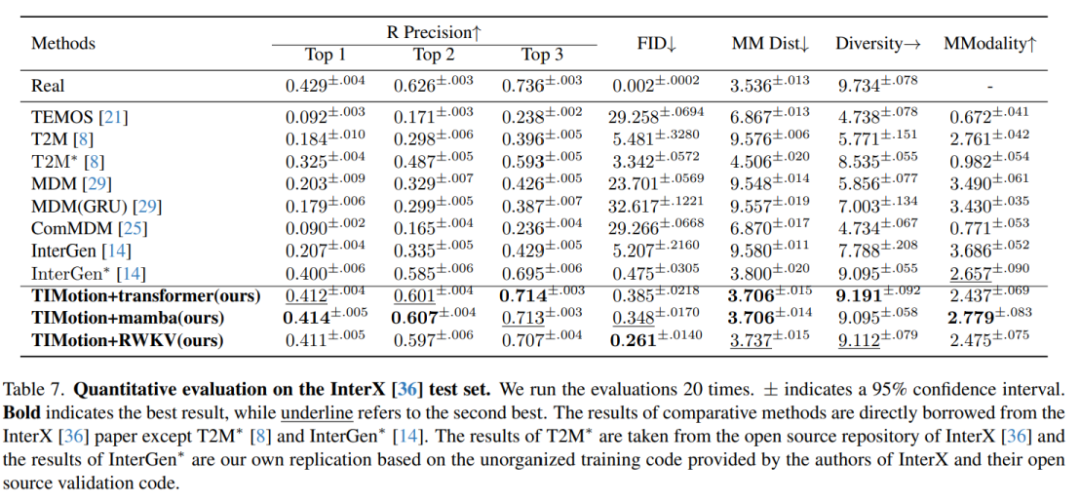
在InterX數據集上,TIMotion在R precision,FID, MM Dist等度量指標上也達到了最優的表現。
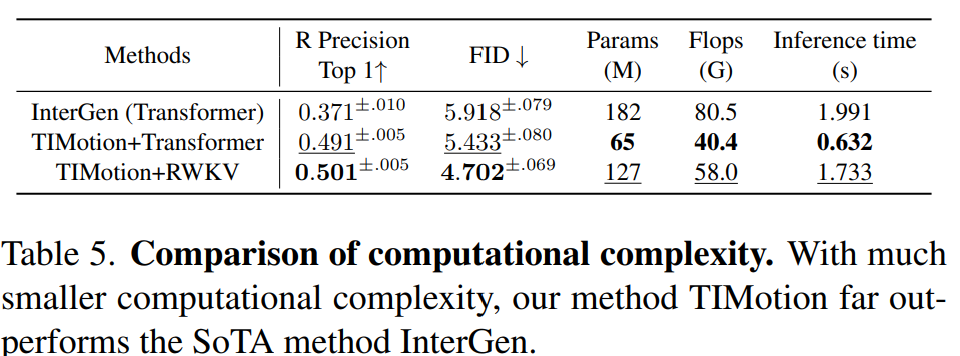
在計算複雜度方面,論文將TIMotion與當前最先進的方法InterGen進行了比較。
與InterGen相比,TIMotion所需的參數和FLOPs更少,但在綜合指標FID和R Precision方面優於InterGen。
值得注意的是,使用與InterGen類似的Transformer架構,TIMotion每個樣本的平均推理時間僅為0.632秒,而InterGen則需要1.991秒。
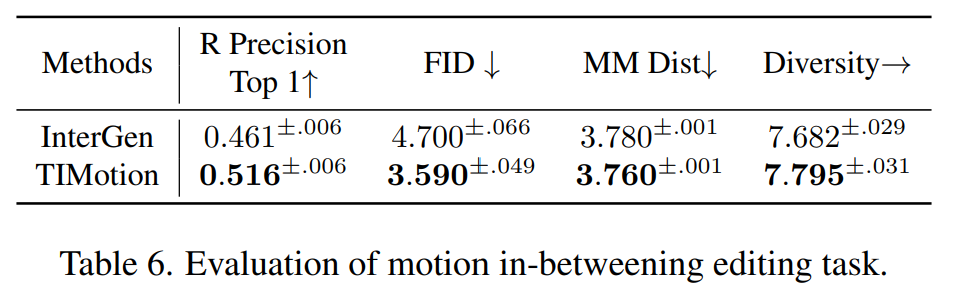
論文在InterHuman的測試集上進行了運動編輯的實驗,通過給定序列的前10%和後10%幀讓模型預測額外80%幀的序列來進行評估方法的可編輯性。
Table 6顯示了TIMotion在運動插值編輯任務中,在所有度量指標上都超越了InterGen。
總結
論文將雙人運動生成過程抽像為一個通用框架MetaMotion,其中包括兩個階段:時間建模和交互混合。
研究發現,由於目前的方法對時序建模的關注不足,導致次優結果和模型參數冗餘。
在此基礎上,團隊提出了TIMotion,這是一種高效、出色的雙人運動生成方法。
具體來說,他們首先提出了Causal Interactive Injection,利用時序和因果屬性將兩個獨立的擔任序列建模為一個因果序列。
此外,還提出了Role-Evolving Mixing來適應整個互動過程中的動態角色,並設計了Localized Pattern Amplification來捕捉短期運動模式,從而生成更平滑、更合理的運動。
TIMotion在兩個大規模雙人運動生成的數據集InterHuman和InterX上均達到了SOTA的效果,證明了論文所提出方法的有效性。
因此,TIMotion為Human-human motion generation提供了一個有效的解決方案。
論文:
https://arxiv.org/abs/2408.17135
項目主頁:
https://aigc-explorer.github.io/TIMotion-page/