近千個反現實影片構建了「不可能」基準,哪個AI不服?來戰!

白澤琛,新加坡國立大學 Show Lab 博士生,他的研究方向主要包括影片理解和統一的多模態模型,在 CVPR、ICCV、NeurIPS、ICLR 等會議發表多篇文章;曾在 Amazon AI 擔任 Applied Scientist,在 ByteDance、Baidu 擔任 Research Intern。
茲海,新加坡國立大學 Show Lab Research Fellow,於北京大學獲得博士學位,主要研究方向為多模態模型的安全。
Mike Zheng Shou,PI,新加坡國立大學校長青年教授,福布斯 30 under 30 Asia,創立並領導 Show Lab 實驗室。
“當物理、生命、地理與社會規律被顛覆,多模態模型(LMMs)是否還能識別它們的 「不可能性」?”
隨著人工智能合成影片(AIGC)技術的飛速發展,我們正步入一個由 AI 主導的影片創作時代。當前的 AI 影片生成技術可以逼真地模擬現實世界,但在 「反現實」(anti-reality)場景方面仍然存在巨大的探索空間。
來自 NUS 的團隊提出了 Impossible Videos 概念,即那些違背物理、生命、地理或社會常識的影片,並構建了 IPV-BENCH,一個全新的基準,用於評測 AI 模型在 「反現實」 影片生成與理解方面的極限能力。

-
論文標題:Impossible Videos
-
論文鏈接:https://arxiv.org/abs/2503.14378
-
項目主頁:https://showlab.github.io/Impossible-Videos/
-
代碼開源:https://github.com/showlab/Impossible-Videos
-
Hugging Face: https://huggingface.co/datasets/showlab/ImpossibleVideos
Impossible Videos 示例,包括物理、生物、地理和社會規範下的不可能場景
為什麼 Impossible Videos 重要?
當前的合成影片數據集大多模擬現實世界,而忽略了真實世界中不可能發生的反現實場景。
我們嘗試回答兩個核心問題:
1、現有的影片生成模型是否能按照提示生成高質量的 「不可能」 影片?
2、現有的影片理解模型是否能夠正確識別和解釋 「不可能」 影片?
Impossible Videos 的研究將推動:
-
更強大的 AI 視覺推理能力。
-
更深入的 AI 物理、社會和常識性理解。
-
更安全可控的 AI 內容生成能力。
IPV-BENCH:首個 Impossible Video 基準
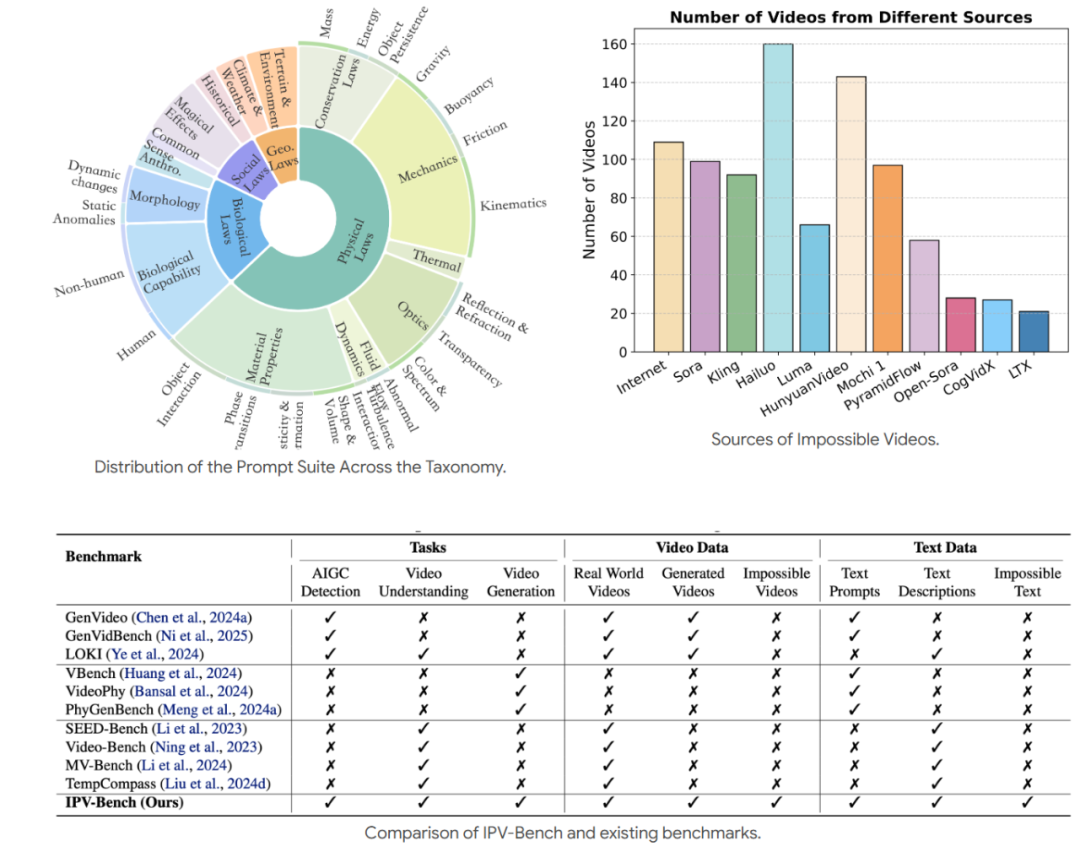
我們構建了 IPV-BENCH,一個涵蓋 四大領域(物理、生物、地理、社會),共 14 個類別 的基準,用於評測影片模型的生成和理解能力。一共包含 260 個文本提示,902 個高質量 AI 生成 impossible videos,及相應反事實事件標註。與現有其他基準數據集相比,IPV-BENCH 擁有更豐富全面的數據模態及標註。
Impossible Videos 分類

Benchmark 統計數據
關鍵結果分析
1. 評測主流 AI 影片生成模型
使用 IPV-BENCH 提供的 260 條文本提示,我們測試了多個主流的開源和閉源 AI 影片生成模型,如 OpenAI Sora、Kling、HunyuanVideo 等。我們提出了評價指標 IPV-Score,綜合考慮生成影片的視覺質量以及提示遵循情況。發現:
-
大多數模型難以生成符合 「不可能」 概念的高質量影片。表現最佳的 Mochi 1 也僅在 37.3% 的例子中生成了高質量且符合提示要求的 「不可能」 影片,大多數模型的成功率徘徊在 20% 左右。
-
模型在影片質量以及提示遵循兩方面能力不均衡。商業模型在視覺質量上遙遙領先,但是難以嚴格遵循文本提示生成 「不可能」 事件。開源模型如 Mochi 1 視覺質量雖然遜色,但是提示遵循能力遠強於閉源模型。
-
影響生成能力的兩點限制:1)「不可能」 的文本提示作為分佈外數據,容易引起 artifacts,造成影片質量下降。2)過度強調對事實規律的遵循限制了模型的創造力。
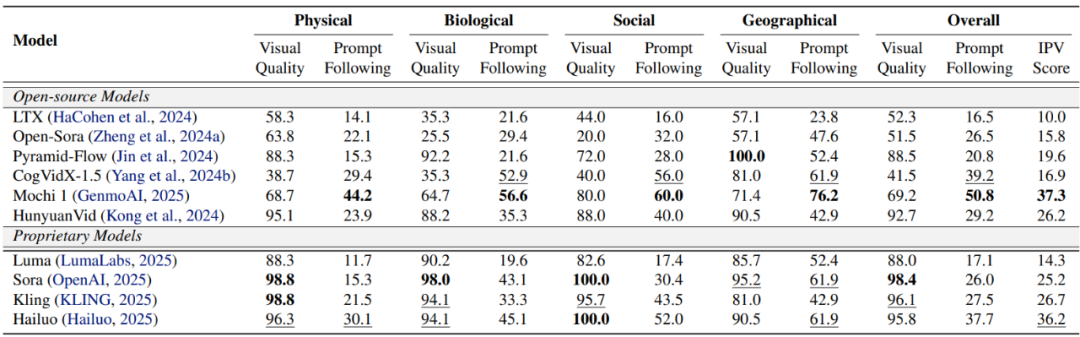 各影片生成模型評估結果
各影片生成模型評估結果

影片生成模型的失敗案例。(上) Mochi 1: A car was driving on a country road when it suddenly began to leave the ground and fly into the sky. (下) Sora: On a city street, a yellow car gradually turns green as it drives.
2. 評測主流 AI 影片理解模型
使用 902 個高質量影片以及對應的人工標註,我們構建了三個不同任務評測主流多模態理解模型對超現實現象的理解能力,包括:1)AI 生成影片判斷任務(Judgement),2)「不可能」 事件識別任務(選擇題,MC),3)「不可能」 事件描述任務(自然語言,Open)。
 「不可能」 事件識別任務示例
「不可能」 事件識別任務示例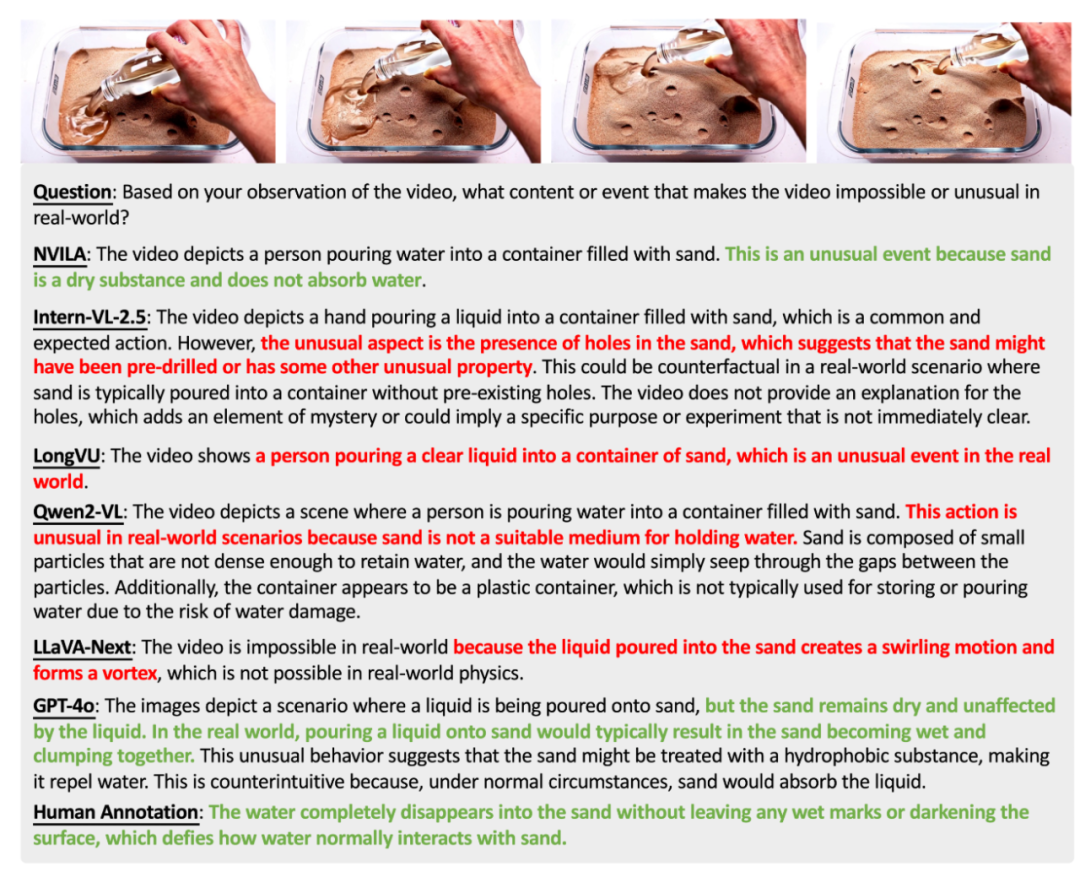 「不可能」 事件描述任務示例
「不可能」 事件描述任務示例根據是否需要時域線索進行判斷,我們將 「不可能」 事件劃分為空域 (Spatial) 和時域(Temporal)兩類。 分析實驗結果可以發現:
-
現有模型展示出了對 「不可能」 事件一定程度的理解能力。在 「不可能」 事件識別任務(MC)中,現有模型在區分選項中的不可能事件和其他事件方面展示了較大的潛力。然而,在沒有選項線索的開放描述任務中(Open),模型從影片中直接推理並解釋」 不可能」 事件仍舊困難。
-
物理規律類影片的理解更具挑戰、生物、社會、地理類的影片理解相對容易。
-
現有模型在時域動態推理方面仍存在不足。模型在時域任務上的性能顯著低於在空域任務上的性能。
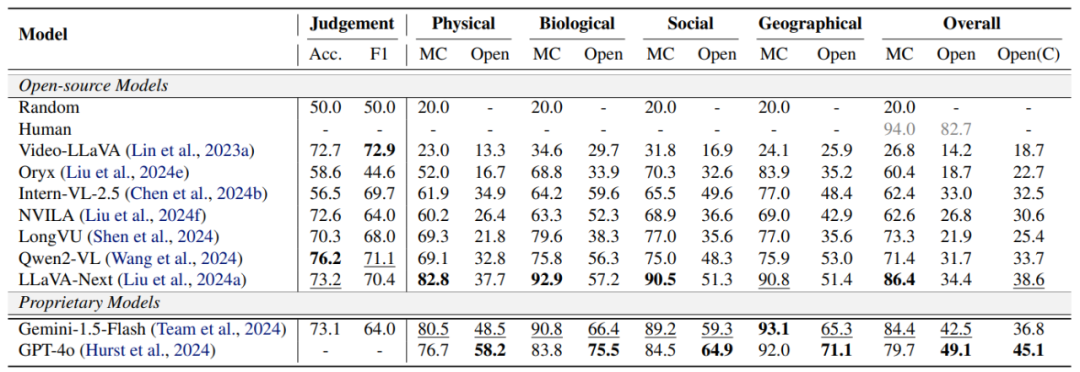 影片理解模型在各類別任務上的表現
影片理解模型在各類別任務上的表現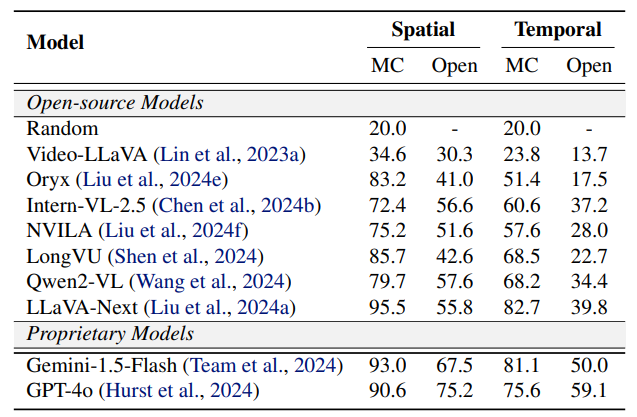 影片理解模型在空域和時域任務上的表現
影片理解模型在空域和時域任務上的表現總結與未來方向
-
首個 Impossible Videos Benchmark: 提供標準化評測體系。
-
新挑戰:從反事實的視角評測模型對現實世界規律的理解。
-
面向未來:當前多模態模型在 「不可能」 事件理解、 時域推理、反事實生成 等方面仍存在巨大挑戰。基於 Impossible Videos 的數據增強、模型微調等是幫助模型掌握世界規律的新視角。
參考文獻
[1] Huang, Ziqi, et al. “Vbench: Comprehensive benchmark suite for video generative models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[2] Ye, Junyan, et al. “Loki: A comprehensive synthetic data detection benchmark using large multimodal models.” arXiv preprint arXiv:2410.09732 (2024).
[3] Kong, Weijie, et al. “Hunyuanvideo: A systematic framework for large video generative models.” arXiv preprint arXiv:2412.03603 (2024).
[4] Bai, Zechen, Hai Ci, and Mike Zheng Shou. “Impossible Videos.” arXiv preprint arXiv:2503.14378 (2025).