腦波解碼延遲僅80毫秒,實時「意念對話」技術登Nature子刊
機器之心報導
機器之心編輯部
無法說話的人,現在可以通過大腦掃瞄的方式實時地用自己的聲音說話了。整個過程沒有延遲,也不需要打字,不用發出任何聲音。
本週,腦機接口的最新研究在社交網絡上引發了人們的熱烈討論,一位Twitter博主的帖子瀏覽量突破了 150 萬。
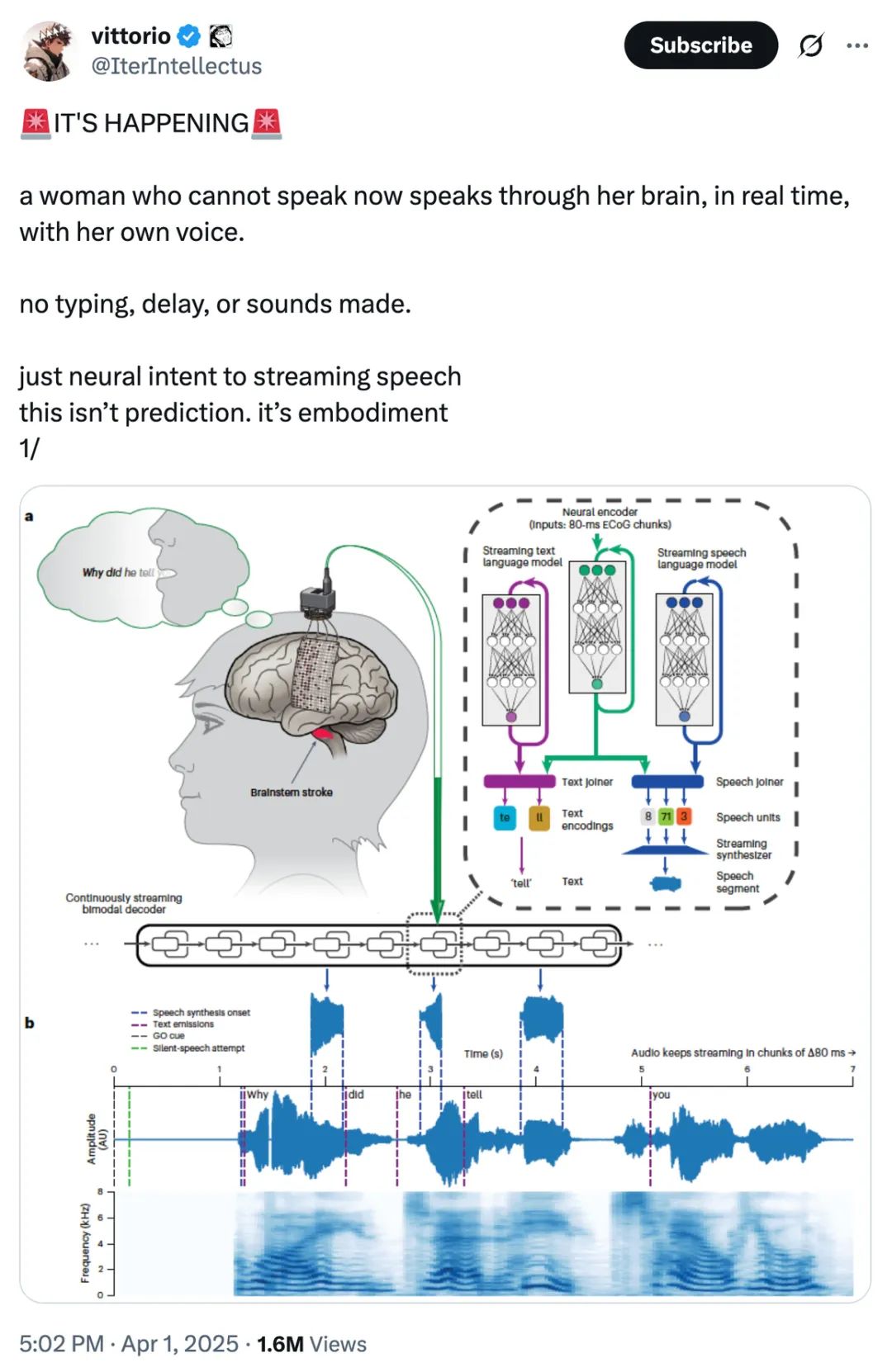
先來看效果。影片中的受試者嚴重癱瘓,不能講話。她的大腦活動被解碼為目標句子,然後使用文本到語音模型一次合成一個單詞。
我們可以看到連接受試者頭部的設備(connector)。屏幕上出現了目標句子(target sentence),然後從大腦活動解碼文本,並應用「單詞級文本到語音合成」。
接下來是更多的示例:
論文一作 Kaylo T. Littlejohn 發推宣傳團隊的成果,他表示,這種流式「腦轉語音」(brain-to-voice)神經假體可以讓癱瘓患者恢復自然、流利和清晰的語言能力。
同時他強調,泛化能力至關重要,隨著快速改進設備,現在構建的解碼方法應能跨用例轉換(比如非侵入式與侵入式的權衡),並為未來的臨床語音神經假體打好基礎。
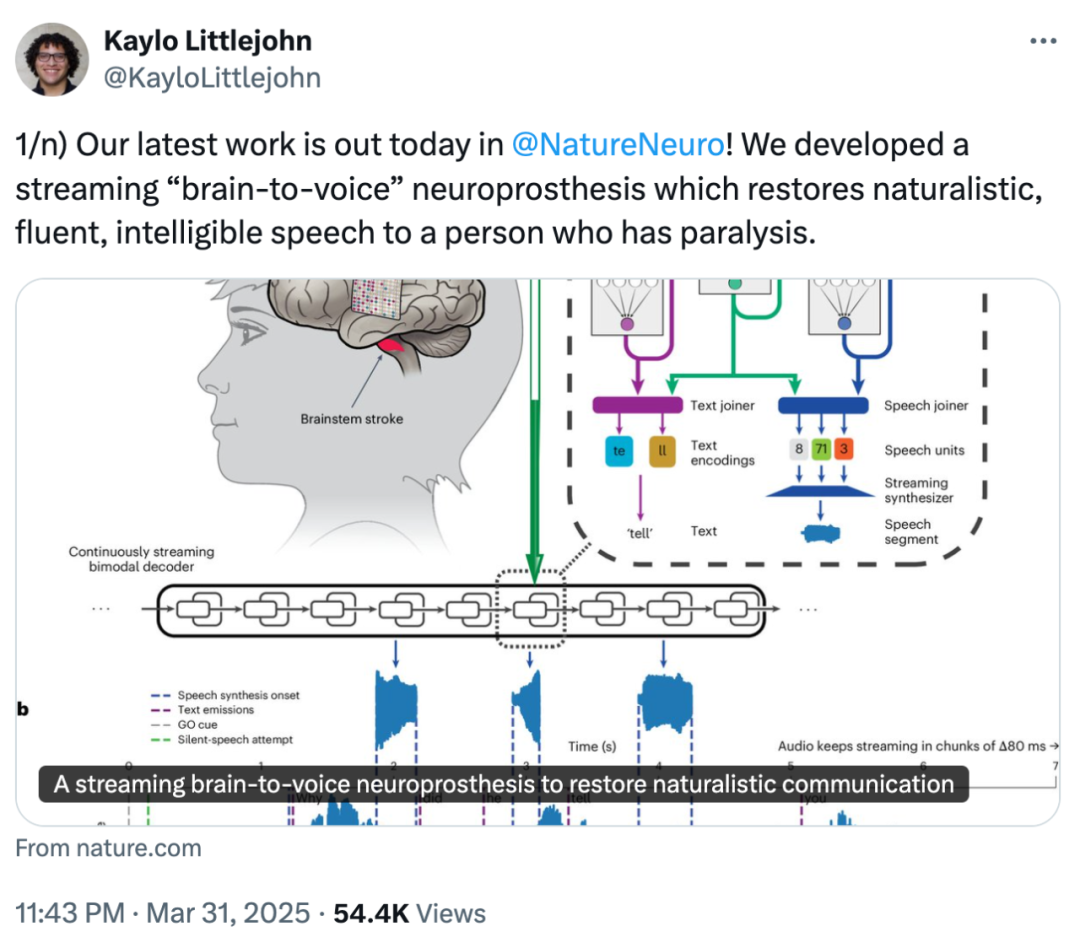
這項技術成果「牛」在哪裡?
要知道在此之前,最好的腦機接口系統也只能讓患者以每分鐘 8-14 個字的速度「打字」。而這個新系統輸出語音的速度可以達到每分鐘 90+ 個英文單詞,而且它不使用任何可聽見的訓練數據,用戶甚至不需要嘗試發出聲音。
該研究來自加州大學伯克利分校(UC Berkeley),已經登上了最新一期《自然》子刊 Nature Neuroscience。

-
論文:A streaming brain-to-voice neuroprosthesis to restore naturalistic communication
-
論文鏈接:https://www.nature.com/articles/s41593-025-01905-6
該系統轉錄的目標是患者大腦的言語運動皮層,採用 253 通道 ECoG 陣列,深度學習神經解碼器經過 2.3 萬次轉語音訓練,構建了延遲僅 80ms 的 RNN-T 架構,既可以合成語音也可以進行實時轉錄,音色模仿自患者受傷之前的錄音。
大多數腦機接口的系統在輸出任何內容之前都需要等待人想出完整句子,但在新的系統上,人類正在思考中的內容就可以被轉為語音,延遲大約為 1 秒。因此該系統可以稱得上是實時的意念轉語音了。
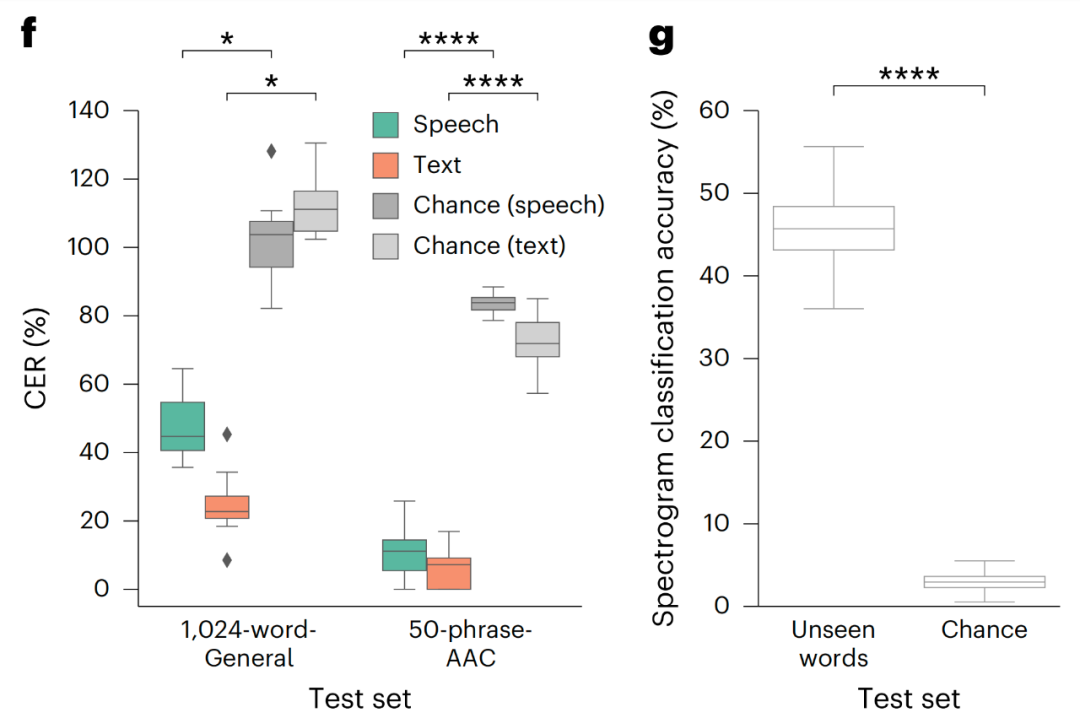
在實際測試中可以看到,語音轉錄的效果快速、流暢且準確:在 50 個短語集(護理需要)的測試中,新方法達到了 91 WPM 、12% 字錯率 (WER)、 11% 字符錯誤率。在 1024 字集的自然句子測試中,該方法也達到了 47 WPM、59% WER 和 45% 字符錯誤率。雖然還不是很準確,但已經證明了該系統的有效性。
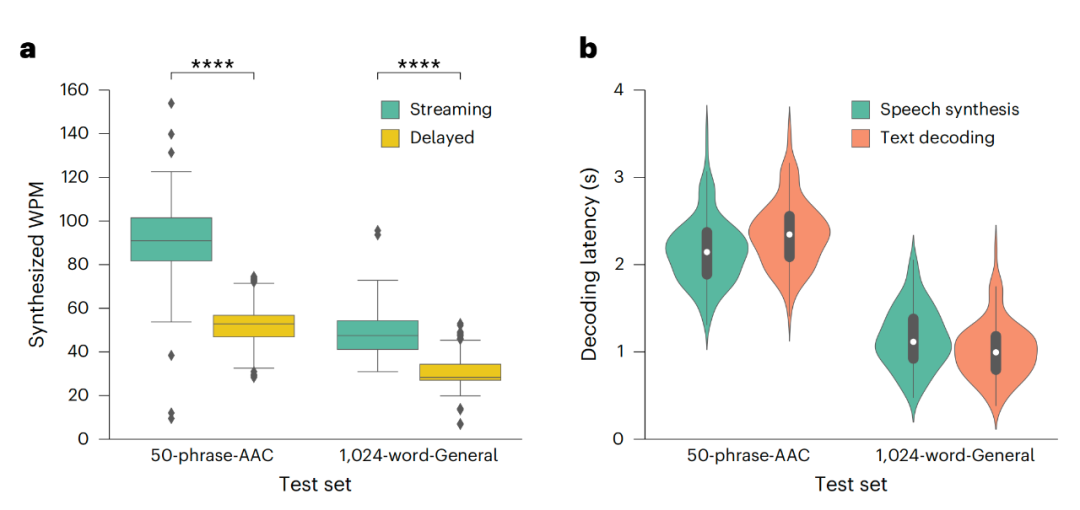
此外,該系統成功地合成了在訓練過程中未曾見過的新詞彙。當給定 24 個新的詞彙,例如 Zulu、Romeo,它正確識別出這些詞彙的概率為 46%,而僅憑偶然猜測的概率為 3.8%。這一切僅通過神經活動就得以實現。
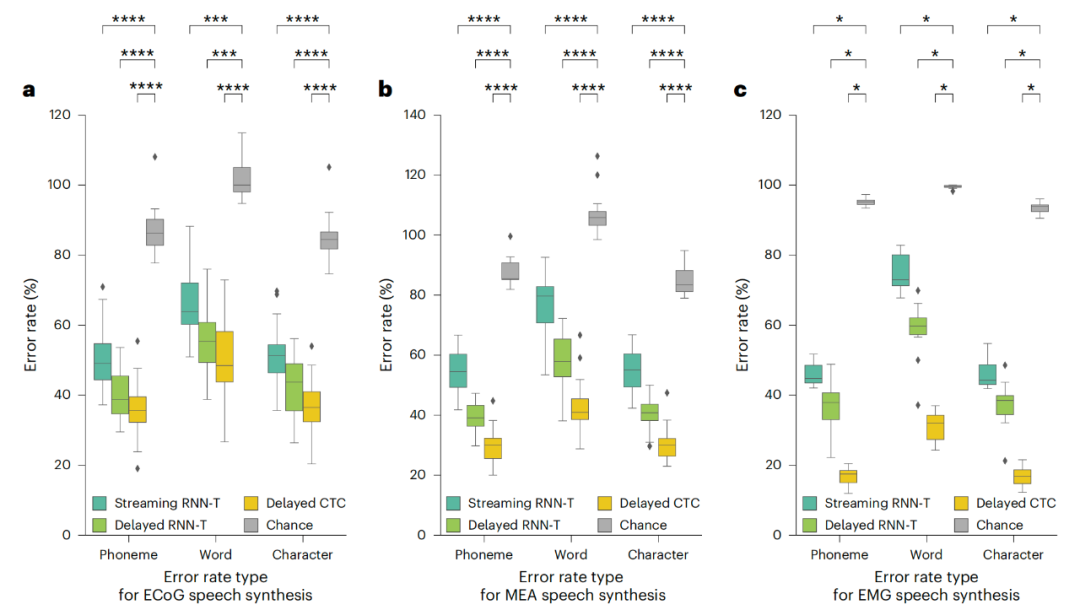
此外,該系統採用了統一的神經網絡架構,能夠跨多種技術平台解碼語音信號,具體包括:
-
ECoG(皮層腦電圖),通過植入大腦表面的電極陣列讀取神經信號,無需穿透腦組織,創傷性較低;
-
MEA(皮層內微電極),通過植入大腦皮層的微型電極記錄單個神經元活動;
-
EMG(面部表面電極,無需手術)。
一直以來,很多研究僅僅局限於試驗階段,相比之下,該系統能夠持續工作,不需要預先編程就能夠通過大腦活動檢測到受試者何時開始和停止說話。研究者用時長 6 分鐘的連續無聲語音塊對其進行了測試。結果顯示,系統能夠準確解碼,幾乎沒有任何誤報。
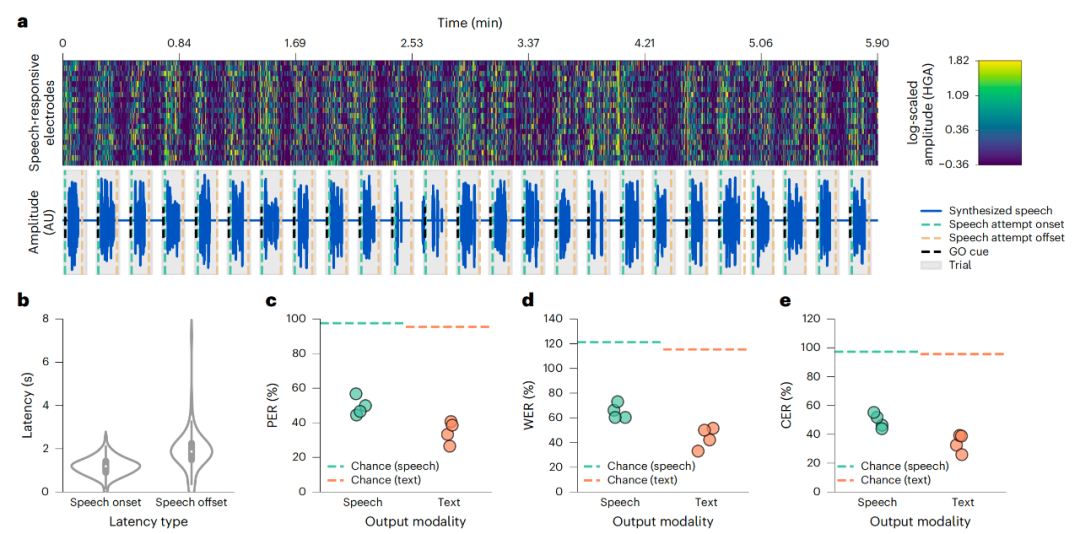
這項研究的解碼速度達到了新的標杆,此前最佳解碼速度為 28 詞 / 分鐘(WPM),該系統的表現達到 90 詞 / 分鐘(WPM),且延遲更低。
更重要的是,受試者無需發聲,借助該系統,受試者用意念就能「說話」。
從臨床角度看,這項研究能讓失去語言能力的人重新獲得說話的權力。從技術角度看,它解決了實時、流暢的神經語音解碼問題。大家期待已久的無聲交流正在實現,這也表明了語言可以完全基於神經信號來傳達。
如果這項技術普及開來,我們可以想像 20 年後的世界,那將是不再需要手機、不再需要鍵盤、不再需要語音指令等等,你要做的只是思考,你的話語便能被實時感知。
參考鏈接:https://x.com/IterIntellectus/status/1906995681253822519