2025美國最新奧數題,讓大模型集體翻車,DeepSeek R1平均分也不到5%
機器之心報導
編輯:+0
當 AI 翻開奧數題,CPU 也燒了!
還記得那些被奧數題折磨得徹夜難眠的日子嗎?
當你在淩晨三點對著一道幾何證明題抓耳撓腮、懷疑人生的時候,你可能會想:「要是有個超級大腦能幫我解決這些問題該多好啊!」

好消息:大模型解數學題的能力很強!壞消息:它們好像也被奧數折磨得不輕。
很多針對大型語言模型(LLMs)的數學基準測試已經表明,最先進的推理模型在美國數學邀請賽(AIME)等數學競賽中表現出色,O3-MINI 模型甚至達到了與頂尖人類參賽者相當的水平。然而,這些測試僅僅評估了最終答案,而忽略了推理和證明過程。
為彌補這一不足,專注於評估大模型數學能力的 MathArena 平台的研究人員,首次全面評估了模型解決複雜數學問題的完整推理和證明構建能力。
美國數學奧林匹克競賽(USAMO)是全球最具挑戰性的中學生數學競賽之一。首先,該賽事強調嚴格證明與邏輯嚴謹性,題目均為證明題,要求選手通過嚴密的邏輯推導和完整的數學語言呈現解答,而非僅給出數值答案(如 AIME)。其次,題目難度極高,涉及數論、組合數學、代數、幾何等核心領域,常需運用高級技巧(如生成函數、不等式放縮、圖論構造等)。而且題目設計具有「門檻效應」:部分問題看似簡單,但需洞察隱藏結構或非標準解法(如構造性證明、反證法)。
他們在 2025 年美國數學奧林匹克競賽(USAMO)試題發佈後立即測試了多個熱門模型,結果令人失望:所有模型都表現欠佳,平均得分不到 5%。

通過深入分析模型的推理過程,研究人員識別出了多種常見失敗模式,併發現模型訓練中的某些優化策略反而產生了負面影響。

-
論文標題:PROOF OR BLUFF? EVALUATING LLMS ON 2025 USA MATH OLYMPIAD
-
論文鏈接:https://arxiv.org/pdf/2503.21934v1
-
項目主頁:https://matharena.ai
-
項目代碼:https://github.com/eth-sri/matharena
結果表明,當前的 LLM 在嚴格的數學推理方面,尤其是在形式化證明生成方面,仍然非常吃力。在未來的研究中,有必要改進訓練方法,如納入重證明的數據集、整合形式驗證工具或開發優先考慮邏輯一致性而非答案優化的架構,彌合數值正確性與逐步證明能力之間的差距。
方法
評估基準與問題準備
研究團隊選擇了 USAMO 2025 作為基準測試,這是一個權威數學競賽,包含六道需要證明的題目,為期兩天。這個競賽非常適合作為評估基準,因為題目具有挑戰性,需要詳細證明才能得滿分,且數據未被汙染.
圖 1 展示了兩個競賽題目。在評估過程中,研究人員要求各模型提供全面詳細的證明,並使用 LaTeX 格式。

為降低結果的變異性,每個模型對每道題目進行了四次獨立解答。所有解答均經過匿名化處理並轉換為 PDF 格式進行評分,評分過程中不考慮思考過程部分。
評審團隊
評分團隊由四位資深數學專家組成,他們都曾是國家 IMO 隊成員或進入過國家隊最終選拔。評審前,他們接受了詳細說明評估目標和方法的指導(可在 GitHub 查閱)。團隊通過 USAMO 2024 三道題目的試評分熟悉了評分標準並解決歧義。
評分流程
USAMO 2025 的六個問題均由兩名評審員獨立評分,每位評審員負責三個不同問題。這種借鑒 IMO 的雙重評分方法確保了評分的一致性並減少了主觀偏見。由於官方不發佈標準答案,研究團隊從可靠的數學社區資源(尤其是 AoPS 論壇)收集整理了標準化評分方案,並驗證了所有解法的準確性。
遵循 USAMO 慣例,每題滿分七分,對有意義的進展給予部分分。評審員根據既定標準獨立評分,對不完全符合評分方案的解法也適當給分,並記錄了評分理由和部分分數的合理性說明。
失敗模式分類
評估者在評分過程中記錄了明顯的失敗模式 —— 即推理中首次出現的錯誤或解釋不充分的實例,包括邏輯缺陷、無根據的假設、數學不準確或計算錯誤。這些錯誤被具體分為四類:
-
邏輯:由於邏輯謬誤或無根據的推理跳躍導致的錯誤,中斷了推理過程。
-
假設:由於引入未經證明或不正確的假設而產生的錯誤,這些假設破壞了後續步驟。
-
創造力:由於無法識別正確方法而導致的從根本上錯誤的解決策略所造成的錯誤。
-
代數 / 算術:由關鍵的代數或算術計算錯誤引起的錯誤。
研究團隊還系統性地記錄了模型在生成解決方案過程中表現出的顯著行為模式和趨勢,以便進行深入分析。這些觀察結果有助於識別模型推理能力中存在的常見問題和需要改進的方向。
結果
主要結果
研究評估了六個推理模型(QWQ、R1、FLASH-THINKING、O1-PRO、O3-MINI 和 Claude 3.7)在 2025 年 USAMO 問題上的表現。
表 1 詳細分析了各模型在每個問題上的表現,平均分基於四次評估運行計算,每題滿分 7 分,每次運行總分 42 分。表中還包括使用各模型的總成本數據。
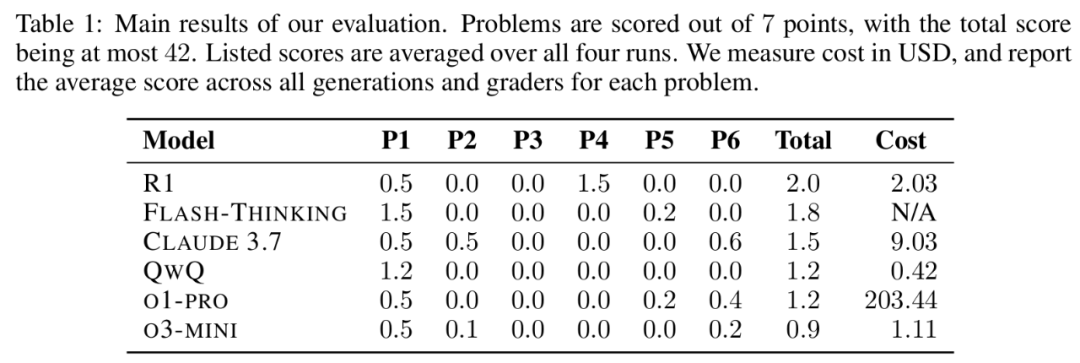
評估發現,雖然當前頂尖語言模型在以數值答案為主的競賽(如 AIME 和 HMMT)中可與頂尖人類競爭者相當,但在生成嚴格證明方面存在顯著差距。所有評估模型的最高平均分不足 5%,近 150 個被評估的解答中無一獲得滿分。
所有模型都無法解決超過一個問題,這凸顯了當前大型語言模型在奧林匹克級數學推理任務中的局限性。這表明現有優化方法如 GRPO 對需要高度邏輯精確性的任務可能尚不足夠。
失敗模式
人類參與者最常見的失誤是無法找到正確解答,但他們通常能清楚判斷自己是否成功解決了問題。相比之下,所有評估的大型語言模型都聲稱已解決問題,這對數學應用構成重大挑戰,因為在缺乏嚴格人類驗證的情況下,這些模型得出的結果不可信賴。
研究人員詳細分析了評分過程中發現的錯誤類型。圖 2 展示了評審員確定的錯誤類別分佈。
最常見的是邏輯缺陷,包括無依據的推理步驟、錯誤理由或對先前進展的誤解。另一個重要問題是模型傾向於將關鍵證明步驟視為瑣碎而不提供適當證明。值得注意的是,儘管 O3-MINI 是表現最佳的推理模型之一,卻經常通過將關鍵步驟標記為「瑣碎」來跳過基本證明步驟。
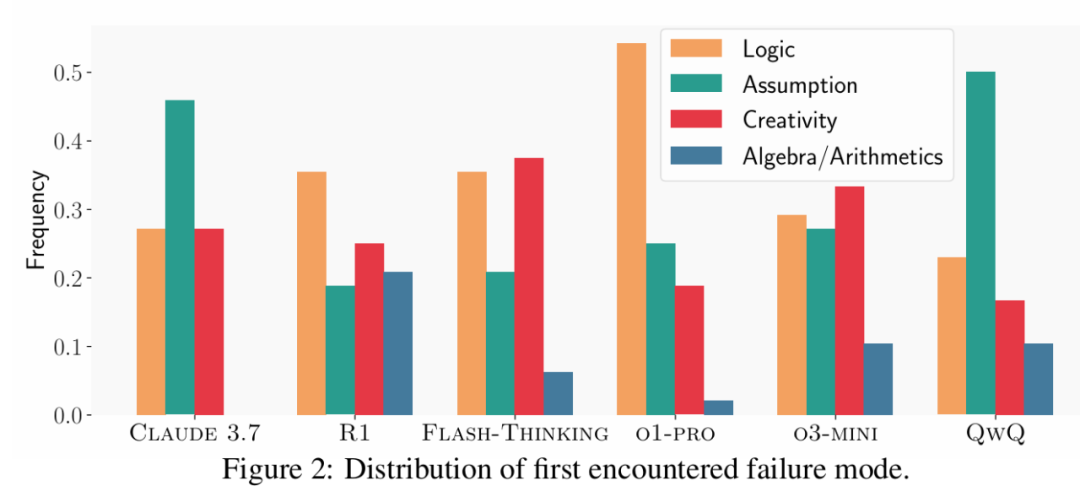
研究還發現模型推理缺乏創造性,通常在所有嘗試中採用相同且錯誤的策略,未能探索替代方法。例外是 FLASH-THINKING,它在同一運行中嘗試多種策略,但僅淺層探索每種方法,未能得出有效結論。
然而,模型在代數和算術計算方面普遍表現出色,能在沒有外部支持的情況下成功執行符號運算。不過,R1 表現出明顯更高頻率的代數或算術錯誤,表明這是該模型需要改進的方向。
自動評分
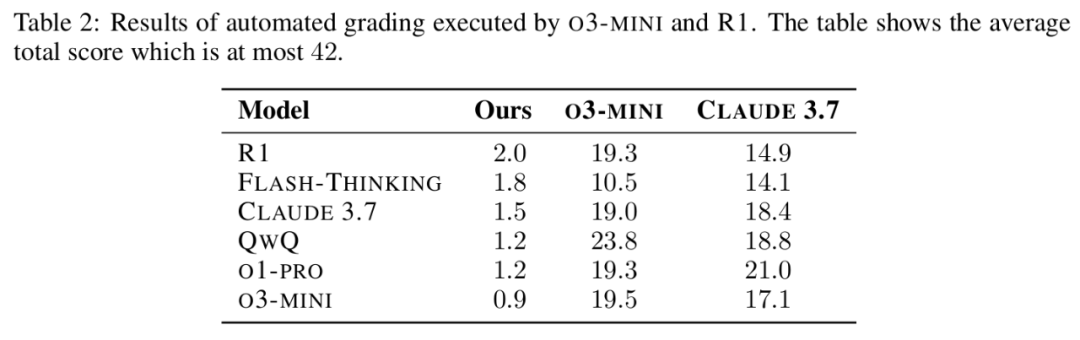
研究團隊探索了用 LLMs 替代人類評分員的可行性,選擇 O3-MINI 和 Claude 3.7 作為評分模型。兩個模型均獲得了評分方案、驗證解決方案和評估示例參考。
表 2 顯示,兩個模型都未能準確評分解決方案,均系統性地高估瞭解答質量。具體而言,它們經常為不正確或無依據的推理授予分數,導致分數膨脹最多達到 20 倍。
值得注意的是,FLASH-THINKING 從自動評估中獲得的分數明顯低於其他模型,研究人員推測這可能是因為它傾向於在每次嘗試中生成多個解決方案,從而混淆了基於 LLMs 的評審系統。相比之下,QWQ 獲得較高分數,可能是因為它通常生成更簡潔的解決方案,更便於自動評審系統理解。
定性討論
答案框選
當前強化學習優化技術依賴從明確的最終答案中提取獎勵,為此模型常被要求將最終答案放在 \boxed {} 環境中。然而,這在 USAMO 問題解答中產生了意外副作用:即使大多數評估問題不需要框選答案,模型仍習慣性地這樣做。
一個典型例子是問題 5 中,QWQ 模型錯誤地限制自己只尋找整數解,儘管題目沒有這樣的要求。它堅持最終答案是 2,雖然已經正確推導出所有偶數都滿足條件。這表明像 GRPO 這樣的對齊技術可能無意中讓模型認為每個數學問題都需要一個明確的框選答案,從而損害了其整體推理能力。
模式泛化
模型常表現出將小數值案例中觀察到的模式過度泛化到更大未測試案例的傾向。雖然這種啟髮式方法對僅需數值答案的問題可能有效,但對於需要嚴格證明的問題,這種方法本質上存在缺陷。模型經常在缺乏正式證明的情況下,錯誤地斷言小案例中觀察到的模式具有普遍適用性。
解答結構與清晰度
不同模型提供的解答在清晰度和結構連貫性上存在顯著差異。O3-MINI 和 O1-PRO 等模型通常以清晰、邏輯化且易於理解的方式呈現解答。相反,FLASH-THINKING 和 QWQ 等模型經常產生混亂且難以理解的回答,有時在單個解答中混合多個不相關的概念。
OpenAI 訓練的模型在清晰度上的明顯優勢表明,專注於解答連貫性的額外訓練顯著提高了其可讀性,這一特性在其他模型中明顯受到較少重視。
所以,當下次有人警告你「AI 即將統治世界」時,不妨淡定地遞給他一張奧數試卷:「先讓它們過了這一關再說吧。」