視覺Token無縫對齊LLMs詞表!V²Flow:基於LLMs實現高保真自回歸圖像生成
V²Flow團隊 發自 凹非寺
量子位 | 公眾號 QbitAI
視覺Token可以與LLMs詞表無縫對齊了!
V²Flow,基於LLMs可以實現高保真自回歸圖像生成。
隨著ChatGPT掀起自回歸建模革命後,近年來研究者們開始探索自回歸建模在視覺生成任務的應用,將視覺和文本數據統一在「next-token prediction」框架下。
實現自回歸圖像生成的關鍵是設計向量化(Vector-Quantization)的視覺Tokenizer,將視覺內容離散化成類似於大語言模型詞表的離散Token。
現有方法雖取得進展,卻始終面臨兩大桎梏:
1、傳統視覺tokenizer生成的離散表徵與LLM詞表存在顯著的分佈偏差。
2、維度詛咒:圖像的二維結構迫使大語言模型以逐行方式預測視覺token,與一維文本的連貫語義預測存在本質衝突。
結構性與特徵分佈性的雙重割裂,暴露了當前自回歸視覺生成的重大缺陷:缺乏能夠既保證高保真圖像重建,又能與預訓練LLMs詞彙表在結構上和特徵分佈上統一的視覺tokenizer。解決這一問題對於實現有效的多模態自回歸建模和增強的指令遵循能力至關重要。
因此,一個核心問題是:
能否設計一種視覺tokenizer,使生成的離散視覺token在保證高質量視覺重建的同時,與預訓練LLMs詞彙表實現無縫融合?
統一視覺Token與大語言模型詞表
最新開源的V²Flow tokenizer,首次實現了將視覺內容直接嵌入現有大語言模型的詞彙空間,在保證高質量視覺重建的同時從根本上解決模態對齊問題。總體而言,V²Flow主要包括三點核心貢獻:
視覺詞彙重采樣器。
如圖1(a) ,將圖像壓縮成緊湊的一維離散token序列,每個token被表示為大語言模型(例如Qwen、LLaMA系列)詞彙空間上的軟類別分佈。這一設計使得視覺tokens可以無縫地嵌入現有LLM的詞彙序列中。換言之,圖像信息被直接翻譯成LLM「聽得懂」的語言,實現了視覺與語言模態的對齊。
在圖1(b)中,經由重采樣器處理後,視覺tokens的潛在分佈與大型語言模型(LLM)的詞彙表高度一致。這種在結構和潛在分佈上的高度兼容性,能夠降低視覺tokens直接融入已有LLM的複雜性。
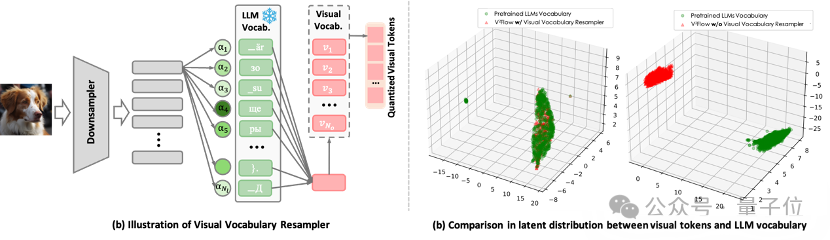 △ 圖 1 視覺詞彙重采樣器的核心設計。
△ 圖 1 視覺詞彙重采樣器的核心設計。掩碼自回歸流匹配編碼器。
為了實現離散化視覺token的高保真視覺重建,V²Flow提出了掩碼自回歸流匹配解碼器。該解碼器採用掩碼Transformer編碼-解碼結構,為視覺tokens補充豐富的上下文信息。增強後的視覺tokens用於條件化一個專門設計的速度場模型,從標準正態先驗分佈中重建出連續的視覺特徵。在流匹配采樣階段,該解碼器採用類似MA的方式,以「next-set prediction」的方式逐步完成視覺重建。
相比於近期提出的僅依賴掩碼編碼器-解碼器結構的TiTok,V2Flow自回歸采樣的優勢是能夠在更少的視覺token數量下實現更高的重建質量,有效提高了壓縮效率。
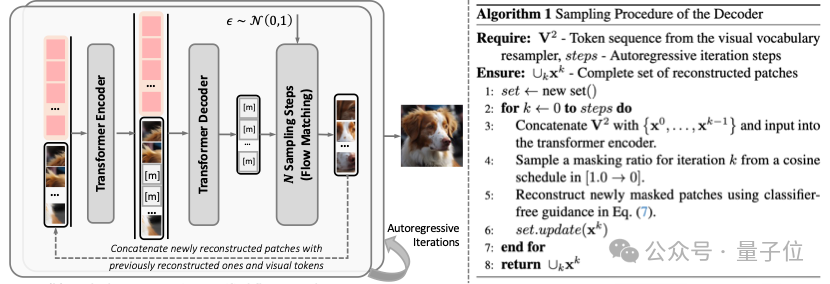 △ 圖 2 掩碼自回歸流匹配解碼器示意圖以及采樣階段算法流程
△ 圖 2 掩碼自回歸流匹配解碼器示意圖以及采樣階段算法流程端到端自回歸視覺生成。
圖3展示了V²Flow協同LLMs實現自回歸視覺生成的流程。為促進兩者無縫融合,在已有LLM詞彙表基礎上擴展了一系列特定視覺tokens,並直接利用V²Flow中的碼本進行初始化。訓練階段構建了包含文本-圖像對的單輪對話數據,文本提示作為輸入指令,而離散的視覺tokens則作為預測目標響應。
在推理階段,經過預訓練的LLM根據文本指令預測視覺tokens,直至預測到 token為止。隨後,離散視覺tokens被送入V²Flow解碼器,通過流匹配采樣重建出高質量圖像。
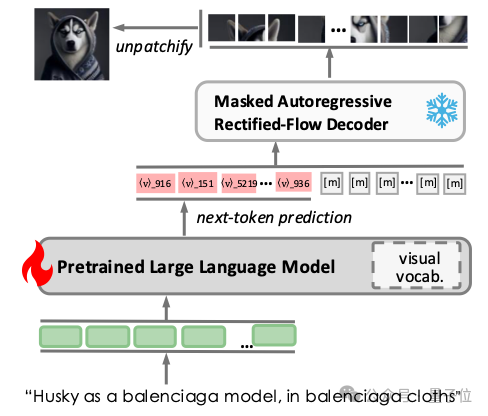 △ 圖3 V²Flow與預訓練LLMs融合實現自回歸視覺生成的整體流程。
△ 圖3 V²Flow與預訓練LLMs融合實現自回歸視覺生成的整體流程。實驗結果
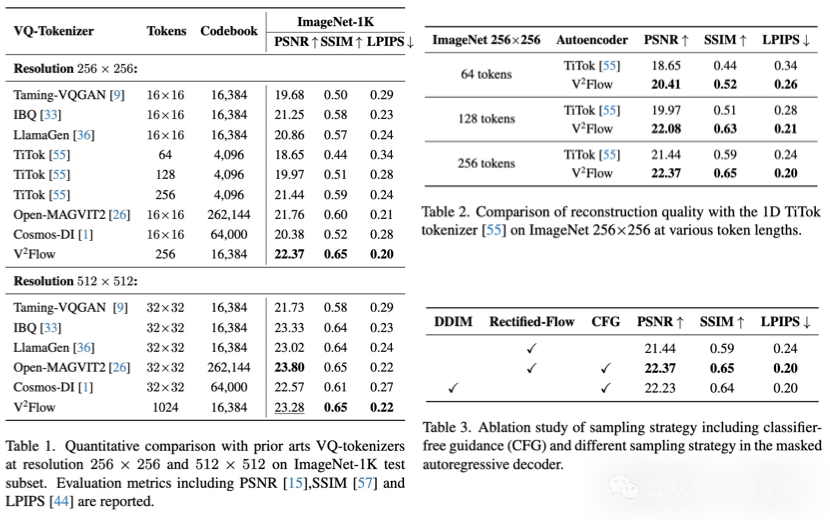
重建質量方面,V²Flow無論是在ImageNet-1k 測試數據集的256和512解像度下均取得了競爭性的重建性能。
相比於字節提出的一維離散化tokenizer TiTok相比,V²Flow利用更少的離散tokens實現了更高質量的圖像重建,顯著提高了整體壓縮效率。
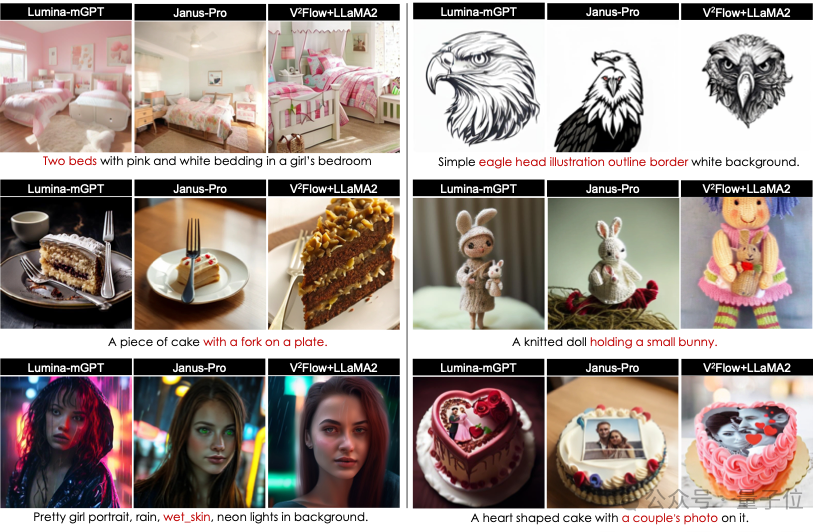
文本引導圖像生成方面,實驗結果表明,相比於當前兩種最先進的自回歸生成模型Janus-Pro-7B和Lumina-mGPT-7B,V²Flow+LLaMA2-7B能夠更加準確地捕捉文本提示中的語義細節,展示了極具競爭力的生成性能。
開源生態與團隊招募:共建多模態未來
開源承諾:讓技術普惠每一位探索者
開源是推動AI技術進化的核心動力。本次發佈的V²Flow框架已完整公開訓練與推理代碼庫,開發者可基於現有代碼快速複現論文中的核心實驗。更令人期待的是,團隊預告將於近期陸續發佈:
512/1024解像度預訓練模型:支持高清圖像重建與生成
自回歸生成模型:集成LLaMA等主流大語言模型的開箱即用方案
多模態擴展工具包:未來將支持影片、3D、語音等跨模態生成任務
加入我們:共創下一代多模態智能
V²Flow作者團隊現招募多模態生成算法研究型實習生!如果你渴望站在AI內容生成的最前沿,參與定義自回歸架構的未來,這裏將是你實現突破的絕佳舞台。
我們做什麼?
探索文本、圖像、影片、語音、音樂的統一自回歸生成範式
構建支持高清、長序列、強語義關聯的多模態大模型
攻克數字人、3D生成、實時交互創作等產業級應用難題
我們需要你具備:
硬核技術力
-
精通Python,熟練使用PyTorch/TensorFlow等框架
-
深入理解Diffusers、DeepSpeed等AIGC工具鏈
-
在CV/NLP領域頂級會議(CVPR、ICML、NeurIPS等)發表論文者優先
極致創新欲
-
對多模態生成、自回歸架構、擴散模型等技術有濃厚興趣
-
曾在Kaggle、ACM競賽等獲得Top名次者優先
-
有開源項目貢獻或獨立開發經驗者優先
投遞方式:zhangguiwei@duxiaoman.com
論文鏈接:
https://arxiv.org/abs/2503.07493
開源項目鏈接:
https://github.com/Davinci-XLab/V2Flow
一鍵三連「點讚」「轉發」「小心心」
歡迎在評論區留下你的想法!