10倍吞吐提升無損性能:多模態適用的KV cache量化策略來了,即插即用無需改原模型
CalibQuant團隊 投稿
量子位 | 公眾號 QbitAI
在InternVL-2.5上實現10倍吞吐量提升,模型性能幾乎無損失。
最新1-bit多模態大模型KV cache量化方案CalibQuant來了。
通過結合後縮放和校準方法,可顯著降低顯存與計算成本,無需改動原模型即可直接使用。

即插即用、無縫集成
多模態大語言模型在各種應用中展現出了卓越的性能。然而,它們在部署過程中的計算開銷仍然是一個關鍵瓶頸。
雖然KV cache通過用顯存換計算在一定程度上提高了推理效率,但隨著KV cache的增大,顯存佔用不斷增加,吞吐量受到了極大限制。
為瞭解決這一挑戰,作者提出了CalibQuant,一種簡單卻高效的視覺KV cache量化策略,能夠大幅降低顯存和計算開銷。具體來說,CalibQuant引入了一種極端的1比特量化方案,採用了針對視覺KV cache內在模式設計的後縮放和校準技術,在保證高效性的同時,不犧牲模型性能。
作者通過利用Triton進行runtime優化,在InternVL-2.5模型上實現了10倍的吞吐量提升。這一方法具有即插即用的特性,能夠無縫集成到各種現有的多模態大語言模型中。
動機
當前的多模態大語言模型在實際應用中常常需要處理大尺寸、高解像度的圖像或影片數據,KV cache機制雖然能提升效率,但其顯存佔用與輸入長度(如視覺幀數、圖像尺寸等)成正比。
當輸入數據的規模增大(例如更多的視覺幀、更高的圖像解像度)時,KV緩存的顯存使用量迅速增加,成為限制吞吐量的瓶頸。儘管當前有些針對LLM KV cache量化的方法可以將其壓縮至2比特,但這些方法沒有針對多模態問題中特有的視覺冗餘做分析優化,導致其無法在極限情況1比特下被使用。
本文通過分析多模態大語言模型中的視覺KV cache的冗餘,設計了適合多模態模型特有的KV cache量化方案。
方法
本文在通道維度量化的基礎上提出了針對反量化計算順序的後縮放優化方案和針對注意力權重優化的校準策略。
1、通道維度KV cache量化:
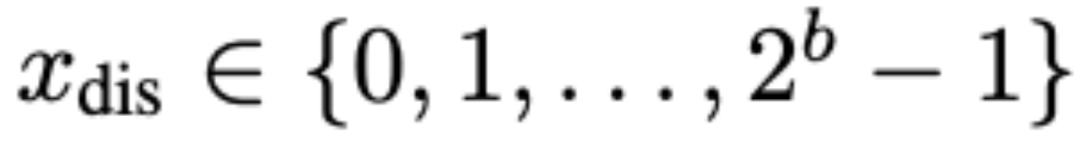 ,計算過程為:
,計算過程為: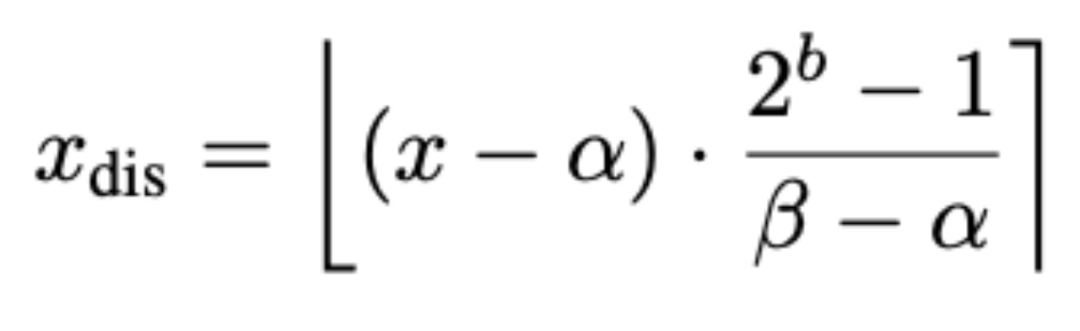
這裏的⌊⋅⌉表示取整運算符。最樸素的方法是使用全局統計量來計算這些極值,但是模型性能會受較大影響,作者選擇在通道維度上細化統計範圍。具體來說,令
表示一個K cache,其中n和d分別表示token的數量和head的維度。定義兩個向量
如下:
然後,通過上述過程對K中的每一行向量進行量化,其中乘法操作是逐元素進行的。作者同樣將這種按通道的量化方法應用於V cache。
2、後縮放KV cache管理策略:
量化後的K cache可以用離散化的整數值、一個縮放因子(scale factor)和一個偏置項(bias term)來表示。在解碼階段,這些值被用於對K cache進行反量化,並隨後與Q相乘。然而,通道維度的量化需要為每個通道分別指定不同的縮放因子和偏置向量,這將導致產生大量不同的數值,增加了反量化過程中的計算開銷。此外,這種方式也使得CUDA內核中的計算效率降低。作者觀察到量化後的K僅具有有限數量的離散取值(例如,對於2比特量化,其取值僅為0、1、2、3),於是提出利用簡單的計算順序重排來減少存儲需求,並提高計算效率。具體過程如下:
設
是K cache矩陣
中的任意一行向量,
為其進行b比特整數量化後的結果,並伴隨有逐通道的縮放因子α,β。給定一個查詢向量
,在生成token過程中注意力計算如下:
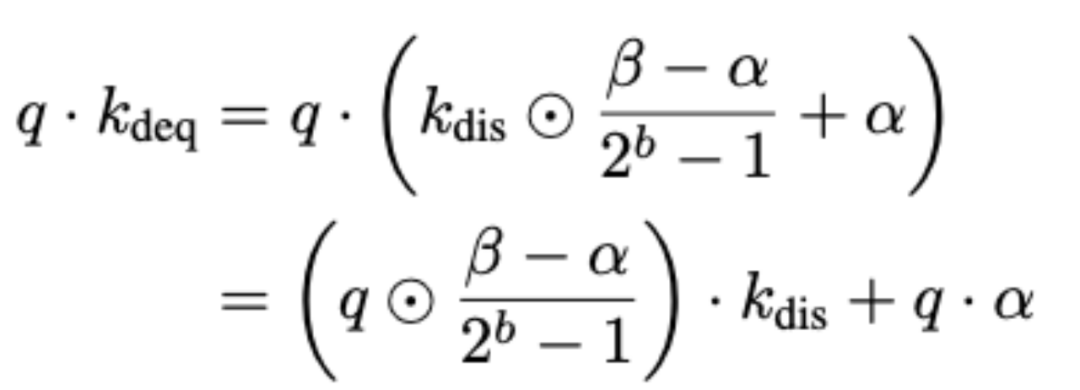
其中,符號⋅和⊙分別表示向量之間的內積和逐元素乘積。通道維度上的反量化操作
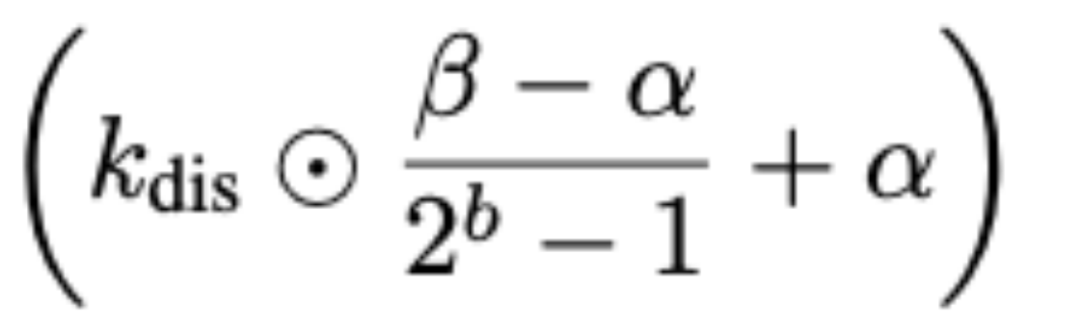
被延遲執行,並高效地集成到後續的向量乘法運算中。因此,這種方法僅存儲經過b比特整數量化後的數值,並且避免了全精度反量化計算過程。這種方法確保了低比特反量化執行的高效性。這種後縮放方法也可以自然地應用到V cache的反量化過程中。
3、量化後的校準:
1比特量化的一個限制是經過反量化之後的數值往往會包含大量的極端值。這是因為1比特量化的碼本總是包含了最小值和最大值,導致那些接近邊界的輸入值在反量化後直接映射到了極端值。
因此,重建後的KV cache通常包含過多的大絕對值,最終導致注意力分數產生明顯的失真。為瞭解決這個問題,作者提出了一種量化後校準方法,用於調整softmax之前注意力分數的峰值。具體來說,假設
中的所有元素都位於區間
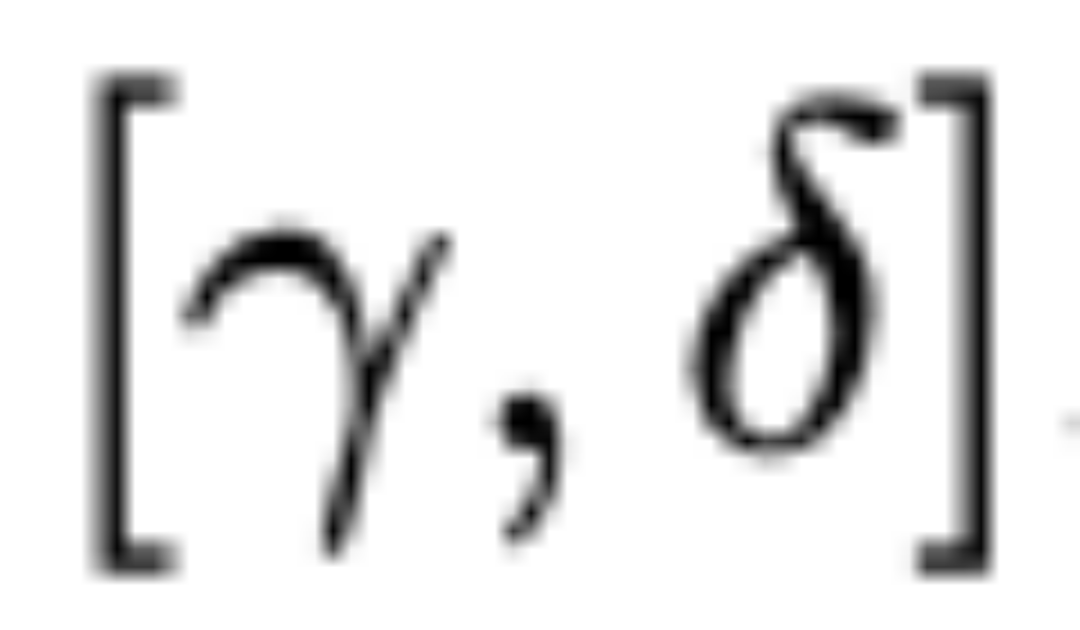
內。給定
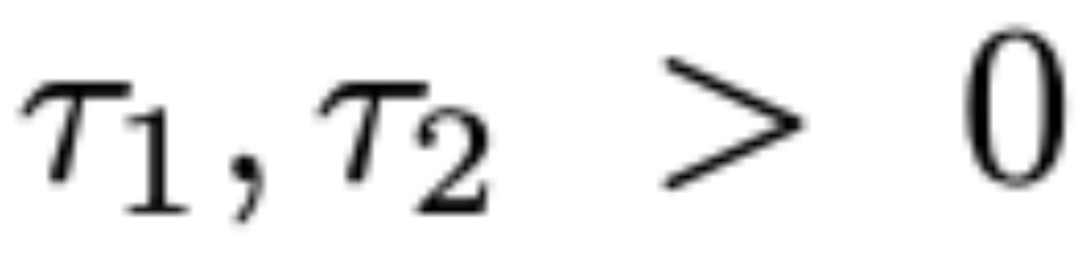
,定義一個線性變換g將區間
映射到
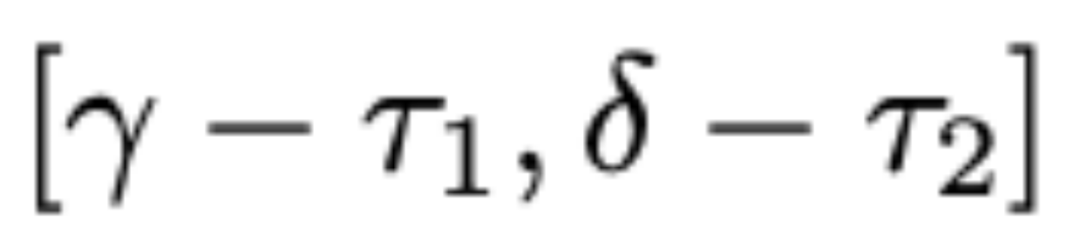
,其表達式如下:
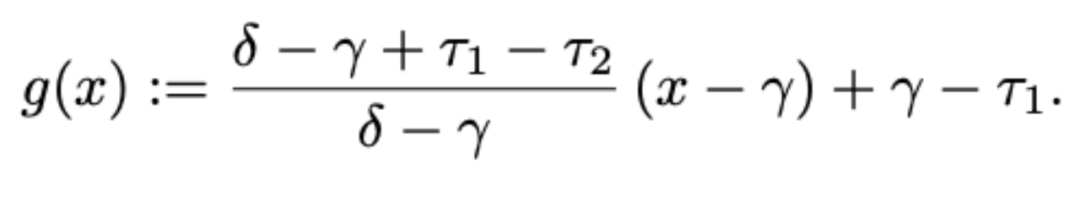
隨後對注意力分數進行如下調整:
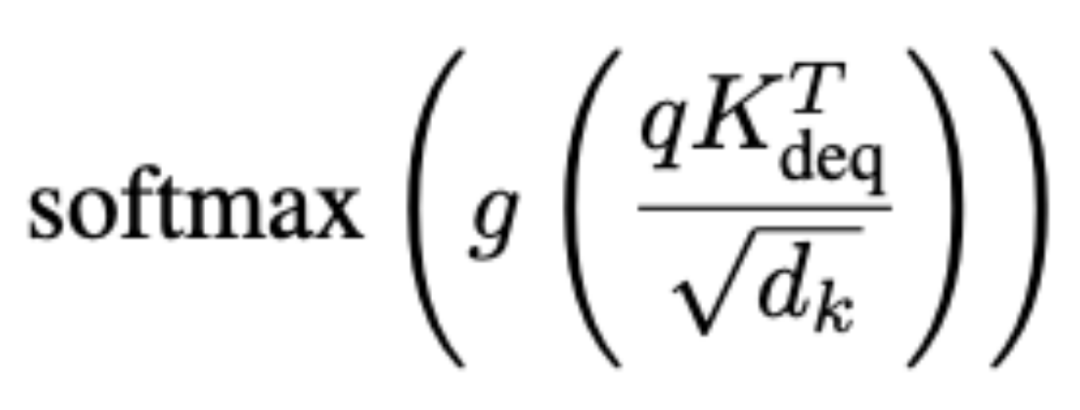
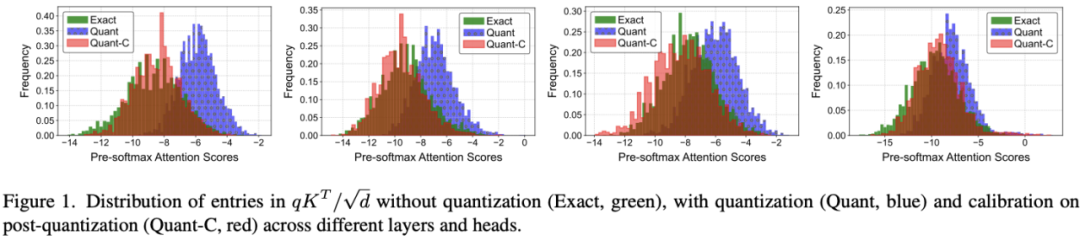
如下圖所示,校準方法(Quant-C,紅色)有效減輕了極端值的影響,使調整後的注意分數分佈相較於未經校準的量化方法(Quant,藍色)更接近全精度(Exact)分佈。
實驗結果
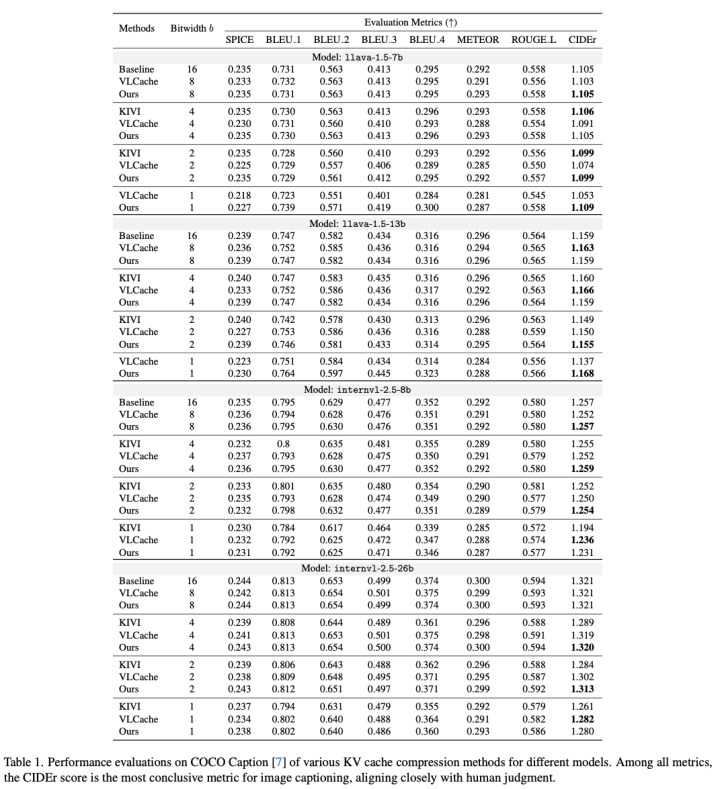
作者將提出的量化方法分別應用在LLaVA和InternVL model上,測試了其在captioning,VQA,Video QA三個不同的任務上的性能。以captioning任務為例,下圖展示了本文所提出的方法在cococaption benchmark下和其他方法如KIVI,VLCache的對比。
在不同比特數(8,4,2,1)下,本文提出的方法在大部分測試指標上都優於其他兩種方法。例如對於llava-1.5-7b,本文的方法在8比特下達到最高的CIDEr 分數 1.105,與全精度持平,並在1比特下提升至1.109,超過了VLCache(1.053)。同樣地,對於InternVL-2.5-26B,本文的方法在4比特和2比特下分別取得了最高的CIDEr分數1.32和1.313,均優於VLCache和KIVI。
Runtime分析
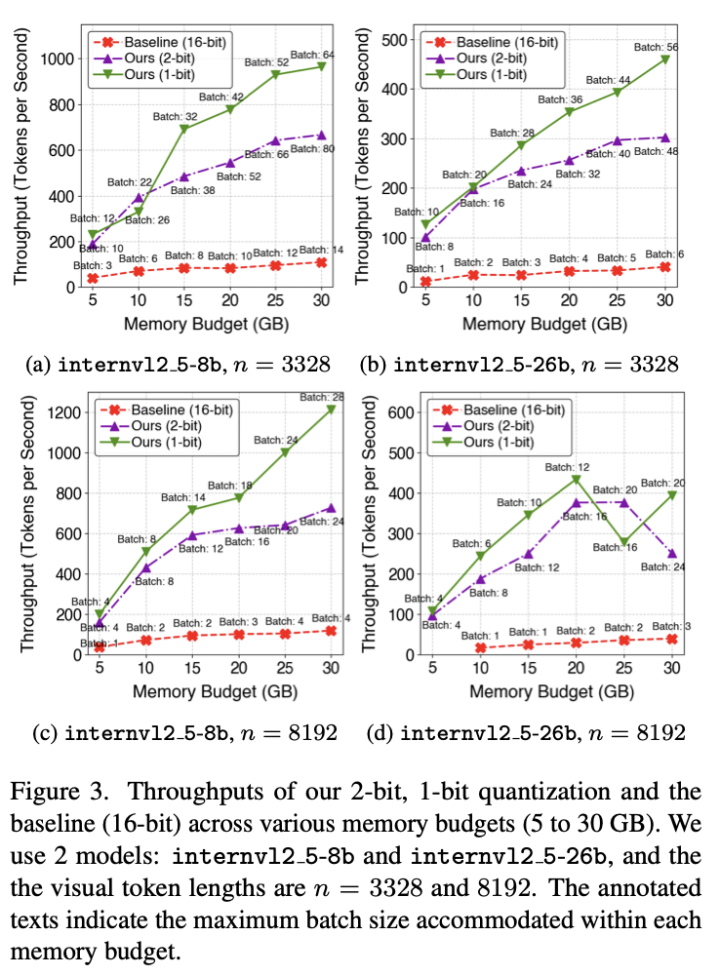
為了展示本文提出的量化方法對解碼效率的影響,作者使用InternVL-2.5系列模型,將所提出的1比特量化方法與16比特基線進行了吞吐量評估(即每秒生成的token數)。作者考慮了兩種視覺token長度的情況:n=3328和8192。作者將GPU最大內存從5GB變化到30GB,並在每種內存限制下,尋找能夠容納的最大batch size,測量解碼階段的吞吐量。
如下圖展示,1比特量化方法在所有顯存預算下始終優於基線方法。例如,當n=3329且使用80億參數模型時,本文的方法在5GB顯存下實現了126.582tokens/s的吞吐量(基線為11.628tokens/s),在30GB下提升至459.016tokens/s(基線為40.816tokens/s)。這意味著相比基線,本文方法的吞吐量提升約為9.88×到11.24×,充分展示了該方法在受限顯存條件下顯著提升解碼速率。
總結
本文探討了多模態大語言模型中視覺KV cache的壓縮方法。簡單地將量化應用到極低比特數常常會引發分佈偏移,導致模型性能下降。為瞭解決這一問題,本文提出了一種新穎的校準策略,作用於softmax之前的注意力分數,有效緩解了量化帶來的失真。此外,本文還引入了一種高效的通道維度後縮放技術以提高計算和存儲效率。
作者在InternVL和LLaVA模型系列上,針對COCO Caption、MMBench-Video和DocVQA等基準任務進行了實驗,結果驗證了所提出方法的有效性。作者利用Triton實現了本文所提出的方法,runtime分析表明本文提出的方法相較於全精度模型有大約10倍的吞吐量提升。
論文標題:CalibQuant:1-Bit KV Cache Quantization for Multimodal LLMs
論文地址:https://arxiv.org/abs/2502.14882
代碼地址:https://github.com/insuhan/calibquant
一鍵三連「點讚」「轉發」「小心心」
歡迎在評論區留下你的想法!