ICLR 2025 Spotlight | 參數高效微調新範式!上海交大聯合上海AI Lab推出參數冗餘微調算法

本文作者來自複旦大學、上海交通大學和上海人工智能實驗室。一作江書洋為複旦大學和實驗室聯培的博二學生,目前是實驗室見習研究員,師從上海交通大學人工智能學院王鈺教授。本文通訊作者為王鈺教授與張婭教授。
低秩適配器(LoRA)能夠在有監督微調中以約 5% 的可訓練參數實現全參數微調 90% 性能。然而,在 LoRA 訓練中,可學習參數不僅注入了知識,也學習到了數據集中的幻覺噪聲。因為這種特性的存在,大多數的 LoRA 參數都將可學習秩設置為一個較小的值(8 或者 16),通過減小知識學習程度來避免幻覺,而這也限制了 LoRA 的性能上限。
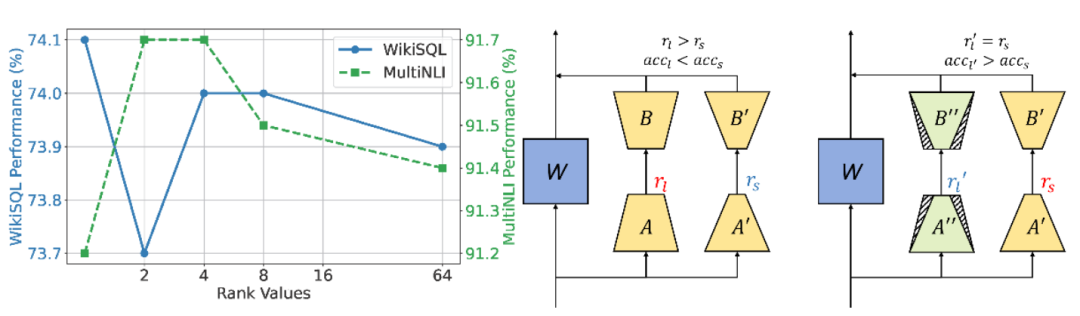 圖 1 普通的 LoRA 微調隨著秩的增大性能無法同步增加,而參數冗餘微調能夠以冗餘參數提升性能。
圖 1 普通的 LoRA 微調隨著秩的增大性能無法同步增加,而參數冗餘微調能夠以冗餘參數提升性能。為瞭解決這個問題,上海交通大學人工智能學院、複旦大學和上海人工智能實驗室的團隊提出了參數冗餘微調範式以及一種創新性的微調算法:NoRM(Noisy Reduction with Reserved Majority)。參數冗餘微調範式下,可以以普通的 LoRA 訓練方式進行訓練,並使用特定的方法在將 LoRA 參數合併回基模型參數前將冗餘部分去除。NoRM 通過 SVD 將 LoRA 參數分解為主成分和冗餘成分,並提出了 Sim-Search 方法,以子空間相似度動態決定主成分的數量。評估結果顯示,NoRM 在指令微調、數學推理和代碼生成的任務上一致性強於 LoRA 和其他參數冗餘微調方法,實現無痛漲點。

-
論文鏈接:https://openreview.net/pdf?id=ZV7CLf0RHK
-
開源代碼:https://github.com/pixas/NoRM
-
論文標題:FINE-TUNING WITH RESERVED MAJORITY FOR NOISE REDUCTION
研究動機
研究者首先在 Llama3-8B-Instruct 上進行預備實驗,使用 MetaMathQA-395K 數據集對模型進行微調,並在 SVAMP 上進行測試。研究者通過三個方面探究微調過程中的冗餘現象:(1)隨機刪除 10%~90% 的 LoRA 參數通道;(2)使用(1)中的方法,對 Transformer 中的不同層的 LoRA 參數進行隨機刪除;(3)使用(1)的方法,對 Transformer 中的不同模塊的 LoRA 參數進行隨機刪除。實驗結果發現,不僅隨機刪除 LoRA 參數能夠提升下遊模型的性能,不同層之間和模塊之間刪除 LoRA 參數對性能的影響呈現一定的規律。

圖 2 隨機刪除比例(a)的性能變化曲線和模型層索引(b)以及模塊(c)上的性能分佈。對達成最好性能的保留比例用深藍色重點展示。
方法概述
在 LoRA 微調中,並不是直接更新參數,而是更新一個低秩表達:。這個表達假設了參數的更新過程中,只在秩以內進行變化。在參數冗餘微調中,為了高效減小參數冗餘度,並能夠根據不同模塊和層之間的冗餘不同去設計算法,研究者們首先考慮直接使用奇異值分解(SVD)對參數更新部分進行分解:
其中為左右奇異矩陣,是包含了奇異值的對角矩陣。一種樸素的思想是保留最大的個奇異值和響應的奇異向量:
然而,通過這種方法只能得到整體的更新參數,無法得到兩個 LoRA 參數分別去除冗餘後的份量。為了能夠獲得一個在預處理和參數存儲上都更加高效的算法,研究者轉向使用隨機 SVD 來分別近似 和。特別地,隨機 SVD 以高斯分佈初始化一個隨機矩陣:
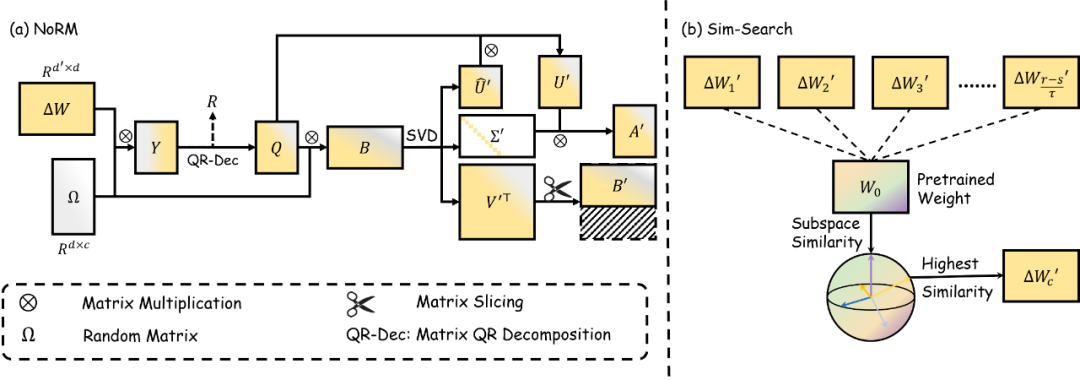
圖 3 NoRM 的算法總覽。其使用隨機奇異值分解來提取 delta 參數的主成分,並使用(b)Sim-Search 基於裁剪後的 delta 權重和預訓練權重間的子空間相似度決定擁有最小幻覺成分的 c 個通道。
接著,計算的主要列子空間:來近似特徵空間。在此之後,通過對的QR分解得到的正交基的近似。基於此正交基,可以在的低維空間上得到delta權重的投影:
那麼在這個小矩陣上執行標準SVD就可以得到:
其中,然後將轉化回去來近似奇異向量:。基於上述計算量,可以重構近似處理後的低秩參數:
確定好整個計算流程後,研究者們通過一種Sim-Search的方法來確定要保留的份量。這種方法通過預先設置好的兩個搜索超參數,搜索步數和搜索步長,得到一組不同下的低秩份量,以及所對應的delta權重。研究者對每一個delta權重使用SVD計算主要的個奇異矩陣:
並使用同樣的公式對基模型的權重進行同樣的分解得到。通過提取個和的左奇異向量來計算子空間相似度:
其中
。基於計算好的Grassmann距離
,可以選擇這一組中擁有最大Grassmann距離的值及對應的delta權重
和
實驗結論
NoRM 通過在三種不同的基模型以及三個不同的微調任務上進行實驗,展現出強大的性能。
實驗 1:指令微調實驗
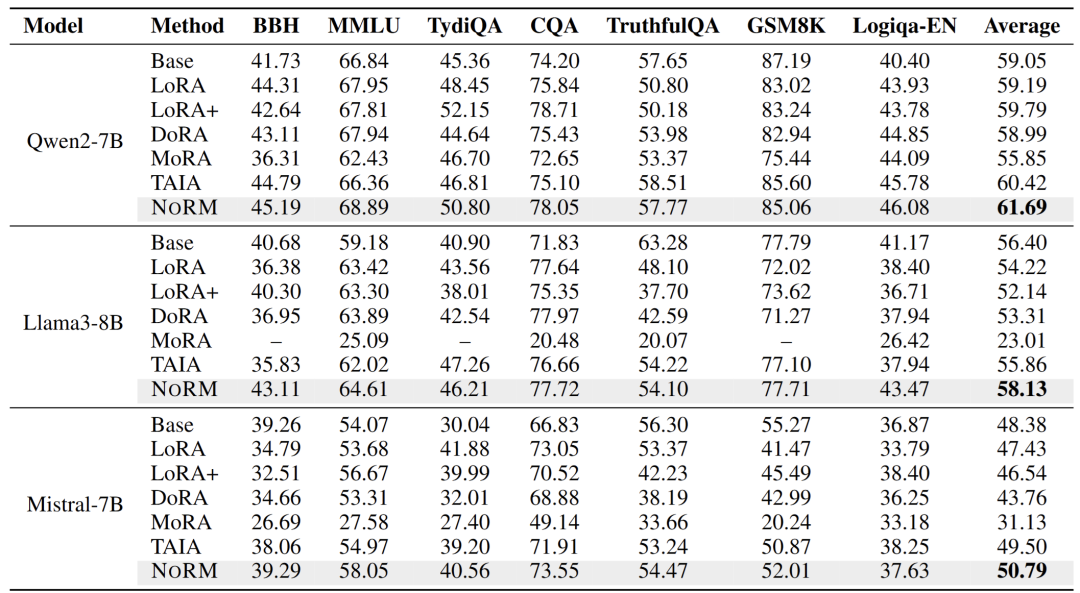
該任務主要測試,對 Instruct 模型進行微調後,如何保證多任務間的泛化性。通過和不同的 PEFT 基線進行比較,NoRM 在所有基模型上相比於最好的 PEFT 方法有著約 5 個點的提升。和之前最強的冗餘微調方法 TAIA 相比,也有著 1~3 個點的提升,展現了 NoRM 強大的冗餘去除能力。
實驗 2:專域微調實驗
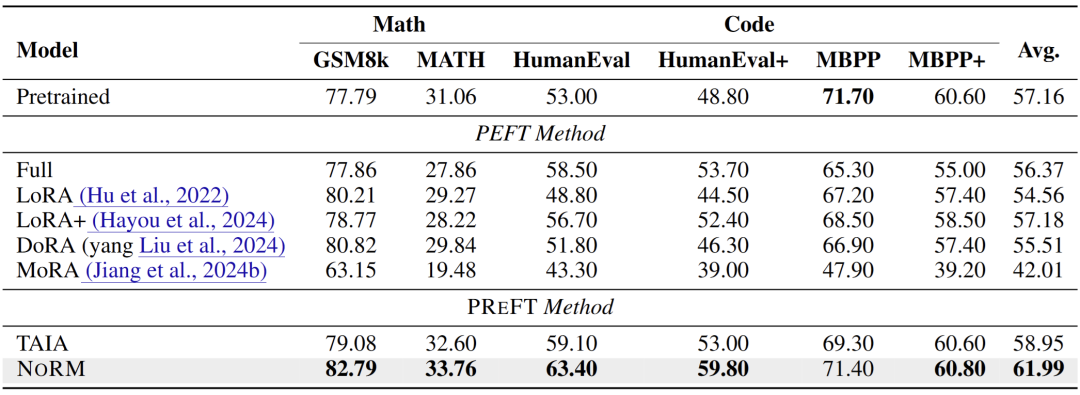
該任務主要測試通過 NoRM 去除了冗餘成分後,是否會對下遊知識的學習造成影響。該實驗選擇 Llama3-8B 作為基模型,在數學推理和代碼生成上進行測試。實驗結果表明,由於 NoRM 可以使用更大的秩進行微調,在下遊知識的吸收上,也優於之前的 PEFT 方法約 4 個點,領先 TAIA 約 3 個點。
實驗 3:可學習參數對 NoRM 的影響
NoRM 通過對可微調參數中的冗餘部分進行自適應去除降低微調幻覺。本實驗中,通過改變秩的大小,NoRM 的性能隨著可微調參數的增加而增加,而 LoRA 的性能並沒有這樣的趨勢,這也映證了微調參數中存在大量冗餘,這也是 LoRA 無法使用大秩提升性能的原因之一。
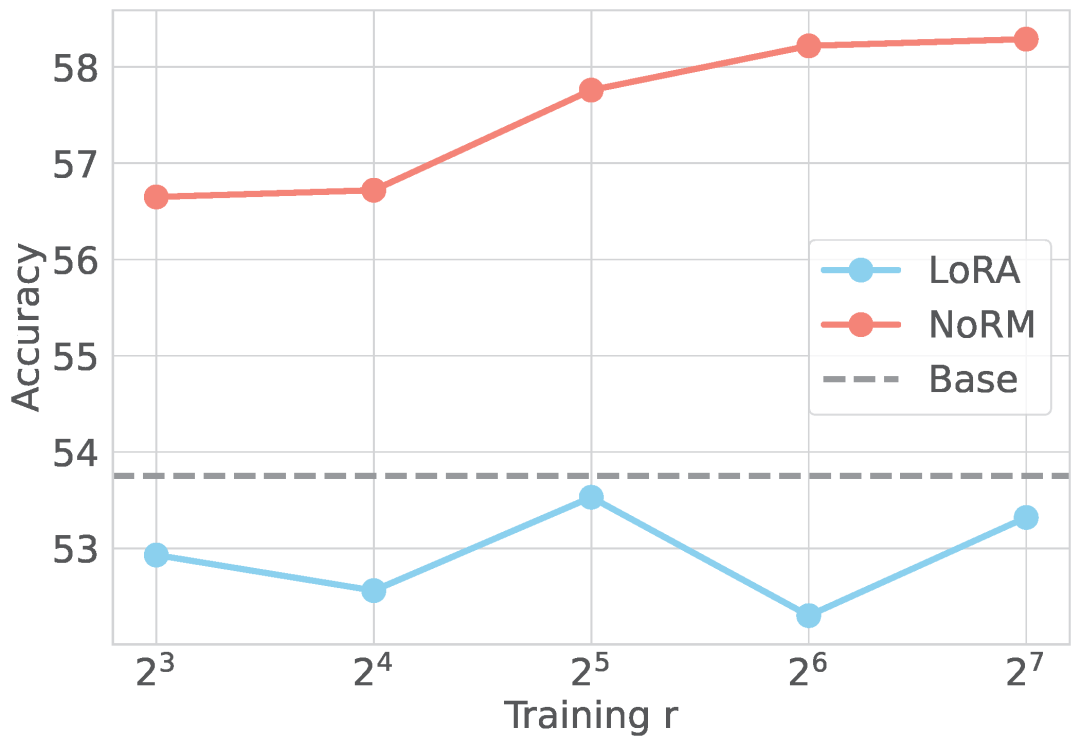 圖 4 NoRM 可以從大秩中受益,但基礎的 LoRA 在秩增大後反而降低性能。
圖 4 NoRM 可以從大秩中受益,但基礎的 LoRA 在秩增大後反而降低性能。實驗 4:NoRM 的學忘比
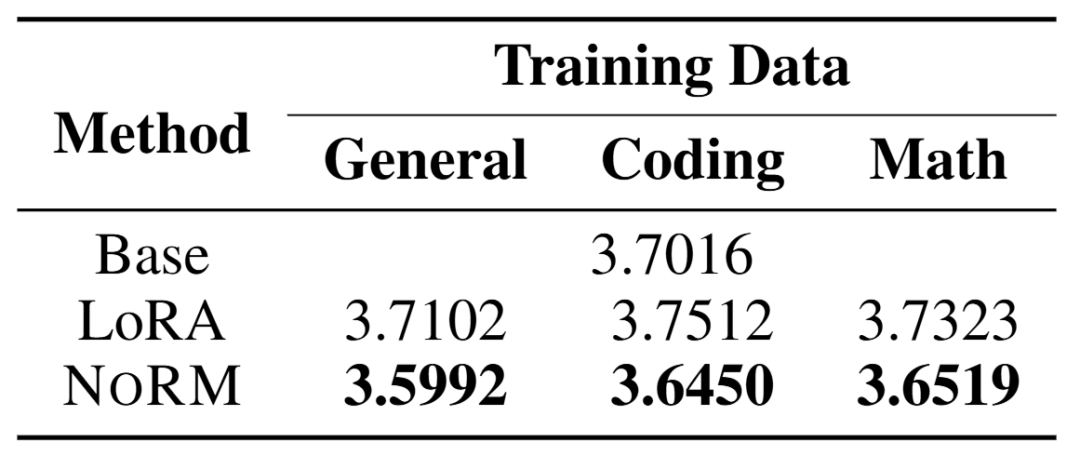
通過對 LoRA 和 NoRM 在記住預訓練知識的能力上進行比較,可以證實 NoRM 的設計哲學在於儘可能保留下遊語料中和預訓練參數中重疊最大的部分。通過測試在 WikiText-103 測試集上的損失函數值,可以看到 NoRM 的損失降低,而 LoRA 相比於基模型都有著一定程度上的升高。
結論和展望
這篇工作發現了有趣的高效參數冗餘現象,並提出了 NoRM 算法來智能識別並保留最有價值的參數,同時去除有著負面作用的冗餘參數,給微調參數做了一次 「減重手術」。在目前強化學習微調盛行的當下,可以將 NoRM 的設計哲學遷移到強化學習中,通過去除數據中會帶來噪聲的成分,提升模型下遊任務的適配性和多任務之間的泛化性。