o3狂燒3萬美金解一題,反被AGI榜單除名!試錯1024次不如10歲小孩哥4分鐘

新智元報導
編輯:編輯部 YNH
【新智元導讀】OpenAI o3推理成本從3000美元飆至3萬美元,暴增10倍。o3-high靠暴力試錯生成4300萬字解題,卻被ARC-AGI「除名」。
短短幾個月,最新評估顯示,o3推理成本比預初估計暴漲10倍!
在ARC-AGI最新測試上,AI單次任務曾用3000美元,而如今已飆升至30000美元。
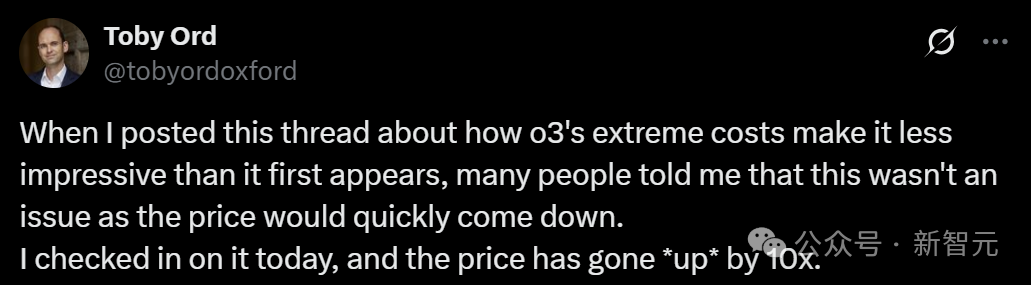
來自牛津大學的高級研究員Toby Ord指出,o3-high看似性能強大,實則更多地依賴於海量計算,而非真正的推理突破。
o3-high在對每個任務嘗試1024次,每次生成137頁文本,總計4300萬字——相當於為每個任務寫了一本《大英百科全書》(4400萬字)。
結果就是,完成每個任務成本高達3萬美金。而這些簡單的謎題,一個10歲的孩子可能只需4分鐘就能解決。
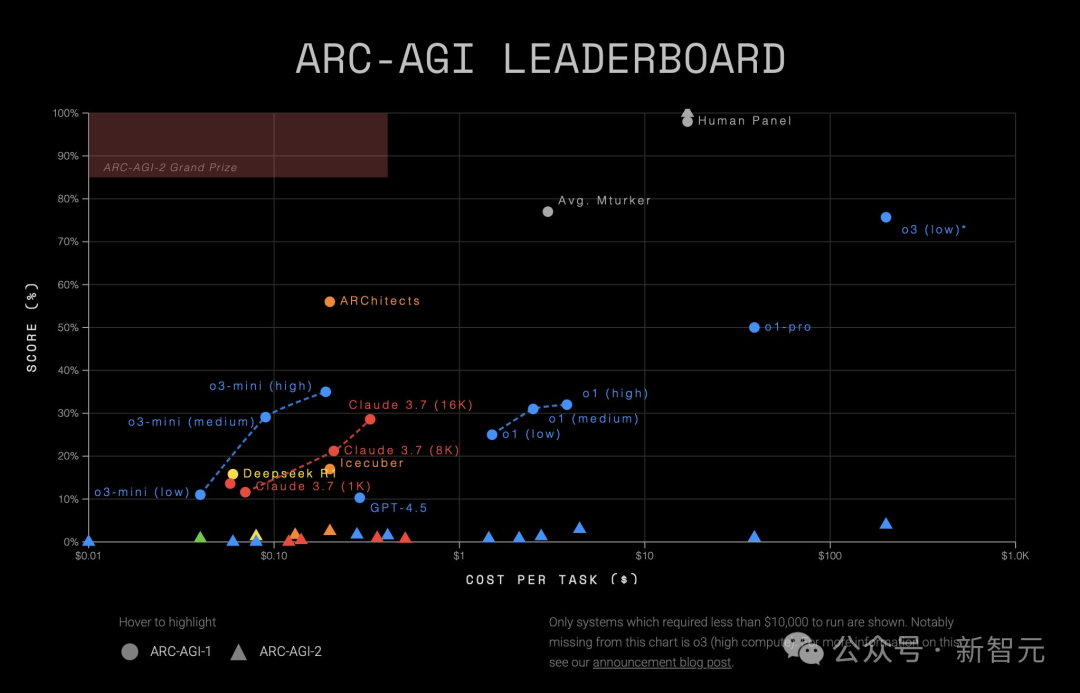 成本飆升直接導致了o3-high超出ARC-AGI每個任務1萬美元限制,直接被排除在排行榜之外
成本飆升直接導致了o3-high超出ARC-AGI每個任務1萬美元限制,直接被排除在排行榜之外甚至,o3-high的算力消耗竟是o3-low的172倍。
這種「暴力試錯」的方式不禁讓人質疑:這真的是智能解題嗎?
從驚豔到驚嚇,o3成本暴增10倍
去年12月,OpenAI推出了推理模型o3。
為了展示o3的強大性能,他們邀請了ARC PrizeFoundation主席Greg Kamradt一同參與那次發佈會。
就在上週,ARC Prize Foundation更新了他們對o3模型計算成本的估算,結果令人震驚。
最初,他們估計o3-low解決一個ARC-AGI任務的成本為20美元,o3-high為3000美元。
而現在,根據修訂後的ARC-AGI表,這些數字分別增加到200美元和3萬美元。
這要比他們預計的成本整整高出10倍,這也可能是OpenAI遲遲沒有正式發佈o3的原因。
成本實在是太高了。
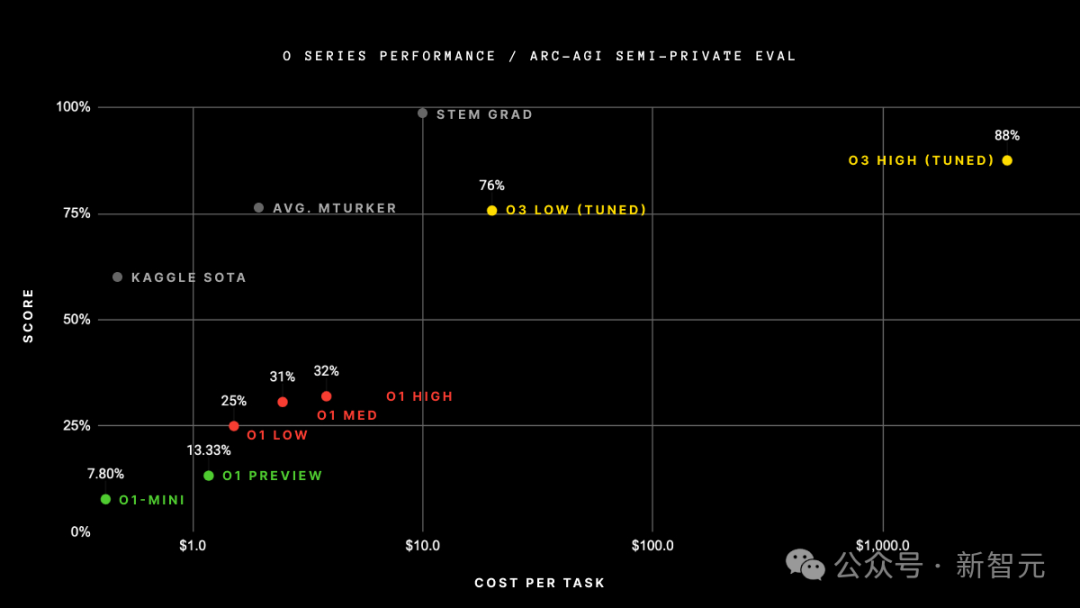
對此,ARC Prize Foundation的聯合創始人之一Mike Knoop表示:「我們認為o1-pro更接近o3的真實成本,因為它在測試時用了大量的計算資源」。
o3的原始估算僅為OpenAI現有o1-pro模型收費的1/10,因此,他們以o1-pro定價作為參考,更新了定價數據。

「但這隻是個參考,我們在排行榜上把o3標記為預覽版,就是為了反映官方定價的不確定性。」
研究員Toby Ord稱,令人失望的是,更新後的圖表顯示,o3整體表現幾乎未超出o1對數收益的趨勢。
他對此推測,或許是因為o3是在ARC-AGI公開測試集的75%上進行了專門的訓練,而OpenAI並未發佈任何消融數據澄清這一增益的來源。
相較之下,o3-mini更讓人眼前一亮,所用的計算資源比o3-high要燒1000倍,卻能展現出真正突破趨勢的表現。
一直以來都有傳言稱OpenAI打算為企業客戶推出昂貴的會員計劃。
有人可能會覺得,即便是如此高的會員費也比請一個員工便宜。
但當一個任務需要3萬美元、4300萬字「暴力堆砌」下才能解決,這種效率是否真的划算。

ARC-AGI五年不敗,難倒了一片AI
提起ARC-AGI,最初只是Keras之父François Chollet在Google一個副業項目,如今卻成為所有AI必考題。
ARC Prize Foundation是一家非營利組織,使命是在基準測試期間成為AGI的北極星。
他們的第一個基準ARC-AGI,是François Chollet於2019年在關於智力測量的論文中發表的,它在AI領域已經保持5年不敗。

隨著模型變得越來越強,上個月,他們更新了ARC-AGI-2。

不像ARC-AGI-1,這個新版本不容易靠蠻力破解。這對AI來講非常難。
難到什麼程度呢?
像GPT-4.5、Claude 3.7 Sonnet、Gemini 2等這些現在頂尖的基礎模型得分都是0%。也就是說一道也解不出來。
推理模型也沒好到哪裡去,Claude Thinking、DeepSeek-R1、o3-mini得分也只有0-1%。
為什麼會這樣?
原因在於ARC-AGI-2的所有任務都需要一些認真的思考。
也就是說,推理模型在解決這些任務時,需要進行大量的推理,消耗非常多的Token。
比如,當前最先進的推理模型在處理需要把符號看作「有意義的內容」時,表現並不好。
它們會嘗試檢查對稱性、做鏡像、進行圖形變換,甚至能識別符號之間的連接關係,但卻無法理解這些符號本身所代表的含義。

符號解釋:ARC-AGI-2公共評估任務#e3721c99
在需要同時運用多條規則,或者這些規則相互影響的任務中表現得也很吃力。
相比之下,如果任務只涉及一條或極少數幾條整體性的規則,AI通常能穩定地發現並正確運用這些規則。
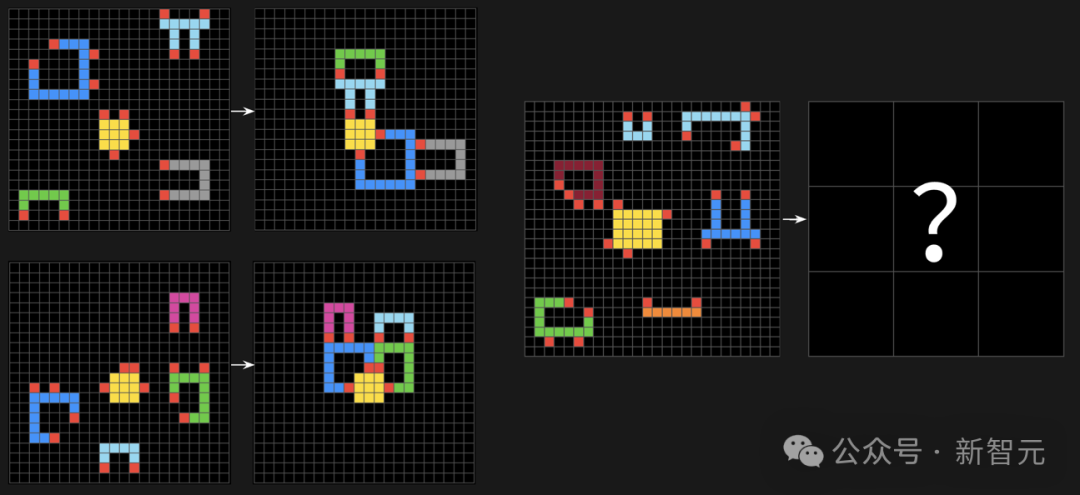
組合推理:ARC-AGI-2公開評估任務 #cbebaa4b
在面對需要根據具體情境靈活應用規則的任務時這些推理模型同樣表現不佳。
它們往往只關注表面模式,而不是理解背後真正的選擇原則。

上下文規則應用:ARC-AGI-2 公共評估任務 #b5ca7ac4
幾年內,AGI或將出現
雖然這些頂尖的推理模型在ARC-AGI的測試中表現不理想,但並沒有妨礙很多人對實現AGI的暢想。
在最新一篇博客中,DeepMind就表示「通用人工智能(AGI)可能在未來幾年內到來」。

結合AI智能體的能力,AGI可以大幅提升AI在理解、推理、規劃和自主執行行動方面的能力。這種技術進步將為社會提供寶貴的工具,以應對包括藥物發現、經濟增長和氣候變化在內的關鍵全球挑戰。
而這也意味著,我們可以期待數十億人將從中獲得切實的益處。例如:
-
通過實現更快速、更精準的醫療診斷,它可以革新醫療保健領域;
-
通過提供個性化的學習體驗,它例如,使教育更加普及且更具吸引力;
-
通過增強信息處理能力,它可以幫助降低創新和創造的門檻;
-
通過使先進工具和知識的獲取更加便捷,它可以讓小型組織有能力解決那些以前只有大型、資金充足的機構才能應對的複雜挑戰。
而現在,o3成本暴漲10倍,智能邊界似乎比我們想像的更遠。
未來幾年,AGI曙光或許將至,但眼下,燒錢智能並不代表著真正的推理突破,我們仍需保持清醒與期待。
參考資料:
https://x.com/tobyordoxford/status/1907379921825014094
OpenAI’s o3 model might be costlier to run than originally estimated