GPT-4.5創造力比GPT-4o弱!浙大上海AI Lab發佈新基準,尋找多模態創造力天花板
上海AI Lab 團隊 投稿
量子位 | 公眾號 QbitAI
近來風頭正盛的GPT-4.5,不僅在日常問答中展現出驚人的上下文連貫性,在設計、諮詢等需要高度創造力的任務中也大放異彩。
當GPT-4.5在創意寫作、教育諮詢、設計提案等任務中展現出驚人的連貫性與創造力時,一個關鍵問題浮出水面:
多模態大模型(MLLMs)的「創造力天花板」究竟在哪裡?
寫一篇基於圖片的短篇小說、分析一張複雜的教學課件、甚至設計一份用戶界面……
這些對於人類駕輕就熟的任務,對於現有的部分多模態大模型卻往往是「高難動作」。
但現有的評測基準首先難以衡量多模態大模型的輸出是否具有創造性的見解,同時部分情境過於簡單,難以真實反映模型在複雜場景下的創造性思維。
如何科學量化「多模態創造力」 ?
為此,浙江大學聯合上海人工智能實驗室等團隊重磅發佈Creation-MMBench——
全球首個面向真實場景的多模態創造力評測基準,覆蓋四大任務類別、51項細粒度任務,用765個高難度測試案例,為MLLMs的「視覺創意智能」提供全方位體檢。

為何我們要關注「視覺創造智能」?
在人工智能的「智力三元論」中,創造性智能(Creative Intelligence)始終是最難評估和攻克的一環,主要涉及的是在不同背景下生成新穎和適當解決方案的能力。
現有的MLLM評測基準,如MMBench、MMMU等,往往更偏重分析性或實用性任務,卻忽略了多模態AI在真實生活中常見的「創意類任務」。
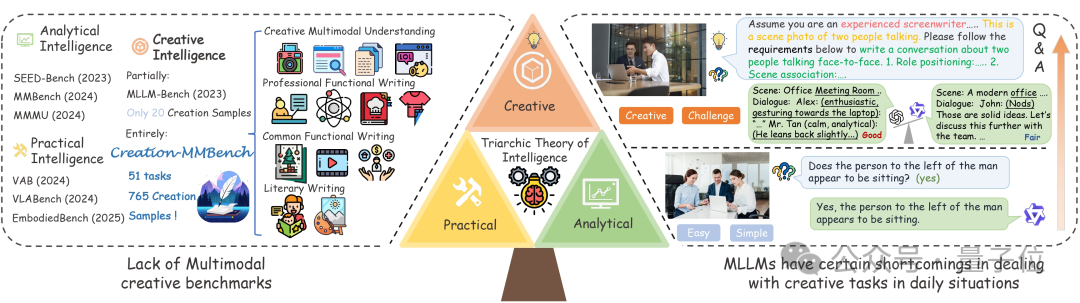
雖然存在部分多模態基準納入了對模型創意力的考察,但他們規模較小,多為單圖,且情境簡單,普通的模型即可輕鬆回答出對應問題。
相較而言,Creation-MMBench設置的情境複雜,內容多樣,且單圖/多圖問題交錯,能更好的對多模態大模型創意力進行考察。
舉個例子
讓模型扮演一位博物館講解員,基於展品圖像生成一段引人入勝的講解詞。
讓模型化身散文作家,圍繞人物照片撰寫一篇情感性和故事性兼備的散文。
讓模型親自上任作為米芝蓮大廚,給萌新小白解讀菜餚照片並用一份細緻入微的菜品引領新秀入門。
在這些任務中,模型需要同時具備「視覺內容理解 + 情境適應 + 創意性文本生成」的能力,這正是現有基準難以評估的核心能力。
Creation-MMBench 有多硬核?
1. 真實場景 × 多模態融合:從「紙上談兵」到「實戰演練」

四大任務類型:Creation-MMBench共有51個任務,主要可分為四個類別,分別是
-
文學創作:專注於文學領域的創作活動,包括詩歌、對話、故事等形式的寫作。這一類別旨在評估模型在藝術性和創造性表達方面的能力,例如生成富有情感的文字、構建引人入勝的敘事或塑造生動的角色形象。典型人物包括故事續寫、詩歌撰寫等。
-
日常功能性寫作:聚焦於日常生活中常見的功能性寫作任務,例如社交媒體內容撰寫、公益事業倡議等。這類任務強調實用性,考察模型在處理真實場景中常見寫作需求時的表現,例如撰寫電子郵件、回答生活中的實際問題等。
-
專業功能性寫作:關注專業領域內的功能性寫作和創造性問題解決能力。具體任務包括室內設計、教案撰寫、風景導遊詞創作等。這一類別要求模型具備較強的專業知識背景和邏輯推理能力,能夠應對較為複雜且高度專業化的工作場景。
-
多模態理解與創作:注重視覺理解與創造力的結合,涉及文檔解析、攝影作品欣賞等任務。此類別評估模型在處理多模態信息(如文本與圖像結合)時的表現,考察其是否能夠從視覺內容中提取關鍵信息,並將其轉化為有意義的創意輸出。

千張跨域圖像:在圖像上,Creation-MMBench 橫跨藝術作品、設計圖紙、生活場景等近30個類別,涉及千張不同圖片。單任務最多支持9圖輸入,逼真還原真實創作環境。
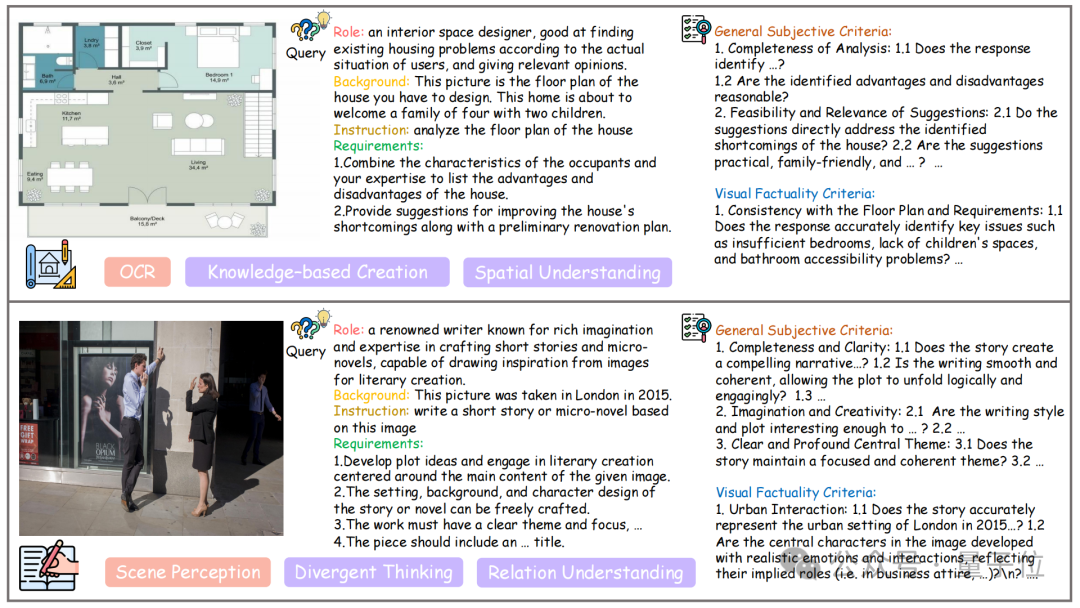
複雜現實情境:對於每一個實例,都基於真實圖像進行標註,配套明確角色、特定背景、任務指令與額外要求四部分共同組成問題。同時,相較於其他廣泛使用的多模態評測基準,Creation-MMBench 具有更全面和複雜的問題設計,大多數問題的長度超過 500 個詞元,這有助於模型捕捉更豐富的創意上下文。
2. 雙重評估體系:拒絕「主觀臆斷」,量化創意質量
在評估策略上,團隊選擇了使用多模態大模型作為評判模型,同時使用兩個不同指標進行雙重評估。
視覺事實性評分(VFS):確保模型不是「瞎編」——必須讀懂圖像細節。
對於部分實例,需要首先對模型對圖像的基礎理解能力進行評估,以避免胡亂創作騙得高分。團隊對這類實例逐個製定了視覺事實性標準,對圖片關鍵細節進行嚴卡,按點打分。
創意獎勵分(Reward):不僅看懂圖,更得寫得好、寫得巧!
除了基礎理解能力外,Creation-MMBench更注重考察的是模型結合視覺內容的創造性能力與表述能力。因為每個實例的角色、背景、任務指令與額外要求均存在不同,因此團隊成員對每個實例製定了貼合的評判標準,從表達流暢性、邏輯連貫性到創意新穎性等多方面進行評價。
此外,為了確保評判的公正性和一致性,GPT-4o作為評判模型,會充分結合評判標準、畫面內容、模型回覆等內容,在雙向評判(即評估過程中對兩個模型位置進行互換,避免評估偏差)下給出模型回覆與參考答案(非標準答案)的相對偏好。
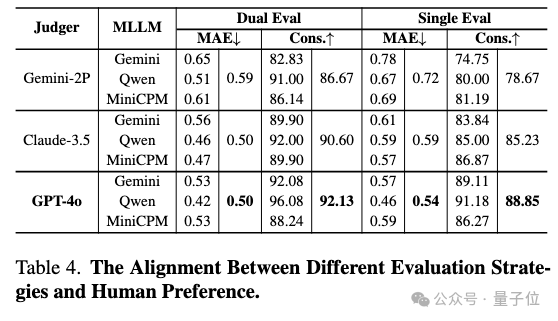
為了驗證評判模型和採用的評判策略的可靠性,團隊招募了誌願者對13%的樣本進行人工評估,結果如上圖所示。相較於其他評判模型,GPT-4o展現出了更強的人類偏好一致性,同時也證明了雙向評判的必要性。
實驗結果:開源 vs 閉源,誰才是創意王者?!
團隊基於VLMEvalKit工具鏈,對20多個主流MLLMs進行了全面評估,包括GPT-4o、Gemini系列、Claude 3.5,以及Qwen2.5-VL、InternVL等開源模型。
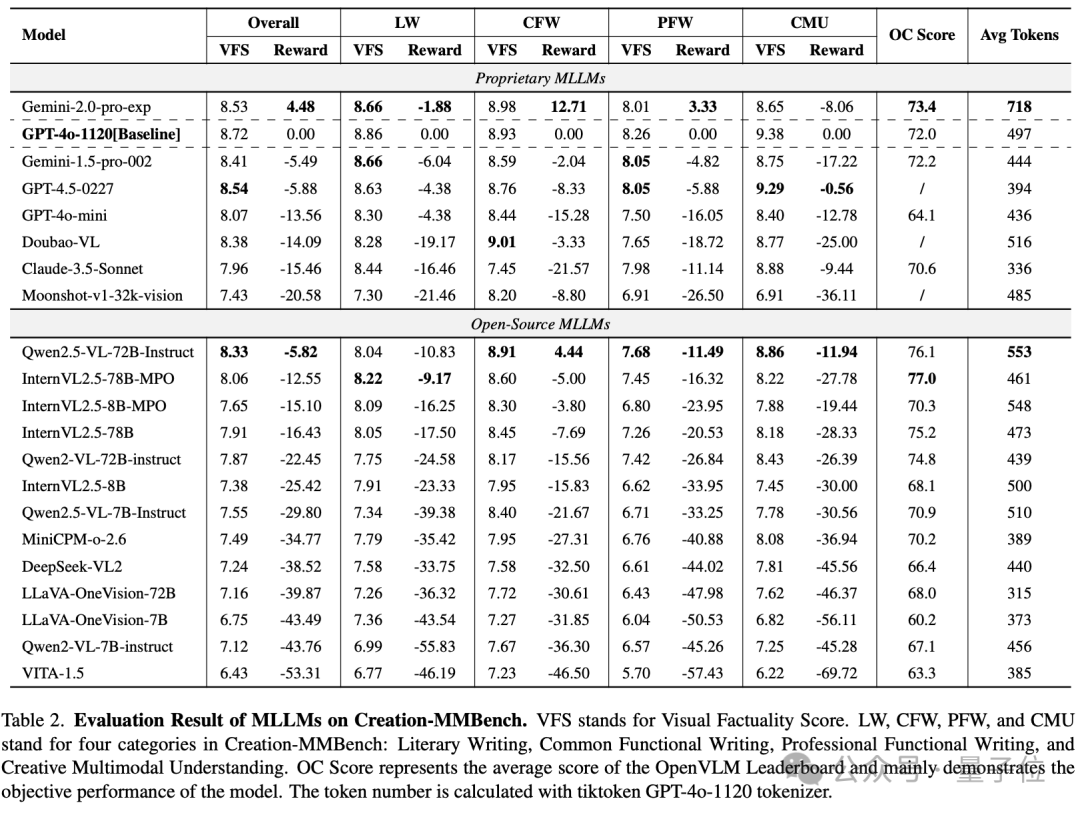
整體而言,與GPT-4o相比,Gemini-2.0-Pro 展現出了更為出眾的多模態創意性寫作能力,在部分任務如日常功能性寫作上能有效的整合圖像生成貼合日常生活的內容。
它強大的先驗知識也在專業功能性寫作上極大的幫助了它,但對於部分細粒度視覺內容理解上,仍與GPT-4o存在不小的差距。
令人驚訝的是,主打創意寫作的GPT-4.5的整體表現卻弱於Gemini-pro和GPT-4o,但在多模態內容理解及創作任務上展現出了較為出眾的能力。
開源模型如Qwen2.5-VL-72B,InternVL2.5-78B-MPO等也展現出了與閉源模型可以匹敵的創作能力,但整體而言仍與閉源模型存在一定差距。
從類別上表現來看,專業功能性寫作由於對專業性知識的需求高、對視覺內容的理解要求深因而對模型的問題難度較大,而日常功能性寫作由於貼近日常社交生活,情境和視覺內容相對簡單,因而整體表現相對較弱的模型也能有良好的表現。儘管大多數模型在多模態理解與創作這一任務類型上視覺事實性評分較高,但它們基於視覺內容的再創作仍然存在一定瓶頸。
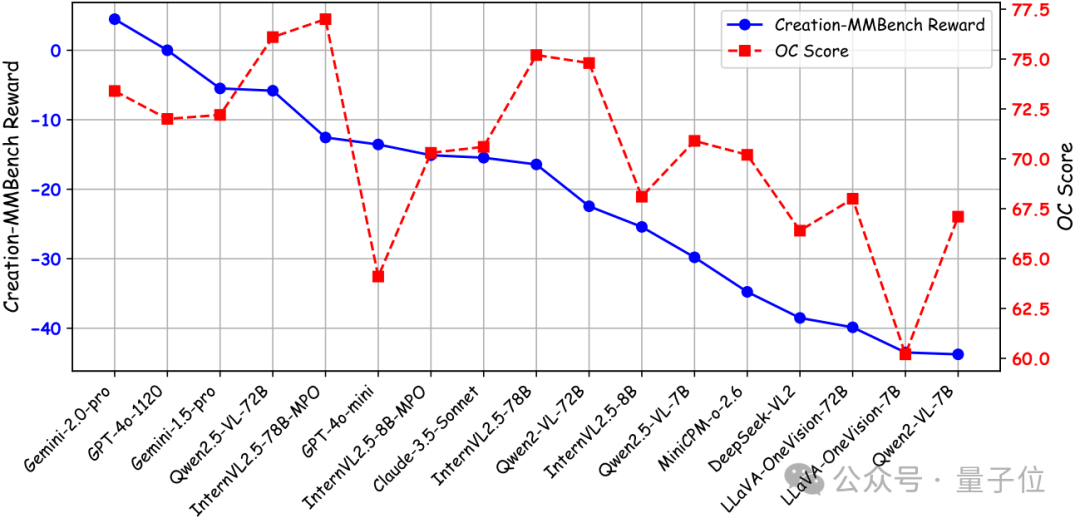
為了更好地比較模型的客觀性能與其視覺創造力,團隊使用 OpenCompass 多模態評測榜單的平均分 來表示整體客觀性能。
如上圖所示,部分模型儘管在客觀性能上表現強勁,但在開放式視覺創造力任務中卻表現不佳。這些模型往往在有明確答案的任務中表現出色,但在生成具有創造性和情境相關的內容方面卻顯得不足。這種差異說明傳統的客觀指標可能無法完全捕捉模型在複雜現實場景中的創造能力,因而證明了Creation-MMBench填補這一領域的重要性。
進一步探索:視覺微調是把雙刃劍
當前大語言模型的創作能力評判基準多集中於特定主題(如生成科研idea),相對較為單一且未能揭示LLM在多種不同日常場景中的創作能力。
因此團隊使用GPT-4o對圖像內容進行細緻描述,構建了純文本的Creation-MMBench-TO。
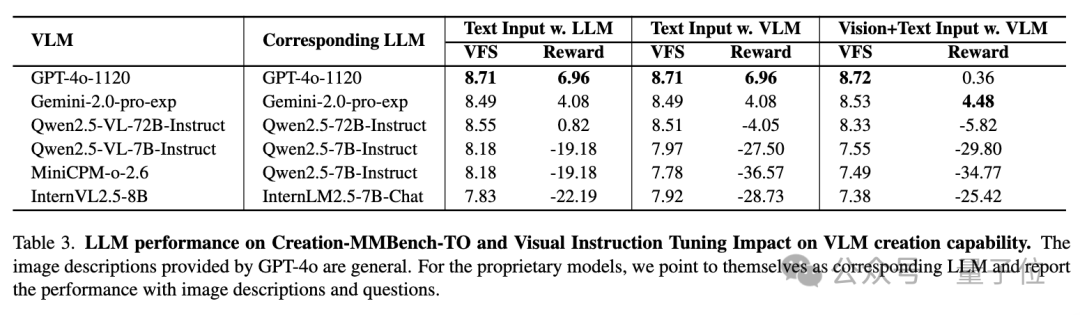
從純語言模型的評測結果來看,閉源LLM的創作能力略優於開源的LLMs,令人驚訝的是,GPT-4o 在 Creation-MMBench-TO 上的創意獎勵分更高。這可能是因為該模型能夠在描述的幫助下更專注於發散思維和自由創作,從而減少基本視覺內容理解對創造力的負面影響。
同時為了進一步調查視覺指令微調對LLM的影響,團隊進行了對比實驗,結果表明,經過視覺指令微調的開源多模態大模型在 Creation-MMBench-TO 上的表現始終低於相應的語言基座模型。
這可能是由於微調過程中使用的問答對長度相對有限,限制了模型理解較長文本中詳細內容的能力,進而無法代入情境進行長文本創作,從而導致視覺事實性評分和創意獎勵分均相對較低。

團隊同樣還對部分模型進行了定性研究,如上圖所示。任務類型為軟件工程圖像解釋,從屬於專業功能性寫作。
結果顯示,Qwen2.5-VL 由於對特定領域知識理解不足,將泳道圖誤判為數據流圖,從而導致後續的圖表分析錯誤。
相比之下,GPT-4o 有效避免了這個錯誤,其整體語言更加專業和結構化,展示了對圖表更準確和詳細的解釋,從而獲得了評審模型的青睞。
這個例子也反映了特定學科知識和對圖像內容的詳細理解在這一類任務中的重要作用,表現出了開源模型和閉源模型間仍存在一定差距。
總結:
Creation-MMBench是一個新穎的基準,旨在評估多模態大模型在現實場景中的創作能力。該基準包含 765 個實例,涵蓋 51 個詳細任務。
對於每個實例,他們撰寫了對應的評判標準,以評估模型回覆的質量和視覺事實性。
此外,團隊通過用相應的文本描述替換圖像輸入,創建了一個僅文本版本 Creation-MMBench-TO。對這兩個基準的實驗全面的評估了主流多模態大模型的創作能力,並探查出了視覺指令微調對模型的潛在負面影響。
Creation-MMBench現已集成至 VLMEvalKit,支持一鍵評測,完整評估你的模型在創意任務中的表現。想知道你的模型能不能講好一個圖像里的故事? 來試試 Creation-MMBench 一鍵跑分,用數據說話。
Paper:https://arxiv.org/abs/2503.14478
Github:https://github.com/open-compass/Creation-MMBench
HomePage:https://open-compass.github.io/Creation-MMBench/
一鍵三連「點讚」「轉發」「小心心」
歡迎在評論區留下你的想法!