CVPR 2025 | GaussianCity: 60倍加速,讓3D城市瞬間生成

想像一下,一座生機勃勃的 3D 城市在你眼前瞬間成型 —— 沒有漫長的計算,沒有龐大的存儲需求,只有極速的生成和驚人的細節。
然而,現實卻遠非如此。現有的 3D 城市生成方法,如基於 NeRF 的 CityDreamer [1],雖然能夠生成逼真的城市場景,但渲染速度較慢,難以滿足遊戲、虛擬現實和自動駕駛模擬對實時性的需求。而自動駕駛的 World Models [2],本應在虛擬城市中訓練 AI 駕駛員,卻因無法保持多視角一致性而步履維艱。
現在,新加坡南洋理工大學 S-Lab 的研究者們提出了 GaussianCity,該工作重新定義了無界 3D 城市生成,讓它變得 60 倍更快。過去,你需要數小時才能渲染一片城區,現在,僅需一次前向傳播,一座完整的 3D 城市便躍然眼前。無論是遊戲開發者、電影製作者,還是自動駕駛研究者,GaussianCity 都能讓他們以秒級的速度構建世界。
城市不該等待生成,未來應該即刻抵達。
 觀看Demo,發現GaussianCity與其他方法的顯著差異!
觀看Demo,發現GaussianCity與其他方法的顯著差異!
 閱讀論文,深入瞭解GaussianCity的技術細節。
閱讀論文,深入瞭解GaussianCity的技術細節。

-
Paper:https://arxiv.org/abs/2406.06526
-
Code:https://github.com/hzxie/GaussianCity
-
Project Page:https://haozhexie.com/project/gaussian-city
-
Live Demo: https://huggingface.co/spaces/hzxie/gaussian-city
引言
3D 城市生成的探索正面臨著一個關鍵挑戰:如何在無限擴展的城市場景中實現高效渲染與逼真細節的兼得?現有基於 NeRF 的方法雖能生成細膩的城市景觀,但其計算成本極高,難以滿足大規模、實時生成的需求。近年來,3D Gaussian Splatting(3D-GS)[3] 憑藉其極高的渲染速度和優異的細節表現,成為對象級 3D 生成的新寵。然而,當嘗試將 3D-GS 擴展至無界 3D 城市時,面臨了存儲瓶頸和內存爆炸的問題:數十億個高斯點的計算需求輕易耗盡上百 GB 的顯存,使得城市級別的 3D-GS 生成幾乎無法實現。
為瞭解決這一難題,GaussianCity 應運而生,首個用於無邊界 3D 城市生成的生成式 3D Gaussian Splatting 框架。它的貢獻可以被歸納為:
-
通過創新性的 BEV-Point 表示,它將 3D 城市的複雜信息高度壓縮,使得顯存佔用不再隨場景規模增長,從而避免了 3D-GS 中的內存瓶頸。
-
借助空間感知 BEV-Point 解碼器,它能夠精準推測 3D 高斯屬性,高效生成複雜城市結構。
-
實驗表明,GaussianCity 不僅在街景視角和無人機視角下實現了更高質量的 3D 城市生成,還在推理速度上比 CityDreamer 快 60 倍,大幅提高了生成效率。
具體來說,得益於 BEV-Point 的緊湊表示,GaussianCity 可以在生成無界 3D 城市時保持顯存佔用的恒定,而傳統 3D-GS 方法在點數增延長顯存使用大幅上升(如下圖(b)所示)。同時,BEV-Point 在文件存儲增長上也遠遠低於傳統方法(如下圖(c)所示)。不僅如此,GaussianCity 在生成質量和效率上都優於現有的 3D 城市生成方法,展現了其在大規模 3D 城市合成中的巨大潛力(如下圖(d)所示)。
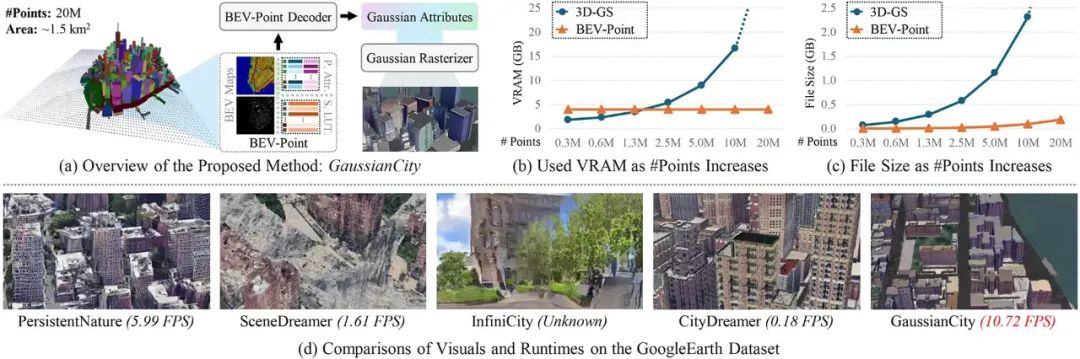
方法
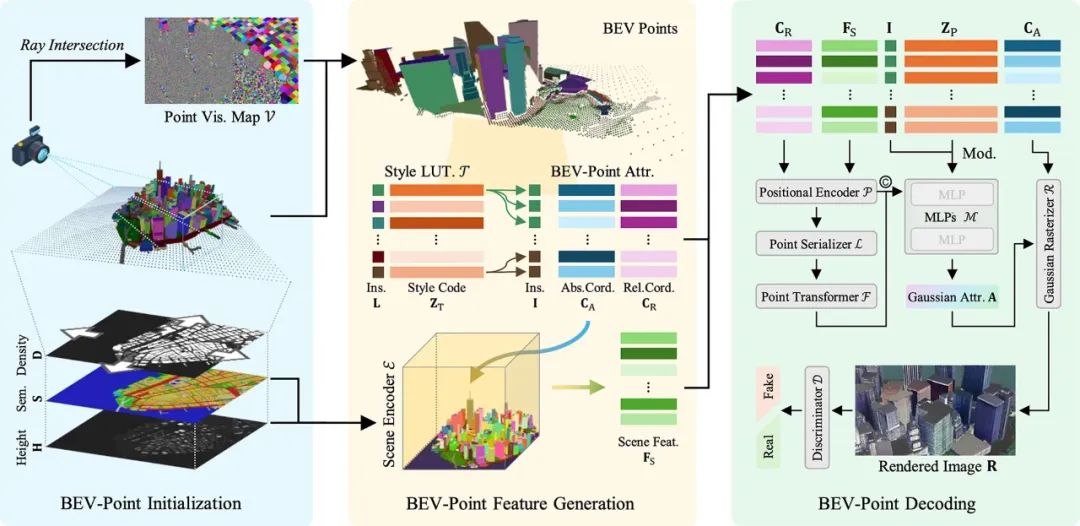
如上圖所示,GaussianCity 將 3D 城市生成過程分為三個主要階段:BEV-Point的初始化、特徵生成和解碼。
BEV-Point 初始化
在 3D-GS 中,所有 3D 高斯點在優化過程中都會使用一組預定義的參數進行初始化。然而,隨著場景規模的增加,顯存需求急劇上升,導致生成大規模場景變得不可行。為此,GaussianCity 採用 BEV-Point 進行優化,以緩解這一問題。
BEV 圖 是生成 BEV-Point 的基礎,包含三個核心圖像:高度圖(Height Map)、語義圖(Semantic Map)和 密度圖(Density Map)。從BEV 圖 中,BEV-Point被生成:
-
高度圖 決定每個點在空間中的 3D 坐標。
-
語義圖 提供每個點的語義標籤,如建築、道路等。
-
密度圖 調整采樣密度,根據不同區域的特徵決定是否增加或減少采樣點。
BEV-Point 通過只保留可見點大幅減少計算量。由於相機視角固定,場景中不可見的點不影響渲染結果,因而不佔用顯存。這樣,隨著場景擴展,顯存使用量保持恒定。
為了優化計算,二值密度圖根據語義類別調整采樣密度。對於簡單紋理(如道路、水域)減少密度,複雜紋理(如建築物)則增加密度。
通過射線交點(Ray Intersection)方法篩選出可見的 BEV-Point,確保僅這些點參與後續渲染和優化,進一步提升計算效率。
BEV-Point 特徵生成
在 BEV-Point 表示中,特徵可分為三大類:實例屬性、BEV-Point 屬性和樣式查找表。
1.實例屬性
實例屬性包括每個實例的基本信息,如實例標籤、大小和中心坐標等。語義圖提供了每個 BEV 點的語義標籤。為了處理城市環境中建築物和車輛的多樣性,引入了實例圖來區分不同的實例。通過檢測連接組件(Connected Components)的方式,將語義圖進行實例化,從而得到每個實例的標籤、大小和邊界框的中心坐標。
2.BEV-Point 屬性
在 BEV-Point 初始化時,生成了每個點的絕對坐標,並設定其原點在世界坐標系的中心。為了更精確地描述每個實例的相對位置,相對坐標系被引入。其原點設置在每個實例的中心,並通過標準化的方式來計算相對坐標。
為了融入更多的上下文信息,場景特徵
從 BEV 圖中提取,並通過點的絕對坐標進行索引,進一步為每個 BEV 點提供更豐富的上下文信息。
3.樣式查找表(Style Look-up Table)
在 3D-GS 中,每個 3D 高斯點的外觀都由其自身的屬性決定,導致存儲開銷隨著高斯點數量的增加而顯著增長,使得大規模場景的生成變得不可行。為瞭解決這一問題,BEV-Point 採用隱向量(Latent Vector)來編碼實例的外觀,使得相同的實例共享同一個隱向量,並通過樣式查找表為不同實例分配樣式,從而減少計算與存儲開銷。
BEV-Point 解碼
BEV-Point 解碼器用於從 BEV-Point 特徵生成高斯點屬性,主要包括五個模塊:位置編碼器、點序列化器、Point Transformer、Modulated MLPs、以及高斯光柵化器。
1.位置編碼器(Positional Encoder)
為了更好地表達空間信息,BEV-Point 坐標和特徵不會直接輸入網絡,而是經過位置編碼轉換為高維嵌入,從而提供更豐富的表徵能力。
2.點序列化器(Point Serializer)
BEV-Point 是無序點雲,直接用 MLP 可能無法充分利用其結構信息。因此,我們引入點序列化方法,將點坐標轉換為整數索引,使相鄰點在數據結構中更具空間連續性,優化信息組織方式。
3.Point Transformer
序列化後的點特徵經過 Point Transformer V3 [10] 進一步提取上下文信息,增強 BEV-Point 的全局和局部關係建模能力。
4.Modulated MLPs
在生成 3D 高斯點屬性時,MLP 結合 BEV-Point 特徵、Point Transformer 提取的特徵、實例的樣式編碼及標籤,以確保生成的高斯點具有一致的外觀和風格。
5.高斯光柵化器(Gaussian Rasterizer)
最終,結合相機參數,BEV-Point 生成的 3D 高斯點屬性通過高斯光柵化器進行渲染。對於未生成的某些屬性,如尺度、旋轉、透明度,則使用預設值填充。
實驗
下圖展示了 GaussianCity 和其他 SOTA 方法的對比,這些方法包括 PersistentNature [4]、SceneDreamer [5] 、InfiniCity [6] 和 CityDreamer [1]。實驗結果表明,GaussianCity 的效果明顯優於其他方法,相比於 CityDreamer 更是取得了 60 倍的加速。

在街景圖生成上,GaussianCity 在 KI湯臣I-360 [7] 數據集上進行訓練,其生成效果超越了 GSN [8] 和 UrbanGIRAFFE [9] 等多種方法。

總結
本研究提出了 GaussianCity,首個針對無邊界 3D 城市生成的生成式 3D Gaussian Splatting 框架。通過引入創新性的 BEV-Point 表示,GaussianCity 在保證高效生成的同時,克服了傳統 3D-GS 方法在大規模場景生成中面臨的顯存瓶頸和存儲挑戰。該方法不僅實現了在街景和無人機視角下的高質量城市生成,還在推理速度上相比 CityDreamer 提升了 60 倍,顯著提高了生成效率。實驗結果表明,GaussianCity 能夠在確保細節還原的同時,高效處理無邊界 3D 城市生成,為大規模虛擬城市的實時合成開闢了新路徑。
參考文獻
[1] CityDreamer: Compositional Generative Model of Unbounded 3D Cities. CVPR 2024.
[2] A Survey of World Models for Autonomous Driving. arXiv 2501.11260.
[3] 3D Gaussian Splatting for Real-Time Radiance Field Rendering. SIGGRAPH 2023.
[4] Persistent Nature: A Generative Model of Unbounded 3D Worlds. CVPR 2023.
[5] SceneDreamer: Unbounded 3D Scene Generation from 2D Image Collections. TPAMI 2023.
[6] InfiniCity: Infinite-Scale City Synthesis. ICCV 2023.
[7] KI湯臣I-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D. TPAMI 2023.
[8] Unconstrained Scene Generation with Locally Conditioned Radiance Fields. ICCV 2021.
[9] UrbanGIRAFFE: Representing Urban Scenes as Compositional Generative Neural Feature Fields. ICCV 2023.
[10] Point Transformer V3: Simpler, Faster, Stronger. CVPR 2024.