三思而後行,讓大模型推理更強的秘密是「THINK TWICE」?

近年來,大語言模型(LLM)的性能提升逐漸從訓練時規模擴展轉向推理階段的優化,這一趨勢催生了「測試時擴展(test-time scaling)」的研究熱潮。OpenAI 的 o1 系列與 DeepSeek 的 R1 模型已展示出顯著的推理能力提升。然而,在實現高性能的同時,複雜的訓練策略、冗長的提示工程和對外部評分系統的依賴仍是現實挑戰。
近日,由 a-m-team 團隊提出的一項新研究提出了一個更簡潔直觀的思路:三思而後行(Think Twice)。它不依賴新的訓練,不引入複雜機制,僅通過一種非常人類式的思維策略 ——「再想一輪」—— 在多個基準任務中帶來顯著性能提升。

-
論文標題:Think Twice: Enhancing LLM Reasoning by Scaling Multi-round Test-time Thinking
-
論文連接:https://arxiv.org/abs/2503.19855
-
項目地址:https://github.com/a-m-team/a-m-models
「Multi-round Thinking」
一輪不夠,那就兩輪、三輪
該方法的核心思想類似於人類在做題時的反思機制:模型先基於原始問題生成第一次答案,再將該答案(而非推理過程)作為新的提示,促使模型獨立 「重答」 一次,並在每一輪中不斷修正先前的偏誤。
這個過程中,模型不會受限於上一次的推理軌跡,而是以一個「結果驅動」的方式自我反思與糾錯,逐步逼近更合理的答案。研究人員指出,這種策略有效緩解了大模型推理中常見的 「認知慣性」,即模型過度依賴初始推理路徑而難以跳脫錯誤邏輯。
不靠訓練,也能提升多個基準性能
研究團隊在四個權威數據集上驗證了該方法,包括:
-
AIME 2024(美國數學邀請賽)
-
MATH-500(由 OpenAI 從原始 MATH 數據集中精選出 500 個最具挑戰性的問題)
-
GPQA-Diamond(研究生級別問答)
-
LiveCodeBench(編程任務)
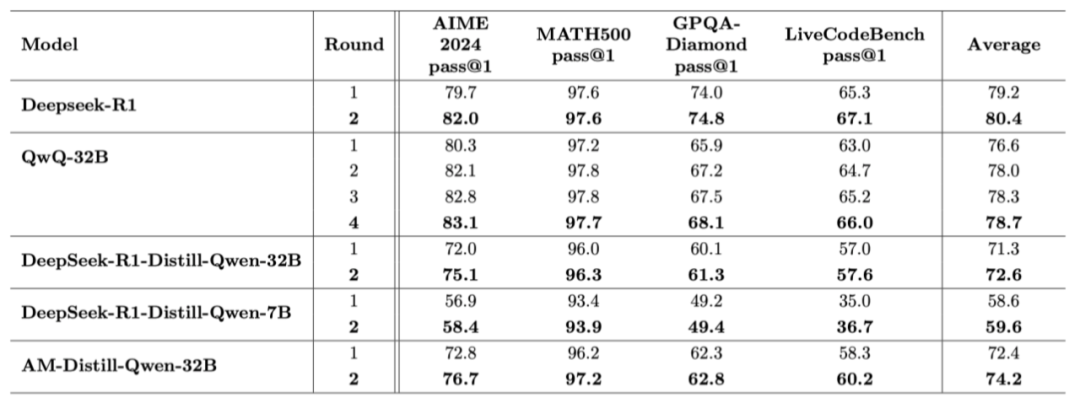
在不改變模型結構、無額外訓練的前提下,DeepSeek-R1 和 QwQ-32B 等主流模型在所有測試集上均表現出不同程度的提升。例如:
-
DeepSeek-R1 在 AIME 上從 79.7% 提升至 82.0%
-
QwQ-32B 在 AIME 上從 80.3% 提升至 83.1%
更值得注意的是,在進行 2 輪、3 輪甚至 4 輪的 「再思考」 後,準確率穩步上升,模型表現出更強的穩定性和反思能力。
更短的答案、更少的猶豫
模型開始 「自信發言」
除了準確率的提升,研究團隊還觀察到了語言風格的變化。通過分析模型生成內容中 「but」、「wait」、「maybe」、「therefore」 等語氣詞的使用頻率,他們發現:
-
模型在第二輪中使用 「but」、「wait」 等不確定詞的頻率明顯減少;
-
即使在多輪中仍答錯,模型的表達也趨向更加簡潔、自信;
-
當模型成功從錯誤中修正時,常伴隨著更慎重的過渡語,例如 「wait」、「therefore」 增多。
這種變化表明,多輪推理不僅提升了結果準確性,也改變了模型的表達風格,使其在回答時更加 「像人類」,且邏輯清晰。
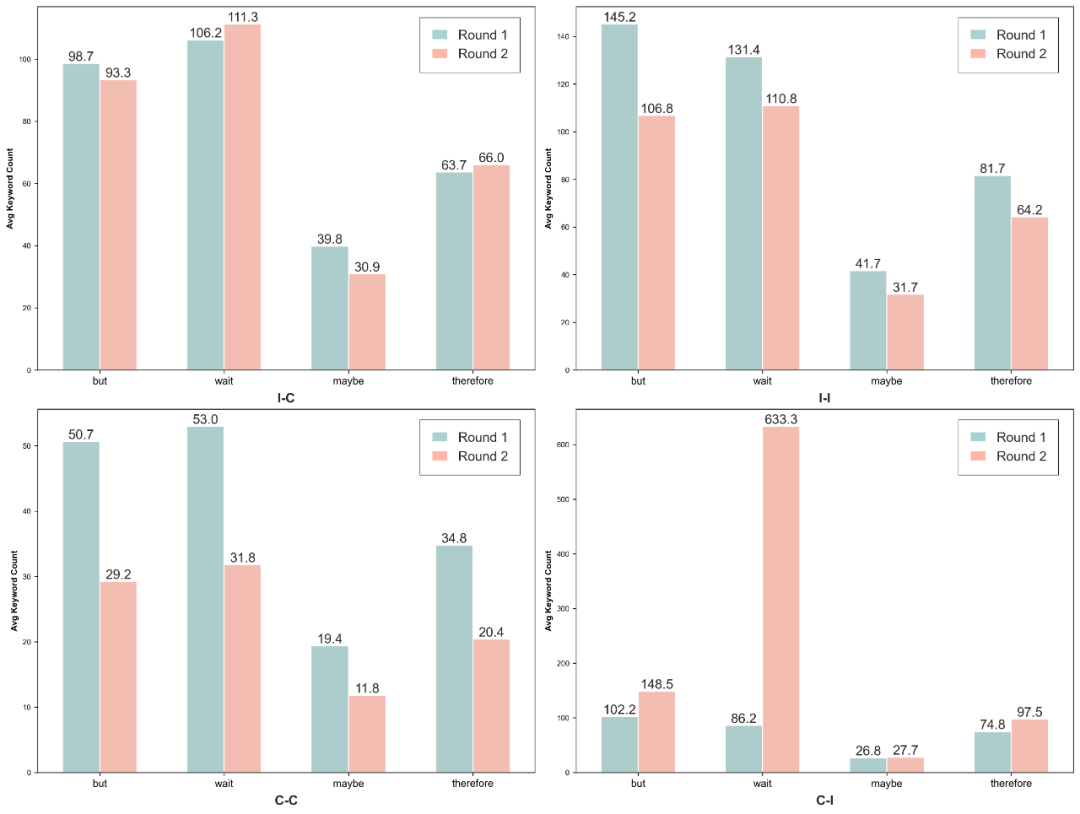
不同推理路徑中平均詞頻的變化。每個子圖展示了四個具有代表性的詞語 —— 「but」(但是)、「wait」(等等)、「maybe」(也許)和 「therefore」(因此)—— 在第 1 輪與第 2 輪中的平均詞頻,對回答類型進行分組:I-C(錯誤 → 正確)、I-I(錯誤 → 錯誤)、C-C(正確 → 正確)和 C-I(正確 → 錯誤)。
多做題同時多思考
可能是更好路徑
這項研究的一個關鍵優勢在於:它完全作用於推理階段,不需要額外的訓練資源,即插即用。這種方法對於模型部署階段的優化具有高度實用性,同時也為後續研究提供了可拓展的思路 —— 如何結合監督微調,或構建更智能的多輪判斷機制。
目前研究團隊已嘗試使用基於多輪推理結果的監督微調數據對模型進一步訓練,初步結果顯示尚未顯著突破,但為 「訓練 + 推理」 的結合方向奠定了基礎。
結語
「Think Twice」 展示了一種簡單有效的思路:鼓勵大模型主動 「反思」,用多輪推理激發更強的認知能力。它不僅提升了準確率,更令模型在語言表達上變得更加理性、緊湊、自信。
在訓練成本不斷攀升的今天,這種無需再訓練的 「輕量級優化」 無疑具有極強的現實吸引力。未來,多輪推理或許能成為一種標準機制,幫助模型更接近真正意義上的 「會思考」。