CVPR 2025 Oral | 多模態交互新基準OpenING,新版GPT-4o殺瘋了?

文生圖 or 圖生文?不必糾結了!
人類大腦天然具備同時理解和創造視覺與語言信息的能力。一個通用的多模態大語言模型(MLLM)理應複刻人類的理解和生成能力,即能夠自如地同時處理與生成各種模態內容,實現多模態交互,這也是向通用人工智能(AGI)邁進的關鍵挑戰之一。最近爆火的新版 GPT4o 與 Gemini-2.0 在圖文交互這方向上也帶來了令人振奮的效果。
然而,當前大部分多模態大語言模型仍局限於處理單一的圖像或文本,特別是難以實現內容流暢一致的多模態交錯生成。而現實生活中,以設計、教育、內容創作等代表的任務,往往需要獲取圖文交錯的內容作為參考,這對模型的多模態生成能力提出了挑戰。
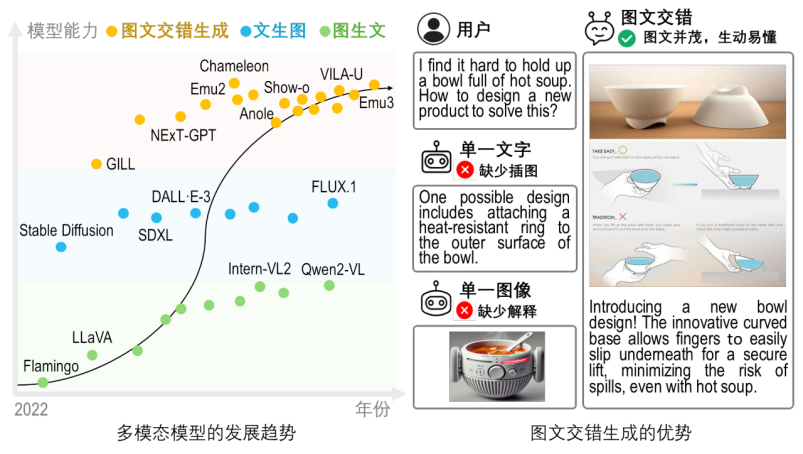
近日,上海人工智能實驗室提出了首個面向開放式圖文交錯生成任務的綜合評測基準 OpenING,相關論文成果已被 CVPR2025 接收為 Oral。該基準包含:1)多樣化的真實圖文生成任務與高質量的標註數據;2)通過增強訓練得到的可靠球證模型 IntJudge;3)對目前圖文交錯生成模型 / 統一理解生成模型進行的綜合評測、排名與分析。研究中的關鍵發現與結論能夠為下一代統一理解與生成的多模態大語言模型的研發提供了重要的啟發與指導。

-
論文標題:OpenING: A Comprehensive Benchmark for Judging Open-ended Interleaved Image-Text Generation
-
技術報告: https://arxiv.org/abs/2411.18499
-
項目主頁: https://opening-benchmark.github.io/
-
代碼地址: https://github.com/LanceZPF/OpenING
OpenING 基準:更豐富、更真實、更全面
現有評測基準(如 OpenLEAF 和 InterleavedBench)存在規模小、主題多樣性不足、數據來源受限等問題,且因過於依賴開源數據集作為數據來源導致數據汙染的風險,難以滿足真實場景的應用需求。

為此,OpenING 應運而生!
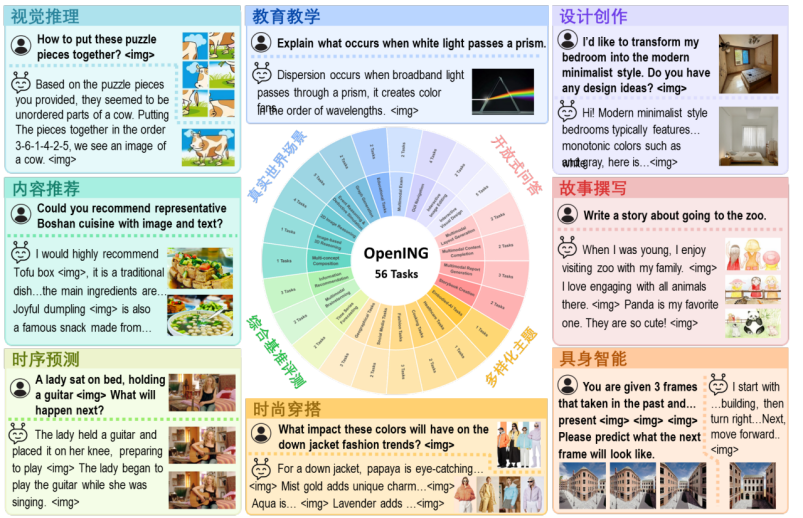
OpenING 首次系統地構建了涵蓋 23 個現實領域、56 個具體任務的圖文交錯生成綜合評測基準,共計收集 5400 個真實場景下的圖文交錯實例。這些實例來源於旅行指南、產品設計、烹飪助手、創意頭腦風暴等日常高頻應用場景。

OpenING 特別設計了高效的標註工具 IntLabel,由超過 50 人的專業團隊嚴格把關,並通過精細化的標註流程確保了數據的一致性與真實性。OpenING 的數據劃分為開發集和測試集兩個部分,為 Judge 模型的訓練和評測分析提供了堅實的基礎。
強大評估模型 IntJudge:告別 GPT 偏見!
傳統基於 GPT 的評測模型(比如 GPT-as-a-Judge)容易受到模型本身偏見,傾向於給自家生成的內容更高的評分。另外此類評測模型因為受到潛在的數據泄露的影響,使得評測的準確性和穩定性存疑。為了獲得更加公平、精準、穩定的評測結果,OpenING 團隊自主研發了一款名為 IntJudge 的評估模型。
IntJudge 的訓練集採用了全新的人機協作標註方法 —Interleaved Arena,並在訓練過程利用一種參考增強生成 Reference-Augmented Generation(RAG)的數據增強策略。通過融合人類專家評估數據和自動生成的數據,該策略大幅提升評測模型的魯棒性和泛化能力。
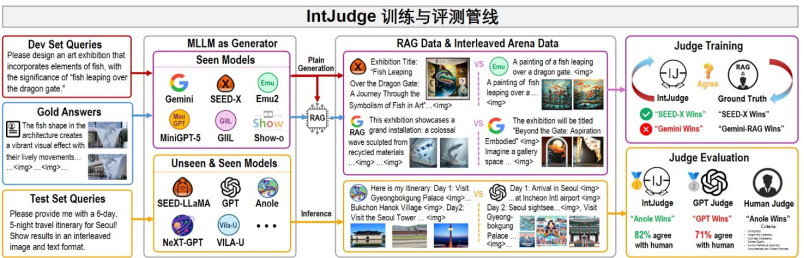
具體來講,IntJudge 的訓練數據由兩部分組成:一是高質量對比數據 Interleaved Arena Data,這些數據通過對不同模型在 OpenING 開發集上生成的的圖文交錯內容進行人工判斷獲得;二是利用參考增強生成(RAG)技術構建的大規模增強數據 RAG Data,通過在每個 AB 對中認定以人工標註的金標準答案為參考的生成內容優於模型直接生成的內容。這種新穎的數據增強策略在極大豐富 IntJudge 模型訓練數據量的同時確保了評測模型在多種生成風格和場景下的穩定表現。
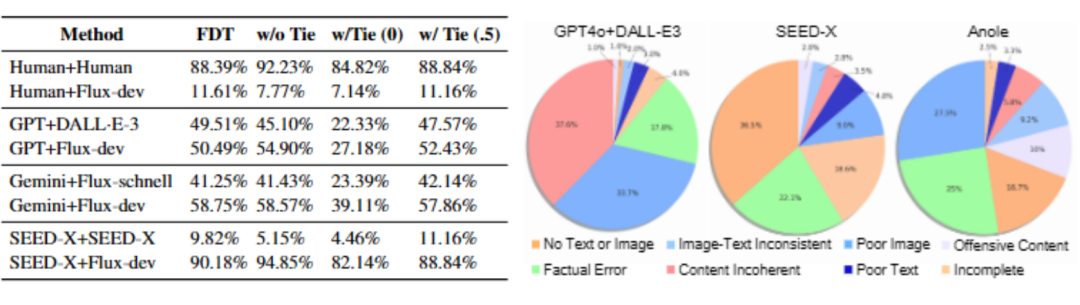
開放式問題的正確性通常難以直接判斷,為此 OpenING 採用了類 ELO 機制的相對評分策略。該策略通過采樣形成模型間的兩兩(AB Pair)對比,獲得對模型客觀性能評測的排行榜。這些客觀指標包括強製區分和波指標 FDT, 以及該指標在包括和波 w/ Tie 和不包括和波 w/o Tie 的兩種情況的指標。此外,OpenING 還提供多種額外評估指標, 包括基於 GPT-as-a-judge 的主觀評測。

憑藉創新的數據構建策略,IntJudge 與人類判斷的一致率達到 82.42%,相較於基於 GPT 系列的評測方法 IntJudge 顯著高出 11.34% . 此外,IntJudge 不僅適用於大規模自動化評測場景,還能夠作為 Reward Model 直接應用於 GRPO 等強化學習(RL)訓練,對多模態生成模型的性能和生成質量進行有效提升。IntJudge 訓練過程中構建的 Interleaved Arena 數據也為多模態生成領域的直接偏好優化(DPO)研究提供了寶貴資源,進一步啟發和促進該方向的深入探索。
模型生成性能大揭秘,與人類差距依然明顯!
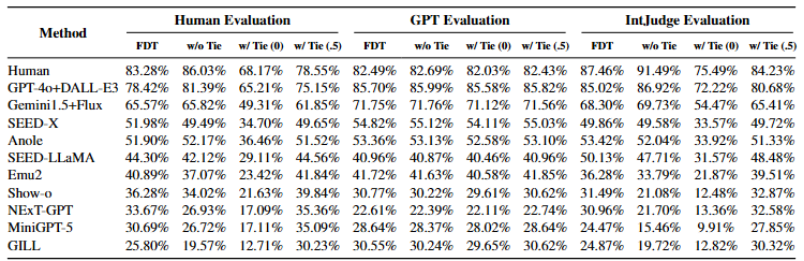
基於 OpenING 的詳盡評測揭示了當前主流多模態模型的表現:
-
集成管道模型(如 GPT-4o+DALL・E-3 和 Gemini 1.5+Flux)得益於高性能基礎模型的協同,整體表現優於其它模型。其生成內容在圖文一致性與視覺質量方面均處領先地位。此外,這類交錯生成管道的性能很大程度上取決於圖像生成模型的能力。與其它主流圖像生成模型相比,Flux-dev 在與多種文本模型搭配使用時展現出顯著的性能提升
-
端到端模型(如 Anole、MiniGPT-5)具有統一的圖文生成模型架構,其簡潔的生成方式展現出了巨大的發展潛力。然而,目前此類模型在圖像和文本生成的綜合能力上仍存在較大提升空間
-
文本生成方面,GPT 系列模型的質量已達到甚至超越人類水平,但在圖像生成質量和真實性方面,所有模型的生成結果仍難以企及人工標註的自然圖像。
通過詳細的誤差分析發現當前模型普遍存在諸如圖像視覺質量差、連續生成的內容不一致、以及無法有效生成圖像或文本等問題。這些發現為下一步模型優化指明了明確的研究方向。此外,研究團隊還針對不同類型模型(如 GPT-4o+DALL-E3、SEED-X、Anole 等)出現的具體問題進行了分析(例如事實性錯誤,文本或圖片、圖片風格不一致、生成效率不足等)並總結了問題出現的比例,為未來的方法優化提出了明確的路徑。
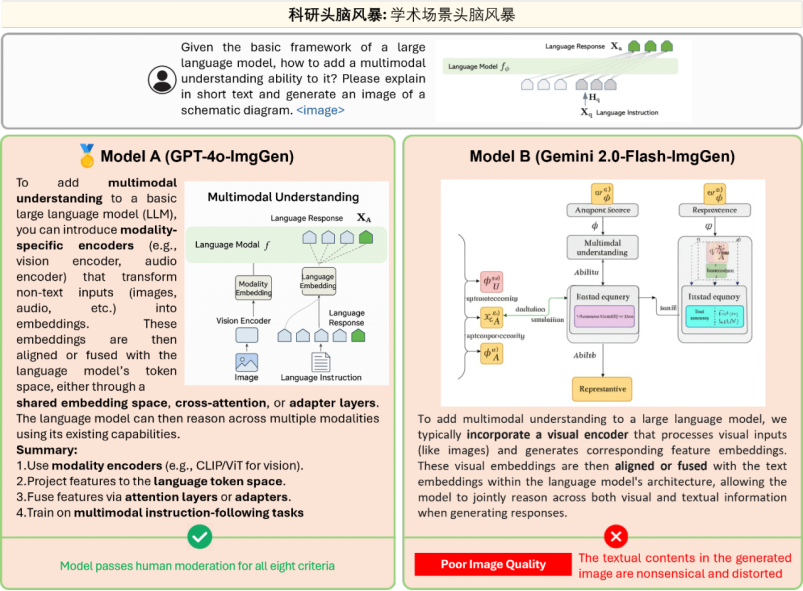
此外,在使用 OpenING 基準對近期發佈的新模型 GPT-4o-ImgGen 和 Gemini 2.0-Flash-ImgGen 和進行評測時,我們驚喜地發現他們在多個任務中展現出了較強的圖文理解能力,以及更為可靠的內容編輯與交錯生成能力。同時,我們也觀察到一些尚待解決的問題,例如 GPT-4o-ImgGen 對 prompt 中命令順序的高度依賴 (如需要指示模型先生成文字再生成圖像)且生圖效率低,而 Gemini 2.0-Flash-ImgGen 無法在圖片中生成高準確度和可識別的文字等。




開放源碼與數據,全社區共建
為了推動圖文交錯生成領域的進一步發展,OpenING 研究團隊已全面開源了完整的基準數據、IntJudge 評測模型及相關代碼。
未來,OpenING 團隊還將繼續擴展數據規模與多樣性,進一步優化評測模型,並推動更接近真實應用場景的研究。團隊鼓勵更多研究者加入,共同推進這一前沿領域的研究。研究團隊相信,OpenING 將持續助力人工智能在真實場景中的落地,讓機器真正具備與人類媲美的圖文交互能力。