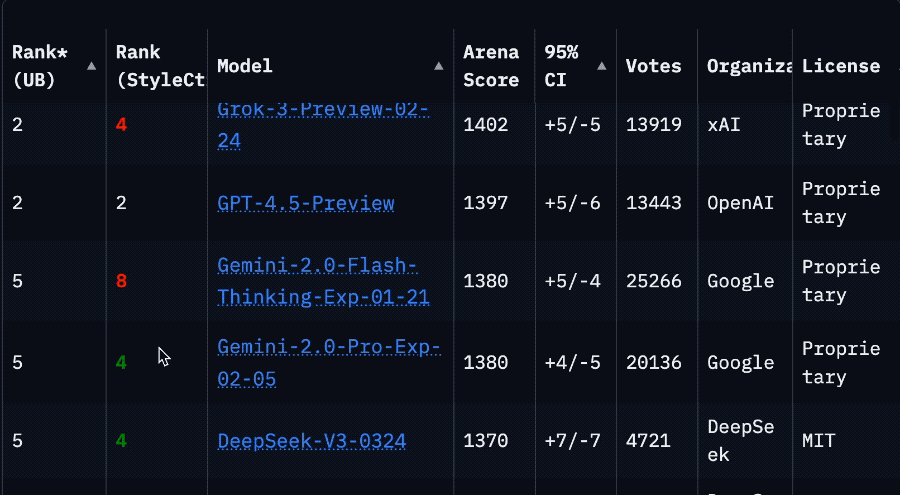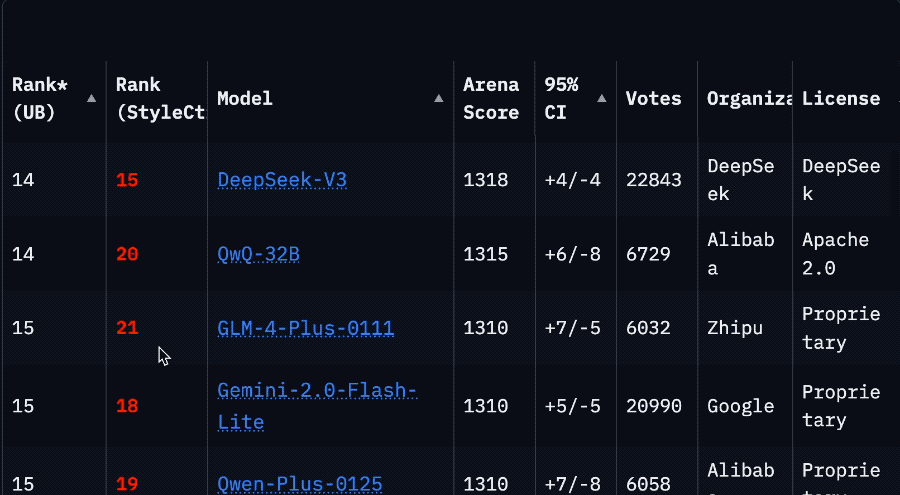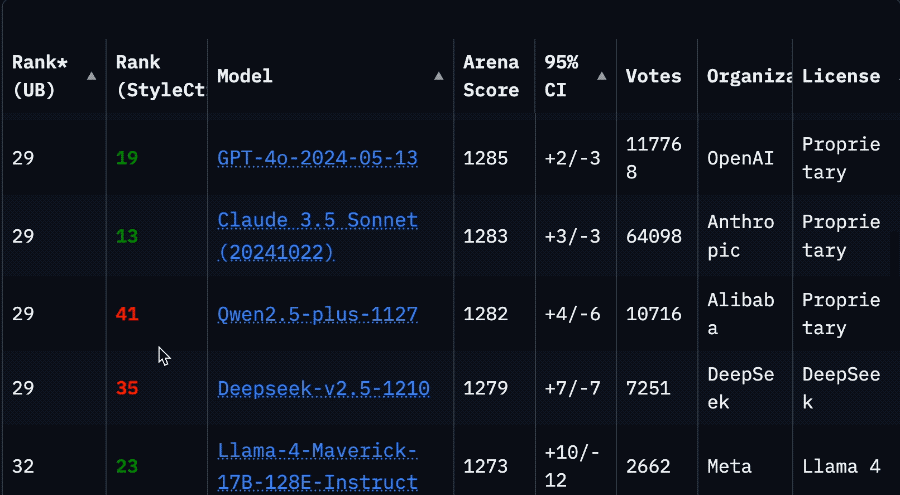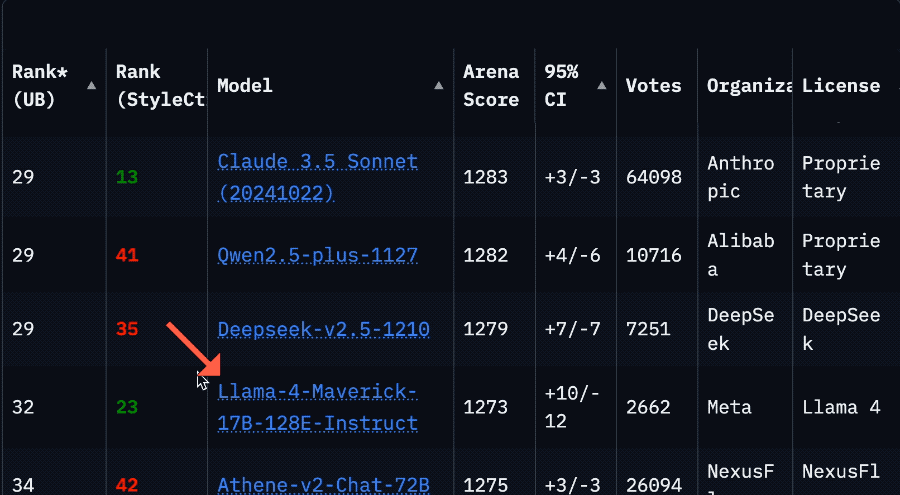
Meta 發佈 Llama 4 系列 AI 模型,引入「混合專家架構」提升效率
IT之家 4 月 6 日消息,Meta 現已發佈旗下最新 Llama 4 系列 AI 模型,包含 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth,Meta 透露相應模型都經過了「大量未標註的文本、圖像和影片數據」的訓練,以使它們具備「廣泛的視覺理解能力」。

目前,Meta 已將系列模型中的 Scout 和 Maverick 上架到 Hugging Face,而 Behemoth 模型則還在訓練中。其中 Scout 可以在單個英偉達 H100 GPU 上運行,而 Maverick 則需要英偉達 H100 DGX AI 平台或「同等性能的設備」。
Meta 表示,Llama 4 系列模型是該公司旗下首批採用混合專家(MoE)架構的模型,這種架構在訓練和回答用戶查詢時的效率更高,所謂「混合專家架構」基本上是將數據處理任務分解為子任務,然後將它們委派給更小的、專門的「專家」模型。
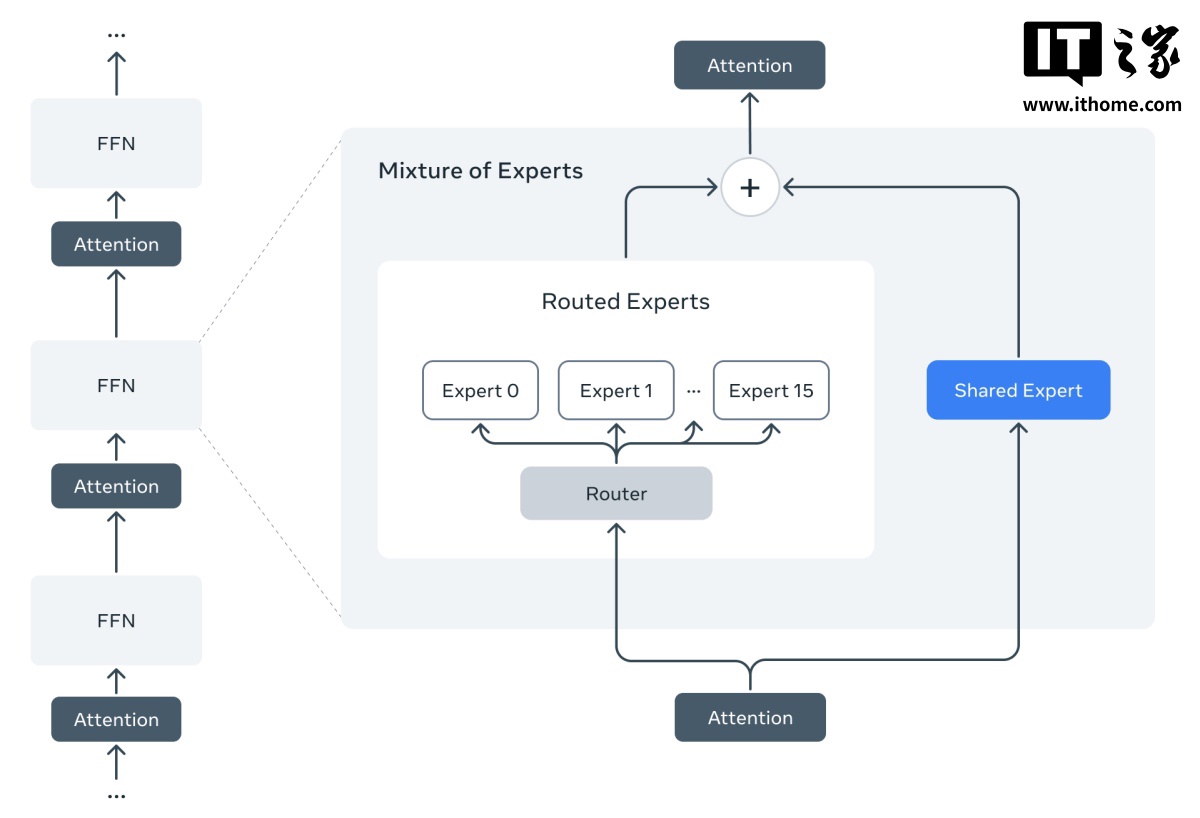
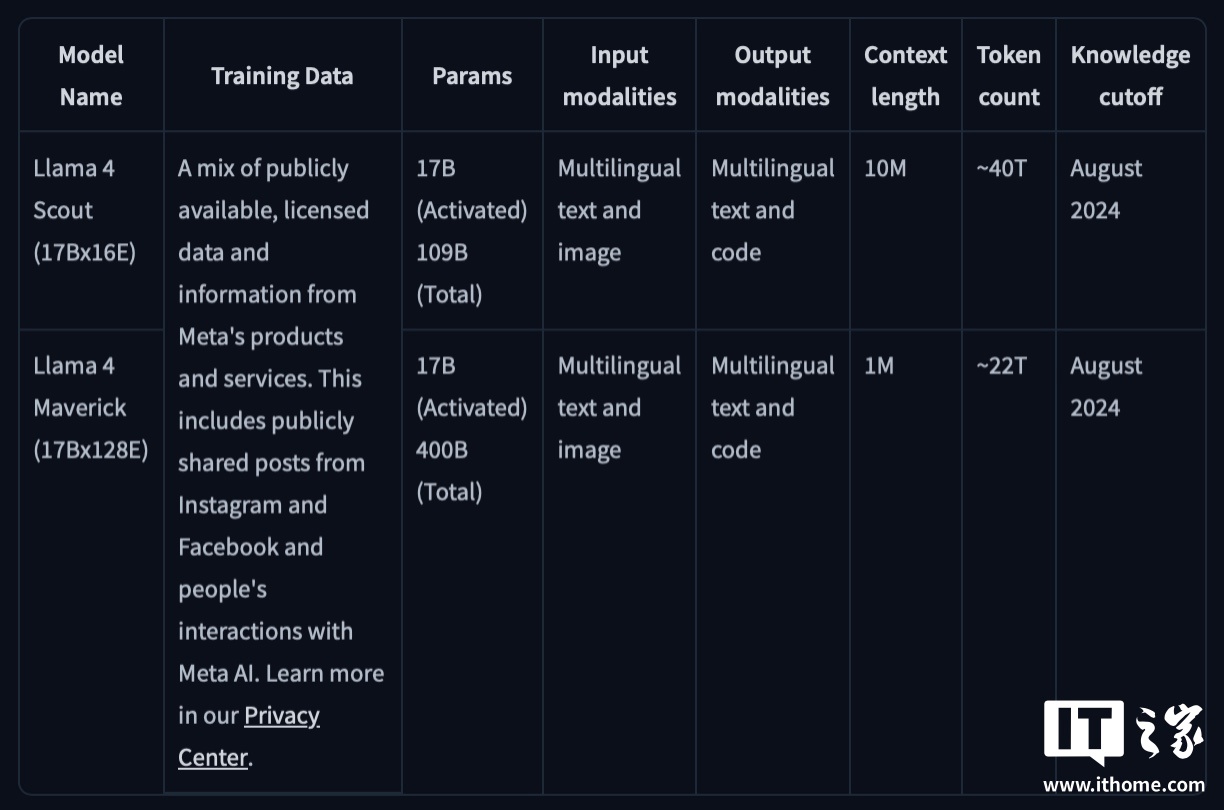
例如,Maverick 總共有 4000 億個參數,但在 128 個「專家」模型中只有 170 億個活躍參數(參數數量大致與模型的問題解決能力相對應)。Scout 有 170 億個活躍參數、16 個「專家」模型以及總計 1090 億個參數。
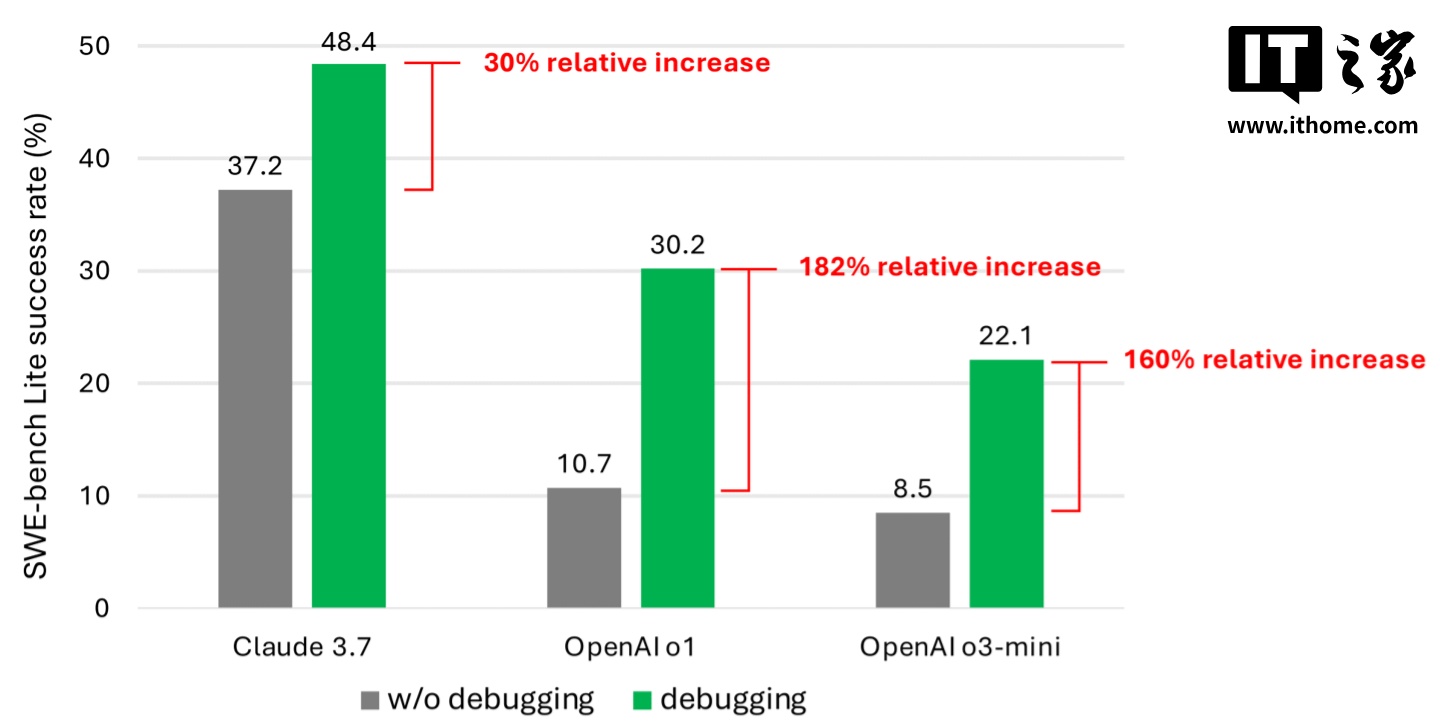
不過值得注意的是,Llama 4 系列中沒有一個模型是像 OpenAI 的 o1 和 o3-mini 那樣真正意義上的「推理模型」。作為比較,「推理模型」會對其答案進行事實核查,並且通常能更可靠地回答問題,但因此也比傳統的「非推理」模型花費更長的時間來給出答案。
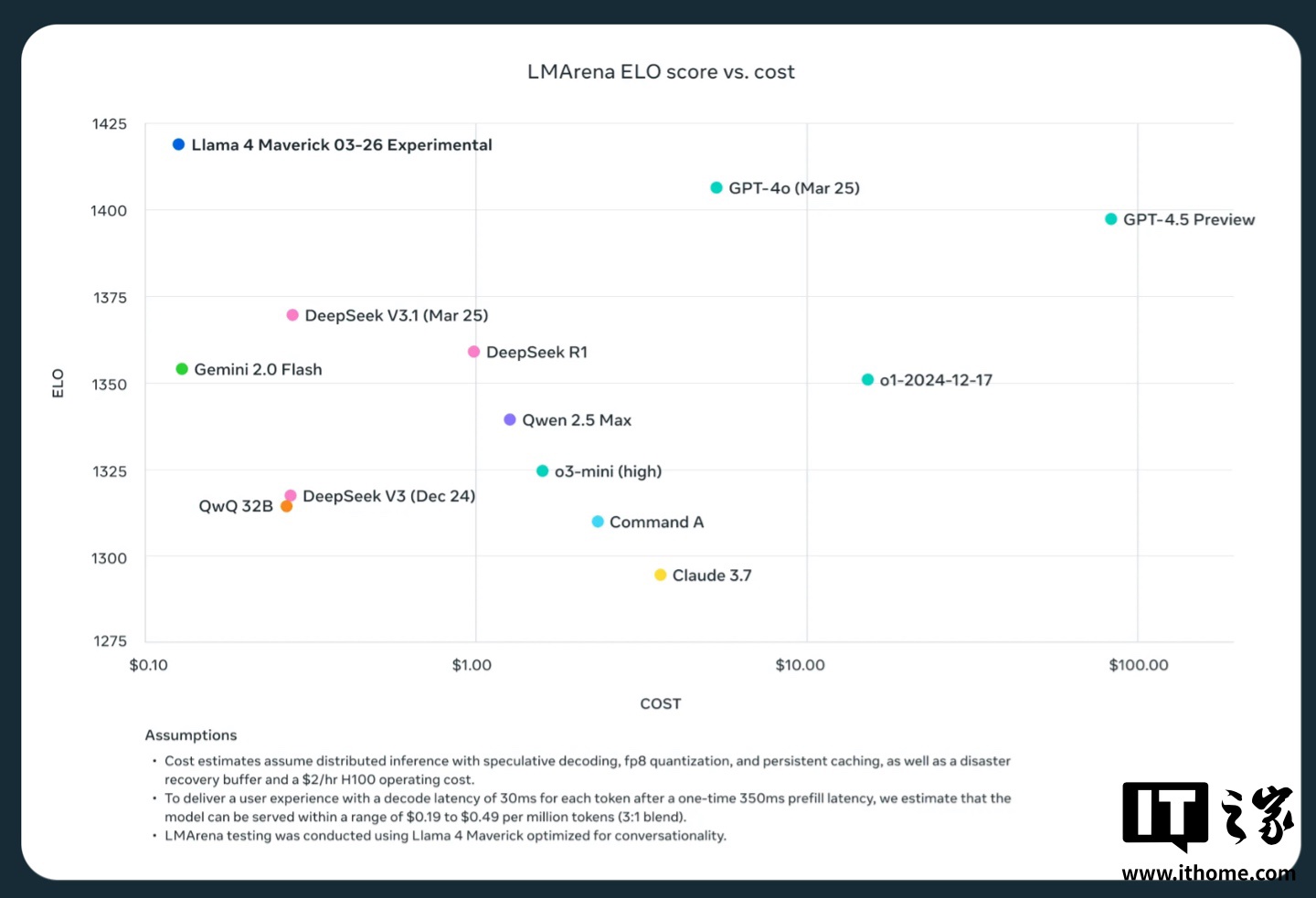
Meta 內部測試顯示,Maverick 模型最適合用於「通用 AI 助手和聊天」等應用場景,該模型在創意寫作、代碼生成、翻譯、推理、長文本上下文總結和圖像基準測試中表現超過了 OpenAI 的 GPT-4o 和Google的 Gemini 2.0 等模型。然而 Maverick 與Google的 Gemini 2.5 Pro、Anthropic 的 Claude 3.7 Sonnet 和 OpenAI 的 GPT-4.5 等功能更強大的最新模型相比仍有一定進步空間。
而 Scout 的優勢則是總結文檔、基於大型代碼庫進行推理。該模型支持 1000 萬個詞元(「詞元」代表原始文本的片段,例如單詞「fantastic」可拆分為「fan」、「tas」和「tic」),因此一次可以處理「多達數百萬字的文本」。
IT之家注意到,Meta 還進一步預告了其 Behemoth 模型,據該公司稱,Behemoth 有 2880 億個活躍參數、16 個「專家」模型,總參數數量接近 2 萬億個。Meta 的內部基準測試顯示,在一些衡量解決數學問題等科學、技術、工程和數學(STEM)技能的評估中,Behemoth 的表現優於 GPT-4.5、Claude 3.7 Sonnet 和 Gemini 2.0 Pro,但不如 Gemini 2.5 Pro。
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。