從0到1玩轉MCP:AI的「萬能插頭」,代碼手把手教你!
選自Towards Data Science
作者:Sandi Besen
機器之心編譯
在人工智能飛速發展的今天,LLM 的能力令人歎為觀止,但其局限性也日益凸顯 —— 它們往往被困於訓練數據的「孤島」,無法直接觸及實時信息或外部工具。
2024 年 11 月,Anthropic 推出了開源協議 MCP(Model Context Protocol,模型上下文協議),旨在為 AI 模型與外部數據源和工具之間的交互提供一個通用、標準化的連接方式。MCP 的開源性質也迅速吸引了開發社區的關注,許多人將其視為 AI 生態系統標準化的重要一步。
MCP 的好處之一是它們能讓 AI 系統更安全。當大家都能用到經過嚴格測試的工具時,公司就不必「重覆造輪子」,這樣既減少了安全隱患,也降低了惡意代碼出現的可能。
隨著 MCP 的逐漸普及,其影響力開始在行業內顯現。2025 年 3 月 27 日,OpenAI 也開始支持 MCP 了。
Google似乎也在考慮是否加入 MCP 大家庭:

仔細看 MCP 的相關資料,會發現明顯存在信息斷層。雖然有很多解釋「它能做什麼」的概述,但當你真想瞭解它是「怎麼運作的」時,資料就變得稀少了 —— 特別是對非專業開發者來說。目前的資料不是過於表面的介紹,就是太過深奧的源代碼。
近日,一篇博客以淺顯易懂的方式講解了 MCP,讓各種背景的讀者都能理解它的概念和功能,讀者還可以跟著代碼進行實踐。

博客鏈接:https://towardsdatascience.com/clear-intro-to-mcp/
讓我們跟隨博客一探究竟(註:本文代碼截圖可能不完整,詳見原文)。
通過類比理解 MCP:餐廳模型
首先,讓我們將 MCP 的概念想像成一家餐廳,其中:
-
主機(Host)=餐廳建築(智能體程序運行的環境)
-
服務器(Server)=廚房(工具發揮作用的地方)
-
客戶端(Client)=服務員(發送工具請求的角色)
-
智能體(Agent)=顧客(決定使用哪種工具的角色)
-
工具(Tools)=食譜(被執行的代碼)
現在,我們來看看這家餐廳的「崗位要求」:
主機(Host)
智能體運行的環境。類比餐廳建築,在 MCP 中,它是智能體或 LLM 實際運行的位置。如果在本地使用 Ollama,用戶即為主機;若使用 Claude 或 GPT,則 Anthropic 或 OpenAI 為主機。
客戶端(Client)
負責從智能體發送工具調用請求的環境。相當於將顧客訂單傳遞至廚房的服務員。實際上是智能體運行的應用程序或接口,客戶端通過 MCP 將工具調用請求傳遞給服務器。
服務器(Server)
類似廚房,存儲各種「食譜」或工具。集中管理工具,使智能體能夠便捷訪問。服務器可以是本地的(用戶啟動)或遠程的(由提供工具的公司託管)。服務器上的工具通常按功能或集成方式分組,例如,所有 Slack 相關工具可集中於「Slack 服務器」,或所有消息工具可集中於「消息服務器」。這種組織方式取決於架構設計和開發者偏好。
智能體(Agent)
系統的「大腦」,由大語言模型驅動,決定調用哪些工具完成任務。當確定需要某工具時,向服務器發起請求。智能體無需原生理解 MCP,因為它通過每個工具關聯的元數據學習使用方法。工具關聯的元數據指導智能體如何調用工具及執行方式。需注意,平台或智能體必須支持 MCP 才能自動處理工具調用,否則開發者需編寫複雜的轉換邏輯,包括從架構解析元數據、以 MCP 格式形成工具調用請求、將請求映射至正確函數、執行代碼,並以符合 MCP 的格式將結果返回給智能體。
工具(Tools)
執行具體工作的函數,如調用 API 或自定義代碼。工具存在於服務器上,可以是:
-
用戶創建並託管在本地服務器的自定義工具
-
他人在遠程服務器上託管的預製工具
-
他人創建但用戶在本地服務器託管的預製代碼
如何協同工作
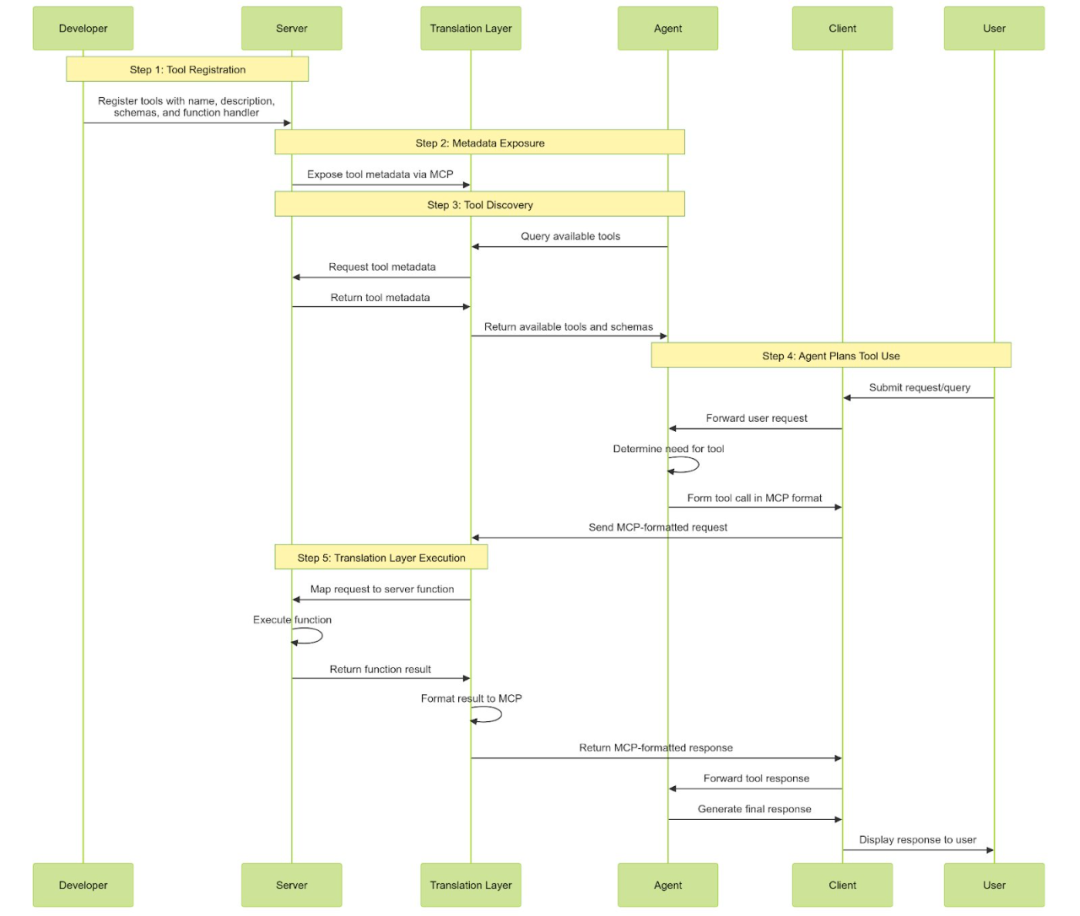
下面詳細介紹 MCP 的具體工作流程:
服務器註冊工具:每個工具都需定義名稱、描述、輸入 / 輸出模式及函數處理程序(執行代碼),並註冊到服務器。這一過程通常通過調用特定方法或 API,向服務器聲明「這是一個新工具及其使用方式」。
服務器暴露元數據:服務器啟動或智能體連接時,通過 MCP 協議暴露工具元數據(包括模式和描述)。
智能體發現工具:智能體通過 MCP 查詢服務器,瞭解可用工具集。智能體從工具元數據中學習如何使用每個工具。這一過程通常在系統啟動時或新工具添延長觸發。
智能體規劃工具使用:當智能體確定需要某個工具(基於用戶輸入或任務上下文)時,會按照標準化的 MCP JSON 格式構建工具調用請求,包含工具名稱、符合工具輸入模式的參數及其他必要元數據。客戶端作為傳輸層,通過 H湯臣P 將 MCP 格式的請求發送至服務器。
翻譯層執行:翻譯層接收智能體的標準化工具調用(通過 MCP),將請求映射到服務器上對應的函數,執行該函數,將結果格式化回 MCP 格式,然後發送回智能體。抽像化 MCP 的框架可以完成所有這些工作,開發者無需編寫翻譯層邏輯(這聽起來是個令人頭疼的事情)。
MCP Brave 搜索服務器的 Re-Act 智能體代碼示例
為了理解 MCP 的實際應用效果,我們可以使用 IBM 的 beeAI 框架,該框架原生支持 MCP 並為我們處理轉換邏輯。如果你計劃運行這段代碼,你需要:
-
複製 beeAI 框架倉庫以獲取此代碼中使用的輔助類: https://github.com/i-am-bee/beeai-framework ;
-
創建一個免費的 Brave 開發者賬戶並獲取 API 密鑰(有免費訂閱可用,需要信用卡);
-
創建一個 OpenAI 開發者賬戶並生成 API 密鑰;
-
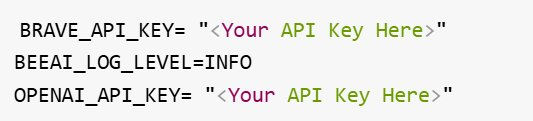
將你的 Brave API 密鑰和 OpenAI 密鑰添加到倉庫 Python 文件夾級別的 .env 文件中;
-
確保你已安裝 npm 並正確設置了路徑。
示例 .env 文件
示例 mcp_agent.ipynb
1. 導入必要的庫

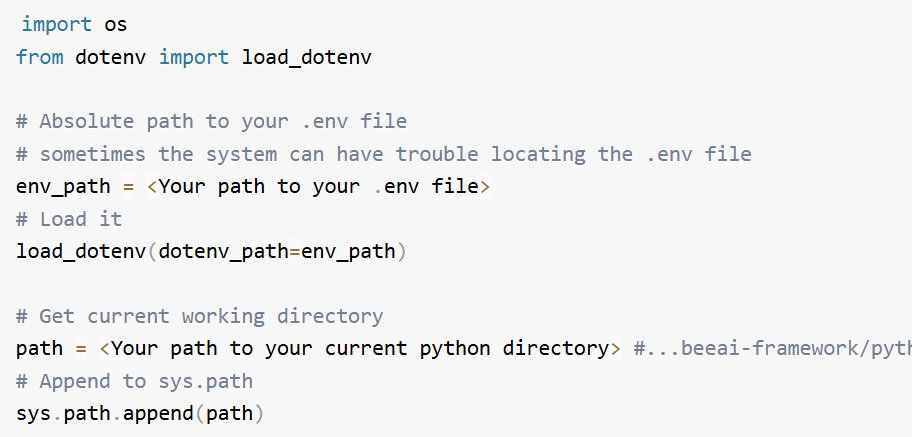
2. 加載環境變量並設置系統路徑(如有需要)
3. 配置日誌記錄器

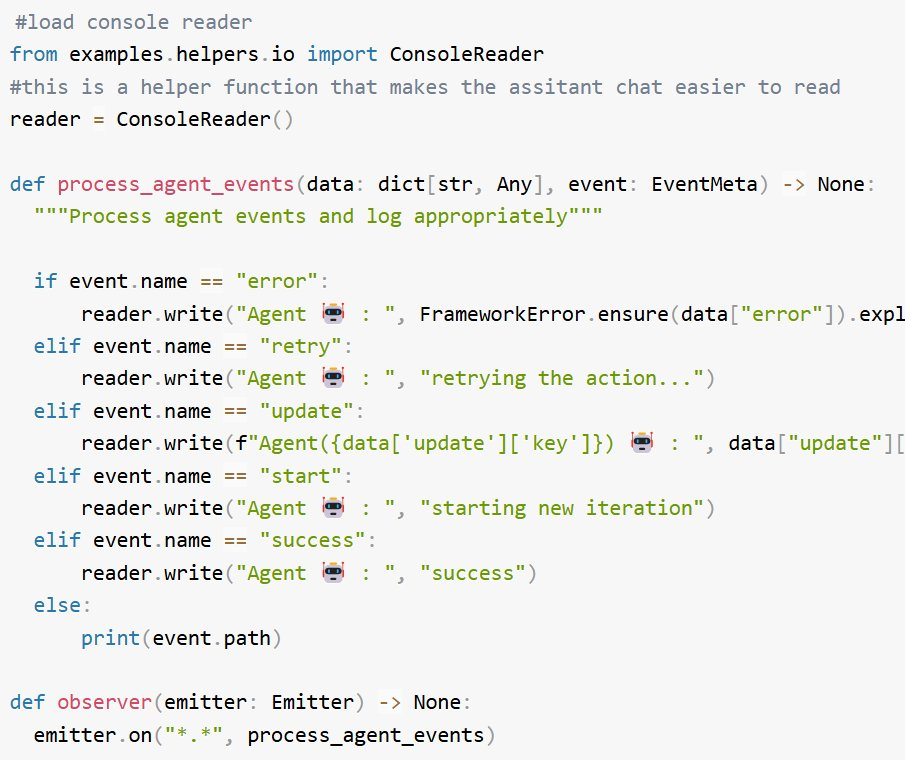
4. 加載輔助函數如 process_agent_events、observer,並創建 ConsoleReader 實例
-
process_agent_events:處理智能體事件並根據事件類型(如錯誤、重試、更新)將消息記錄到控制台。它為每種事件提供有意義的輸出,以幫助跟蹤智能體活動。
-
observer:監聽來自發射器的所有事件,並將它們路由到 process_agent_events 進行處理和顯示。
-
ConsoleReader:管理控制台輸入 / 輸出,允許用戶交互並通過帶有色彩編碼角色的方式顯示格式化消息。
5. 設置 Brave API 密鑰和服務器參數。
Anthropic 有一個 MCP 服務器列表:https://modelcontextprotocol.io/examples

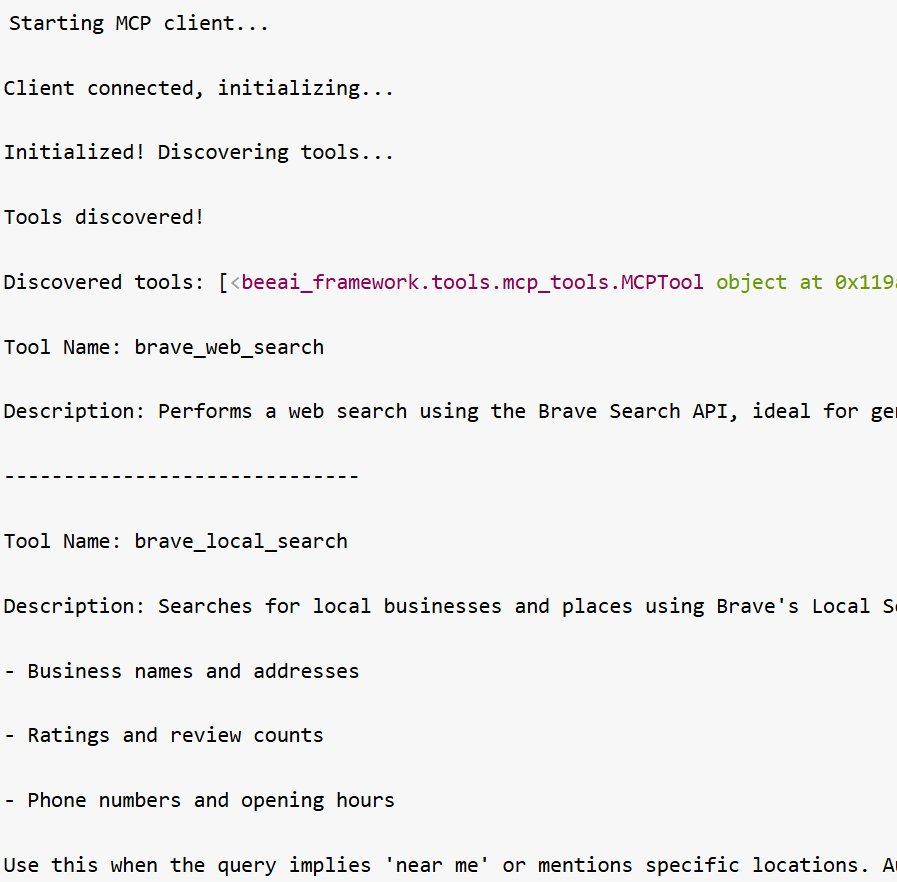
6. 創建一個 Brave 工具,它將啟動與 MCP 服務器的連接,發現工具,並將發現的工具返回給智能體,以便它決定對於給定的任務應該調用哪個工具。
在此情況下,Brave MCP 服務器上可發現 2 個工具:
-
brave_web_search:執行帶分頁和過濾的網頁搜索
-
brave_local_search:搜索本地商家和服務

(可選)檢查與 MCP 服務器的連接,並在將其提供給智能體之前確保它返回所有可用的工具。

輸出
7. 編寫創建智能體的函數
-
分配一個 LLM
-
創建一個 brave_tool () 函數的實例,並將其分配給 tools 變量
-
創建一個 re-act 智能體,並給它分配選擇的 llm、tools、內存(以便它可以進行持續的對話)
-
向 re-act 智能體添加系統提示
注意:您可能會注意到在系統提示詞中添加了一句話:「If you need to use the brave_tool you must use a count of 5.」這是一個臨時解決方案,因為在 Brave 服務器的 index.ts 文件中發現了一個錯誤。用戶將為該倉庫貢獻代碼來修復它。

8. 創建主函數
-
創建智能體
-
與用戶進入對話循環,並使用用戶提示和一些配置設置運行智能體。如果用戶輸入「exit」或「quit」,則結束對話。

輸出:

MCP 憑藉網絡效應、標準化優勢、降低開發成本和行業門檻以及增強互操作性,未來發展潛力巨大。但它也面臨挑戰,包括工具發現依賴服務器、新增故障點、治理需求、安全考慮和延遲問題。
隨著技術的不斷髮展,我們期待 MCP 能夠克服這些挑戰,充分發揮其潛力,為行業帶來更多價值。