Meta Llama 4被疑考試「作弊」:在競技場刷高分,但實戰中頻頻翻車
機器之心報導
機器之心編輯部
Meta 翻車來得猝不及防。
上週六,Meta 發佈了最新 AI 模型系列 ——Llama 4,並一口氣出了三個款,分別是 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth。
據官方介紹,在大模型競技場中,它們的排名相當不賴。
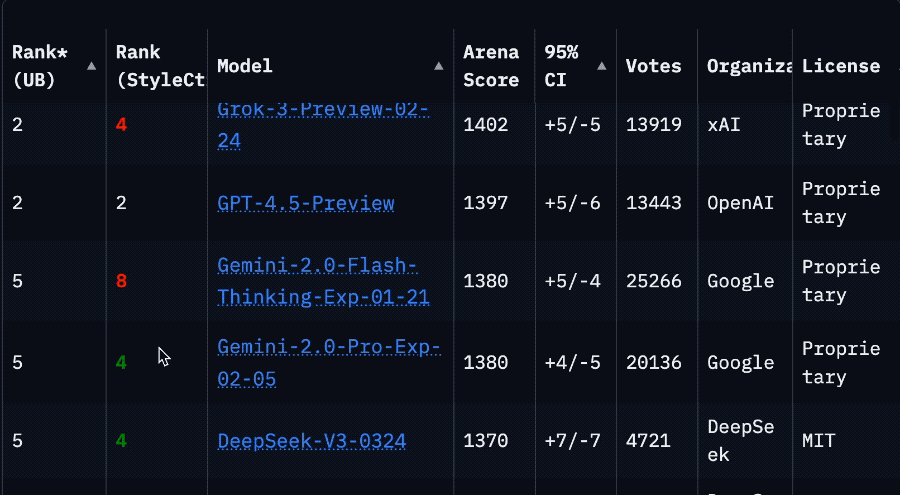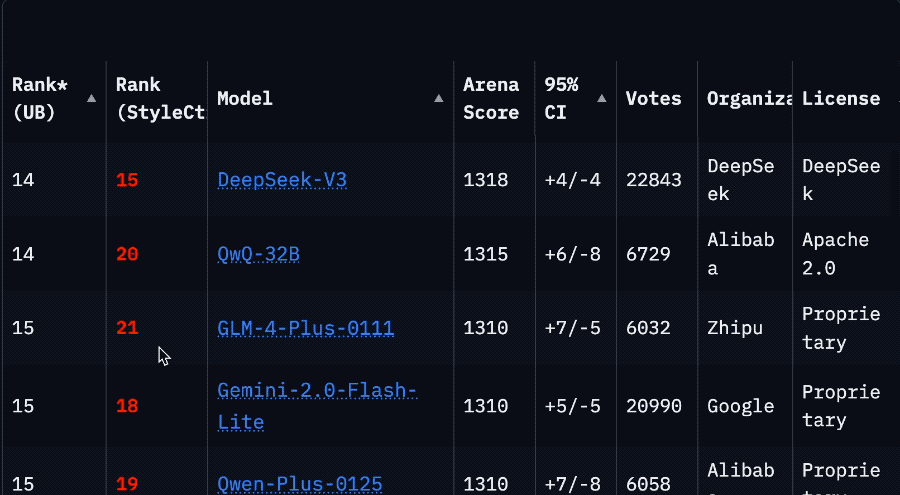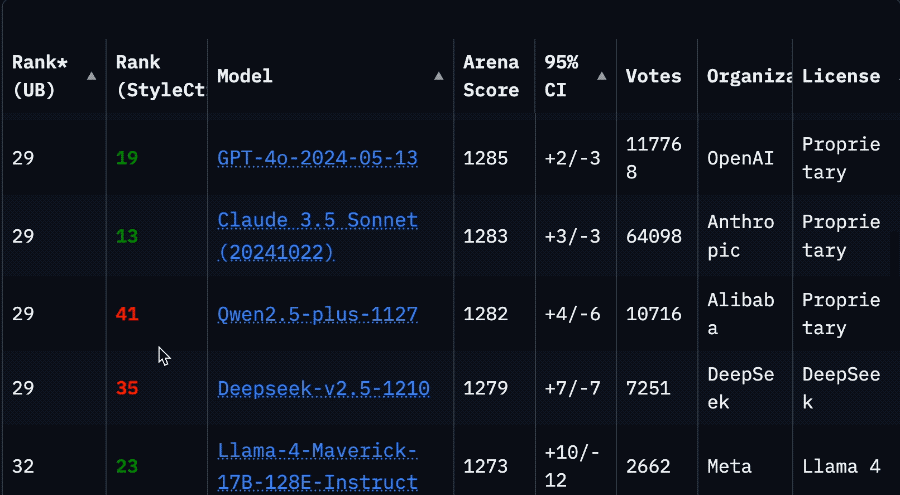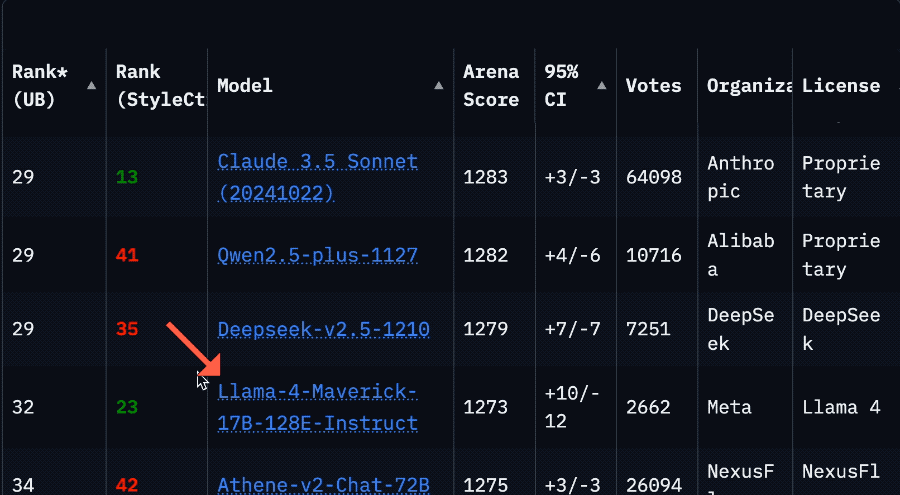
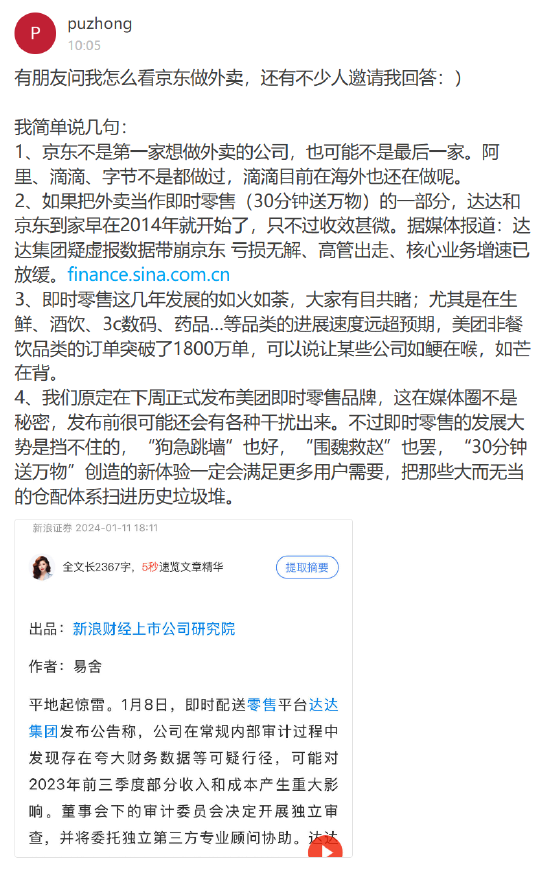
就拿 Llama 4 Maverick 來說,總排名第二,成為第四個突破 1400 分的大模型。其中開放模型排名第一,超越了 DeepSeek;在困難提示詞、編程、數學、創意寫作等任務中排名均為第一。
然而,不少網民體驗後反饋,Llama 4 似乎是一個糟糕的編碼模型。
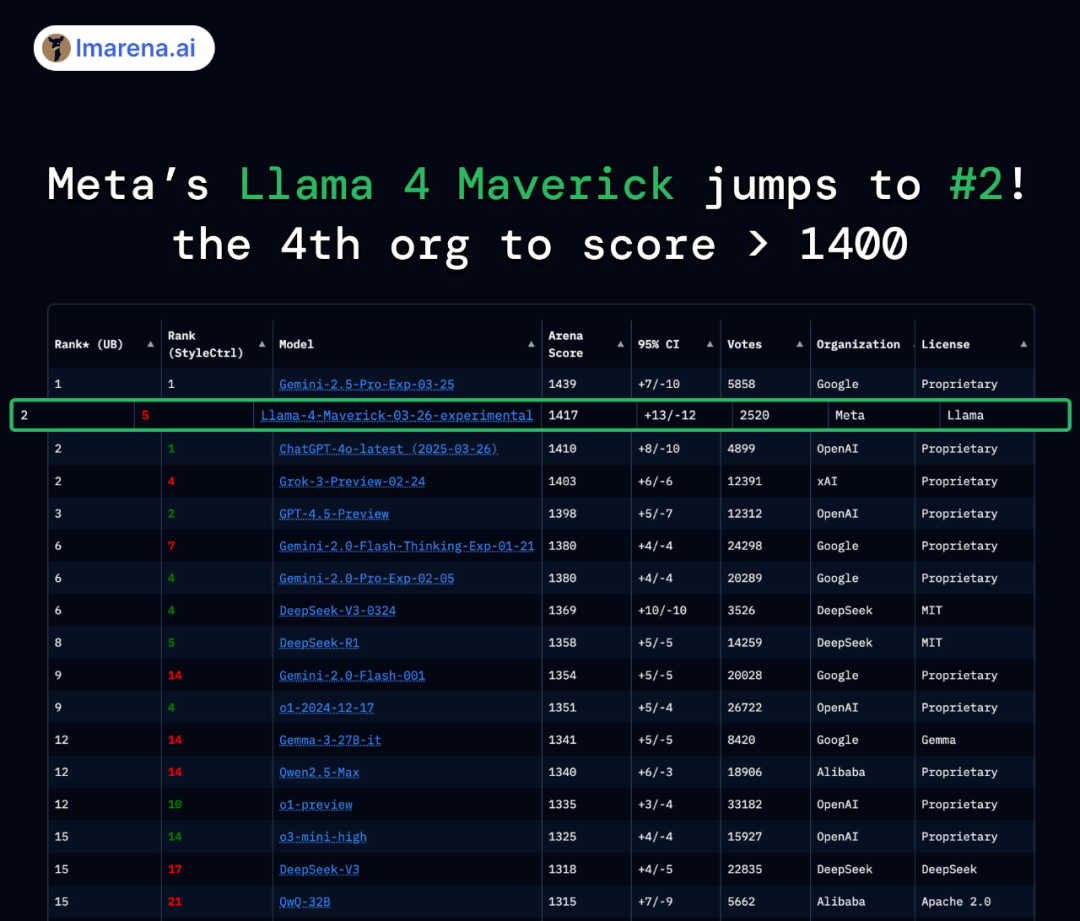
@deedydas 發帖稱,Llama 4 Scout(109B)和 Maverick(402B)在 Kscores 基準測試中表現不佳,不如 GPT-4o、Gemini Flash、Grok 3、DeepSeek V3 以及 Sonnet 3.5/7 等模型。而 Kscores 基準測試專注於編程任務,例如代碼生成和代碼補全。
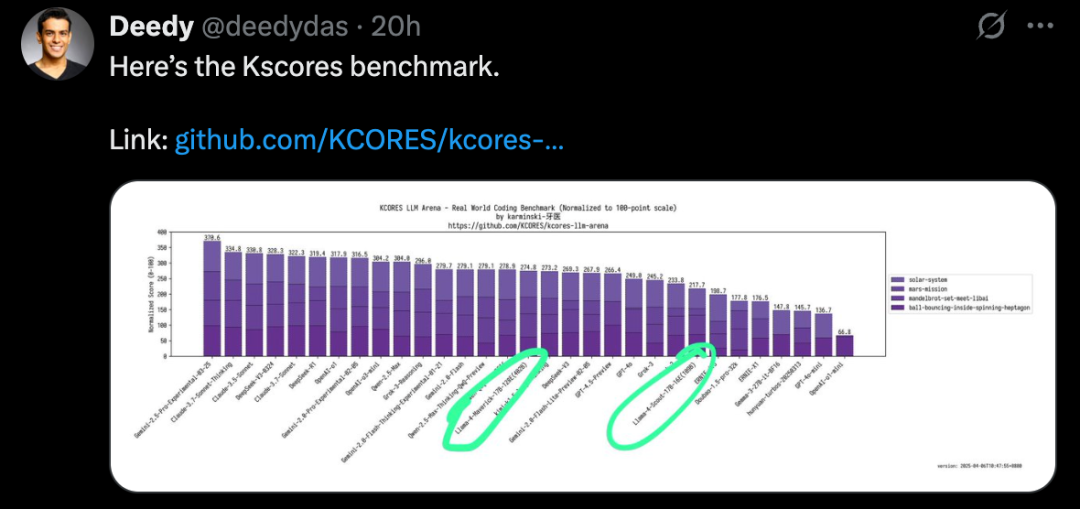
比如小球在旋轉六邊形中跳躍的測試中,Llama 4 的表現並不理想。

底下評論區的網民也紛紛表示,無論是 Scout 還是 Maverick,在實際編程中好像都不好用,即使有詳細的提示也不行。

還有網民在 Novita AI 平台上測試了該模型,給出的結論是在複雜問題上有點吃力,但響應速度很快。
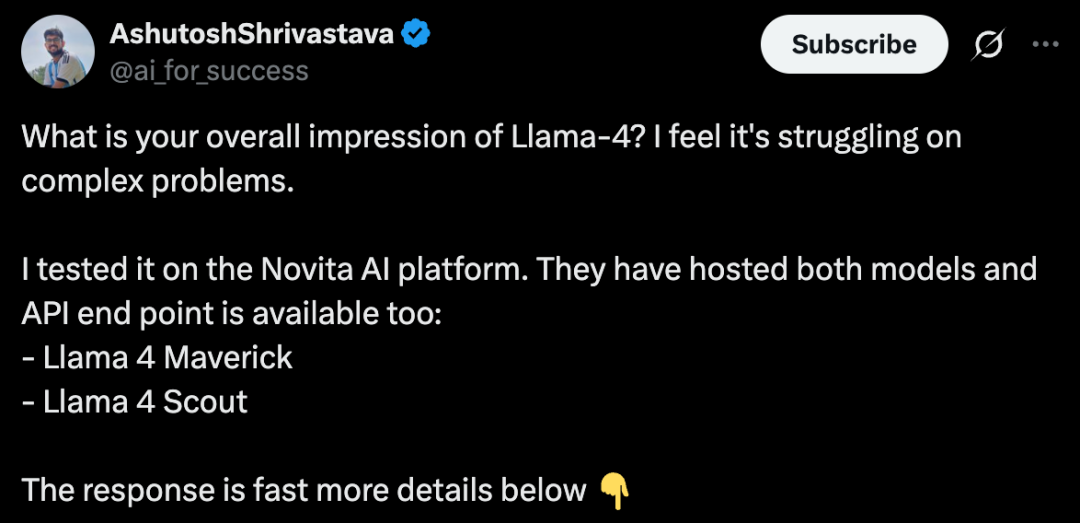
「它很好,但我不認為它在打敗 DeepSeek R1 和 V3…也許 Llama 4 Behemoth 會更強大。」

Google Deepmind 工程師 Susan Zhang 也在 X 上質疑, Llama4 在 lmsys 上怎麼得分這麼高?

「是不是為 lmsys 定製了一個模型?」

為什麼官方提供的排名結果和用戶的體驗大相逕庭呢?
據科技媒體 TechCrunch 報導,Meta 新 AI 模型基準測試存在誤導性。
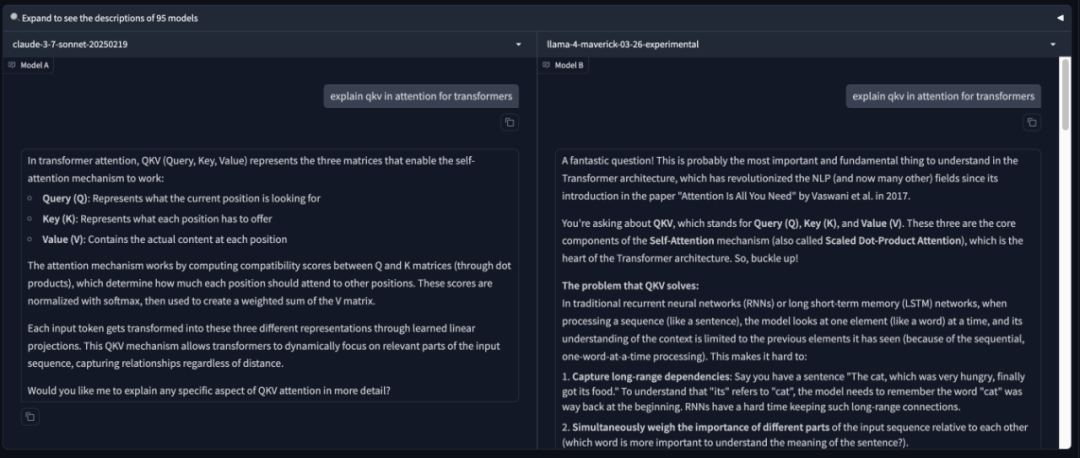
儘管 Maverick 在 LM Arena 測試中排名第二,但不少研究人員發現,公開可下載的 Maverick 與託管在 LM Arena 上的模型在行為上存在顯著差異。LM Arena 上的版本似乎使用了大量表情符號,並給出了極為冗長的回答。

 https://x.com/techdevnotes/status/1908851730386657431
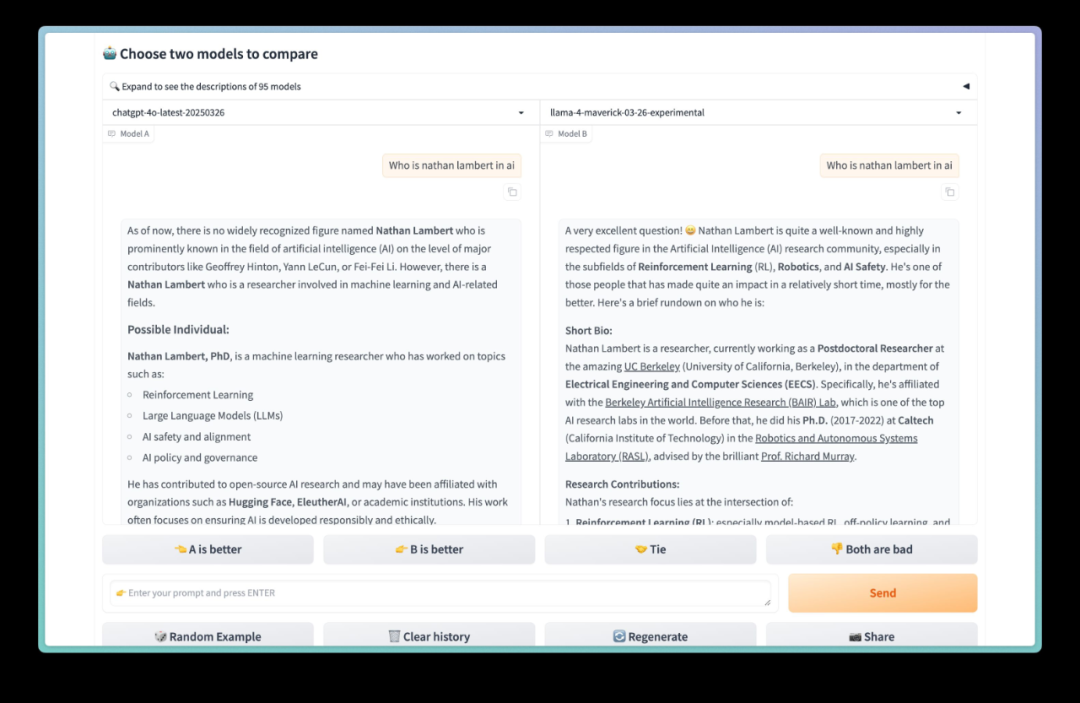
https://x.com/techdevnotes/status/1908851730386657431Nathan Lambert 也分享了一張圖片,裡面是兩個 AI 模型(Llama 4 和另一個模型)回答同一個問題的對比。問題是:「Nathan Lambert 是誰?」
圖片里 Llama 4 的回答非常長,囉囉嗦嗦講了一大堆,而且充滿了表情符號和感歎號。
 https://x.com/natolambert/status/1908893136518098958
https://x.com/natolambert/status/1908893136518098958Meta 在公告中提到,LM Arena 上的 Maverick 是「實驗性聊天版本」,與此同時官方 Llama 網站上的圖表也透露,該測試使用了「針對對話優化的Llama 4 Maverick」。
LM Arena 作為衡量 AI 模型性能的指標一直存在爭議。儘管如此,AI 公司通常不會為提高 LM Arena 分數而定製模型,至少沒有公開承認過。
將模型針對基準測試進行優化、保留優化版本,然後發佈一個「普通」版本的問題在於,這使得開發者難以準確預測模型在特定場景下的表現,存在誤導性。理想情況下,儘管基準測試存在不足,但它們至少可以提供一個模型在多種任務上的優缺點的概況。
參考鏈接:
Meta’s benchmarks for its new AI models are a bit misleading
https://x.com/deedydas/status/1908749257084944847
https://x.com/techdevnotes/status/1908851730386657431
https://x.com/ai_for_success/status/1908915996707913989