鉸鏈物體的通用世界模型,超越擴散方法,入選CVPR 2025

基於當前觀察,預測鉸鏈物體的的運動,尤其是 part-level 級別的運動,是實現世界模型的關鍵一步。儘管現在基於 diffusion 的方法取得了很多進展,但是這些方法存在處理效率低,同時缺乏三維感知等問題,難以投入真實環境中使用。
清華大學聯合北京大學提出了第一個基於重建模型的 part-level 運動的建模——PartRM。用戶給定單張輸入圖像和對應的 drag ,PartRM 能生成觀測物體未來狀態的三維表徵 ,使得生成數據能夠真正服務於機器人操縱等任務。實驗證明 PartRM 在生成結果上都取得了顯著的提升。該研究已入選CVPR 2025。

-
論文題目:PartRM: Modeling Part-Level Dynamics with Large Cross-State Reconstruction Model
-
論文主頁:https://partrm.c7w.tech/
-
論文鏈接:https://arxiv.org/abs/2503.19913
-
代碼鏈接:https://github.com/GasaiYU/PartRM
研究動機
世界模型是一種基於當前觀察和動作來預測未來狀態的函數。該模型的研發使得計算機能夠理解物理世界中的複雜規律,在機器人等領域得到了廣泛應用。近期,對 part-level 的動態建模的興趣日益增長,給定當前時刻的觀察並給與用戶給定的拖拽,預測下一時刻的鉸鏈物體各個部件的運動受到越來越多的關注,這種類型的世界模型對於需要高精度的任務,例如機器人的操縱任務等,具有重要的意義。
然而,我們對這個充滿前景的領域的調研表明,目前的前沿研究(如 Puppet-Master)通過對預訓練的 大規模影片擴散模型進行微調,以實現增加拖拽控制的功能。儘管這種方法有效地利用了預訓練過程中 學習到的豐富運動模式,但在實際應用中仍顯不足。其中一個主要局限是它僅輸出單視角影片作為表示,而模擬器需要三維表示來從多個視角渲染場景。此外,擴散去噪過程可能需要幾分鐘來模擬單個拖 拽交互,這與為操作策略(Manipulation Policies)提供快速試錯反饋的目標相悖。
因此,我們需要採用三維表徵,為了實現從輸入單視角圖像的快速三維重建,我們利用基於三維高斯潑濺(3DGS)的大規模重建模型,這些模型能以前饋方式從輸入圖像預測三維高斯潑濺,使重建時間從傳 統優化方法所需的幾分鐘減少到僅需幾秒鍾。同時,通過將用戶指定的拖拽信息加入到大規模三維重建 網絡中,我們實現了部件級別的動態建模。在這個問題中,我們認為聯合建模運動和幾何是至關重要的,因為部件級運動本質上與每個部件的幾何特性相關聯(例如,抽屜在打開時通常沿其法線方向滑動)。這種集成使我們能夠實現更真實和可解釋的部件級動態表示。
同時,由於我們是第一個做這個任務的,在這個任務上缺少相關的數據集,因此我們基於 PartNet- Mobility 構建了 PartDrag-4D 數據集,並在這個數據集上建立了衡量對部件級別動態建模的基準(Benchmark),實驗結果表明,我們的方法在定量和定性上都取得了最好的效果。
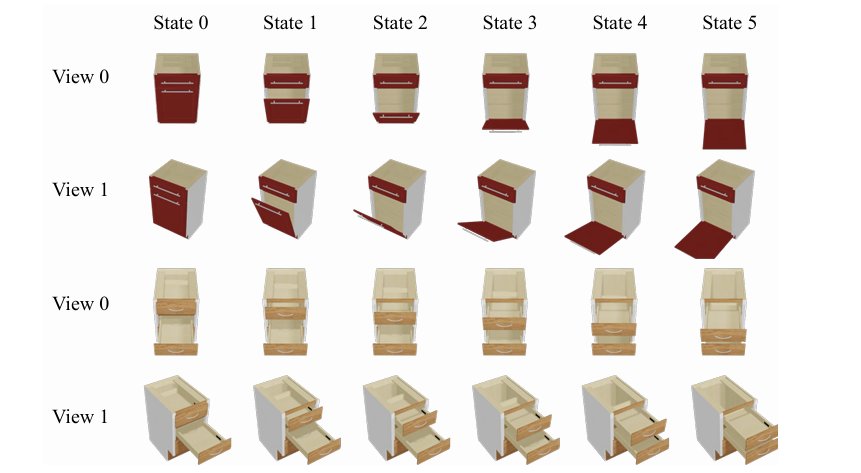
PartDrag-4D 數據集的構建
我們首先定義 PartRM 需要完成的任務,給定單張鉸鏈物體的圖像 ot 和用戶指定的拖拽 at ,我們需要設計 一個模型,完成
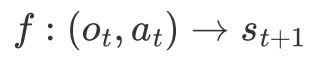
其中
是 Ot 在 at 作用下的三維表徵。
現有的數據集分為兩種, 一種是只含有
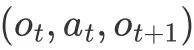
數據對,但是缺乏對應的三維表徵(比如 DragAPart 中提出的 Drag-a-Move 數據集)。還有一種是通用數據集,比如 Objaverse 中的動態數據,這種數據不止還有部件級別的運動,還會含有物體整體的變形等運動,不適合我們訓練。
因此,我們基於提供鉸鏈物體部件級別標註的 PartNet-Mobility 數據集構建了 PartDrag-4D 數據集。我們選取了 8 種鉸鏈物體(其中 7 種用於訓練, 1 種用於測試),共 738 個 mesh。對於每個 mesh,如圖所示,我們使其中某個部件在兩種極限狀態(如完全閉合到完全開啟)間運動至 6 個狀態,同時將其他部分狀態 設置為隨機,從而產生共 20548 個狀態,其中 20057 個用於訓練,491 個用於測試。為渲染多視角圖像,我們利用 Blender 為每個 mesh 渲染了 12 個視角的圖像。對於兩個狀態之間拖拽數據的采樣,我們在鉸鏈物體運動部件的 Mesh 表面選取采樣點,並將兩個狀態中對應的采樣點投影至 2D 圖像空間,即可獲得對應的拖拽數據。
PartRM 方法
方法概覽
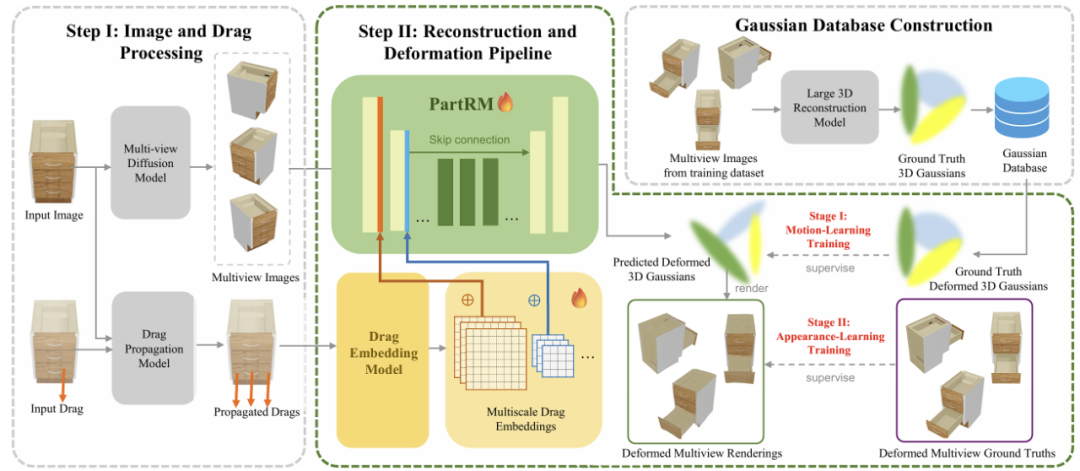
上圖提供了 PartRM 方法的概述,給定一個單視角的鉸鏈物體的圖像 ot 和對應的拖拽 at,我們的目標是生 成對應的 3D 高斯潑濺
。我們首先會利用多視角生成模型 Zero123++ 生成輸入的多視角圖像,然後對輸入的拖拽在用戶希望移動的 Part 上進行傳播。這些多視角的圖像和傳播後的拖拽會輸入進我們設計的網絡中,這個網絡會對輸入的拖拽進行多尺度的嵌入,然後將得到的嵌入拚接到重建網絡的下采樣層中。在訓練過程中,我們採用兩階段訓練方法,第一階段學習 Part 的運動,利用高斯居里的 3D 高斯進行 監督,第二階段學習外觀,利用數據集里的多視角圖像進行監督。
圖像和拖拽的預處理
圖像預處理:由於我們的主網絡是基於 LGM 設計的, LGM 需要多視角的圖像作為輸入,所以我們需要將 輸入的單視角圖像變成多視角,我們利用多視角圖像生成網絡 Zero123++,為了使得 Zero123++ 生成的 圖像質量更高,我們會在訓練集上對其進行微調。
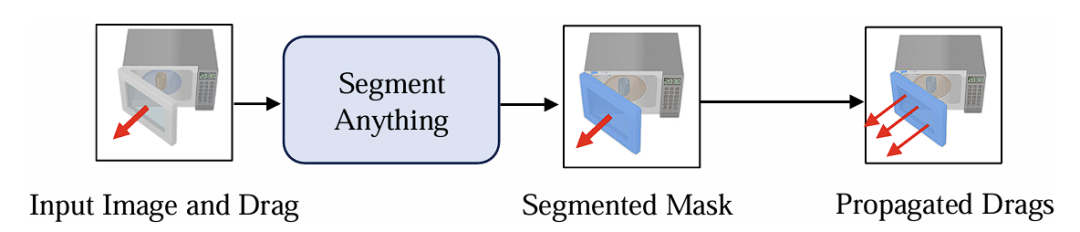
拖拽傳播:如果用戶只輸入一個拖拽,後續網絡可能會對拖拽的區域產生幻覺從而出錯,因此我們需要 對拖拽進行傳播到需要被拖拽部分的各個區域,使得後續網絡感知到需要被拖拽的區域,為此我們設計了一個拖拽傳播策略。如圖所示,我們首先拿用戶給定的拖拽的起始點輸入進 Segment Anything 模型中得到對應的被拖拽區域的掩碼,然後在這個掩碼區域內采樣一些點作為被傳播拖拽的起始點,這些被傳播的拖拽的強度和用戶給定的拖拽的強度一樣。儘管在拖動強度大小的估計上可能存在不準確性,我們後續的模型仍然足夠穩健,能夠以數據驅動的方式學習生成預期的輸出。
拖拽嵌入
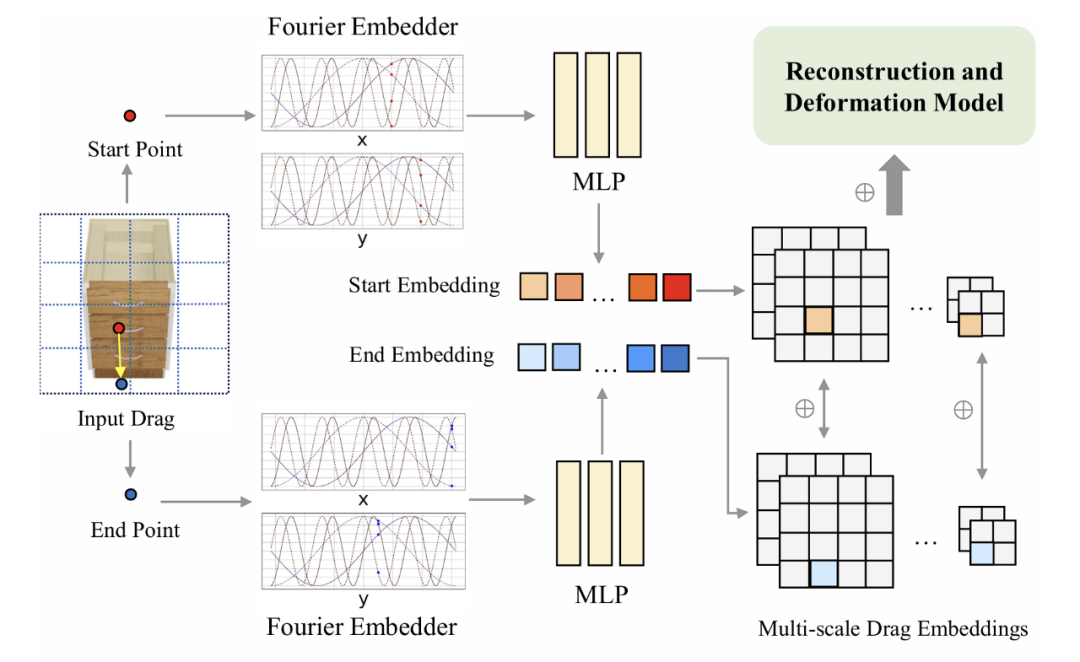
PartRM 重建網絡的 UNet 部分沿用了 LGM 的網絡架構,為了將上一步處理好的拖拽注入到重建網絡中, 我們設計了一個多尺度的拖拽嵌入。具體地,對於每一個拖拽,我們會將它的起始點和終止點先過一個 Fourier 嵌入,然後過一個三層的 MLP:
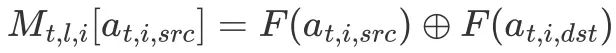
其中代表在 channel 維度上連接。得到第 l 層的嵌入後,我們將
和網絡第 l 層的輸出 Ol 在 channel 維度上連接,並過一個卷積層,作為 Ol 的殘差加到 Ol 上作為下一層的輸入,具體地:
代表第 i 個拖拽在第 l 層的嵌入,其餘部分設為 0。F 代表 Fourier 嵌入和 MLP ,
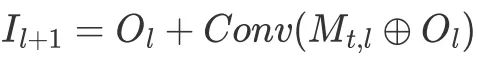
其中卷積層的參數全零初始化,
為第 l + 1 層的輸入。
兩階段訓練流程
為了保證對靜態 3D 物體外觀和幾何的建模能力,我們在預訓練的 LGM 基礎上構建了 PartRM。但直接在新數據集上微調會導致已有知識災難性遺忘,從而降低對真實場景數據的泛化能力。為此,我們提出了 兩階段學習方法:先專注於學習之前未涉及的運動信息,再訓練外觀、幾何和運動信息,以確保更好的性能。
運動學習階段:在運動學習階段,我們期望模型能夠學到由輸入的拖拽引起的運動。我們首先利用在我 們的數據集上微調好的 LGM 去推理每個狀態 Mesh 對應的 3D 高斯潑濺表徵,拿這些作為監督數據我們第 一階段的訓練。對於兩個 3D 高斯之間的對應,我們利用 LGM 輸出的是一個 splatter image 這一優勢,即 LGM 會對 2D 圖像的每一個像素點學一個高斯潑濺,我們可以直接對監督數據和 PartRM 網絡預測的輸出 做像素級別的 L2 損失,即:
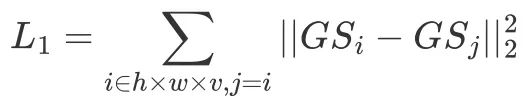
其中 i 代表在 splatter image 里的坐標, GSi 和 GSj 均為每個像素點對應的 14 維高斯球參數。
外觀學習階段: 在運動學習階段之後,我們引入了一個額外的階段來聯合優化輸出的外觀,幾何以及部 件級別的運動。這個階段我們會渲染我們輸出的 3D 高斯,利用數據集中提供的多視角圖像計算一個損失,具體地:
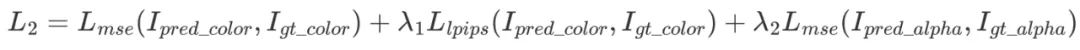
實驗結果
實驗設置
我們在兩個數據集上來衡量我們提出的 PartRM 方法,這兩個數據集包括我們提出的 PartDrag-4D 數據集 以及通用數據集 Objaverse-Animation-HQ。因為 Objaverse-Animation-HQ 數據量比較大,我們只從其中采樣 15000 條數據,然後手動拆分訓練集和測試集。驗證時,我們對輸出的 3D 高斯渲染 8 個不同的視角,在這 8 個視角上算 PSNR ,SSIM 和 LPIPS 指標。
我們選用 DragAPart , DiffEditor 和 Puppet-Master 作為我們的 baseline。對於不需要訓練的 DiffEditor 方法,我們直接拿它官方的訓練權重進行推理。對於需要訓練的 DragAPart 和 Puppet-Master,我們在訓練 集上對他們進行微調。
由於現有的方法只能輸出 2D 圖像,不能輸出 3D 表徵,為了和我們的任務對齊,我們設計了兩種方法。第一種稱為 NVS-First,即我們首先對輸入的單視角圖像利用 Zero123++ 生成多視角圖像,再分別對每個視角結合每個視角對應的拖拽進行推理,生成對應的圖像後再進行 3D 高斯重建;第二種稱為 Drag-First,
即我們首先先對輸入視角進行拖拽,然後對生成的結果利用 Zero123++ 進行多視角生成,最後進行 3D 高斯重建。我們採用了兩種 3D 高斯重建方法,第一種為直接用 LGM (下圖中兩個時間的第一個)進行重建,第二種利用基於優化的 3D 高斯潑濺進行重建(下圖中兩個時間的第二個)。
定性比較
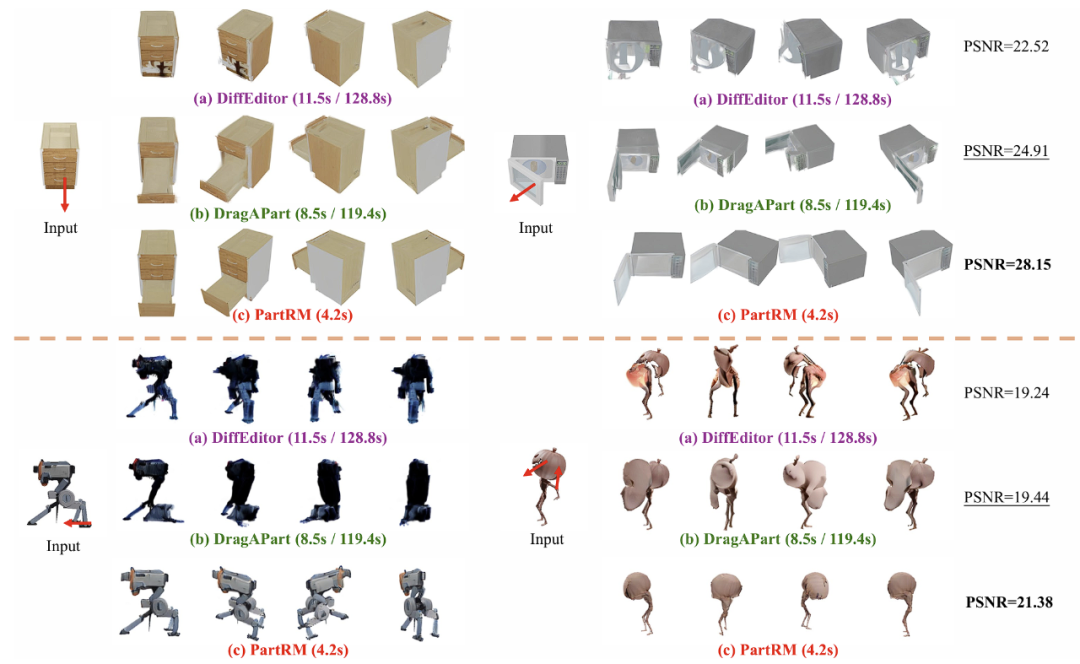
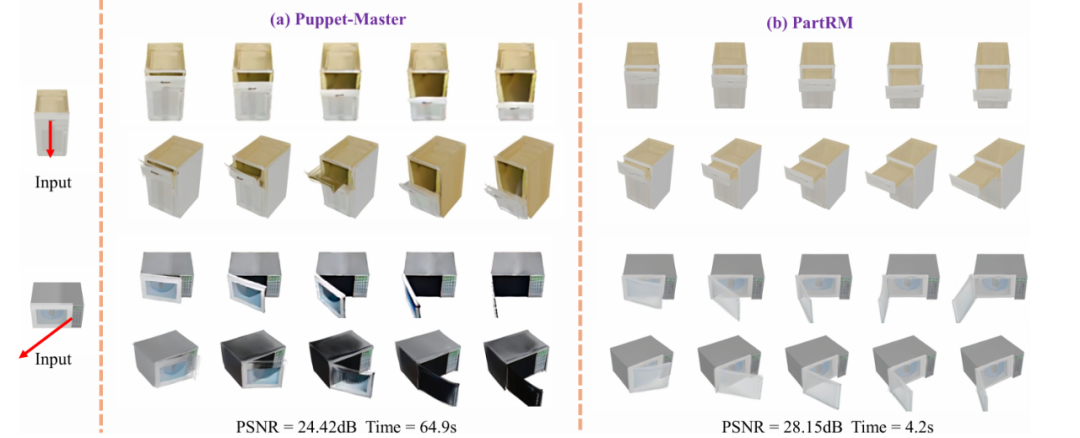
在視覺效果方面, PartRM 通過對外觀,幾何和運動的聯合建模,能夠在抽屜開合等場景中生成物理合理的三維表徵。相比之下, DiffEditor 由於缺乏三維感知,導致部件形變錯位; DragAPart 雖然能夠處理簡 單的關節運動,但在生成微波門板時出現了明顯的偽影等問題,同時在通用數據集上表現不佳;Puppet- Master 在外觀的時間連續性和運動部分的建模方面表現不佳。

在 in the wild 質量方面,我們從互聯網上采了一些數據,手動設置拖拽,利用我們在 PartDrag-4D 上訓練 好的 PartRM 進行推理。圖中可以看到,我們的方法在一些和訓練數據分佈差別不大的數據上可以取得較 好的效果;但是在一些分佈差別較大的數據上效果欠佳。
定量比較
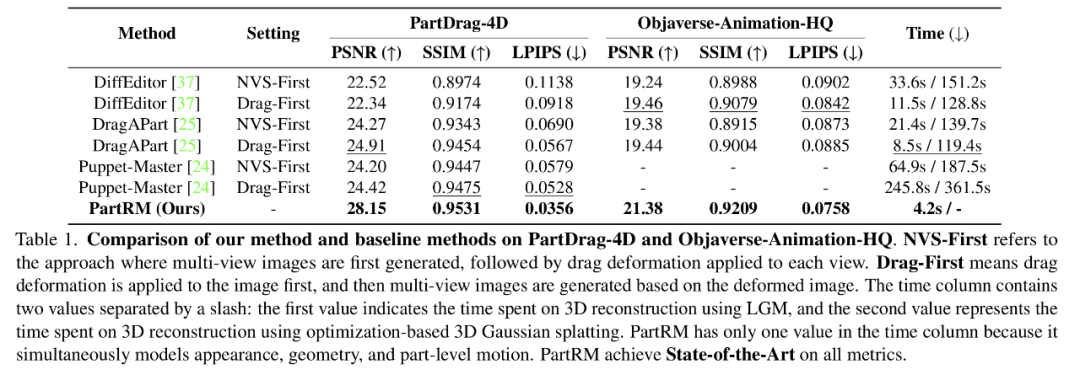
定量評估中, PartRM 在 PSNR、SSIM、 LPIPS 指標上較基線模型均有提升;同時大幅提升了生成效率, PartRM 僅需 4 秒即可完成單次生成,而傳統方案需分步執行 2D 形變與三維重建。
總結
本文介紹了 PartRM ,一種同時建模外觀、幾何和部件級運動的新方法。為瞭解決 4D 部件級運動學習中的數據稀缺問題,我們提出了 PartDrag-4D 數據集,提供了部件級動態的多視角圖像。實驗結果表明,我們的方法在部件運動學習上優於以往的方法,並且可應用於具身 AI 任務。然而,對於與訓練分佈差異較大的關節數據,可能會遇到挑戰。