Meta Llama 4 發佈 36 小時「差評如潮」,匿名員工爆料拒絕署名技術報告
Meta 最新基礎模型 Llama 4 發佈 36 小時後,評論區居然是這個畫風:
失望,非常失望
不知道他們後訓練怎麼搞的,總之不太行
在 [各種測試] 中失敗
……

還被做成表情包調侃,總結起來就是一個「差評如潮」。

具體來看,大家的抱怨主要集中在代碼能力。
最直觀的要數經典「氛圍編程」小球反彈測試,小球直接穿過牆壁掉下去了。
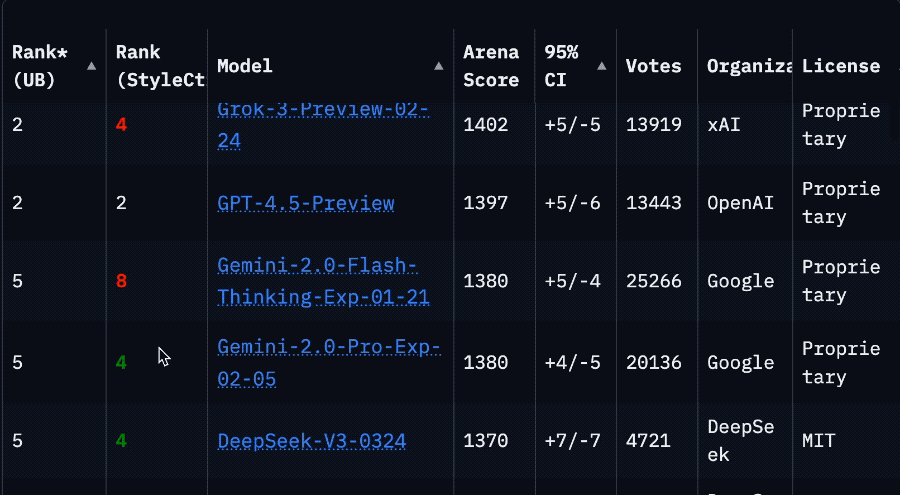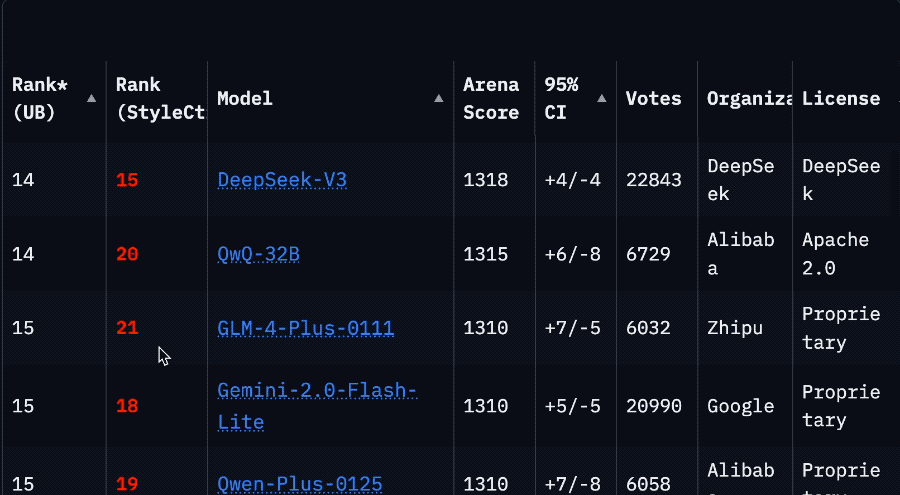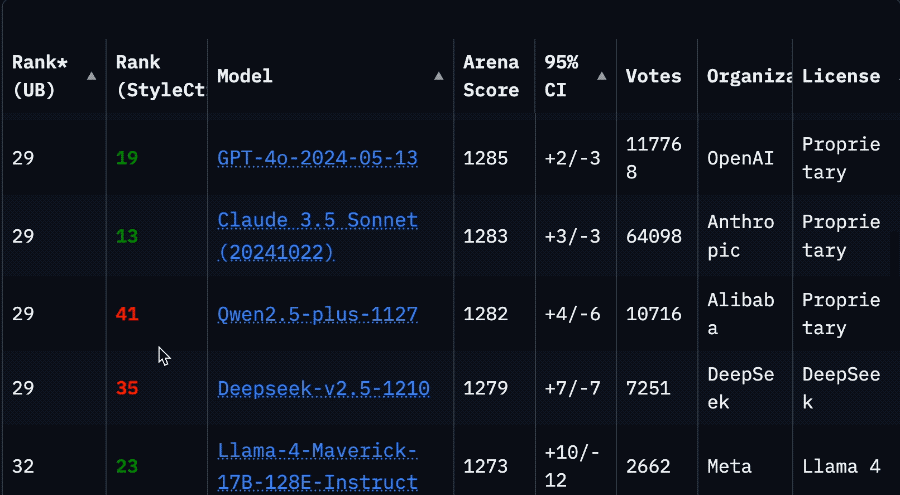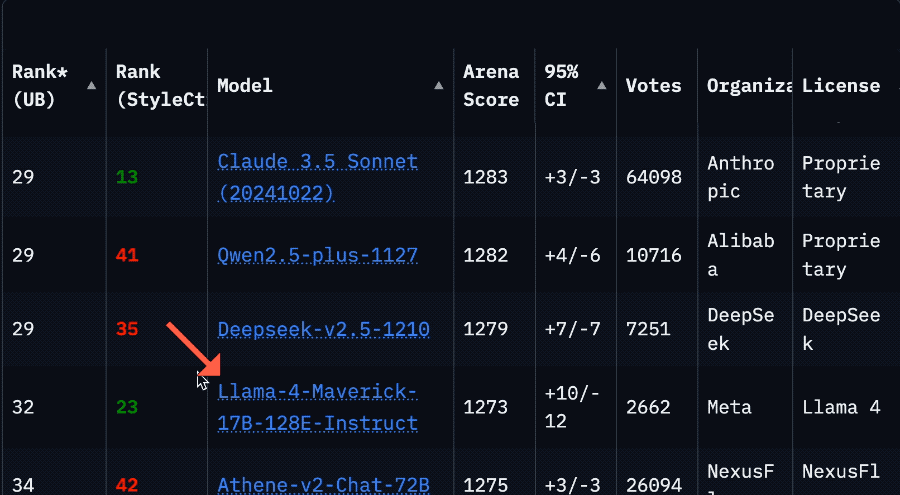
反映在榜單上,成績也相當割裂。
發佈時的官方測評(LiveCodeBench)分數和在大模型競技場表現明明都很不錯。
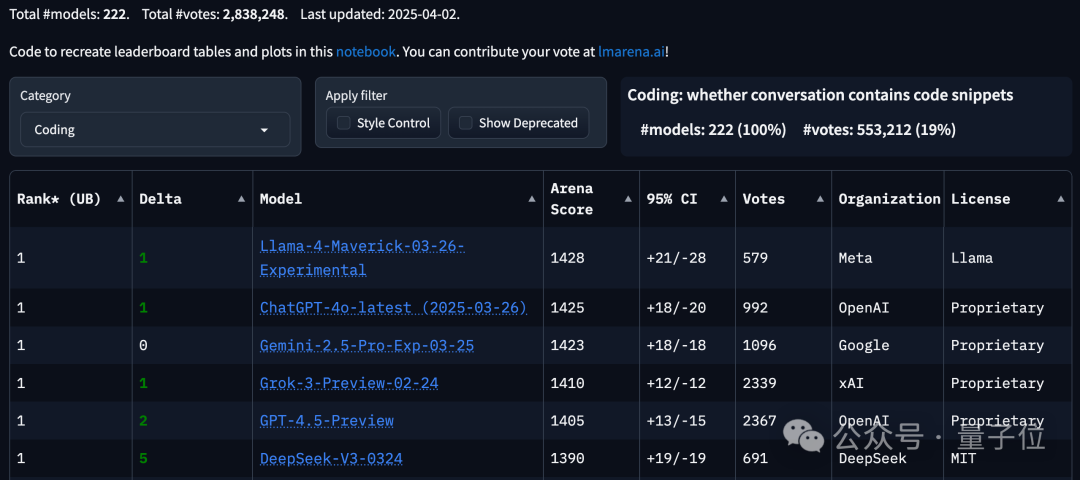
但到了各種第三方基準測試中,情況大多直接逆轉,排名末尾。
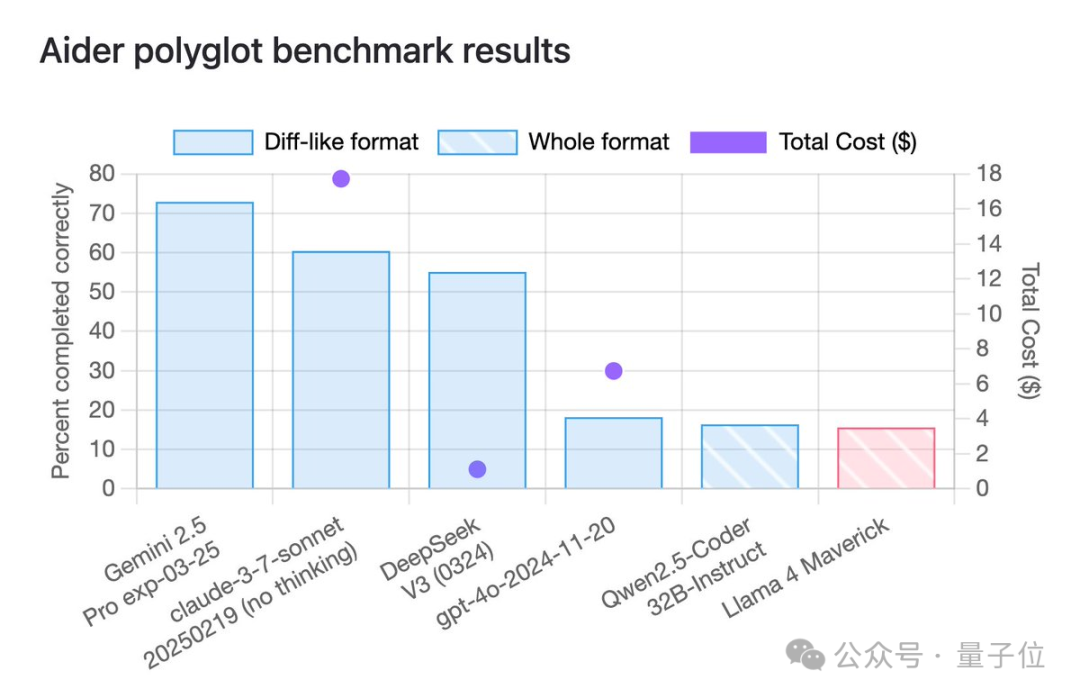
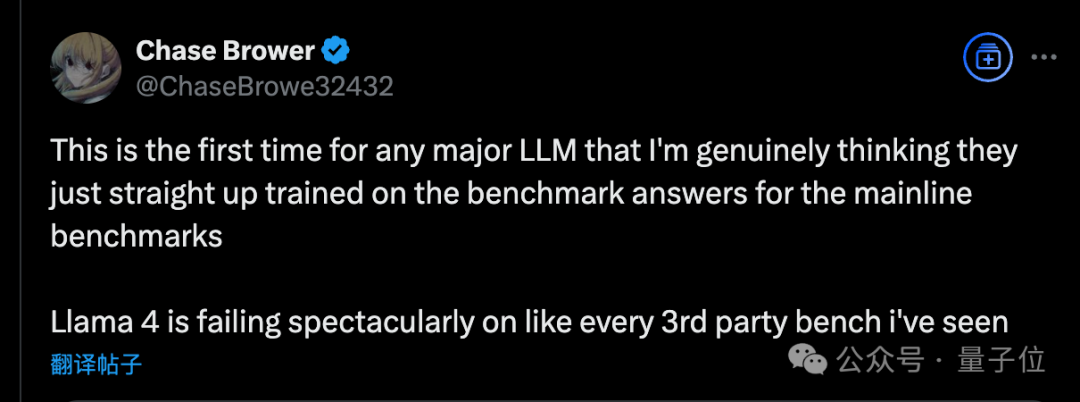
讓人不由得懷疑,這個競技場排名到底是數據過擬合,還是刷票了。
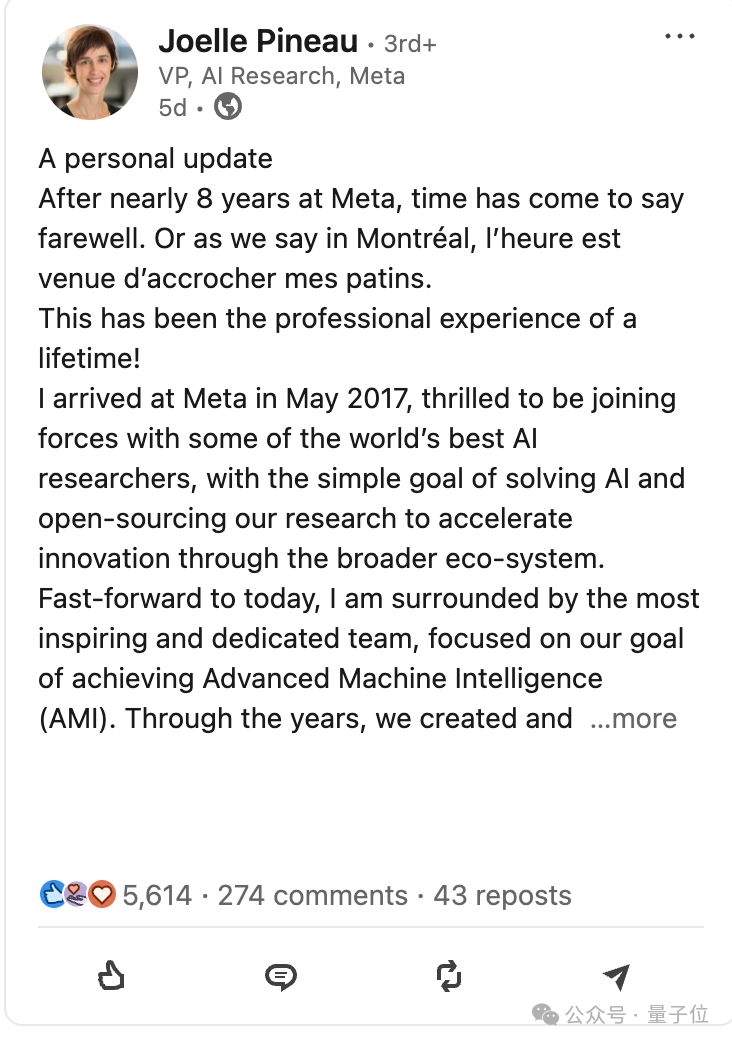
就在 Llama 4 即將發佈前幾天,Meta AI 研究主管 Joelle Pineau 在工作 8 年之後突然宣佈離職,總之就是不太妙。
Llama 4 怎麼了?
大模型關注者們火熱實測「抽水」之際,一則有關 Llama 4 的匿名爆料,突然引起軒然大波:
有網民稱自己已向 Meta GenAI 部門提交提交辭職,並要求不要署名在 Llama 4 的技術報告上。
原貼發佈在海外留學求職交流平台一畝三分地,在國內也引起很多討論。
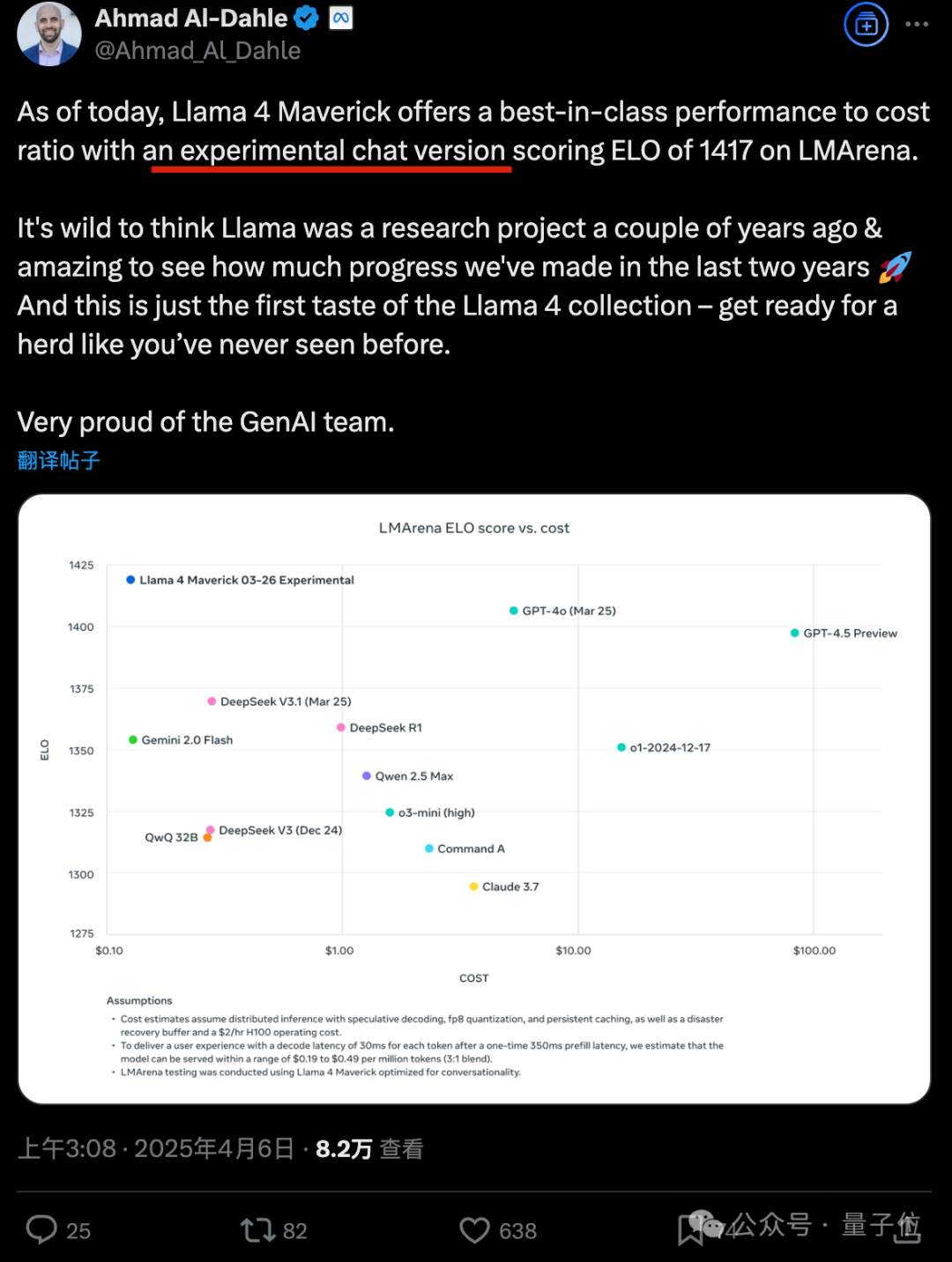
此爆料尚未得到證實,但有人搬出 Meta GenAI 負責人 Ahmad Al-Dahle 的帖子,至少能看出在 Llama 4 大模型競技場里運行的是特殊版本模型。
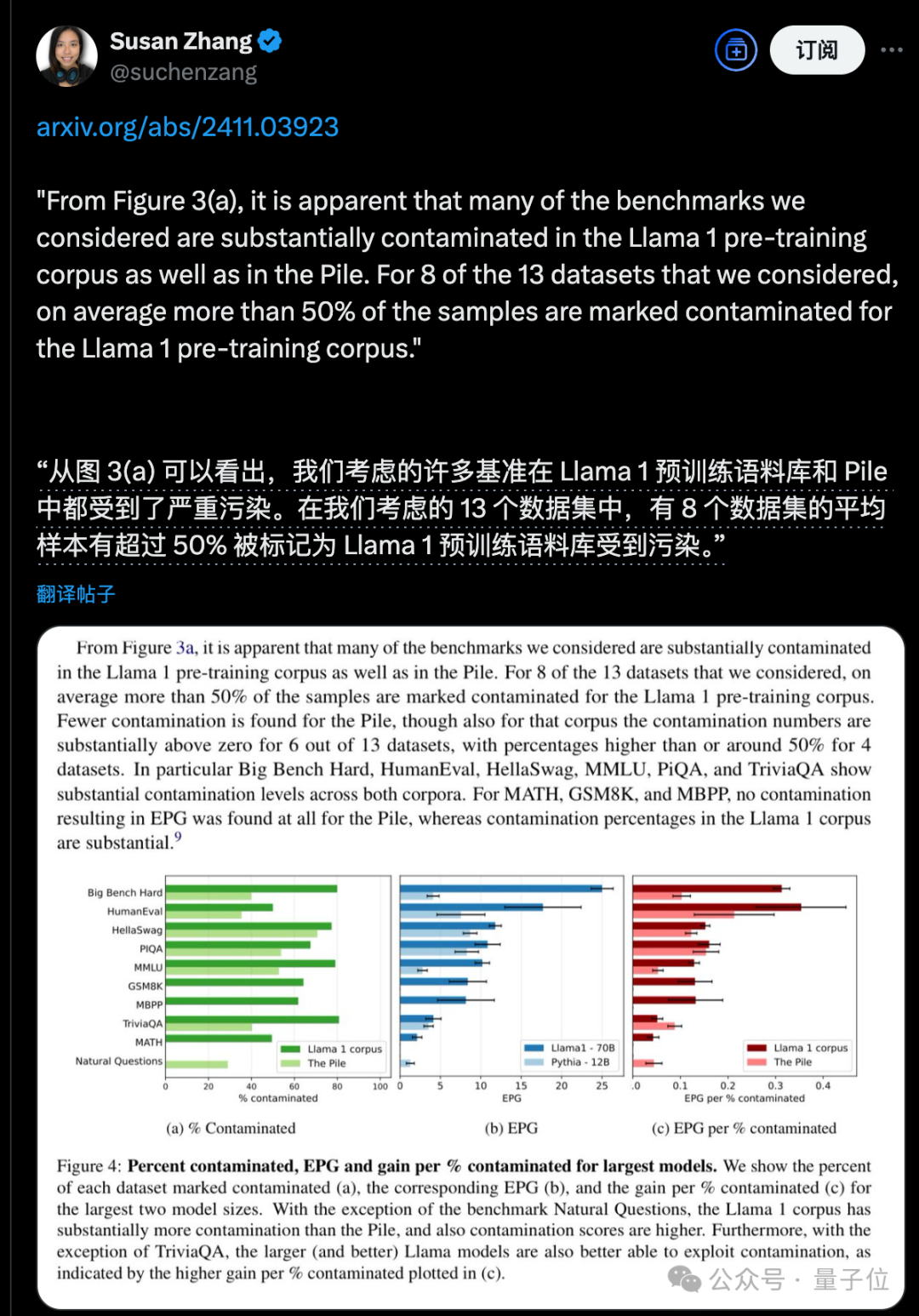
還有 Meta 前員工借此話題貼出 2024 年 11 月的一項研究,指出從 Llama 1 開始數據泄露的問題就存在了。

也不只是編程能力一個方面有問題,在 EQBench 測評基準的的長文章寫作榜中,Llama 4 系列也直接墊底。
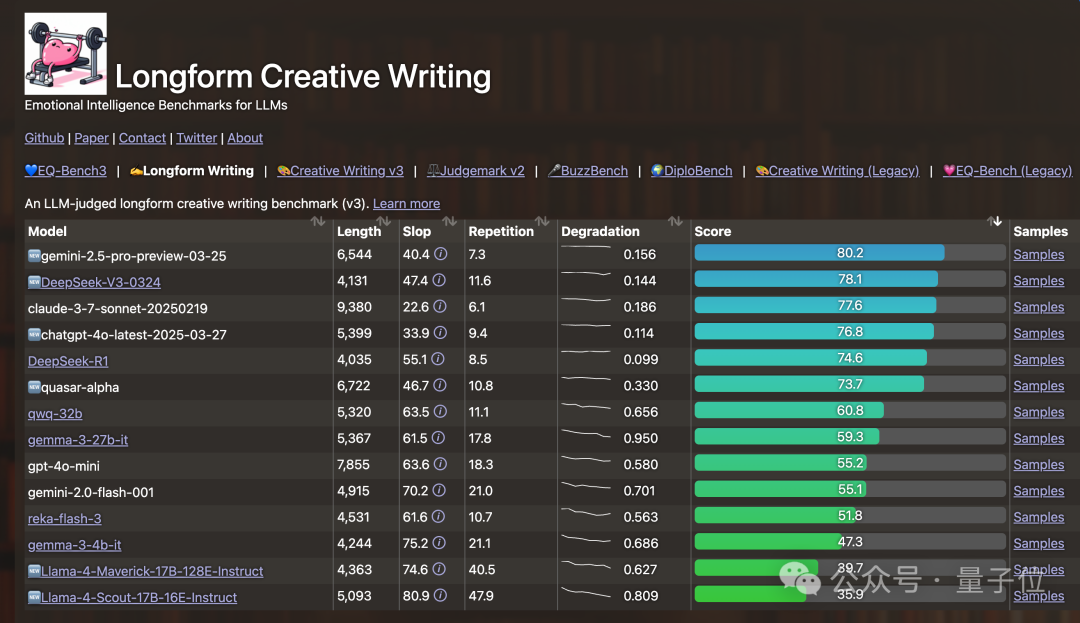
榜單維護者_sqrkl 說明了具體情況。
測試非常簡單,模型需要先完成一個短篇小說的頭腦風暴、反思並修改寫作計劃,最終每輪寫 1000 字,重覆 8 輪以上。
由 Claude-Sonnet 3.7 來當球證,先對每個章節單獨打分,再對整個作品打分。
Llama 4 的低分表現在寫到後面開始大段的內容重覆,以及寫作非常公式化。
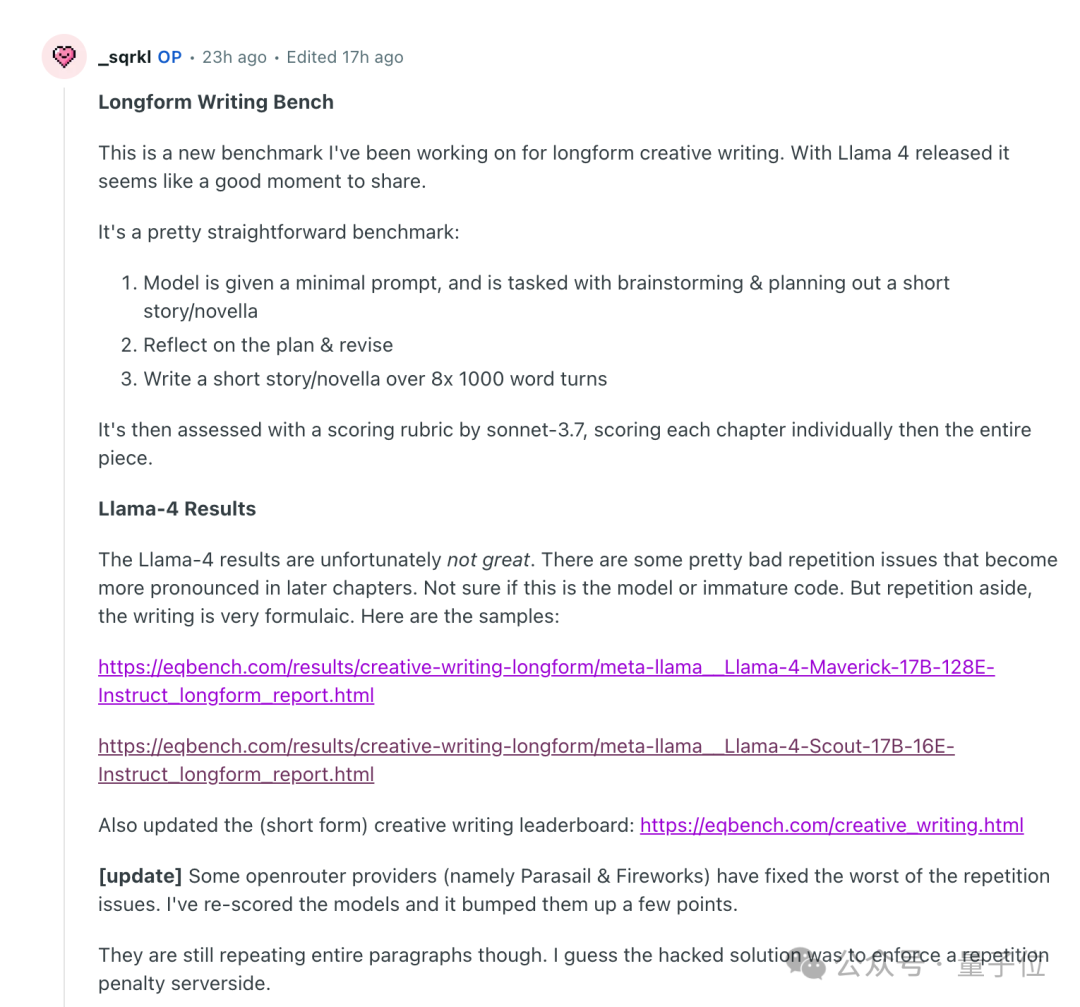
對此結果,有一個猜想是之前的版權訴訟讓 Meta 刪除了網絡和書籍數據,使用了更多的合成數據。
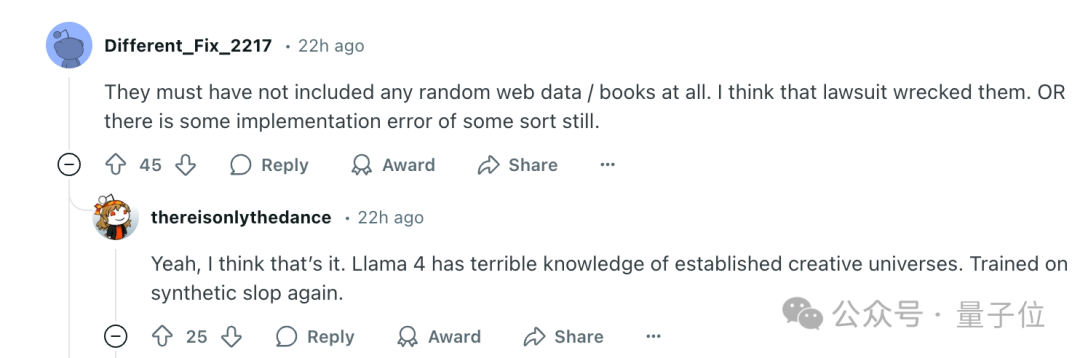
在這場訴訟中,許多作家發現自己的作品可能被用於 AI 訓練,還到倫敦的 Meta 辦公室附近發起抗議。

Llama 4 發佈後的種種,讓人聯想到年初的匿名員工爆,有網民表示當初只是隨便看看,現在卻開始相信了:
在這條爆料中,Deepseek v3 出來之後,訓練中的 Llama4 就顯得落後了,中層管理的薪金都比 DeepSeek V3 的訓練成本都高,Meta 內部陷入恐慌模式。
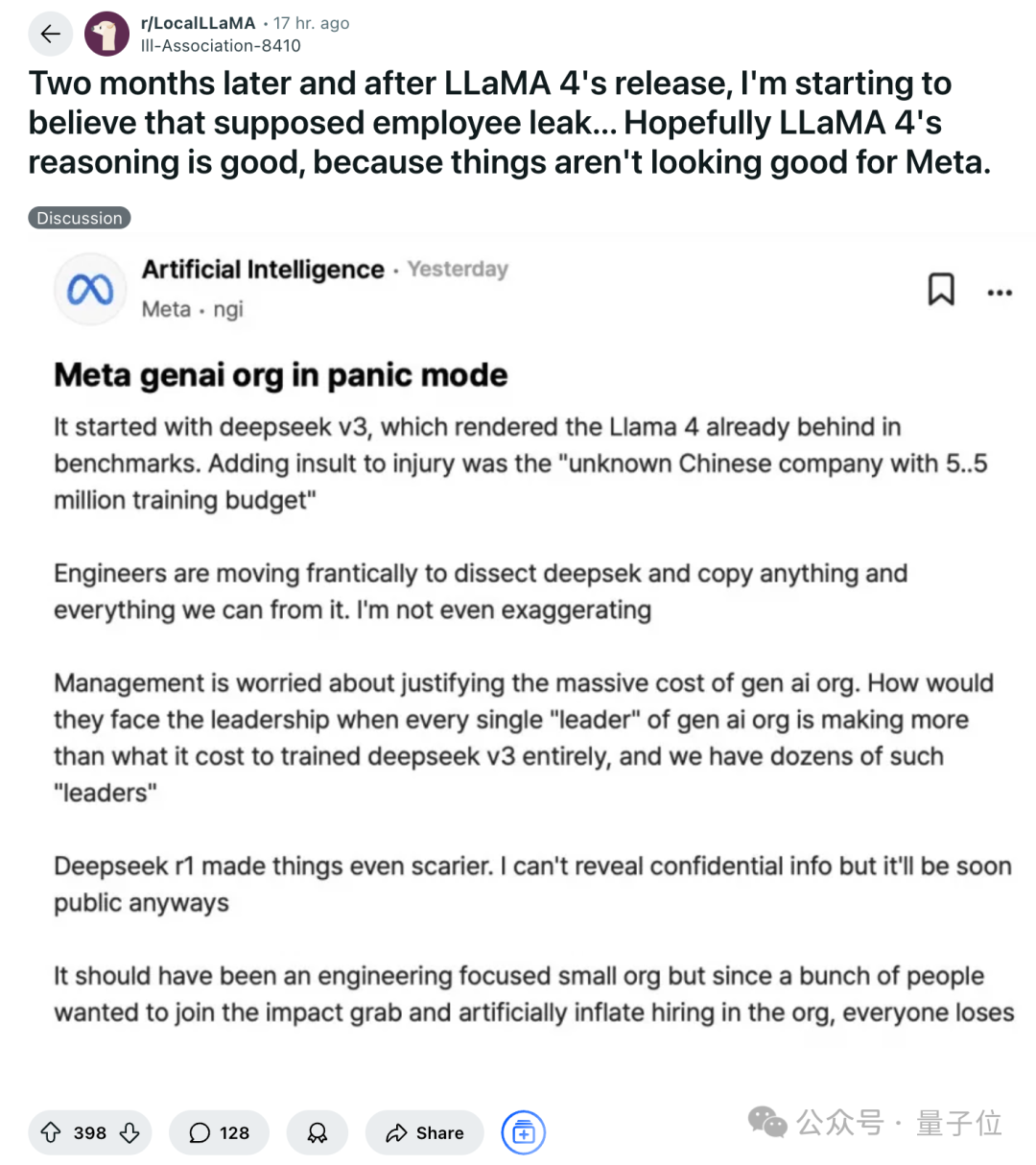
讓人不由得感歎,DeepSeel-R1 橫空出世僅僅兩個月時間,卻像過了幾輩子。

參考鏈接:
-
[1]https://www.reddit.com/r/LocalLLaMA/comments/1jt7hlc/metas_llama_4_fell_short/
-
[2]https://www.1point3acres.com/bbs/thread-1122600-1-1.html
-
[3]https://x.com/suchenzang/status/1909070231517143509
-
https://x.com/TheAhmadOsman/status/1908833792111906894
本文來自微信公眾號:量子位(ID:QbitAI),作者:夢晨,原標題《Llama 4 發佈 36 小時差評如潮!匿名員工爆料拒絕署名技術報告》
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。