中國科大新成果入選 ICLR 2025:特定領域僅用 5% 訓練數據,知識準確率提升 14%
讓大語言模型更懂特定領域知識,有新招了!
來自中國科學技術大學 MIRA 實驗室的王傑教授團隊提出了一個創新的框架 —— 知識圖譜驅動的監督微調(KG-SFT),該框架通過引入知識圖譜(KG)來提升大語言模型(LLMs)在特定領域的知識理解和處理能力。
實驗結果表明,其在多個領域和多種語言的數據集上取得了顯著的效果,成功入選 ICLR 2025。

截至目前,LLMs 在常識問答方面表現越來越出色,但它們對領域知識的理解和推理能力仍然有限。
由於難以深入理解專業領域問答背後所蘊含的複雜知識和邏輯關係,因此在面對這類問題時,往往無法準確地給出正確的答案和詳細的推理過程,這極大地限制了其在專業領域的應用價值。
尤其是在數據稀少和知識密集型的場景中,如何讓 LLMs 更好地理解和操縱知識,成為了研究的關鍵。
而中科大 MIRA 實驗室的這項工作即圍繞此展開。
KG-SFT 是如何工作的
KG-SFT 針對 LLMs 難以理解領域問答背後的知識和邏輯,導致推理能力弱的問題,提出基於知識圖譜增強的大語言模型監督微調技術。
KG-SFT 首先通過解析領域知識圖譜中的多條推理路徑,設計圖上推理路徑與文本推理過程的聯合生成機制。使 LLMs 在監督微調過程中,能夠同步輸出推理答案以及蘊含豐富領域知識和邏輯關係的推理過程,從而提升其對領域知識的理解與推理能力。
KG-SFT 框架的核心在於將知識圖譜與監督微調相結合,通過生成問答背後的邏輯嚴密的推理過程解釋來增強 LLMs 對知識和邏輯的理解。
該框架包含三個關鍵組件:
-
Extractor(提取器)
-
Generator(生成器)
-
Detector(檢測器)
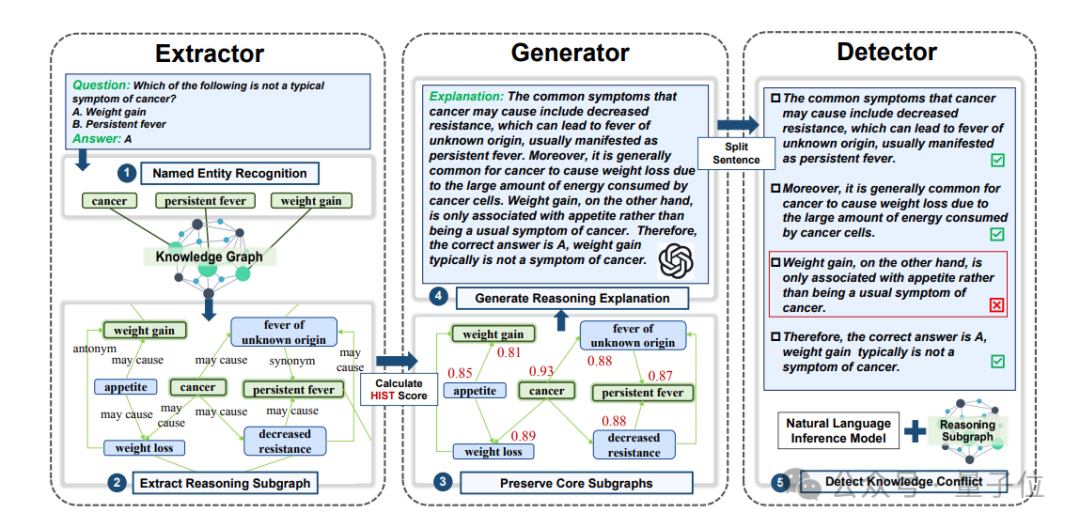
1、Extractor:精準提取知識關聯
Extractor 首先對問答對(Q&A)中的實體進行識別,並從外部知識圖譜中提取相關的推理子圖。
這一步驟揭示了 Q&A 對背後的知識關聯和邏輯,為後續的解釋生成提供了基礎。
通過命名實體識別(NER)和多條推理路徑的檢索,Extractor 能夠有效地從大規模知識圖譜中獲取與問題相關的知識。
2、Generator:生成流暢的解釋
Generator 利用圖結構重要性評分算法(如 HITS 算法)對推理子圖中的實體和關係進行評分,選擇高分部分作為重要內容。
然後,使用大型語言模型(如 ChatGPT)生成流暢的解釋草稿。
這些解釋不僅邏輯清晰,而且能夠幫助 LLMs 更好地理解問題和答案之間的關係。
3、Detector:確保解釋的正確性
Detector 對生成的解釋草稿進行句子級別的知識衝突檢測,確保解釋的正確性。
通過自然語言推理(NLI)模型(如 DeBERTa)和重新引導機制,Detector 能夠標記並糾正可能存在的知識衝突,從而提高解釋的可靠性。
實驗結果及創新點
實驗結果表明,KG-SFT 在多個領域和語言設置中均取得了顯著的性能提升。
特別是在低數據醫學問答任務上,KG-SFT 在英語場景中僅使用 5% 的訓練數據就比傳統方法提高了近 14% 的準確率。
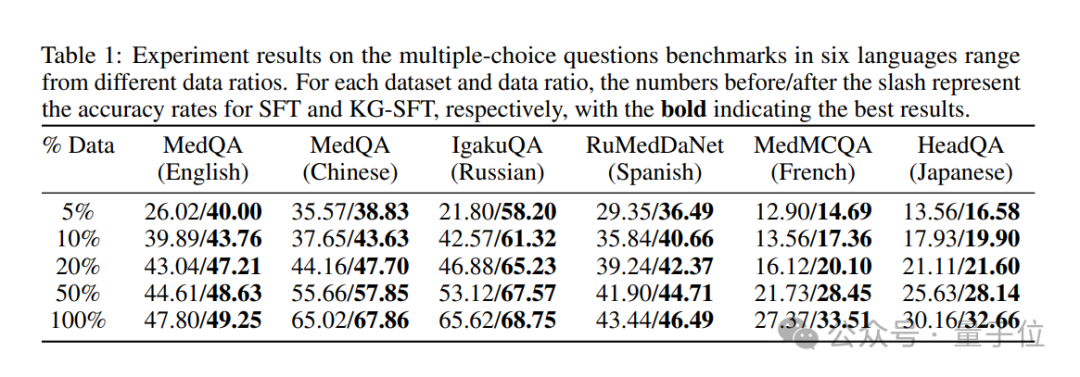
從創新之處來看,KG-SFT 不僅關注數據的數量,更注重數據的質量。
通過生成高質量的解釋,KG-SFT 幫助 LLMs 更好地理解和操縱知識,從而在特定領域實現更優的性能。
此外,KG-SFT 還可以作為插件式模塊與現有的數據增強方法結合使用,進一步提升性能。
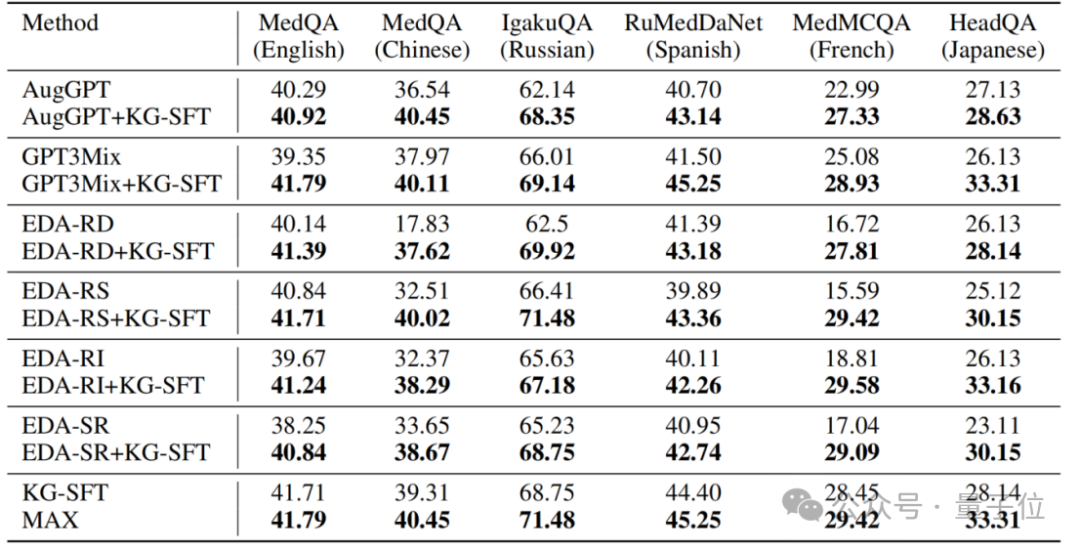
在多領域數據集上的實驗結果進一步驗證了 KG-SFT 的廣泛適用性。
儘管在某些需要複雜推理的領域(如形式邏輯和專業會計)中表現稍遜,但整體性能依然具有較強的競爭力。
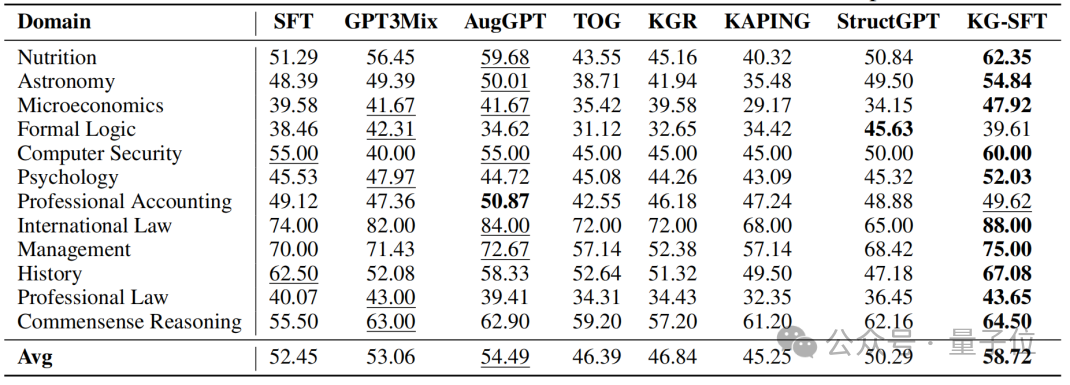
概括而言,KG-SFT 框架通過結合知識圖譜和 LLMs,有效地提升了監督微調數據的質量,從而顯著提高了 LLMs 在特定領域的性能。
這一方法不僅在低數據場景中表現出色,還展示了其作為插件式模塊與現有數據增強方法結合的潛力。
論文作者第一作者陳瀚鑄是中國科學技術大學 2021 級碩博連讀生,師從王傑教授,主要研究方向為大語言模型、知識圖譜和推理數據合成。
更多細節歡迎查閱原論文。
論文地址:
https://openreview.net/pdf?id=oMFOKjwaRS
本文來自微信公眾號:量子位(ID:QbitAI),作者:KG-SFT 團隊,原標題《中科大 ICLR2025:特定領域僅用 5% 訓練數據,知識準確率提升 14%》
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。