CLIP被淘汰了?LeCun謝賽寧新作,多模態訓練無需語言監督更強!

新智元報導
編輯:犀牛
【新智元導讀】LeCun謝賽寧等研究人員通過新模型Web-SSL驗證了SSL在多模態任務中的潛力,證明其在擴展模型和數據規模後,能媲美甚至超越CLIP。這項研究為無語言監督的視覺預訓練開闢新方向,並計劃開源模型以推動社區探索。
最近AI圈最火的模型非GPT-4o莫屬,各種風格圖片持續火爆全網。
如此強悍的圖片生成能力,得益於GPT-4o本身是一個原生多模態模型。
從最新發佈的LLM來看,多模態已經成為絕對的主流。
在多模態領域,視覺表徵學習正沿著兩條採用不同訓練方法的路徑發展。
其中語言監督方法,如對比語言-圖像預訓練(CLIP),利用成對的圖像-文本數據來學習富含語言語義的表示。
自監督學習(SSL)方法則僅從圖像中學習,不依賴語言。
在剛剛發佈的一項研究中,楊立昆、謝賽寧等研究人員探討了一個基本問題:語言監督對於多模態建模的視覺表徵預訓練是否必須?
 論文地址:https://arxiv.org/pdf/2504.01017
論文地址:https://arxiv.org/pdf/2504.01017研究團隊表示,他們並非試圖取代語言監督方法,而是希望理解視覺自監督方法在多模態應用上的內在能力和局限性。
儘管SSL模型在傳統視覺任務(如分類和分割)上表現優於語言監督模型,但在最近的多模態大語言模型(MLLMs)中,它們的應用卻較少。
部分原因是這兩種方法在視覺問答(VQA)任務中的性能差距(圖1),特別是在光學字符識別(OCR)和圖表解讀任務中。
除了方法上的差異,兩者在數據規模和分佈上也存在不同(圖1)。
CLIP模型通常在網絡上收集的數十億級圖像-文本對上進行訓練,而SSL方法則使用百萬級數據集,如ImageNet,或具有類似ImageNet分佈的數億規模數據。
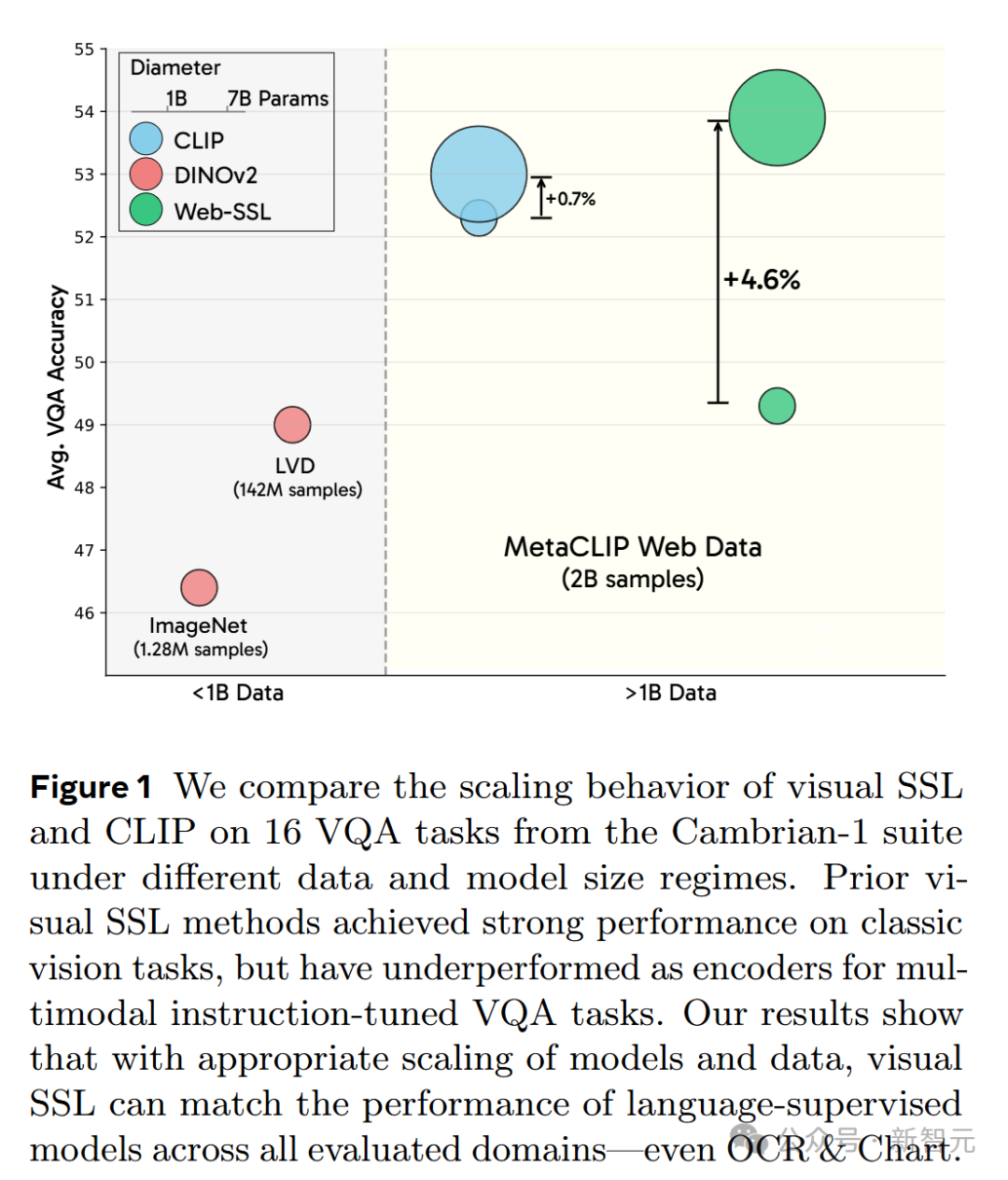
圖1結果表明,通過適當擴展模型和數據規模,視覺SSL能夠在所有評估領域(甚至包括OCR和圖表任務)中匹配語言監督模型的性能
作為本文共同一作的David Fan興奮的表示,他們的研究表明,即便在OCR/Chart VQA上,視覺SSL也能具有競爭力!
正如他們新推出的完全在網頁圖像上訓練、沒有任何語言監督的Web-SSL模型系列(1B-7B參數)所展示的。

為了進行公平比較,研究團隊在數十億級規模網絡數據上訓練SSL模型,與最先進的CLIP模型相同。
在評估方面,主要使用VQA作為框架,採用了Cambrian-1提出的評估套件,該套件評估了16個任務,涵蓋4個不同的VQA類別:通用、知識、OCR和圖表、以及Vision-Centric。
研究團隊使用上述設置訓練了一系列參數從1B到7B的視覺SSL模型Web-SSL,以便在相同設置下與CLIP進行直接且受控的比較。
通過實證研究,研究團隊得出了以下幾點見解:
-
視覺SSL在廣泛的VQA任務中能夠達到甚至超越語言監督方法進行視覺預訓練,甚至在與語言相關的任務(如OCR和圖表理解)上也是如此(圖3)。
-
視覺SSL在模型容量(圖3)和數據規模(圖4)上的擴展性良好,表明SSL具有巨大的開發潛力。
-
視覺SSL在提升VQA性能的同時,仍能保持在分類和分割等傳統視覺任務上的競爭力。
-
在包含更多文本的圖像上進行訓練尤其能有效提升OCR和圖表任務的性能。探索數據構成是一個有前景的方向。
研究人員計劃開源Web-SSL視覺模型,希望激勵更廣泛的社區在多模態時代充分釋放視覺SSL的潛力。
視覺SSL 1.0到2.0
研究人員介紹了本文的實驗設置。相比之前的研究,他們做了以下擴展:
(1) 把數據集規模擴展到十億級別;
(2) 把模型參數規模擴展到超過1B;
(3) 除了用經典的視覺基準測試(比如ImageNet-1k和ADE20k)來評估模型外,還加入了開放式的VQA任務。
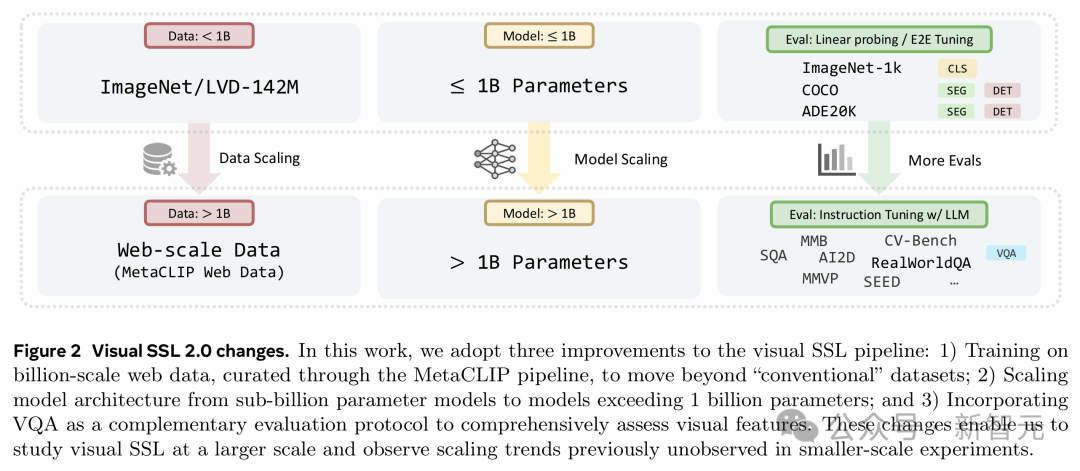 這些變化能在大規模上研究視覺SSL,觀察到之前小規模實驗看不到的規模效應趨勢
這些變化能在大規模上研究視覺SSL,觀察到之前小規模實驗看不到的規模效應趨勢擴展視覺SSL
研究團隊探討了視覺SSL模型在模型規模和數據規模上的擴展表現,這些模型只用MC-2B的圖片數據來訓練。
-
擴展模型規模:研究團隊把模型規模從10億參數增加到70億參數,同時保持訓練數據固定為20億張MC-2B圖片。他們用現成的訓練代碼和方法配方,不因模型大小不同而調整配方,以控制其他變量的影響。
-
擴展看到的數據量:研究團隊把焦點轉向固定模型規模下增加總數據量,分析訓練時看到的圖片數量從10億增加到80億時,性能如何變化。
擴展模型規模
擴展模型規模的目的有兩個:一是找出在這種新數據模式下視覺SSL的性能上限,二是看看大模型會不會表現出一些獨特的行為。
為此,研究團隊用20億張無標籤的MC-2B圖片(224×224解像度)預訓練了DINOv2 ViT模型,參數從10億到70億不等。沒有用高解像度適配,以便能和CLIP公平比較。
研究團隊把這些模型稱為Web-DINO。為了對比,他們還用同樣數據訓練了相同規模的CLIP模型。
他們用VQA評估每個模型,結果展示在圖3中。
研究團隊表示,據他們所知,這是首次僅用視覺自監督訓練的視覺編碼器,在VQA上達到與語言監督編碼器相當的性能——甚至在傳統上高度依賴文字的OCR & 圖表類別上也是如此。
Web-DINO在平均VQA、OCR & 圖表、以及Vision-Centric VQA上的表現,隨著模型規模增加幾乎呈對數線性提升,但在通用和知識類VQA的提升幅度較小。
相比之下,CLIP在所有VQA類別的表現到30億參數後基本飽和。
這說明,小規模CLIP模型可能更擅長利用數據,但這種優勢在大規模CLIP模型上基本消失。
Web-DINO隨著模型規模增加持續提升,也表明視覺SSL能從更大的模型規模中獲益,超過70億參數的擴展是個有前景的方向。
在具體類別上,隨著模型規模增加,DINO在Vision-Centric VQA上越來越超過CLIP,在OCR & 圖表和平均VQA上也基本追平差距(圖3)。
到了50億參數及以上,DINO的平均VQA表現甚至超過CLIP,儘管它只用圖片訓練,沒有語言監督。
這表明,僅用視覺訓練的模型在CLIP分佈的圖片上也能發展出強大的視覺特徵,媲美語言監督的視覺編碼器。
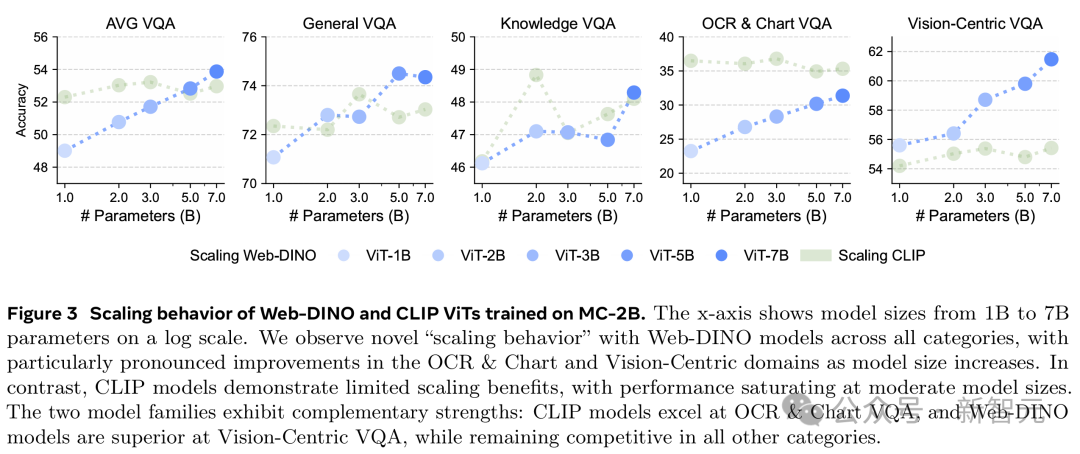
Web-DINO模型在所有類別上都展現出新的「擴展行為」,尤其在OCR & 圖表和Vision-Centric領域,CLIP模型的擴展收益有限,性能在中等規模時就飽和了
擴展所見數據量
研究團隊研究了增加看到的數據量會怎樣影響性能,在MC-2B的10億到80億張圖片上訓練Web-DINO ViT-7B模型。
如圖4所示,通用和知識類VQA性能隨著看到的數據量增加逐步提升,分別在40億和20億張時飽和。
Vision-Centric VQA 性能從10億到20億張時提升明顯,超過20億張後飽和。
相比之下,OCR & 圖表是唯一隨著數據量增加持續提升的類別。
這說明,模型看到更多數據後,學到的表徵越來越適合文字相關任務,同時其他能力也沒明顯下降。
另外,和同規模的CLIP模型(ViT-7B)相比,Web-DINO在相同數據量下的平均VQA表現始終更強(圖 4)。
尤其在看到80億張樣本後,Web-DINO在OCR & 圖表VQA任務上追平了CLIP的表現差距。
這進一步證明,視覺SSL模型可能比語言監督模型有更好的擴展潛力。
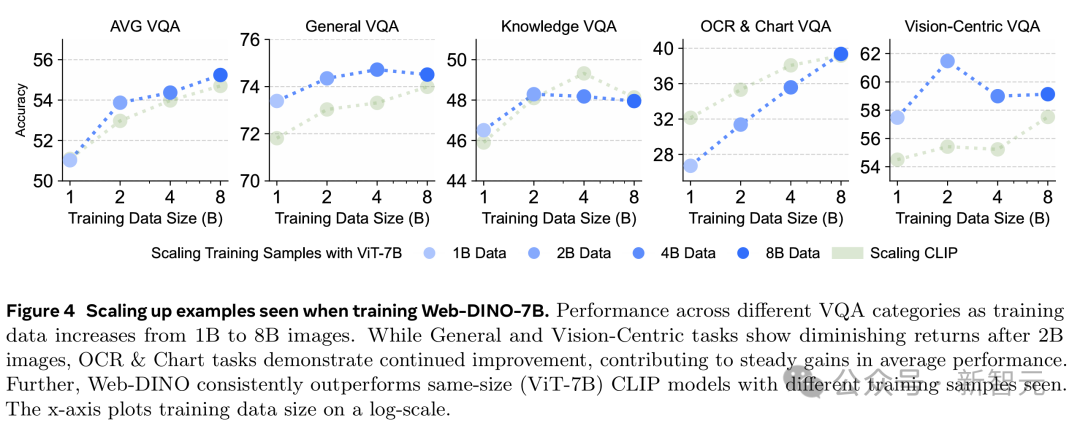
隨著訓練數據從10億增至80億張圖片,Web-DINO-7B在OCR和圖表任務中持續提升,而通用和視覺任務在20億張後收益遞減。總體上,Web-DINO在平均性能上穩步提高,並始終優於同規模的CLIP模型
Web-SSL系列模型
研究團隊在表3里展示了他們的視覺編碼器跟經典視覺編碼器對比所取得的最佳結果,涉及VQA和經典視覺任務。
Web-DINO在VQA和經典視覺任務上都能超越現成的MetaCLIP。
即便數據量比SigLIP和SigLIP2少5倍,也沒語言監督,Web-DINO在VQA上的表現還是能跟它們打和手。
總體來看,Web-DINO在傳統視覺基準測試中碾壓了所有現成的語言監督CLIP模型。
雖然研究人員最好的Web-DINO模型有70億參數,但結果表明,CLIP模型在中等規模的模型和數據量後就飽和了,而視覺SSL的性能隨著模型和數據規模的增加會逐步提升。
Web-DINO在所有VQA類別中也超過了現成的視覺SSL方法,包括DINOv2,在傳統視覺基準上也很有競爭力。
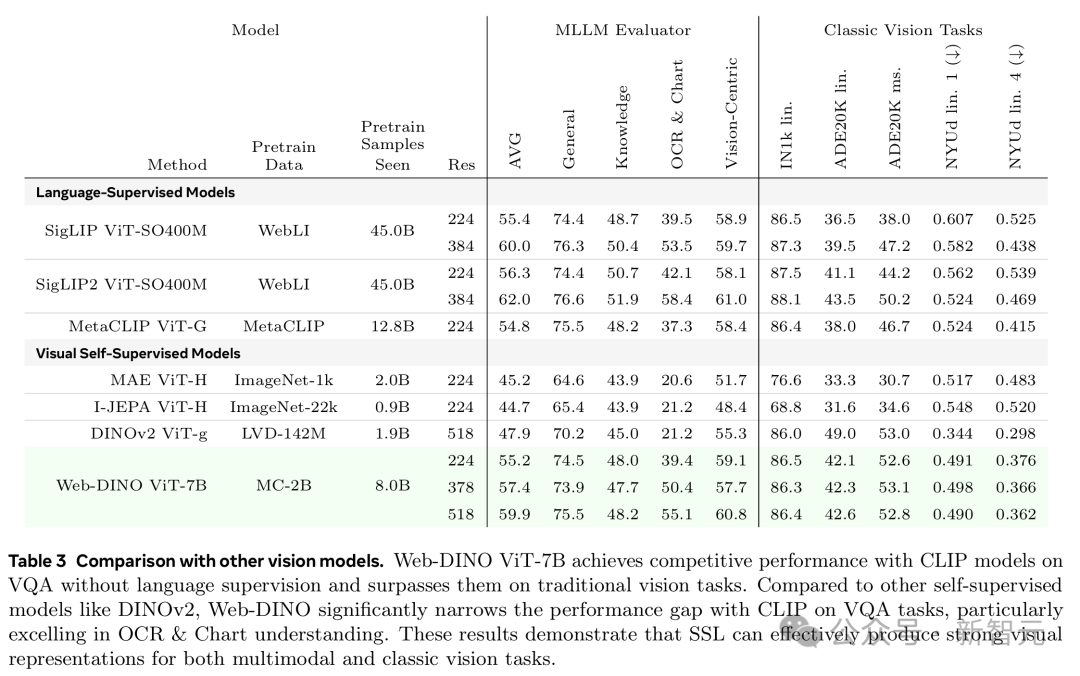 Web-DINO ViT-7B在沒有語言監督的情況下,在VQA任務上與CLIP模型表現相當,在傳統視覺任務上超過了它們
Web-DINO ViT-7B在沒有語言監督的情況下,在VQA任務上與CLIP模型表現相當,在傳統視覺任務上超過了它們研究人員還額外對Web-DINO微調了2萬步,分別測試了378和518解像度,以便跟更高解像度的現成SigLIP和DINO版本對比。
從224到378再到518解像度,Web-DINO在平均VQA表現上穩步提升,尤其在OCR和圖表任務上有明顯進步。
經典視覺任務的表現隨著解像度提高略有提升。在384解像度下,Web-DINO稍微落後於SigLIP;到了518解像度,差距基本被抹平。
結果表明,Web-DINO可能還能從進一步的高解像度適配中獲益。
作者介紹
David Fan

David Fan是Meta FAIR的高級研究工程師,研究方向是自監督學習和影片表徵。
曾在亞馬遜Prime Video擔任應用科學家,從事影片理解和多模態表徵學習的研究,重點關注自監督方法。
此前,他在普林斯頓大學以優異成績(Magna Cum Laude)獲得計算機科學理學工程學士學位,導師是Jia Deng教授。
Shengbang Tong

Peter Tong(Shengbang Tong,童晟邦)是NYU Courant CS的一名博士生,導師是Yann LeCun教授和謝賽寧教授。研究興趣是世界模型、無監督/自監督學習、生成模型和多模態模型。
此前,他在加州大學伯克利分校主修計算機科學、應用數學(榮譽)和統計學(榮譽)。並曾是伯克利人工智能實驗室(BAIR)的研究員,導師是馬毅教授和Jacob Steinhardt教授。
參考資料:
https://x.com/DavidJFan/status/1907448092204380630
https://arxiv.org/abs/2504.01017