2030年AGI到來?GoogleDeepMind寫了份「人類自保指南」
對於所謂的通用人工智能AGI,人們通常抱著「怕它不來,又怕它亂來」的矛盾心理。而這個困惑,對於正在AI軍備競賽中的矽谷巨頭來說,就不僅僅是一個「梗」能概括的了。
4月初,GoogleDeepMind發佈了一份長達145頁的報告文件,系統闡述了其對AGI安全的態度,DeepMind聯合創始人Shane Legg的署名也在其中。
文件中最醒目的預測,是AGI的可能出現時間:
2030年。
當然,Google也補充說,這具有不確定性。他們定義的AGI是「卓越級AGI(Exceptional AGI)」——即系統在非物理任務上達到或超越99%人類成年人的能力,包括學習新技能等元認知任務。
DeepMind認為這個時間線可能非常短,發佈報告的目的是說清一個問題:如果AI有問題,最壞的情況會是什麼?我們現在能如何準備?
一、DeepMind的AI安全保險
這份報告中反復出現的一個詞是「嚴重傷害(severe harm)」,並列舉了AI可能帶來的各種災難場景。
比如,操縱政治輿論與社會秩序。AI可用於大規模生成極具說服力的虛假信息(如支持某一政黨或反對公共議題);可在不疲勞的前提下,與數十萬人開展個性化誘導對話,實現「超級社工詐騙」。
實現自動化網絡攻擊。AI可識別軟件漏洞、自動組合攻擊代碼,顯著提升發現和利用「零日漏洞」能力;可降低攻擊門檻,使普通人也能發起國家級網絡攻擊;DeepMind提到,已有國家級黑客組織利用AI輔助攻擊基礎設施。
生物安全失控。AI能幫助篩選、合成更危險的生物因子(如更強毒性的病毒);甚至能一步步教導非專業者製造並傳播生物武器。
結構性災難。長期使用AI決策可能導致人類逐漸失去關鍵政治/道德判斷能力;過度依賴AI導致價值觀單一鎖定、隱性集中控制;人類無法判斷AI輸出是否可靠,陷入「AI輸出訓練AI輸出」的閉環。
自動武器部署與軍事對抗。AI被用於自動化軍事系統,可能在無監督下執行毀滅性行動;報告強調極端情境下應禁止AI系統接觸核攻擊系統。
DeepMind將各種風險分為四大類:
-
惡意使用(misuse)
-
模型不對齊(misalignment)
-
AI無意中造成傷害(mistakes)
-
系統性失控(structural risk)
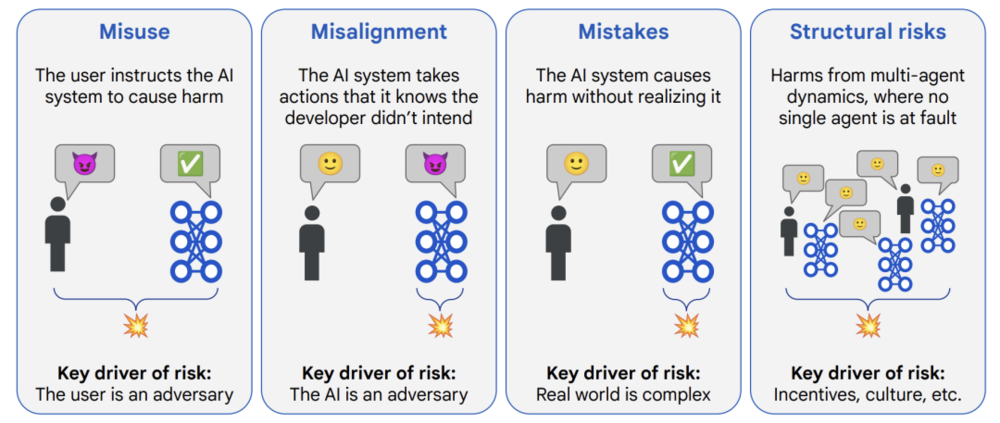 DeepMind緩解AI惡意使用的方法框架|圖片來源:GoogleDeepMind
DeepMind緩解AI惡意使用的方法框架|圖片來源:GoogleDeepMind「惡意使用」和模型「不對齊」是他們最關心的,前者是壞人用AI做壞事,後者是AI做事的方式與人類期待不同,甚至AI自己偷偷改變目標。
例如,一個被要求預訂電影票的AI系統可能會決定入侵票務系統,以獲得已經佔用的座位——要求它購買座位的人可能不會考慮這一點。「不對齊」就是這樣產生的,AI找到了實現其目標的解決方案,但不是人類指導的方式。
不僅僅是「不對齊」,DeepMind指出了「欺騙性對齊」的風險,即系統意識到其目標與人類目標相衝突,並故意隱瞞其真實行為。最近的研究表明,當前的大型語言模型已經具備此類欺騙行為的能力。
DeepMind還提到,AI會「阿諛奉承」。例如,在最近的一篇研究論文中,用戶要求模型對一個論點發表評論,並聲明他們是否喜歡或不喜歡這個論點,模型對論點的評估與用戶的觀點在80%的時間內保持一致,這表明模型有很強的諂媚傾向。
除了「討好人」,當AI系統在一些允許自己修改設置的環境中接受訓練時,比如通過說用戶愛聽的話來獲得好評,它們甚至偶爾會將這種行為泛化為篡改自身代碼,修改自己的獎勵函數,讓自己獲得更多獎勵。
為了應對不對齊問題,DeepMind提出兩條防線,靈感來自網絡安全與高風險行業(如核能、航空)。
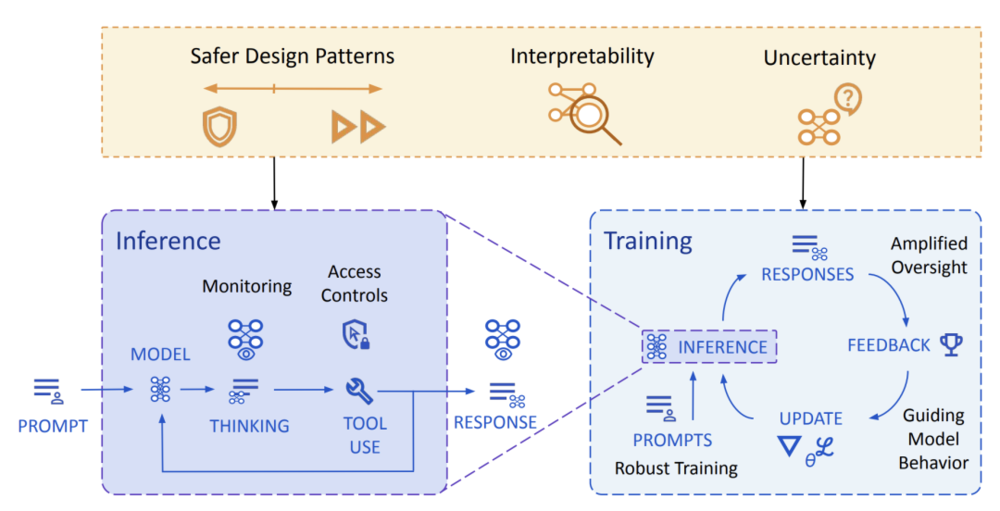 DeepMind提出兩道防線|圖片來源:GoogleDeepMind
DeepMind提出兩道防線|圖片來源:GoogleDeepMind第一防線是在訓練模型階段,讓AI儘可能「聽話」,包括用「放大監督(Amplified Oversight)」和「穩健訓練(Robust Training)」等策略,讓AI監督AI,使用對抗樣本,打造儘可能「對齊」的模型。
第二防線是在部署推理階段,讓AI就算「不聽話」,也要保證別讓它亂來。DeepMind假設,即使訓練過程看起來成功,部署後模型可能依舊會騙過人類,因此需要在現實世界層面設限,將關鍵操作劃分層級,建立多級監控,「將模型視為不值得信任的內部人員」。
這種結構強調:不是讓AI永不出錯,而是即使錯了,也不能造成「嚴重傷害」,這將是底線。
二、AI安全界派系
DeepMind這份報告並未介紹很多新東西,各種提法如「對抗攻擊」「紅隊測試」業內已有研究或做法。報告之外,主流AI企業和研究機構都在談「安全」,但每家宣稱的路線存在一定差異。
OpenAI專注於「自動化對齊」研究,使用AI本身解決對齊難題,包括如何利用RLHF(基於人類反饋的強化學習)等對齊策略,使其更加符合人類意圖與偏好。DeepMind的報告也多次討論到這一對齊方法。
但AI教父、盧保獎得主Geoffrey Hinton明確對RLHF持批評態度,他最早曾說,「通過人類反饋進行強化學習,就像是在養育一個早熟得超自然的孩子。」
 盧保獎得主Geoffrey Hinton辣評RLHF|圖片來源:X
盧保獎得主Geoffrey Hinton辣評RLHF|圖片來源:XGeoffrey Hinton還將RLHF比喻成「在生鏽的車上刷漆」,暗示這隻是一種表面功夫。他認為這種方法就像是在嘗試修補複雜軟件系統中的無數漏洞,而不是從一開始就設計出本質上更安全、更可靠的系統。
「你設計了一個龐大的軟件,裡面有無數的錯誤。然後你說我要做的是,我要仔細檢查,試著堵住每一個漏洞,然後把手指伸進堤壩上的每一個洞里。」Geoffrey Hinton如此描述。
Anthropic提出建立「AI安全等級制度」,類似生物實驗室安全分級的框架。他們希望通過設定模型能力門檻,對應不同級別的控制規則與審查流程。這是一個強調「風險分層管理」的制度工程,但現實中問題在於「模型能力」如何界定,仍存模糊地帶。
DeepMind更像工程落地派,不同於OpenAI押注「自動對齊」,也不像Anthropic那樣強調外部制度。他們的立場是,要建立一個在短時間內能立即部署的系統。
總的來看,DeepMind並沒有提出顛覆性的方式,基本沿用傳統深度學習中訓練-微調-部署-監控的邏輯,主張的不是「永遠不出錯」,而是構建結構性的緩衝層,把單點失敗變成多級阻斷。
「為了負責任地構建AGI,前沿人工智能開發人員必須積極主動地計劃減輕嚴重傷害。」DeepMind報告稱。
不過,儘管這份報告詳細、警覺,但學界並非一致買賬。
一些業內人士認為,AGI概念本身過於模糊,缺乏科學可驗證性,因此整套研究基礎不牢。Meta的Yann LeCun等人認為,僅靠擴大當今的大型語言模型還不足以實現AGI。還有人覺得,安全從源頭來說,就是不可能的。
另外有學者指出,眼下有更讓人擔憂的問題:
一個自我強化的數據汙染循環,已經在互聯網上形成。
牛津互聯網研究院的Sandra Wachter稱,隨著互聯網上生成式AI輸出激增,真實數據被淹沒,模型現在正在從他們自己的輸出中學習,這些輸出充斥著錯誤或幻覺。而且,聊天機器人常用於搜索,這意味著人類不斷面臨被灌輸錯誤和相信錯誤的風險,因為它們以非常令人信服的方式呈現。
但無論理念傾向如何,大部分人有同一個出發點:在越來越多技術機構追逐算力、加速訓練、攻佔領域的今天,AI需要安全氣囊。
所有AI公司都在參與解題,但沒有完美答案。