OpenAI 發佈大模型現實世界軟件工程基準測試 SWE-Lancer

作者 | Daniel Dominguez
譯者 | 明知山
策劃 | 丁曉昀
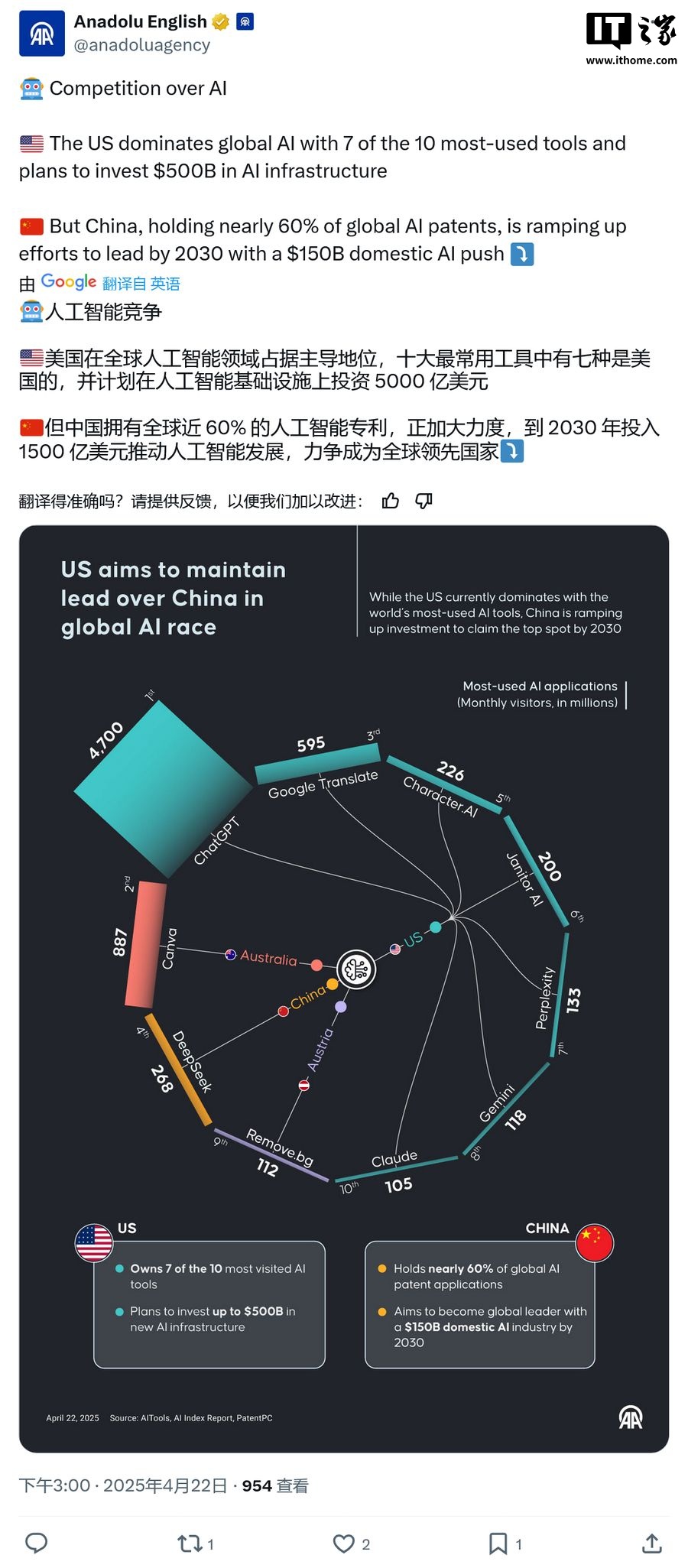
OpenAI 發佈 SWE-Lancer 基準測試,用於評估 AI 大語言模型在現實世界自由職業軟件工程任務中的表現。該基準測試的數據集包含來自 Upwork 的 1400 多個任務,總價值高達 100 萬美元。這些任務既包括獨立的編碼活動,也包括管理決策,複雜程度和報酬各有不同,充分模擬了現實世界中的自由職業場景。
SWE-Lancer 通過嚴格的評估方法來反映軟件工程的經濟價值和複雜性。它採用經過專業工程師驗證的先進的端到端測試方法來評估模型在實際環境中的表現。儘管 AI 大語言模型近期取得了顯著進展,但初步結果顯示,這些模型在應對基準測試中的多數任務時仍然面臨嚴峻挑戰。
基準測試涵蓋了多種任務,如應用程序邏輯開發、UI/UX 設計以及服務器端邏輯實現,確保能夠對模型能力進行全面的評估。SWE-Lancer 還為研究人員提供了一個統一的 Docker 鏡像和公共評估拆分,用以促進 AI 模型評估過程中的協作和透明度。
該項目旨在推動對 AI 在軟件工程領域經濟影響的研究,特別是潛在的生產力提升和對勞動力市場的影響。通過將模型性能與貨幣價值聯繫起來,SWE-Lancer 展現了 AI 在軟件工程中的實際影響,並凸顯了持續優化 AI 技術的重要性。
在基準測試中表現最好的模型是 Claude 3.5 Sonnet,在獨立編碼任務中的成功率為 26.2%,這表明 AI 能力仍有很大的提升空間。許多模型在需要深度上下文理解或評估多個提案的任務方面表現不佳,這表明未來的模型可能需要更複雜的推理能力。
一些評論表示對 SWE-Lancer 的實際應用表示懷疑,認為可能只對特定群體有吸引力,另一些人則認為這是理解 AI 對軟件工程社會經濟影響的關鍵一步,與行業向 AI 驅動的生產力工具發展的整體趨勢相契合,正如 Gartner 2027 所預測的軟件工程智能平台的廣泛採用。
用戶 Alex Bon 表示:
終於有機會讓 AI 證明它也能在零工經濟中生存下來了!
獨立黑客 Jason Leow 則表示:
我喜歡這個發展方向。用全棧問題進行測試,將其與市場價值聯繫起來,這正是日常開發工作所面臨的東西。我一直覺得舊的基準測試有些不太對勁。
SWE-Lancer 為評估 AI 在自由職業軟件工程中的應用提供了一個重要的框架,揭示了 AI 在實際應用中的挑戰與機遇。基準測試的結果凸顯了進一步研究和開發的必要性,以便提升 AI 模型在現實世界軟件工程任務中的表現。
查看英文原文:
https://www.infoq.com/news/2025/03/openai-swe-benchmark/
聲明:本文為 AI 前線整理,不代表平台觀點,未經許可禁止轉載。