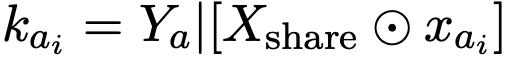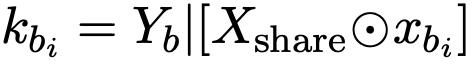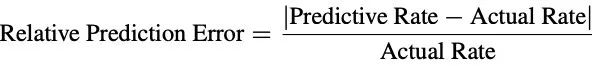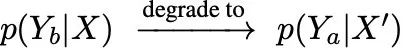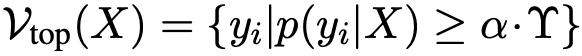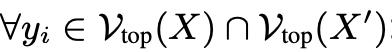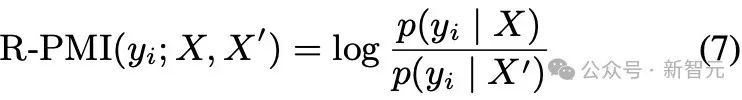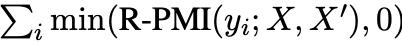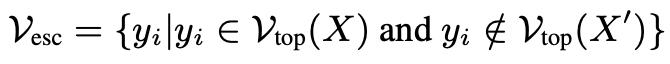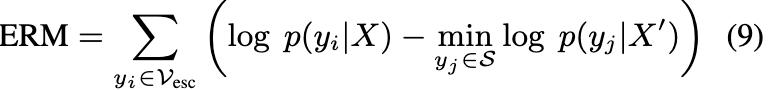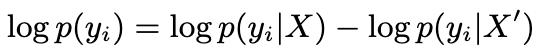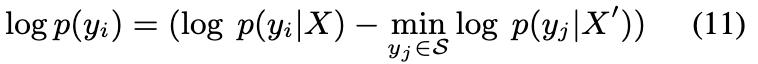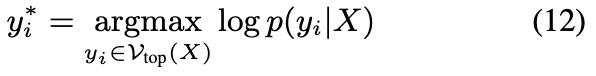LLM幻覺,竟因知識「以大欺小」,華人團隊祭出對數線性定律與CoDA策略

【導讀】來自UIUC等大學的華人團隊,從LLM的基礎機制出發,揭示、預測並減少幻覺!通過實驗,研究人員揭示了LLM的知識如何相互影響,總結了幻覺的對數線性定律。更可預測、更可控的語言模型正在成為現實。
大語言模型(LLMs)已經徹底改變了AI,但「幻覺」問題如影隨從,堪稱LLM癌症。
LLM會一本正經、義正辭嚴的捏造事實,「臉不紅,心不跳」地說謊。
「幻覺」被普遍認為與訓練數據相關。
但在掌握真實訓練數據的情況下,為什麼LLM還會幻覺?能否提前預測LLM幻覺的發生?
來自美國伊利諾伊大學香檳分校UIUC、哥倫比亞大學、西北大學、史丹福大學等機構的研究團隊,在Arxiv上發佈預印本,提出了知識遮蔽定律(The Law of Knowledge Overshadowing):揭示、預測並減少LLM幻覺!
一作張雨季宣佈新發現,介紹了LLM幻覺的對數線性定律(Log-Linear Law),分享了最新研究成果:
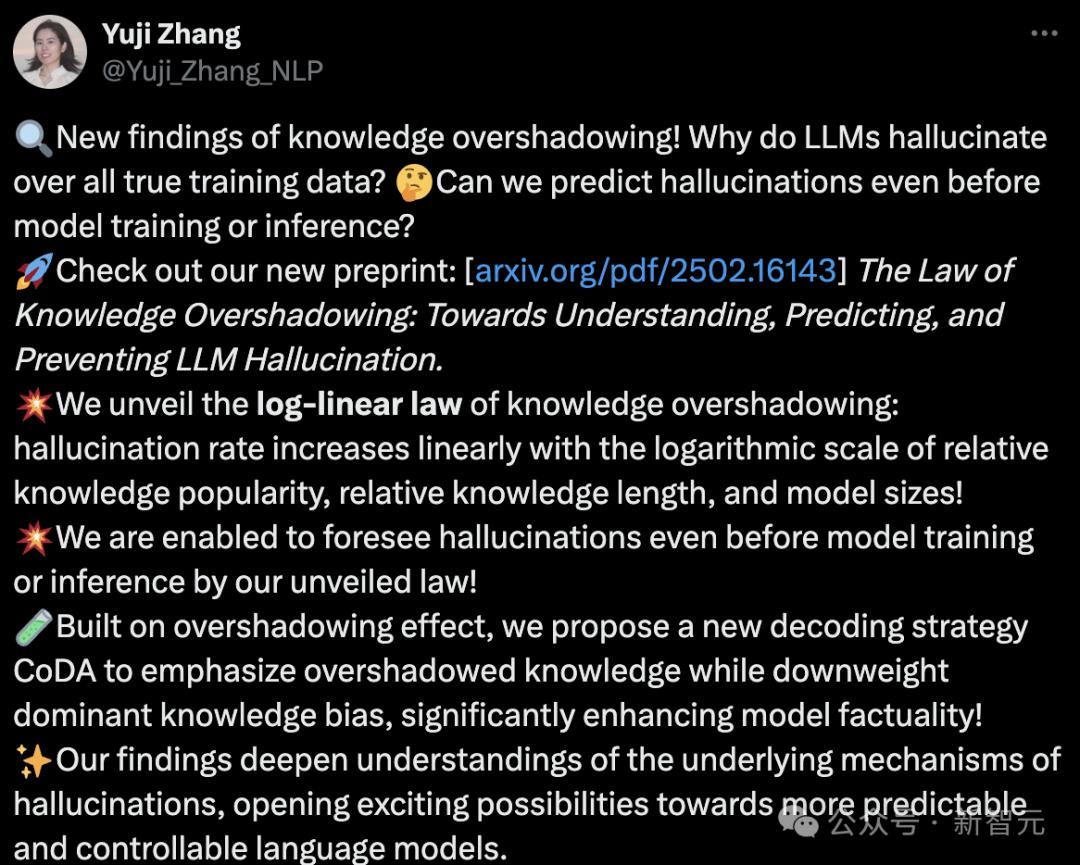
此研究深入研究了LLM幻覺,有4大亮點:
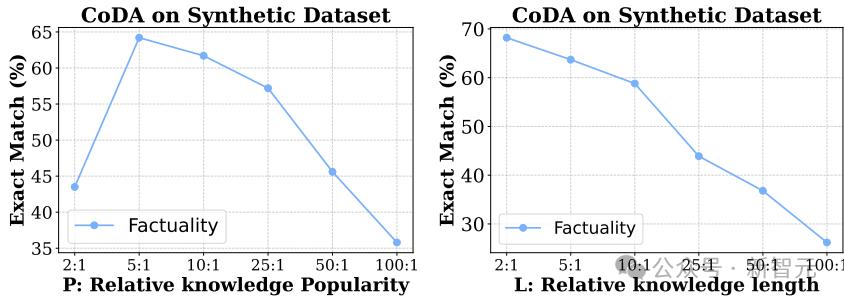
1 發現幻覺的對數線性規律:幻覺率隨著相對知識流行度、相對知識長度和模型規模的對數線性增長
2 在訓練或推理前預測幻覺:在訓練前「知識遮蔽效應」可預測幻覺發生的可能性
3 提出全新解碼策略CoDA(Contrastive Decoding with Attenuation)強調被遮蔽的知識,降低主流知識偏差,大幅提升LLM事實性(Factuality)
4 更可預測、更可控的語言模型正在成為現實!研究加深了對LLM幻覺機制的理解,為未來的可解釋性與可控性研究打開新方向

論文鏈接:https://arxiv.org/abs/2502.16143
LLM存在一種根本矛盾:
即使使用高質量的訓練數據,「幻覺」依舊存在。
要解決這一矛盾,需要對LLL的根本機制有更深入的理解。
為此,本次研究團隊提出了新概念:「知識遮蔽」,即模型中的主導知識可以在文本生成過程中,掩蓋那些不太突出的知識,從而導致模型編造不準確的細節。
基於這一概念,研究者引入了新的框架來量化事實性幻覺,通過模擬知識遮蔽效應實現。
事實性幻覺的發生率會隨著以下3個因素的對數尺度線性增加:(1)知識普及度,(2)知識長度,以及(3)模型大小。
基於這一規律,可以預先量化幻覺現象,甚至在模型訓練或推理之前,就能預見幻覺出現。
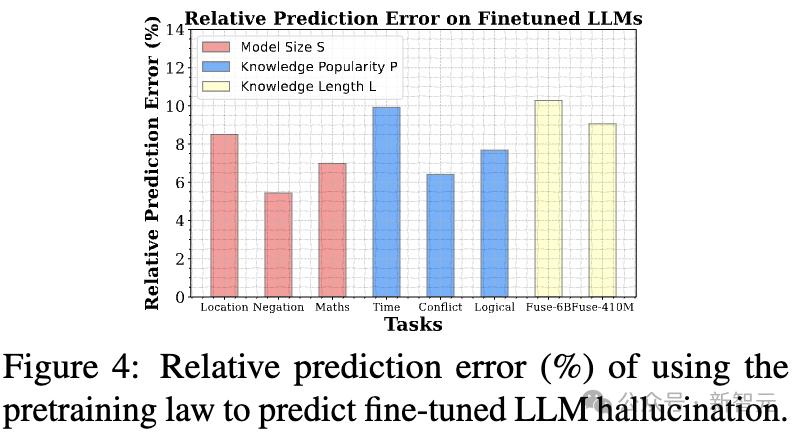
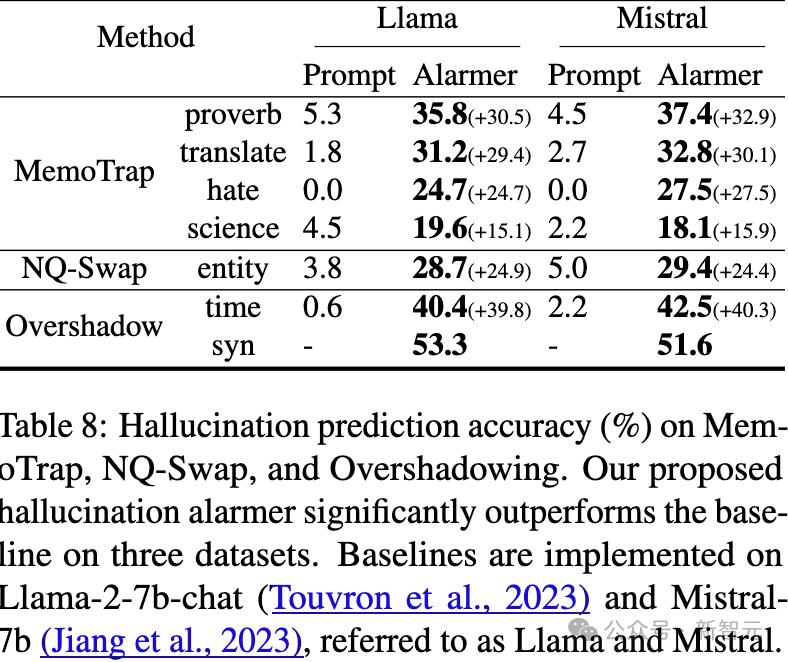
在遮蔽效應基礎之上,研究人員還提出了一種新的解碼策略CoDa,以減少幻覺現象,這顯著提高了模型在Overshadow(27.9%)、MemoTrap(13.1%)和NQ-Swap(18.3%)測試中的事實準確性。
新研究不僅加深了對幻覺背後基礎機制的理解,也為開發更加可預測和可控的語言模型提供了可行的見解。
什麼是「LLM幻覺」
LLM的「幻覺」指的是模型生成不真實或非事實陳述的現象。
給出提示「LLM幻覺」,AI自己可以解釋什麼是LLM幻覺:

排名第一的原因就是訓練數據問題。
然而,發現即使在嚴格控制預訓練語料庫僅包含事實陳述的情況下,這一問題仍然存在。
具體來說,在使用查詢提取知識時,觀察到某些知識傾向於掩蓋其他相關信息。
這導致模型在推理過程中未能充分考慮被掩蓋的知識,從而產生幻覺。
知識遮蔽導致幻覺
「知識遮蔽」(knowledgeovershadowing)是指更常見的知識會抑制較少出現的知識,從而導致幻覺的產生。
為了系統地描述知識遮蔽現象,在訓練語料庫中,研究人員定義了知識對(knowledge pairs)。
具體來說,設
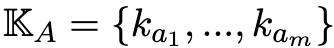
和
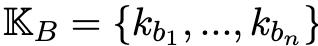
代表一對知識集合。
其中,K_A包含m個知識陳述樣本ka_i,而K_B包含n個知識陳述樣本kb_j。
在K_A和K_B中的每個陳述都通過一個共享的詞元集合X_{share}相關聯。
在知識集K_A中,每個聲明ka_i由一個共享的token序列Xshare、一個唯一的token序列xai和輸出Ya組成。
每個聲明kai表示為:
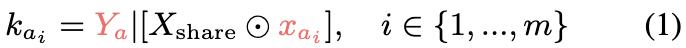
其中⊙表示將獨特的序列xai插入Xshare中(整合位置可以變化)。
同樣,對於不太受歡迎的知識集K_B,用xbj表示獨特的token序列,每個聲明kbj表述為:
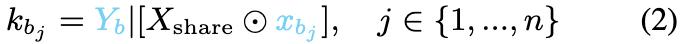
當在推理過程中抑制獨特的token序列xbj或xai時,會發生知識遮蔽。
以xbj被遮蔽為例,當提示Xshare⊙xbj時,模型輸出Ya,形成
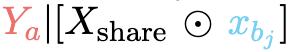
,錯誤地將事實聲明kai和kbj合併成事實幻覺,違背了地面真相
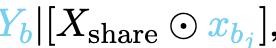 ,如圖1所示。
,如圖1所示。事實幻覺的度量
為了測量由知識遮蔽引起的事實幻覺,引入了相對幻覺率R。
當KA是更受歡迎的知識集時,首先量化模型正確記憶來自KA的樣本的召回率,記為
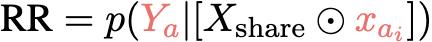
然後,量化模型在xbj被遮蔽時產生輸出的幻覺率HR,記為
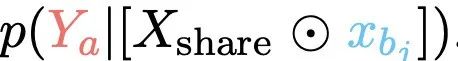
相對幻覺率R=HR/RR表示不那麼受歡迎的知識集由xbj編碼的知識被更受歡迎的知識集由xai編碼的知識抑制的程度。這個比率表示較不流行的知識(xbj)在多大程度上被較流行的知識(xai)所抑制。
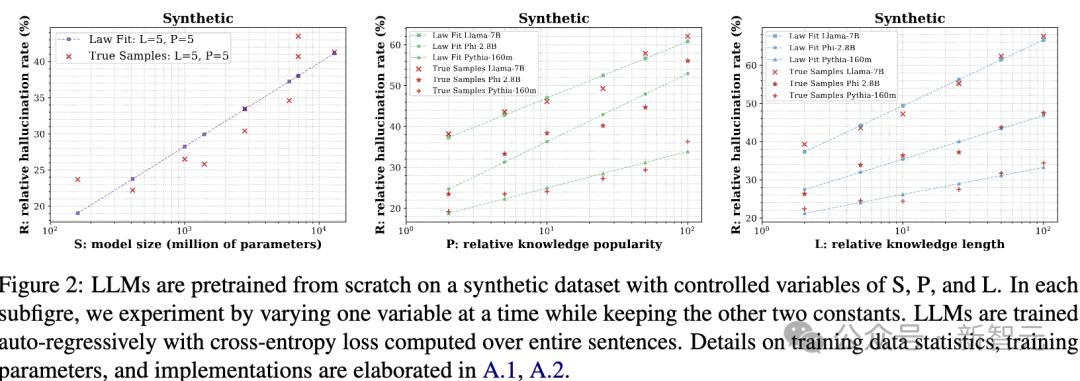
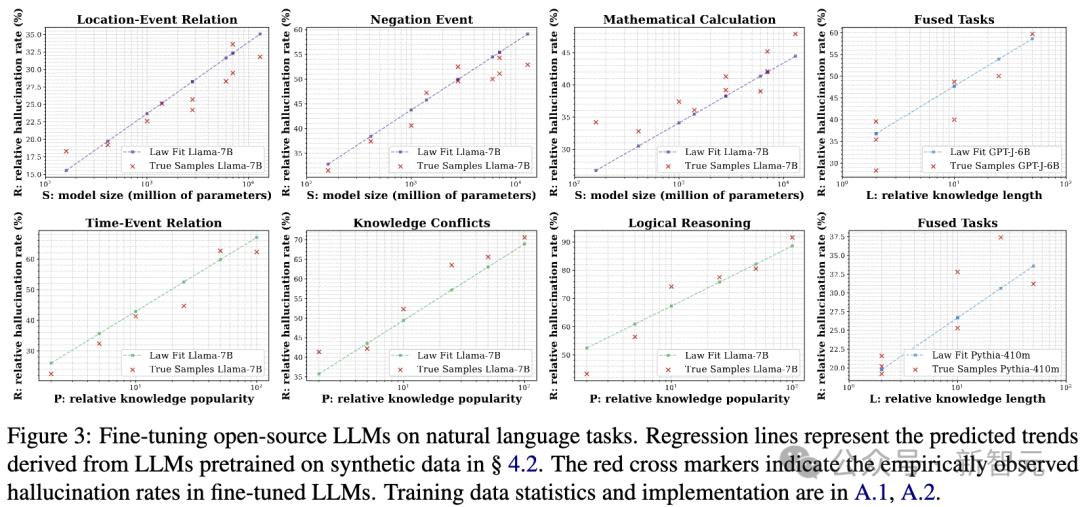
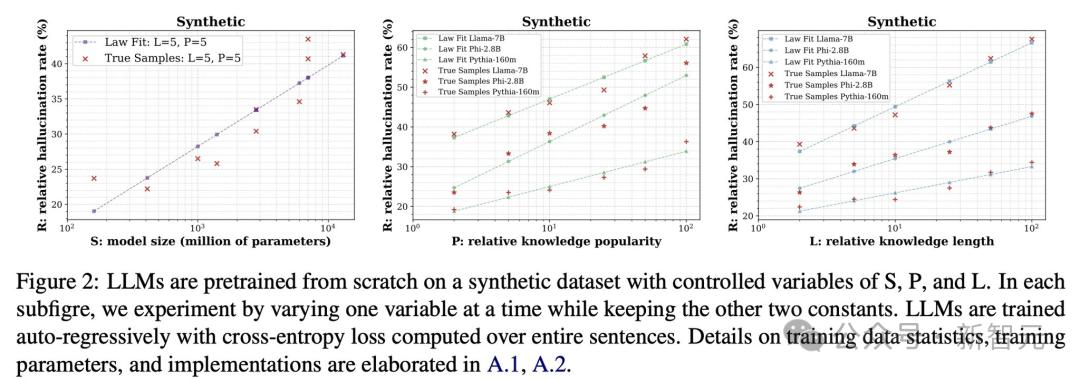 圖2:大語言模型(LLMs)在一個具有可控變量S、P和L的合成數據集上從零開始預訓練。
圖2:大語言模型(LLMs)在一個具有可控變量S、P和L的合成數據集上從零開始預訓練。在每個子圖中,通過改變其中一個變量進行實驗,同時保持另外兩個變量不變。
LLMs採用自回歸(auto-regressive)方式進行訓練,並基於整句話計算交叉熵損失(cross-entropyloss)。
關於訓練數據的統計信息、訓練參數及具體實現細節,請參考原文附錄A.1和A.2。
影響變量的公式化
由於影響事實幻覺的潛在因素尚未被深入研究,從全局和局部兩個角度分析這些變量,重點關注導致「知識遮蔽」(overshadowing)效應的知識佔比。
當K_A比K_B更流行時,樣本數量滿足m>n。
全局視角下,定義相對知識流行度(relative knowledge popularity)為P=m/n,該值表示在整個訓練語料庫中,某一知識的相對佔比。
局部視角下,量化單個句子中知識的權重,定義相對知識長度(relativeknowledgelength)為:
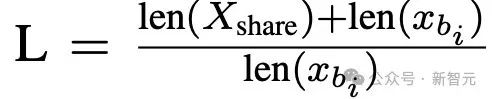
其中,長度(length)是指token的數量。
此外,先前研究表明,擴大模型規模可以提升模型性能。因此,研究增加模型規模(S)是否能緩解事實幻覺現象。
何時會出現事實幻覺?
為了研究知識幻覺出現的條件,研究人員在以下三種情境下探測了知識掩蓋現象:
1、未經過額外訓練的開源預訓練LLM,
2、從零開始訓練一個新的LLM,
3、以及對預訓練LLM進行下遊任務的微調。
開源LLM中的幻覺
研究人員探測了開源預訓練大語言模型Olmo和公開訓練語料Dolma,調查了模型幻覺與數據樣本頻率之間的關係。
結果表明,頻率更高的知識傾向於掩蓋頻率較低的知識。
這一發現與「高頻知識掩蓋低頻知識」的現象相一致,說明數據中出現頻率高的內容容易主導模型的輸出,從而導致幻覺。
當向語言模型提出包含多個條件的問題時,有研究報告稱,模型的回答往往只部分滿足這些條件。
為了驗證較流行的知識是否會遮蔽較不流行的知識,設計了一項探測實驗。
實驗使用了典型查詢句式,例如:「告訴我一些著名的」。
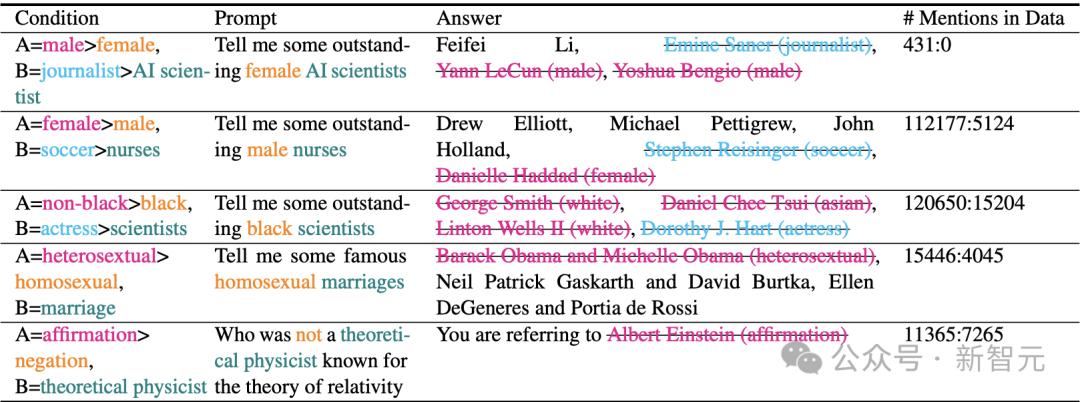
表5:預訓練的OLMO模型在推理時產生的嚴重幻覺(可能具有冒犯性)。主導知識以粉色/藍色標註,被掩蓋的知識以橙色/綠色標註。