拿20年前的蘋果「古董」筆記本跑模型推理:九分之一現代CPU速度,但成功了
眾所周知,大語言模型(LLM)往往對硬件要求很高。近日,軟件工程師 Andrew Rossignol 成功在一台「古董」老筆記本 PowerBook G4 上運行了生成式 AI。
據瞭解,這台筆記本已有 20 年歷史,僅配備 1.5 GHz PowerPC G4 處理器和 1 GB 內存,但仍然順利跑起了 Meta 的 Llama 2 大模型推理任務。此番實驗移植了開源 llama2.c 項目,而後使用名為 AltiVec 的 PowerPC 矢量擴展提升性能表現。
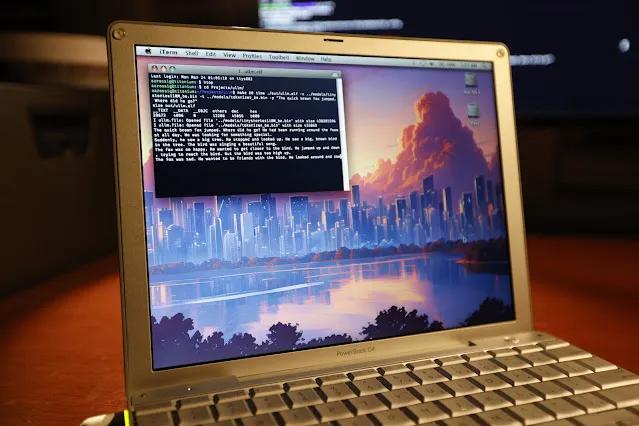
在 PowerBook G4 上運行 TinyStories 110M Llama 2 大模型推理任務。
Rossignol 在一篇博客里,完整介紹了關於此項目的所有過程和更多技術細節。以下是經不改變原意的翻譯和整理後的博客原文:
另闢蹊徑,慢慢思考:在 PowerPC Mac 上運行大模型
為舊硬件注入新生命永遠是件令人心曠神怡的好事,也是我本人的愛好之一。讓現代軟件在幾十年前設計的系統上運行起來,對我總有種難以抗拒的吸引力。而在近年深入研究大語言模型(LLM)的過程中,這種衝動也一直縈繞在我的腦海:能不能把 AI 的前沿技術引入自己那台代表舊日榮光的 2005 款 PowerBook G4 中?借助一塊 1.5 GHz 處理器、整整 1 GB 的內存和 32 位尋址空間,我開始了實驗並最終取得了成功。而通過在蘋果經典筆記本電腦上跑起大模型推理,我們證明即使是陳舊的硬件也完全可以牽手代表未來的 AI 新成果。
我首先選擇了 Andrej Karpathy 的 llama2.c 項目——這個出色的項目僅使用一個 C 文件就實現了 Llama 2 大模型推理。其中沒有使用到任何加速器,性能完全靠項目的簡單性實現,也讓我找到了實現推理的基本思路。
我將其核心實現分叉成了名叫 ullm 的新項目。核心算法保持不變,但我花了一些時間對代碼做出改進,增強了其穩健性。
代碼改進
我從最基礎的改進著手,陸續添加了系統函數的打包器,例如文件 I/O 和內存分配機制,借此降低程序檢測難度。
- 引入狀態返回,刪除所有 exit 調用。
- 抽像文件訪問以簡化狀態處理。
- 抽像 malloc/free 以進行簡單的調試 / 分析。
- 將 512 字節靜態 LUT 替換為單字符串。
- 修復了使用 -Wall 編譯時的一些警告提示。
從庫入手
我把代碼組織成庫以便於大規模修復,這套庫具有由標頭公開的公共 API,因此可以進行單元測試、確保進一步重構不致破壞其推理功能。

該庫需要兩條輸入:其一為 const config,負責提供模型路徑、rng seed 與 token 輸出回調等細節信息;其二則是 state,負責跟蹤加載權重、臨時緩衝區和 tokenizer 狀態等。
生成的 API 測試起來非常簡單,並可輕鬆為其構建命令行界面工具。
基於回調的輸出與測試
由於遷移至公共 API,因此我們可以輕鬆使用回調替換掉基於 printf 的輸出,這樣就能讓推理引擎持續生成 token。這也是後續實現端到端推理管道集成測試所必需的最後一條變更。
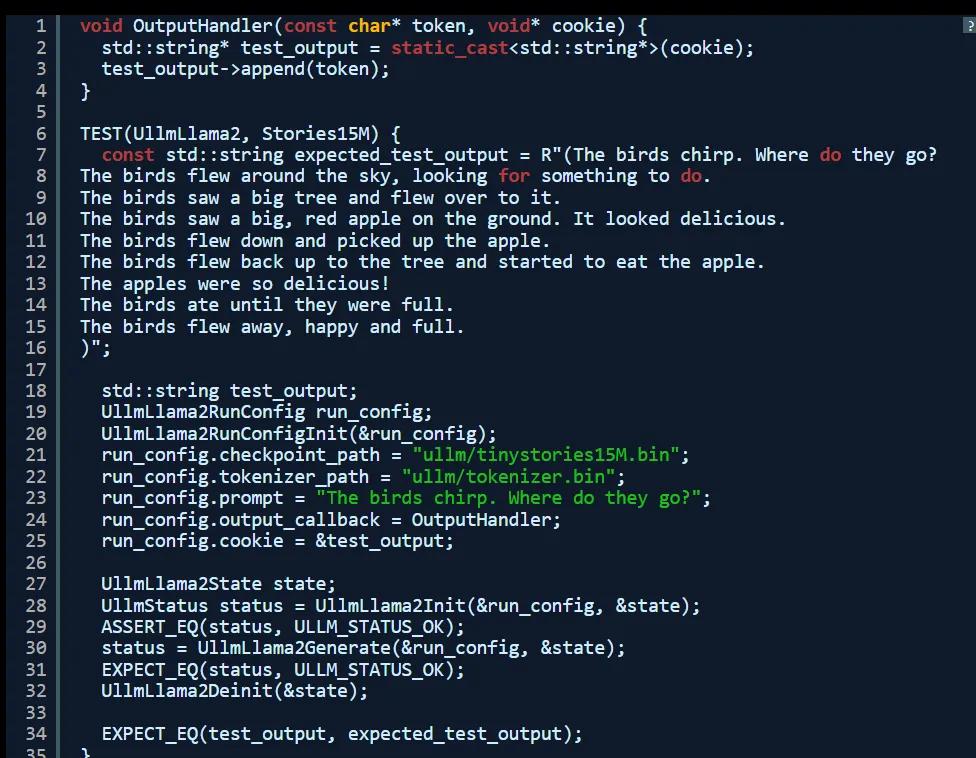
內部結構
除了公共 API 之外,我還重新組織了其內部結構。在改進之後,代碼變得相對優雅,同時刪除了所有 exit 調用,以便在初始化或推理過程中失敗時進行狀態傳播。
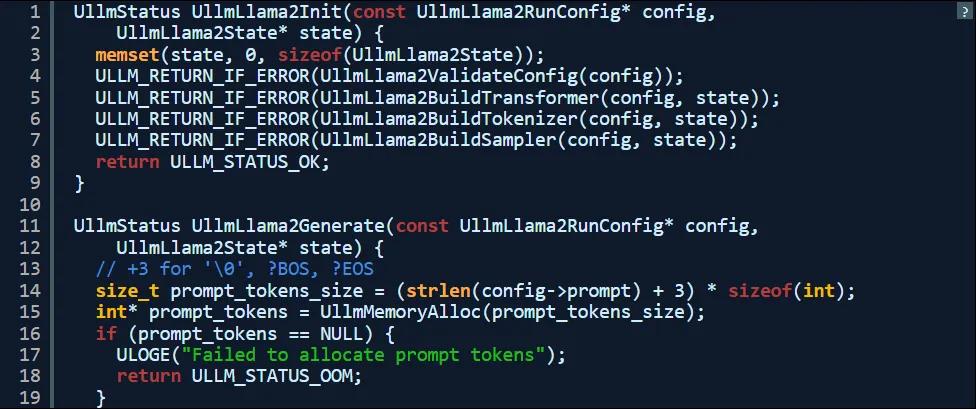
移植到 PPC
為了適應運行 gcc 4.x(大家沒看錯)工具鏈的 PowerPC Mac,我還做了額外的調整。最核心的問題就是 PowerPC 7447B CPU 為大端處理器,而如今發佈的模型檢查點和標記器則預設使用小端處理器。在首次測試時 malloc 達到 2 GB,明顯是出了問題。從種種跡象來看,模型明顯是在從文件中讀取小端值。
- 大小端:將模型檢查點 / 標記器從小端轉換為大端。
- 對齊,16 字節:將權重複製到內存中,而非進行內存映射。
- 性能:AltiVec。
在解決了錯誤並完成上述結構變更後,我使用 x86 Dell PowerEdge T440 主力機實現了輸出奇偶校驗。
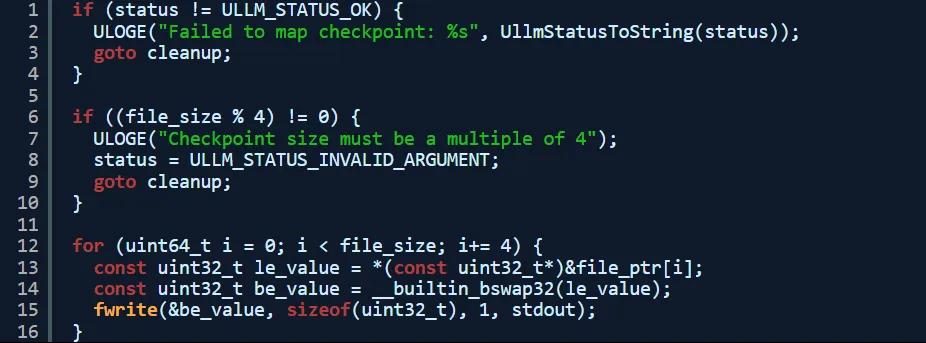
以下是我編寫的,用於切換模型檢查點的粗略代碼:
模型
Llama2.c 項目推薦使用 TinyStories 模型,而且理由非常充分。這些小模型無需任何專門的硬件加速,即可生成特定形式的輸出。
在實驗中,我使用 15M 模型變體進行了大部分測試,之後又切換到保真度最高的 110M 模型。這已經是上限了,更大的模型要麼 32 位尋址空間裝不下,要麼在現有硬件的 CPU 和可用內存帶寬上運行速度太慢。
好消息是,這些模型確實能創作出不少異想天開的兒童故事,讀起來那是相當有趣。而由於體量相對較小,它們也讓我在調試架構難題時感受相對輕鬆。
性能
為了在蘋果與戴亞硬件間直觀比較性能,我選擇啟用編譯器優化(-O2)的單線程推理選項。
在單一英特爾至強 Silver 4216 3.2 GHz 核心上運行推理時,其基準性能結果如下:
I ullm.llama2: Complete: 6.91 token/s
real 0m26.511s
user 0m26.019s
sys 0m0.472s
可以看到,戴亞的成績是總用時 26.5 秒,每秒平均生成 6.91 個 token(劇透:蘋果遠遠達不到這個水平)。其中 Inference seed 並非隨機,所以生成的輸出結果在每輪運行中均恒定不變,這就保證了多次運行下的性能間可以直接比較。
好了,使用相同的代碼在 1.5 GHz PowerPC 7447B 處理器上運行,PowerBook G4 到底取得了怎樣的成績?
I ullm.llama2: Complete: 0.77 token/s
real 4m0.099s
user 3m51.387s
sys 0m5.533s
雖然速度慢得多,但它仍然成功了!在與擁有更高內存帶寬的現代 CPU 相比,PowerPC 的速度大約是其九分之一。老實講,居然能跟 15 年後的年輕計算機保持在同一性能數量級內,這真的令人印象深刻。
下面我們來看看耗費時間最長的函數:matmul。控制結構的核心在於嵌套循環與乘法 / 求和。
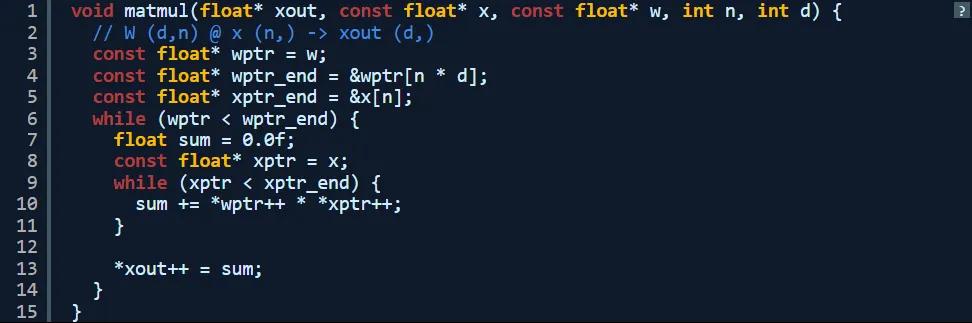
那還能不能做得更好?我記得 PowerPC 處理器支持所謂 AltiVec 矢量擴展,雖然早期版本的處理器擴展比較有限,但確實包含一項可以加快速度的關鍵運算:融合乘加。使用融合乘加運算,處理器能夠執行 4 倍的並行浮點乘法與加法,依靠 SIMD(單指令多數據)語義實現加速。
以下是使用 AltiVec SIMD 擴展重寫的同一函數。請注意,這是我第一次編寫 AltiVec 代碼。在修復了 16 字節對齊問題之後,此代碼能夠與原始 C 語言版本生成同樣的輸出。
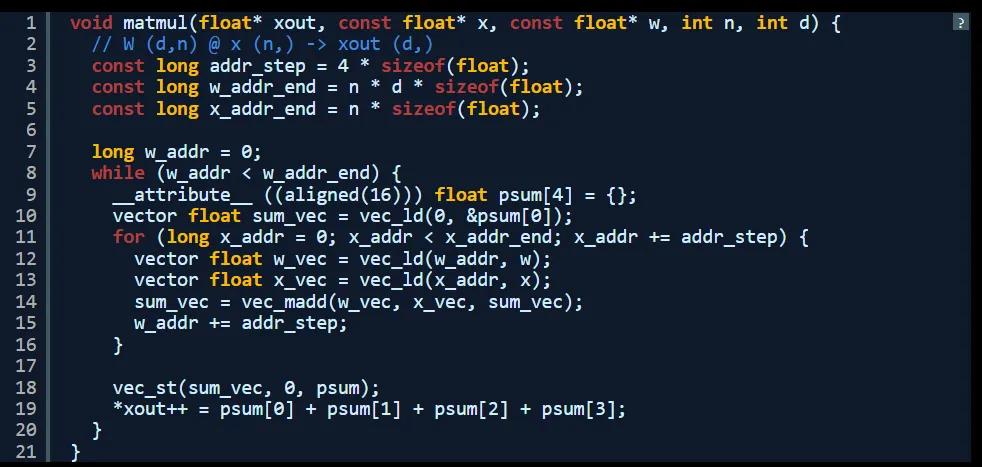
可以看到,這裡實際上有 4 個並行求和,之後我在核心乘法求和循環結束時進行了手動求和。
如今網絡上幾乎找不到多少關於這個古老擴展集的資料,好在 Gemini 給了我不少幫助。另外,官方提供的 PowerPC 文檔也還不錯,只是與舊版本的 ISA 並不完全匹配。
I ullm.llama2: Complete: 0.88 token/s
real 3m32.098s
user 3m23.535s
sys 0m5.368s
好極了!AltiVec 將推理過程縮短了約 30 秒,讓實現速度從戴亞的九分之一變成了八分之一,每秒生成的 token 數量則增加了 10%。爽!
後續探索
Llama2.c 項目還討論了如何使用相同代碼運行具備數十億參數的模型。雖然頗具吸引力,但遺憾的是 G4 PowerPC 系統是 32 位的,因此最大可尋址內存只有區區 4 GB,運行模型體量的上限也就是這個 110M TinyStories 了。量化技術雖然有肥皂劇幫助,但模型檢查點仍然高達 7 GB(不量化則約為 26 GB),還是塞不進可用地址空間。
所以我認為這個項目可以到此結束了。在此過程中,我熟悉了大模型的性質及其操作方式,也深切意識到矩陣乘法正是製約每秒輸出 token 數量的最大瓶頸。
所以還是讓我的老爺機做它該做的吧:一邊聽歌一邊碼字,今天確實辛苦它了。
參考鏈接:
https://www.macrumors.com/2025/03/24/powerbook-g4-generative-ai/
http://www.theresistornetwork.com/2025/03/thinking-different-thinking-slowly-llms.html
本文來自微信公眾號「AI前線」,整理:華衛、核子可樂 ,36氪經授權發佈。