UI-R1|僅136張截圖,vivo開源DeepSeek R1式強化學習,提升GUI智能體動作預測

基於規則的強化學習(RL/RFT)已成為替代 SFT 的高效方案,僅需少量樣本即可提升模型在特定任務中的表現。
該方法通過預定義獎勵函數規避人工標註成本,如 DeepSeek-R1 在數學求解中的成功應用,以及多模態領域在圖像定位等任務上的性能突破(通常使用 IOU 作為規則 reward)。
vivo 與香港中文大學的研究團隊受到 DeepSeek-R1 的啟發,首次將基於規則的強化學習(RL)應用到了 GUI 智能體領域。

-
論文標題:UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning
-
論文地址:https://arxiv.org/abs/2503.21620
-
項目主頁:https://yxchai.com/UI-R1/
-
項目代碼:https://github.com/lll6gg/UI-R1
簡介
本研究創新性地將規則 RL 範式拓展至基於低級指令的 GUI 動作預測任務。具體實現中,多模態大語言模型為每個輸入生成包含推理標記和最終答案的多條響應軌跡,在訓練和測試時的 prompt 設計如下:

隨後通過我們設計的獎勵函數評估每條響應,並採用 GRPO 等策略優化算法更新模型參數。該獎勵函數包含三個維度:
-
動作類型獎勵:根據預測動作與真實動作的匹配度計算;
-
動作參數獎勵(聚焦點擊操作):通過預測坐標是否落入真實邊界框評估;
-
格式規範獎勵:評估模型是否同時提供推理過程和最終答案。
數據製備方面,僅依據難度、多樣性和質量三原則篩選 130 餘個移動端訓練樣本,展現出卓越的數據效率。實驗表明,UI-R1 在桌面端和網頁平台等跨領域(OOD)數據上均取得顯著性能提升,印證了規則 RL 處理跨領域複雜 GUI 任務的潛力。
方法:強化學習驅動的 GUI 智能體
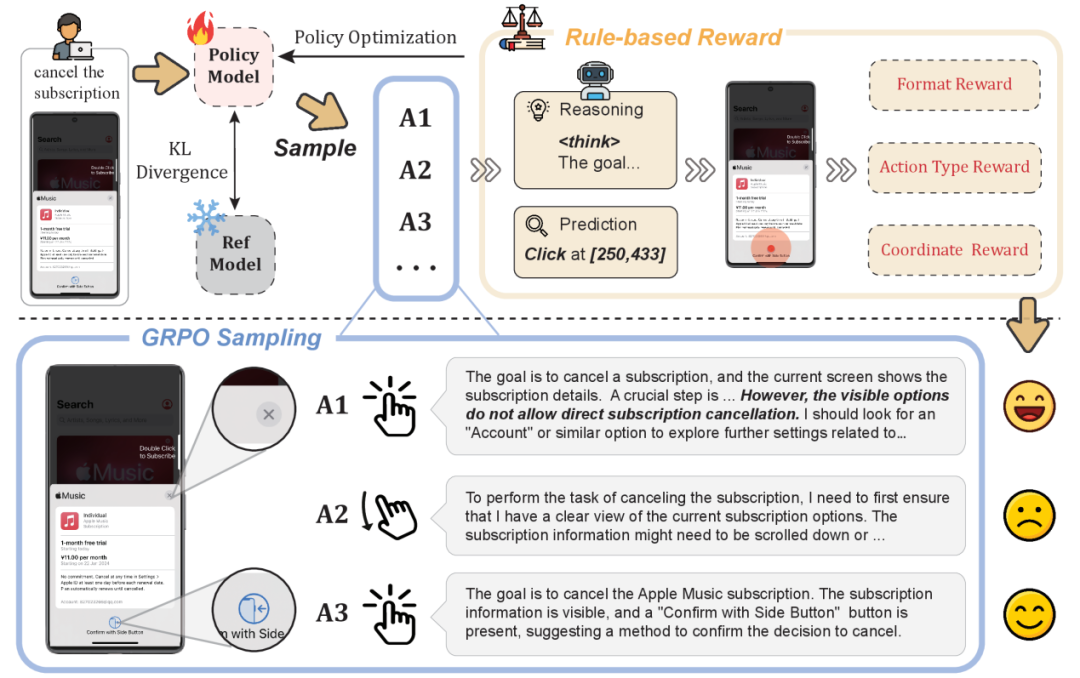
我們提出的 UI-R1 模型採用了三個關鍵創新:
1. 獨特的獎勵函數設計
研究團隊設計了專門針對 GUI 任務的獎勵函數:R = R_T + R_C + R_F
R_T:行為類型獎勵(點擊、滑動、返回等)
R_C:坐標準確度獎勵(點擊位置是否準確)
R_F:格式獎勵(輸出的格式是否正確)
2. 精心篩選的高質量數據
與其使用大量普通數據,我們提出採用了「質量優先」的策略,從三個維度精選訓練數據:
質量:選擇標註準確、對齊良好的樣本
難度:專注於基礎模型難以解決的「困難」樣本
多樣性:確保涵蓋各種行為類型和元素類型
最終只使用了 136 個高質量樣本,比傳統方法少了幾百甚至上千倍,就能夠訓練得到比 SFT 方式更優的效果。
3. 群體相對策略優化算法
UI-R1 採用了一種名為 GRPO(Group Relative Policy Optimization)的算法。這種算法不需要額外的評論家模型,而是通過比較同一問題的多個不同回答來學習什麼是「好」的回答。
實驗結果
1. 域內效果提升明顯
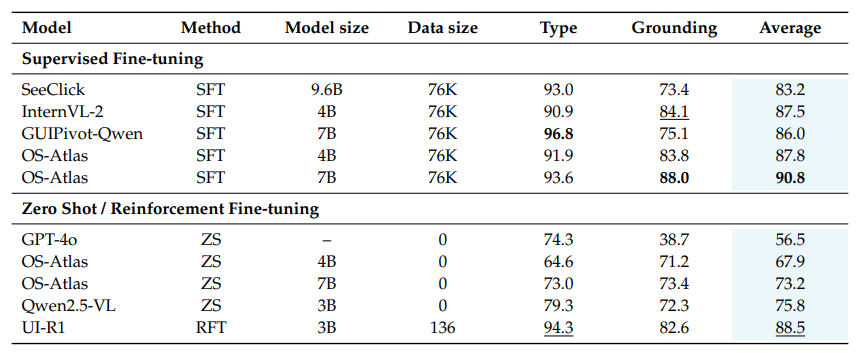
在 AndroidControl 基準測試上,UI-R1-3B 與基礎模型 Qwen2.5-VL-3B 相比:
-
行為類型準確率提高了 15%
-
定位準確率提高了 10.3%
2. 域外泛化能力驚人
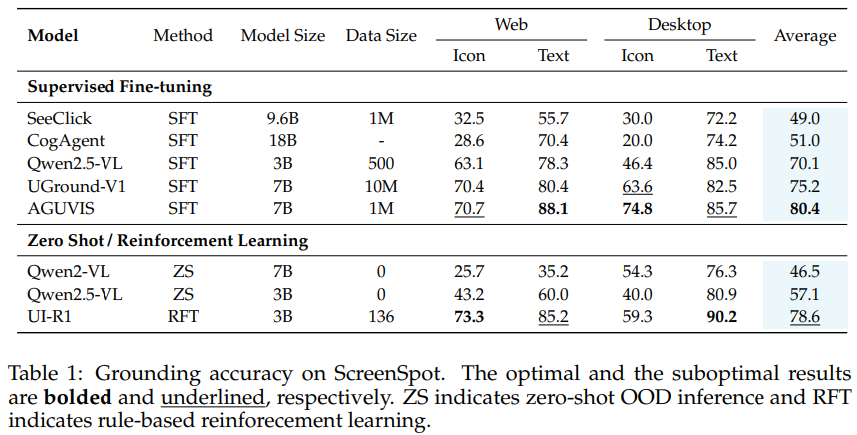
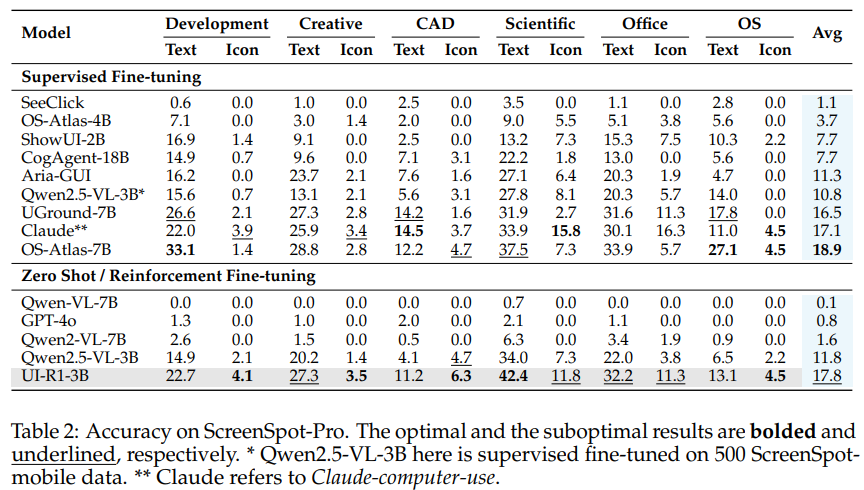
UI-R1 在從未見過的桌面 PC 端和網頁界面上表現同樣出色:
-
在 ScreenSpot 測試中,UI-R1-3B 的平均準確率達到 78.6%,超越 CogAgent-18B 等大模型。
-
在專業高解像度環境 ScreenSpot-Pro 測試中,UI-R1-3B 達到 17.8% 的平均準確率,提升了與使用 76K 數據訓練的 OS-Atlas-7B(18.9%)性能相當。
分析
我們關於 UI-R1 做了一系列分析,研究發現:在 GRPO 的強化學習微調的方式下,數據質量比數據數量重要:
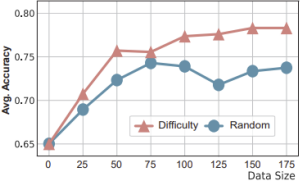
-
困難樣本更有價值:按難度選擇的方法比隨機選擇的性能顯著更好。
-
數據增長收益遞減:隨著訓練數據量增加,性能提升趨於平緩。
-
精選小數據集比大數據集更有效:三階段數據選擇方法優於使用整個數據集或者隨機篩選相同數量的子集。
此外,我們還發現動作預測的難度與思考的長度之間存在關聯:思考長度越長,準確率越低(說明問題越難),但通過 UI-R1 形式的強化學習微調之後,對於難樣本的成功率提升也更加明顯。
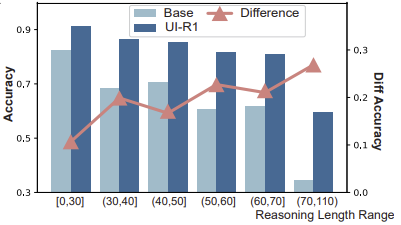
這一現象證明了強化微調的價值,通過讓模型自主思考來提升難樣本的準確率,這個特性是之前的監督微調所難以獲得的。
未來探索方向
UI-R1 初步探索了大模型強化學習和推理技術在 GUI Agent 領域的應用。下一步,我們將嘗試將 UI-R1 從 RFT 拓展到 SFT + RFT 的組合,實現大規模 UI 數據下統一的思考、決策、規劃的 GUI Agent 大模型。