類R1強化學習遷移到視覺定位!全開源Vision-R1將圖文大模型性能提升50%

圖文大模型通常採用「預訓練 + 監督微調」的兩階段範式進行訓練,以強化其指令跟隨能力。受語言領域的啟發,多模態偏好優化技術憑藉其在數據效率和性能增益方面的優勢,被廣泛用於對齊人類偏好。目前,該技術主要依賴高質量的偏好數據標註和精準的獎勵模型訓練來提升模型表現。然而,這一方法不僅資源消耗巨大,訓練過程仍然極具挑戰。
受到基於規則的強化學習(Rule-Based Reinforcement Learning)在 R1 上成功應用的啟發,中科院自動化研究所與中科紫東太初團隊探索了如何結合高質量指令對齊數據與類 R1 的強化學習方法,進一步增強圖文大模型的視覺定位能力。該方法首次在 Object Detection、Visual Grounding 等複雜視覺任務上,使 Qwen2.5-VL 模型實現了最高 50% 的性能提升,超越了參數規模超過 10 倍的 SOTA 模型。
目前,相關工作論文、模型及數據集代碼均已開源。

-
論文標題:Vision-R1: Evolving Human-Free Alignment in Large Vision-Language Models via Vision-Guided Reinforcement Learning
-
論文地址:https://arxiv.org/pdf/2503.18013
-
Github 倉庫:https://github.com/jefferyZhan/Griffon/tree/master/Vision-R1
-
Huggingface 倉庫:https://huggingface.co/collections/JefferyZhan/vision-r1-67e166f8b6a9ec3f6a664262
引言
目標定位任務要求模型能夠精準識別用戶輸入的任意感興趣目標,並給出精確的目標框,對圖文大模型的細粒度感知和空間理解能力提出了嚴峻挑戰。當前,圖文大模型通常將目標定位建模為文本序列預測任務,並通過大規模預訓練和指令數據的監督微調,以 Next Token Prediction 實現對不同粒度目標描述的精準定位。儘管在指代表達理解等任務上已超越傳統視覺專家模型,但在更複雜、目標密集的場景中,其視覺定位與目標檢測能力仍與專家模型存在顯著差距。
R1 的成功應用推動了對基於規則的任務級別獎勵監督的探索,使模型擺脫了對人工偏好數據標註和獎勵模型訓練的依賴。值得注意的是,視覺定位指令數據本身具有精準的空間位置標註,並與與人類對精準目標定位偏好高度一致。基於這些優勢,Vision-R1 通過設計類 R1 的強化學習後訓練框架,在任務級別監督中引入基於視覺任務評價指標的反饋獎勵信號,為增強圖文大模型的細粒度視覺定位能力提供了創新突破方向。
 Vision-R1 關鍵設計示意圖
Vision-R1 關鍵設計示意圖Vision Criteria-Driven Reward Function
聚焦圖文大模型目標定位問題
在文本序列的統一建模和大規模數據的自回歸訓練下,圖文大模型在目標定位任務上取得了顯著的性能提升。然而,其進一步發展仍受到三大關鍵問題的限制:(1)密集場景中的長序列預測易出現格式錯誤,(2)有效預測目標的召回率較低,(3)目標定位精度不足。
這些問題製約了模型在更複雜視覺任務上的表現。在自回歸 Token 級別的監督機制下,模型無法獲得實例級別的反饋,而直接在單目標場景下應用 GRPO 訓練方法又忽視了視覺定位任務的特性及 Completion 級別監督的優勢。
為此,研究團隊結合圖文大模型在視覺定位任務中面臨的挑戰,提出了一種基於視覺任務評價準則驅動的獎勵函數,其設計包括以下四個核心部分:
-
框優先的預測匹配:與僅針對單個目標進行設計的方法不同,Vision-R1 採用多目標預測的統一建模方式。為了計算包含多個目標預測的獎勵,Vision-R1 首先對文本序列化的預測結果進行反序列化,提取出每個目標的預測框及其標籤,並將預測結果與真實標註進行匹配,以確保獎勵機制能夠全面衡量多目標場景下的定位質量。
-
雙重格式獎勵:該獎勵項旨在解決密集場景下長序列預測的格式錯誤問題。對於每個預測文本序列,模型需滿足指定的模板格式(如 Qwen2.5-VL 採用的 JSON 格式),並確保目標坐標的數值正確性。僅當預測結果同時滿足格式和內容要求時,模型才能獲得獎勵 1,從而引導其生成符合標準的預測輸出。
-
召回獎勵:該獎勵項針對有效預測目標召回率低的問題,鼓勵模型儘可能多地識別目標。具體而言,針對每個預測目標及其匹配的真實目標(GT),當兩者的 IoU 超過預設閾值 ζ 時,視為該預測有效。對於一個預測序列,其召回獎勵定義為有效預測目標數量與實際需要預測目標數量的比例,以此激勵模型提高目標的覆蓋率。
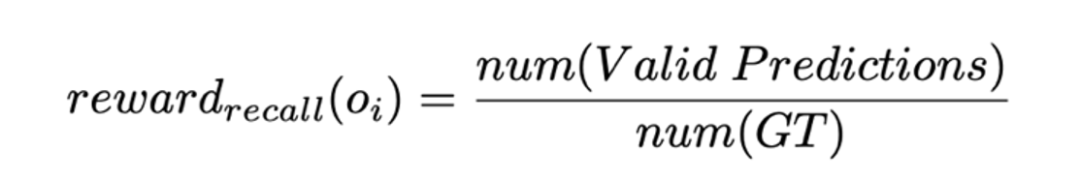
-
精度獎勵:精度獎勵與召回獎勵協同作用,形成「1+1>2」的優化效果。其中,召回獎勵提升模型對目標的全面識別能力,而精度獎勵則確保預測的準確性。精度獎勵從單實例角度衡量預測質量,其核心目標是鼓勵模型生成高質量的邊界框。具體地,精度獎勵被定義為所有有效預測的平均 IoU 值,以直接激勵模型優化目標框的精確度:
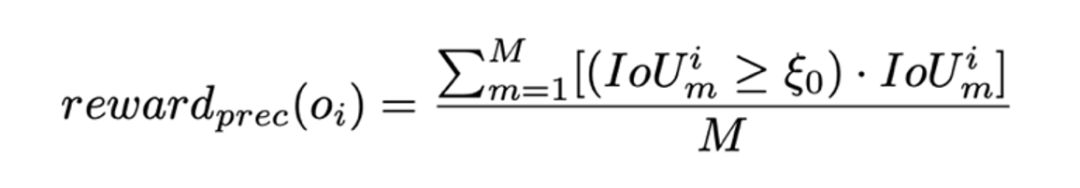
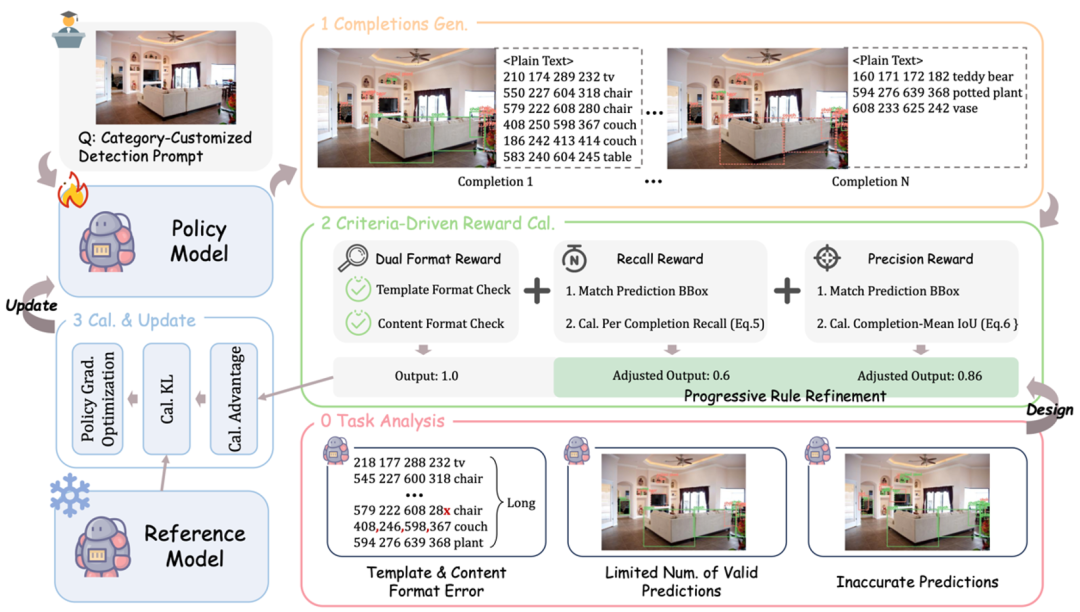 Vision-R1 整體框架
Vision-R1 整體框架Progressive Rule Refinement Strategy
實現持續性能提升
在目標定位任務中,預測高質量(高 IoU)的目標框始終是一個挑戰,尤其是在密集場景和小目標情況下。這種困難可能導致模型在同組預測中獎勵差異較小,從而影響優化效果。針對這一問題,研究團隊提出了漸進式規則調整策略,該策略通過在訓練過程中動態調整獎勵計算規則,旨在實現模型的持續性能提升。該策略主要包括兩個核心部分:
差異化策略:該策略的目標是擴大預測結果與實際獎勵之間的映射差異。具體而言,通過懲罰低召回率(Recall)和低平均 IoU 的預測,並對高召回率和高 IoU 的預測給予較高獎勵,從而鼓勵模型生成更高質量的預測,尤其是在當前能夠達到的最佳預測上獲得最大獎勵。這一策略引導模型在訓練過程中逐漸提高預測精度,同時避免低質量預測的獎勵過高,促進其優化。具體實現如下:
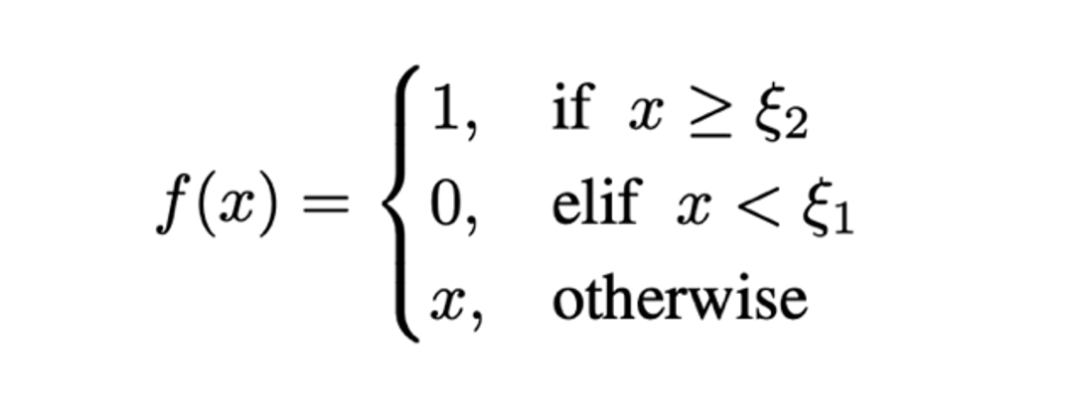
階段漸近策略:類似於許多有效的學習方法,給初學者設定容易實現的目標並逐步提升獎勵難度是一個常見且行之有效的策略。在 Vision-R1 中,訓練過程被劃分為初學階段和進階階段,並通過逐步調整閾值 ζ 來實現獎勵規則的逐漸變化。具體來說:
-
初學階段(Beginner Phase): 在這一階段,設置較低的 ζ 閾值(0.5/0.75),給予模型相對寬鬆的獎勵標準,幫助其快速入門並學習基礎的定位能力。
-
進階階段(Advanced Phase): 隨著訓練的深入,逐步提高 ζ 閾值,增加標準要求,以促使模型達到更高的準確度,避免模型依賴簡單策略,從而持續推動模型性能的提升。
不同模型的域內外目標檢測評測
為全面評估 Vision-R1 的效果,研究團隊選擇了近期定位能力大幅提升的 Qwen2.5-VL-7B 模型和定位能力突出的 Griffon-G-7B 模型,在更有挑戰的經典目標檢測數據集 COCO 和多樣場景的 ODINW-13 上進行測試,以展現方法對不同定位水平模型的適用性。
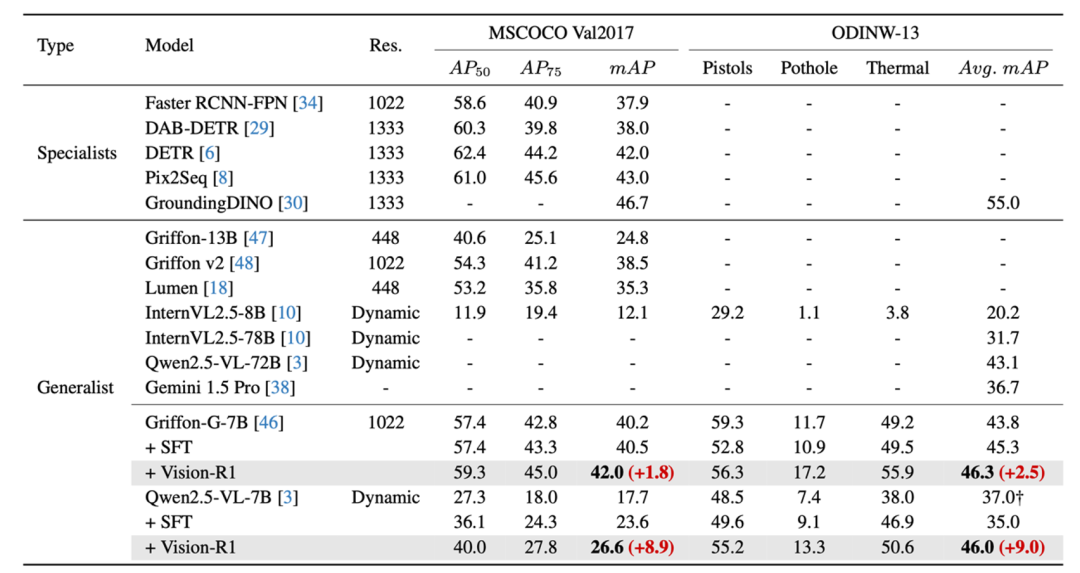 經典 COCO/ODINW 數據集上 Vision-R1 方法相較於基線模型性能的提升
經典 COCO/ODINW 數據集上 Vision-R1 方法相較於基線模型性能的提升實驗結果表明,無論基礎性能如何,與基線模型相比這些模型在 Vision-R1 訓練後性能大幅提升,甚至超過同系列 SOTA 模型,進一步接近了定位專家模型。
研究團隊還在模型沒有訓練的域外定位數據集上進行測試,Vision-R1 在不同模型的四個數據集上取得了平均 6% 的性能提升,充分論證了方法的泛化性。
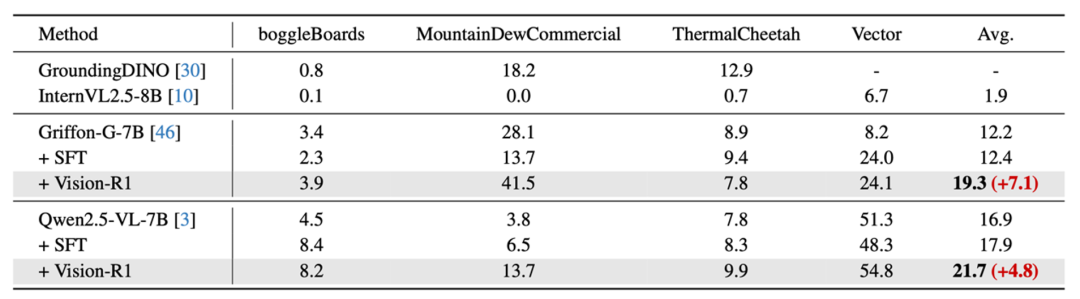 域外數據集上 Vision-R1 方法相較於基線模型性能的提升
域外數據集上 Vision-R1 方法相較於基線模型性能的提升模型通用問答能力評測
研究團隊進一步評估了模型在非定位等通用任務上的性能,以驗證方法是否能在少量影響模型通用能力的情況下,大幅度提升模型的視覺定位能力。研究團隊發現,Vision-R1 近乎不損失模型的通用能力,在通用問答、圖表問答等評測集上模型實現了與基準模型基本一致的性能。
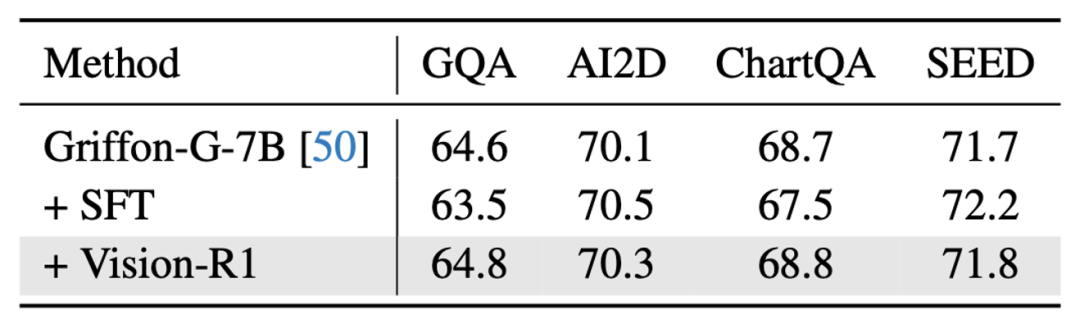 通用問答數據集上 Vision-R1 方法與基線模型性能的比較
通用問答數據集上 Vision-R1 方法與基線模型性能的比較可視化分析
研究團隊提供了在 Qwen2.5-VL-7B 模型上使用 Vision-R1 後在多個場景下的目標檢測可視化結果。如結果所示,Vision-R1 訓練後,模型能夠更好召回所感興趣的物體,並進一步提升定位的精度。
 Vision-R1 訓練模型與基準模型檢測結果可視化
Vision-R1 訓練模型與基準模型檢測結果可視化