AI危險檢測再進化!三層級解析長影片異常,各種時序粒度均有明顯優勢 | CVPR HighLight
HolmesVAU團隊 投稿
量子位 | 公眾號 QbitAI
多模態影片異常理解任務,又有新突破!
「異常理解」是指在影片監控、自動駕駛等場景中,利用模型發現影片中的異常內容,從而預判危險,以便及時做出決策。
來自華中科大等機構的研究人員,提出了新的影片異常理解模型Holmes-VAU,以及相關數據集。
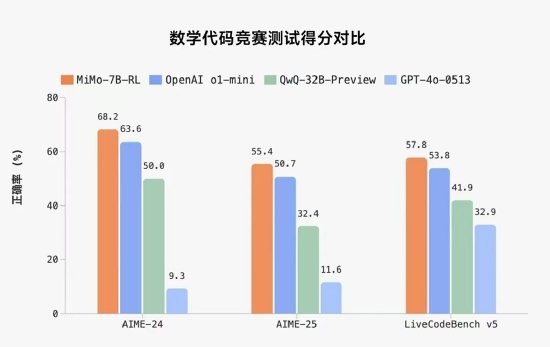
與通用多模態大模型對比,Holmes-VAU在各種時序粒度的影片異常理解上都展現出顯著優勢。

為了實現開放世界的多模態影片異常理解(VAU),已有的VAU benchmark只有短影片的caption標註或長影片的instruction標註,忽略了影片異常事件的時序複雜性。
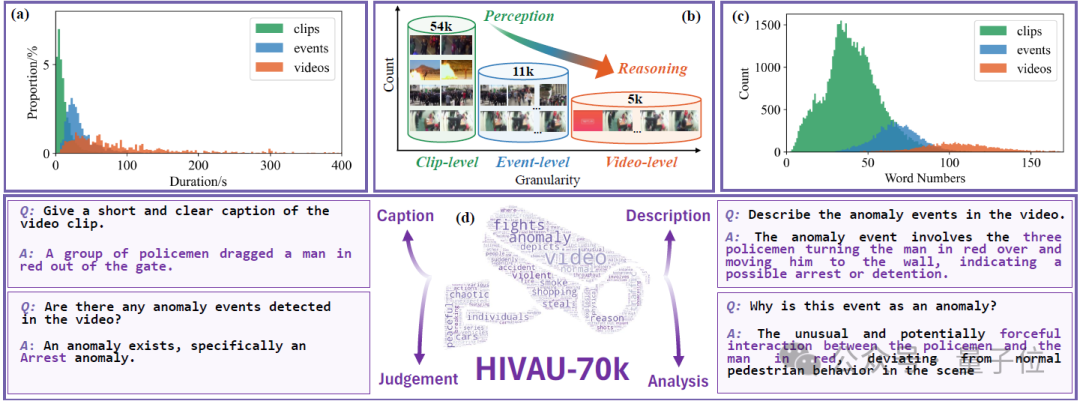
為同時促進模型對短影片的感知能力和對長影片的推理能力,作者提出了一種高效半自動數據引擎並構建了HIVAU-70k數據集,包含超7萬影片異常理解任務的多時序尺度指令數據。
同時作者提出了一種基於異常分數的時序采樣器,從長影片中動態稀疏采樣關鍵幀到後續多模態大模型中,顯著提升了異常分析的準確性和推理效率。
多層級影片異常理解指令數據集
針對影片異常理解任務(Video Anomaly Understanding),以往的一些異常影片指令數據集主要有兩方面問題:
-
數據集中的影片時長較短,導致模型缺乏對長影片的異常理解能力;
-
即便包含長影片,也缺乏對長影片的細粒度和結構化的標註,導致模型的異常理解空間難以對齊。
為此,作者提出了一個大型多模態指令數據集HIVAU-70k,其中包含多種時間粒度的影片異常標註,由粗到細分別為:
-
video-level:未裁剪長影片,包括影片中所有異常事件的文本描述分析;
-
event-level:從長影片中裁剪出的異常事件片段,包括單個異常事件的文本描述分析;
-
clip-level:從event中進一步裁剪出的影片片段,包括影片片段的文本描述。
HIVAU-70k中的指令數據包括影片描述、異常判斷、異常描述和異常分析等任務,為影片異常理解多模態大模型提供了豐富多樣的數據來源。
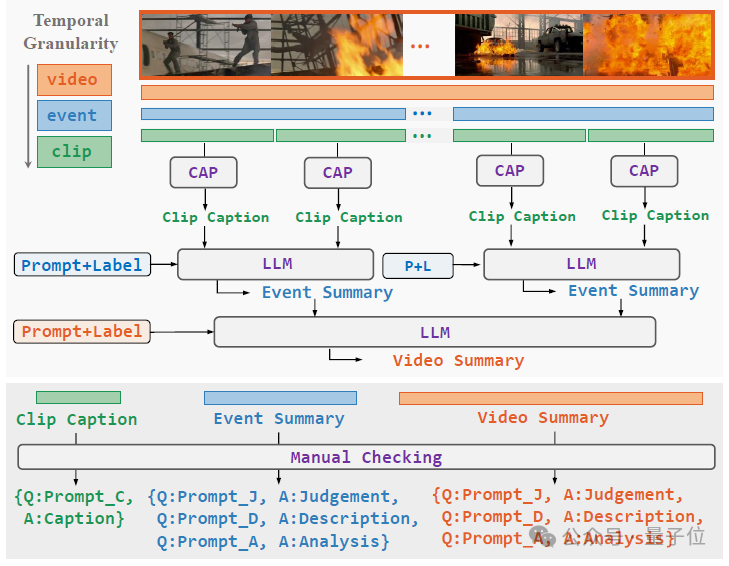
這樣的多層級指令數據集是怎麼構造的呢?從一個未裁剪的長影片開始,需要依次經過以下三個步驟:
-
分層影片解耦(Hierarchical Video Decoupling):將video-level影片中的異常事件標註並裁剪出來,得到event-level影片, 再對event-level影片進一步平均切分得到clip-level影片;
-
分層自由文本註釋(Hierarchical Free-text Annotation):對於clip-level影片,使用人工或caption model得到clip caption;對於event-level影片,結合所包含的clip-level caption和異常類別,提示LLM得到事件總結;對於video-level影片,結合所包含的事件總結和異常類別,提示LLM得到影片總結;
-
層次化指令數據構建(Hierarchical Instruction Data Construction):針對不同層級的影片及其文本標註,設計不同的任務,構造任務相關的問題並與文本註釋組合,得到最終的指令數據。
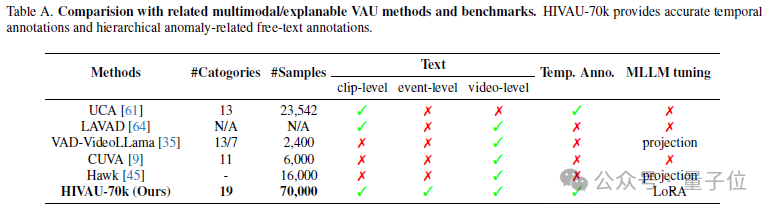
與其他相關的數據集相比,HIVAU-70k不僅有數量上的優勢,還提供了多粒度的文本標註以及時序上的異常邊界標註。
動態稀疏采樣的影片異常理解模型
長影片異常理解在使用大型語言模型(LLMs)或視覺語言模型(VLMs)時,常因幀冗餘問題而受到限制,導致異常檢測的準確性變得複雜。
以往的VAU(影片異常理解)方法難以聚焦異常。
例如,密集窗口采樣方法會增加大量冗餘幀的計算量,而均勻幀采樣方法常常錯過關鍵異常幀,使其應用範圍局限於短影片。
為此,作者提出了Anomaly-focused Temporal Sampler (ATS),並將其集成到VLM中,通過在HIVAU-70k上的指令微調,構建了Holmes-VAU模型。
異常幀通常比正常幀包含更多信息,並表現出更大的變化,基於這一觀察,作者設計了一種采樣策略,在異常分數較高的區域采樣更多幀,同時在分數較低的區域減少采樣。
為實現非均勻采樣,作者提出了一種「密度感知采樣器」(density-aware sampler),用於從總共T個輸入幀中選擇N個幀。
具體來說,作者將異常分數S視為概率質量函數,並首先沿時間維度累積它們,得到累積分佈函數(CDF),記為 S_cumsum:
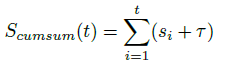
接著,在累積軸上均勻采樣N個點,並將這些點映射到累積分佈S_cumsum上。相應的時間軸上的N個時間戳會被映射到最接近的幀索引,最終形成采樣的幀索引集合G。
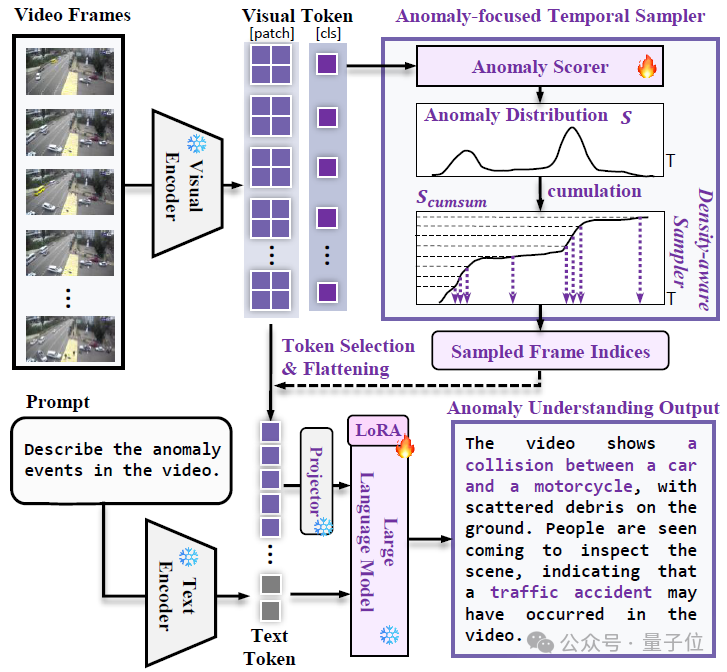 △Holmes-VAU模型框架圖
△Holmes-VAU模型框架圖下入展示了測試集上的異常分數和采樣幀的可視化結果。這些結果表明了ATS的準確異常檢測能力,最終輸入到多模態大模型的采樣幀也集中於異常區域。
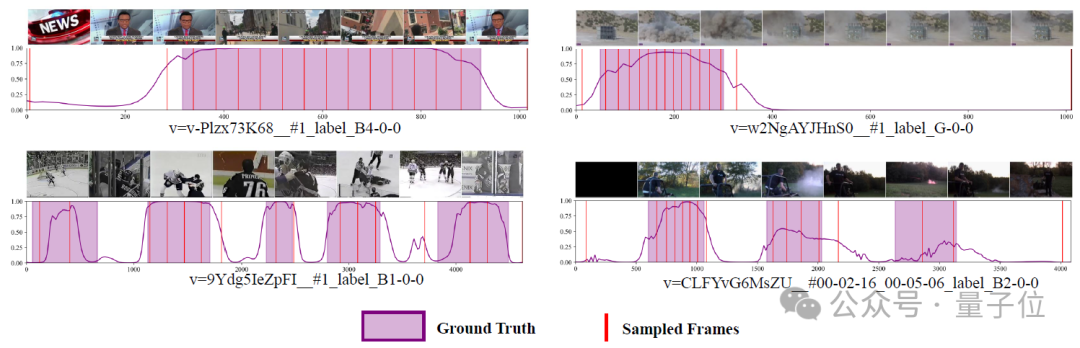 △Anomly-focused Temporal Sampler (ATS) 異常分數及采樣幀示意圖
△Anomly-focused Temporal Sampler (ATS) 異常分數及采樣幀示意圖實驗結果
異常推理性能評估
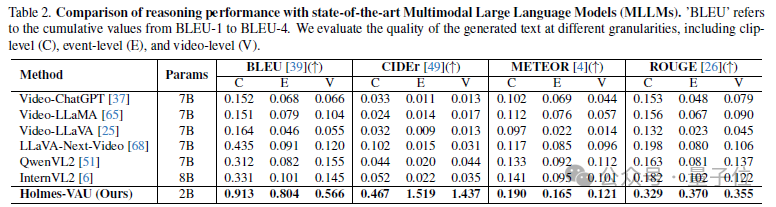
作者在HIVAU-70k的測試集上,將模型輸出的推理文本與註釋的真實文本進行比較,計算了包括BLEU、CIDEr、METEOR和ROUGE等指標來衡量模型輸出的異常理解文本質量。
與通用多模態大模型對比,Holmes-VAU在各種時序粒度的影片異常理解上都展現出顯著優勢。
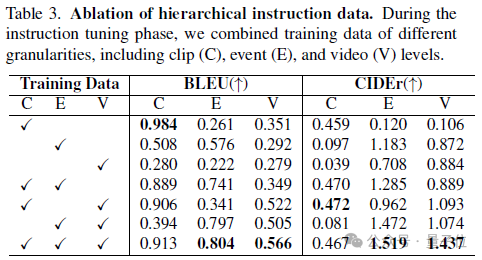
在多層級標註中,對不同層級指令數據集的組合,可以觀察發現,單一層級的標註只能提升單一層級任務的性能。
不同層級的標註組合可以相互補充,實現從clip-level的基礎視覺感知, 到event-level單一異常事件的分析,再到video-level的長時序異常總結和推理等方面的全面提升,達到更細粒度和完整的多模態異常空間對齊。
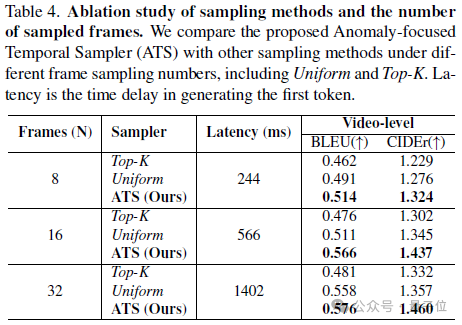
對於非均勻采樣器的作用,作者也對比了不同幀采樣方式,包括本文提出的ATS、之前方法用的Top-K采樣和Uniform采樣。
結果表明在相同的采樣幀數下,ATS展現出更優越的長影片異常理解能力,這是由於Top-K采樣過於集中在異常幀,忽略了影片上下文的參考,Uniform采樣則容易忽略關鍵的異常幀。
而作者提出的ATS則有效結合了這兩者的優勢,關注異常幀的同時,能夠保留部分上下文幀的采樣。
定性比較
下圖對比了Holmes-VAU和其他MLLM輸出的異常分析文本,Holmes-VAU表現出更準確的異常判斷和分析能力,同時對長影片也表現出更完整的異常總結能力。
 △Holmes-VAU和其他MLLM的異常分析文本質量對比
△Holmes-VAU和其他MLLM的異常分析文本質量對比論文:
https://arxiv.org/abs/2412.06171
代碼:
https://github.com/pipixin321/HolmesVAU
一鍵三連「點讚」「轉發」「小心心」
歡迎在評論區留下你的想法!