三個LLM頂一個OpenAI?2億條性能記錄加持,路由n個「小」模型逆襲

新智元報導
編輯:LRST 好睏
【新智元導讀】路由LLM是指一種通過router動態分配請求到若干候選LLM的機制。論文提出且開源了針對router設計的全面RouterEval基準,通過整合8500+個LLM在12個主流Benchmark上的2億條性能記錄。將大模型路由問題轉化為標準的分類任務,使研究者可在單卡甚至筆記本電腦上開展前沿研究。這一突破不僅為學術界提供了低門檻的研究工具,更為大模型性能優化提供了新的思路:通過智能調度實現異構模型的協同增效,以極低的計算成本突破單一模型的性能上限。
當前大模型研究面臨三大困境:算力壟斷(頂尖成果集中於大廠)、成本壁壘(單次訓練成本高,可能需要數千GPU小時)以及技術路徑單一化(過度依賴單一模型的規模擴展)。
為突破這些限制,路由LLM(Routing LLM)範式應運而生——通過智能調度實現多個開源小模型的協同增效,以「組合創新」替代「規模競賽」。
 代碼:
代碼:https://github.com/MilkThink-Lab/RouterEval
論文: https://arxiv.org/abs/2503.10657
論文合集:https://github.com/MilkThink-Lab/Awesome-Routing-LLMs
路由LLM實際上是model level的MoE(Mixture-of-Experts),傳統MoE通過在模型內部擴展專家網絡(如稀疏激活的FFN層)提升性能,而路由LLM將完整LLM視為獨立「專家」,通過預訓練Router動態分配任務輸入。
 三個大模型=OpenAI
三個大模型=OpenAI這種範式具有三重優勢:
異構兼容性:支持閉源模型(如GPT-4)、開源模型(如Llama系列)及專用微調模型的混合部署。
多目標優化:可根據場景需求,在性能、成本、風險控制等維度實現動態權衡
靈活部署:可根據實際需求動態調整候選模型池,針對特定場景(如代碼生成、醫療問答)快速定製專屬解決方案,而無需從頭訓練大模型
路由LLM範式的核心機制
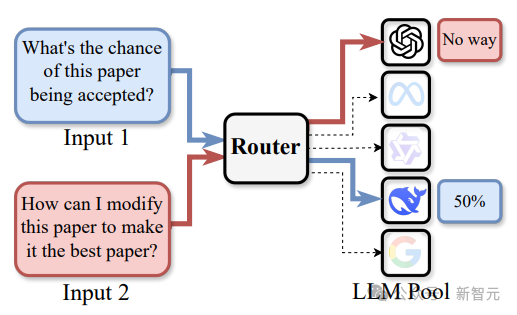
路由LLM系統採用「輸入-路由-執行器」三級架構,其中路由層是系統的智能中樞,承擔著任務分配與資源調度的核心功能:
輸入層:接收多樣化的用戶請求,包括文本生成、文本摘要、代碼補全等任務
路由層:通過預訓練Router對輸入進行深度分析,基於多維度特徵選擇最優LLM執行器
性能優先模式:識別任務領域特徵,匹配性能最優的LLM(當前版本核心目標)
成本優化模式:平衡性能與計算開銷,選擇性價比最高的LLM(後續版賓特性)
風險控制模式:通過多模型交叉驗證,降低單一模型的幻覺風險(後續版賓特性)
執行層:由候選LLM池中被選定的模型完成實際推理,並將結果返回給用戶
與MoE(Mixture-of-Experts)相比,路由LLM實現了兩大突破:
協作粒度:在模型級實現專家協作,而非傳統MoE的層間專家擴展
系統開放性:支持跨架構、跨訓練階段的LLM協同,包括閉源模型、開源模型及專用微調模型的混合部署
這種架構使得路由LLM既能繼承MoE的動態優勢,又突破了其封閉性限制,為構建開放、靈活的大模型協作系統奠定了基礎。
RouterEval解決了什麼問題?
研究人員系統性收集、整理並開源了涵蓋8567個不同LLM在12個主流評測基準(包括MMLU、GSM8K等)下的2億條性能記錄,基於這些數據構建了面向 router的基準測試平台RouterEval,創新性體現在:
數據完備性:覆蓋從7B到數百B參數規模的LLM,涵蓋通用能力、領域專長等多維度的 Benchmark,為router設計提供了全面的訓練與驗證數據
研究低門檻化:所有性能記錄均已預處理完成,研究者只需訓練一個分類器(即router)即可開展實驗,支持在單卡GPU甚至筆記本電腦上運行,極大降低了參與門檻
問題範式轉化:將複雜的路由LLM問題轉化為標準的分類任務,使研究者可複用成熟的機器學習方法(如few-shot learning、對比學習等)快速切入
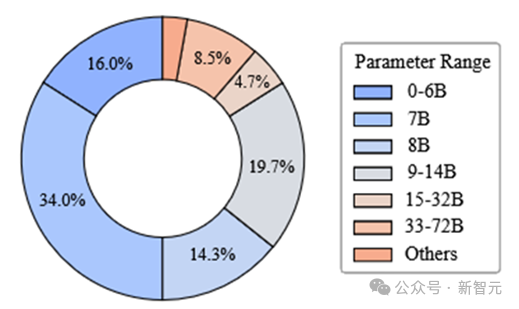 8000+模型的參數量分佈
8000+模型的參數量分佈基於RouterEval的海量數據,研究團隊首次揭示了Model-level Scaling Up現象:在具備一定能力的router調度下,路由LLM系統的性能可隨候選LLM池的擴大而快速提升。這一現像在以往研究中難以被觀察到,主要受限於候選模型數量不足(通常<20個)。
RouterEval的發現
Model level scaling up現象
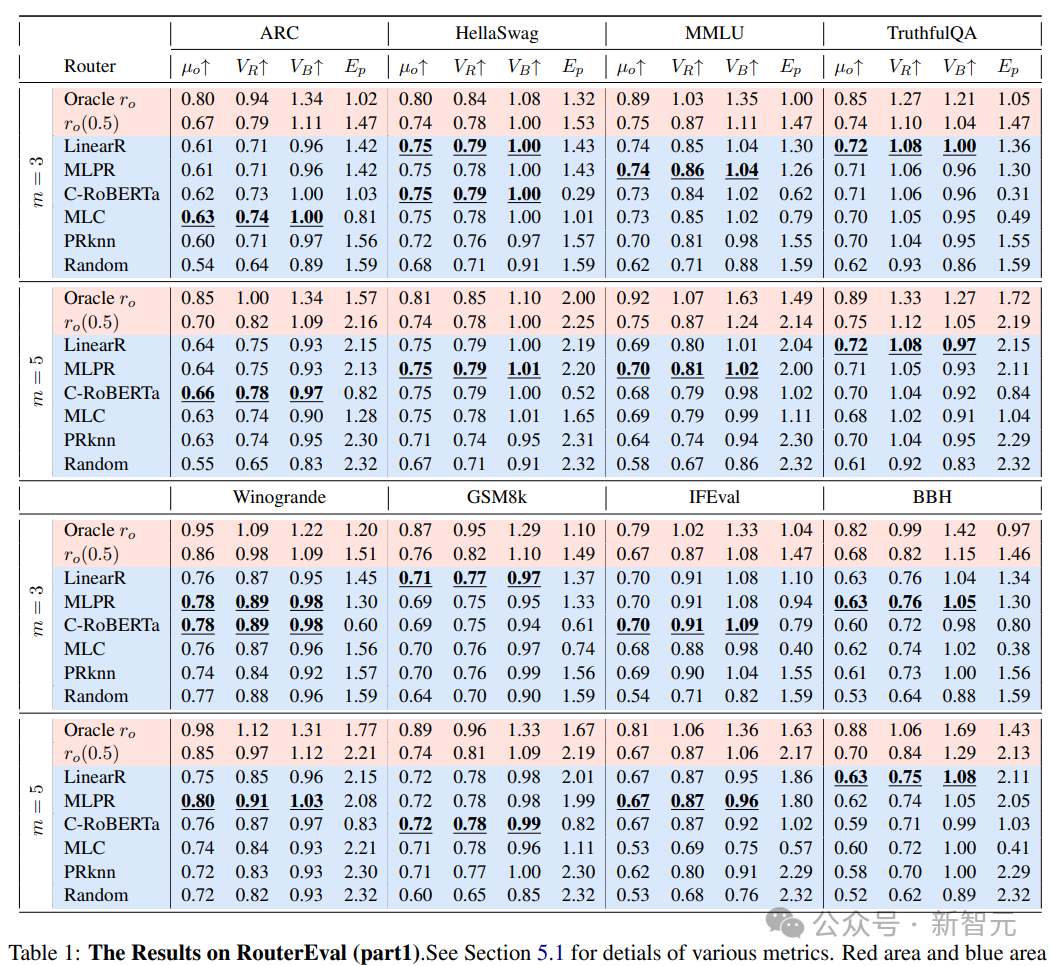
利用RouterEval基準中的2億條性能記錄,研究團隊構建了理論性能上限——Oracle Router(r_o)。Oracle Router是一種理想化的路由器,它能夠始終為每個輸入選擇性能最佳的LLM,因此代表了路由LLM系統的性能上限。
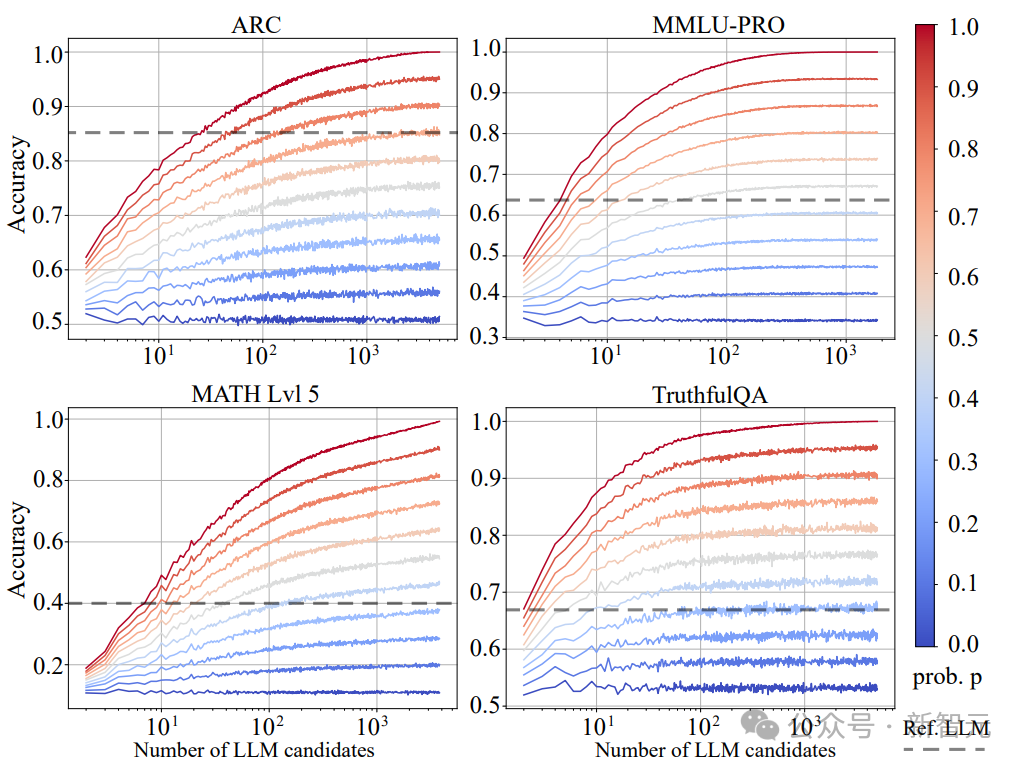
為了系統研究router性能對系統整體表現的影響,研究人員定義了router性能的連續譜系r_o(p):
-
當p→1時,r_o(p)趨近於Oracle Router,代表分類性能接近理論上限
-
當p→0時,r_o(p)退化為隨機router,即隨機選擇候選LLM
- 中間狀態r_o(p)(0
實驗結果表明:
-
強router的scaling up效應:當p>0.3時,系統性能隨候選LLM數量呈明顯快速上升
-
弱router的性能瓶頸:隨機router(p=0)幾乎未表現出scaling up現象
-
超越參考模型:一般候選LLM數量在3~10且p在0.5~0.7時,系統性能可以接近甚至超過參考模型(參考模型一般是GPT-4)
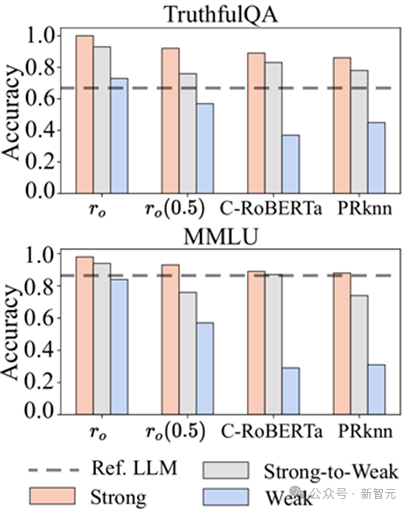 候選模型數量m = 5
候選模型數量m = 5弱模型逆襲效應
通過智能路由調度,多個性能一般的LLM可以協同實現超越頂級單體模型的性能表現。例如,當使用Oracle Router(r_o)調度5個在MMLU基準上單獨表現僅為0.2-0.3的弱模型時,系統整體性能可躍升至0.95,顯著超越GPT-4(0.86)。
這一發現為資源有限的研究者提供了新的技術路徑:無需追求單一超大模型,而是通過多個中小模型的智能組合實現性能突破。
候選池規模閾值
從Model-level Scaling Up現象示意圖可以看到3-10個LLM候選的時候已經可以達到非常不錯的性能。而且此時的部署成本並不高,具有很高的性價比。
實驗數據表明,路由LLM系統的性能提升存在明顯的規模經濟拐點:
-
3-5個候選LLM:可覆蓋大部分常見任務需求,部署成本相比單一頂級模型低。
-
5-10個候選LLM:性能進入穩定提升期,在多數基準上可超越GPT-4等頂級單體模型
-
多於10個候選LLM:性能增益存在邊際效應,每增加1個模型帶來的性能提升並不大
這一發現為實際部署提供了重要指導:在大多數應用場景下,維護一個5-10個模型的候選池即可實現性能與成本的最佳平衡。
例如,在智能客服系統中,組合使用GPT-4(複雜問題)、Llama-3-8B(常規問題)和Phi-3(意圖識別)三個模型,即可在保證服務質量的同時將運營成本顯著降低。
主要挑戰
數據壁壘
要訓練出高性能的router,當前可用的性能記錄數據仍然遠遠不足。由於大多數LLM的性能數據掌握在少數科技公司手中且未開源,這需要整個研究社區的共同努力來構建更全面的數據集。目前,可以通過遷移學習、數據增強等算法技術在一定程度上緩解數據不足的問題;
多候選分類挑戰
隨著候選LLM數量的增加,router需要處理的分類任務複雜度顯著上升。這不僅增加了模型訓練的難度,也對router的泛化能力提出了更高要求。如何在保證分類精度的同時控制計算開銷,是未來研究的重點方向之一;
多目標權衡局限
雖然路由LLM理論上可以同時優化性能、計算成本和幻覺風險等多個目標,但RouterEval目前僅聚焦於性能優化。這是因為當前router的性能水平尚未達到理想狀態,過早引入多目標優化可能會分散研究重點。此外,計算成本和幻覺風險等指標的數據採集難度較大,需要社區共同推動相關數據集的構建;
部署複雜度
即使獲得了高性能的router,實際部署仍面臨諸多挑戰。多個LLM的協同運行需要解決計算負載均衡、資源動態分配、模型高效激活等系統級問題。幸運的是,實驗表明僅需部署3-10個LLM即可獲得優異性能,這大大降低了實際應用的複雜度。未來研究可借鑒分佈式計算領域的技術成果,進一步優化部署方案。
參考資料:
https://arxiv.org/abs/2503.10657