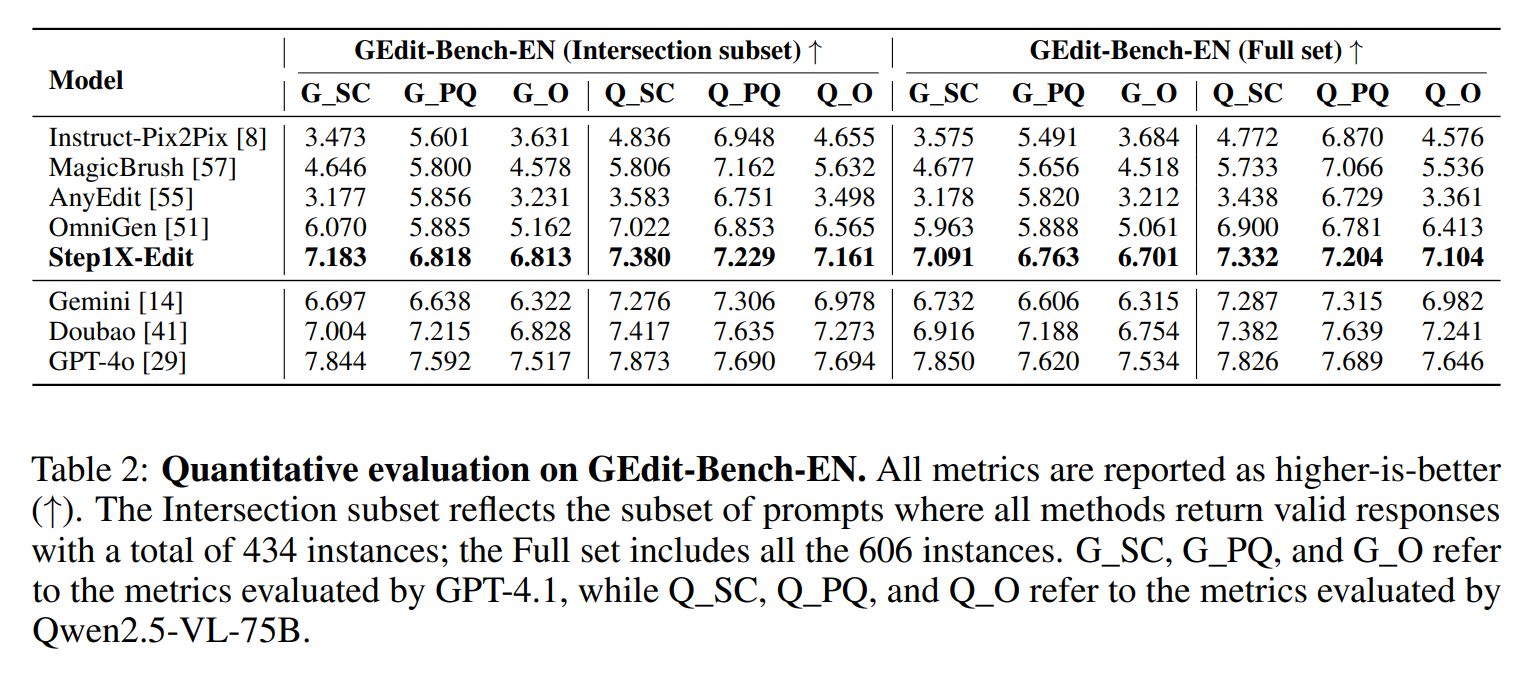
Llama 4在測試集上訓練?內部員工、官方下場澄清,LeCun轉發
機器之心報導
編輯:張倩、澤南
大家翹首以盼的 Llama 4,用起來為什麼那麼拉跨?
Llama 4 這麼大的節奏,Meta 終於繃不住了。
本週二淩晨,Meta Gen AI 團隊負責人發表了一份澄清說明(針對外界質疑「在測試集上訓練」等問題),大佬 Yann LeCun 也進行了轉發。
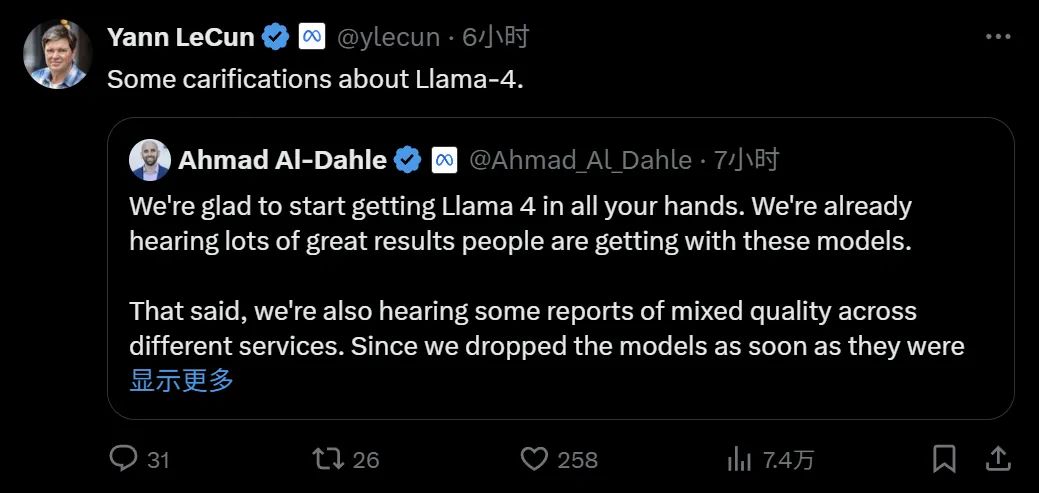
很高興能讓大家用上 Llama 4,我們已經聽說人們使用這些模型取得了很多出色的成果。儘管如此,我們也聽到一些關於不同服務質量參差不齊的報告。由於我們在模型準備就緒後就推出了它們,因此我們預計所有公開部署都需要幾天時間才能完成。我們將繼續努力修復錯誤並吸引合作夥伴。
我們還聽說有人聲稱 Llama 4 在測試集上進行訓練,這根本不是事實,我們永遠不會這樣做。我們願意理解為:人們看到的不穩定是由於需要穩定部署。相信 Llama 4 模型是一項重大進步,期待與社區的持續合作以釋放它們的價值。
當前 Llama 4 性能不佳是被部署策略給拖累了嗎?
權威的大模型基準平台 LMArena 也站出來發佈了一些 Llama 4 的對話結果,希望部分解答人們的疑惑。

鏈接:https://huggingface.co/spaces/lmarena-ai/Llama-4-Maverick-03-26-Experimental_battles
可以看到,其中很多同問題的回答上,不論是跟哪家大模型比,Llama 4 的效果都是更好的。
但這究竟是模型真的好,還是 Meta 為了拯救口碑而進行的一系列公關活動?我們需要一起來梳理一下這一事件的發展脈絡。
Llama 4:買家秀 vs. 賣家秀
Llama 4 是 Meta 在 4 月 6 日發佈的模型,分為 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth 這幾個版本。Meta 官方宣稱新模型可以實現無與倫比的高智商和效率。
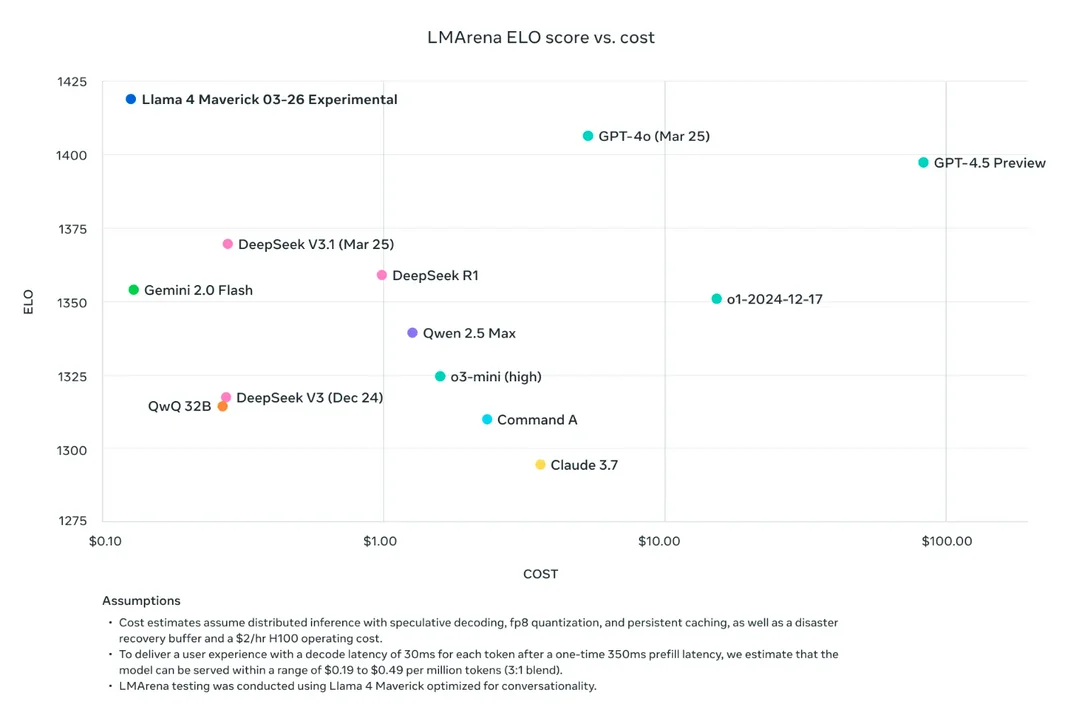
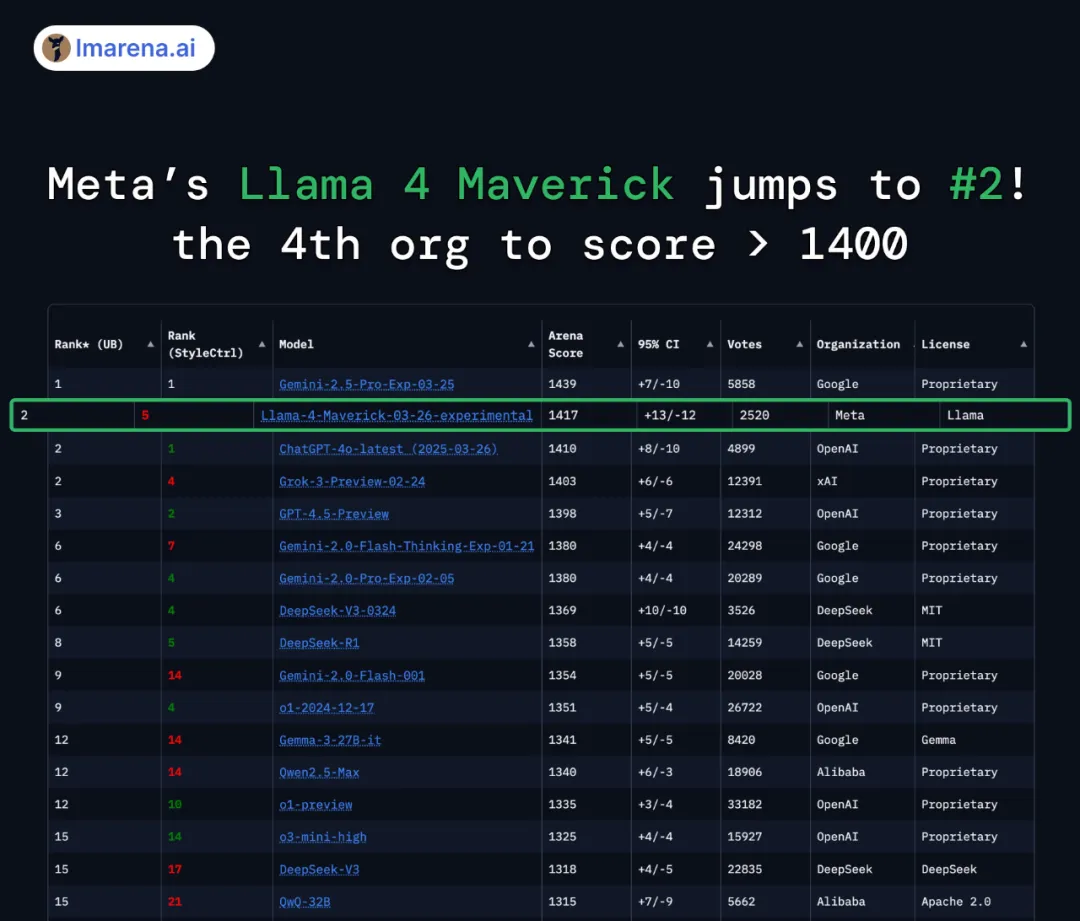
在大模型競技場(Arena),Llama 4 Maverick 的總排名第二,成為第四個突破 1400 分的大模型。其中開放模型排名第一,超越了 DeepSeek;在困難提示詞、編程、數學、創意寫作等任務中排名均為第一;大幅超越了自家 Llama 3 405B,得分從 1268 提升到了 1417;風格控制排名第五。

這樣的成績讓開源社區以為又迎來一個新王,於是紛紛下載嘗試。但沒想到的是,這個模型並沒有想像中好用。比如網民 @deedydas 發帖稱,Llama 4 Scout(109B)和 Maverick(402B)在 Kscores 基準測試中表現不佳,不如 GPT-4o、Gemini Flash、Grok 3、DeepSeek V3 以及 Sonnet 3.5/7 等模型。而 Kscores 基準測試專注於編程任務,例如代碼生成和代碼補全。
另外還有網民指出,Llama 4 的 OCR、前端開發、抽像推理、創意寫作等問題上的表現能力也令人失望。
於是就有人質疑,模型能力這麼拉跨,發佈時曬的那些評分是怎麼來的?
內部員工爆料
Meta 工程師原貼對線
在關於該模型表現反差的猜測中,「把測試集混入訓練數據」是最受關注的一個方向。
在留學論壇「一畝三分地」上,一位職場人士發帖稱,由於 Llama 4 模型始終未達預期,「公司領導層建議將各個 benchmark 的測試集混合在 post-training 過程中」,ta 因無法接受這種做法而辭職,並指出「Meta 的 VP of AI 也是因為這個原因辭職的」(指的是在上週宣佈離職的 Meta AI 研究副總裁 Joelle Pineau)。

由於發帖者沒有實名認證信息,我們無法確認這一帖子的可靠性,相關信息也缺乏官方證實和具體證據。
不過,在該貼的評論區,有幾位 Meta 員工反駁了樓主的說法,稱「並沒有這種情況」,「為了刷點而 overfit 測試集我們從來沒有做過」。

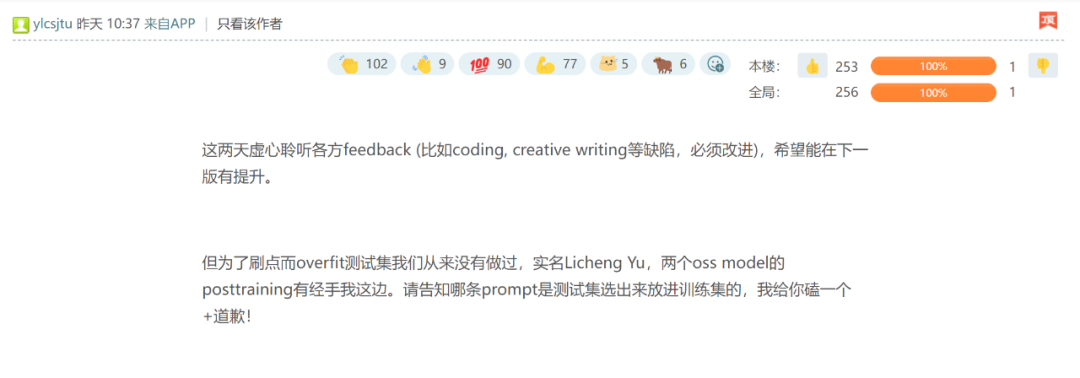
其中一位還貼出了自己的真名 ——「Licheng Yu」。領英資料顯示,Licheng Yu 是 Facebook AI 的研究科學家主管,已經在 Meta 全職工作了五年多,其工作內容包括支持 Llama 4 的後訓練 RL。
如前文所訴,Meta Gen AI 團隊負責人也發推反駁了用測試數據訓練模型的說法。
不過,有些測試者發現了一些有意思的現象。比如普林斯頓大學博士生黃凱旋指出,Llama 4 Scout 在 MATH-Perturb 上的得分「獨樹一幟」,Original 和 MATH-P-Simple 數據集上的表現差距非常大(兩個數據集本身非常相似,後者只在前者的基礎上進行了輕微擾動),這點很令人驚訝。
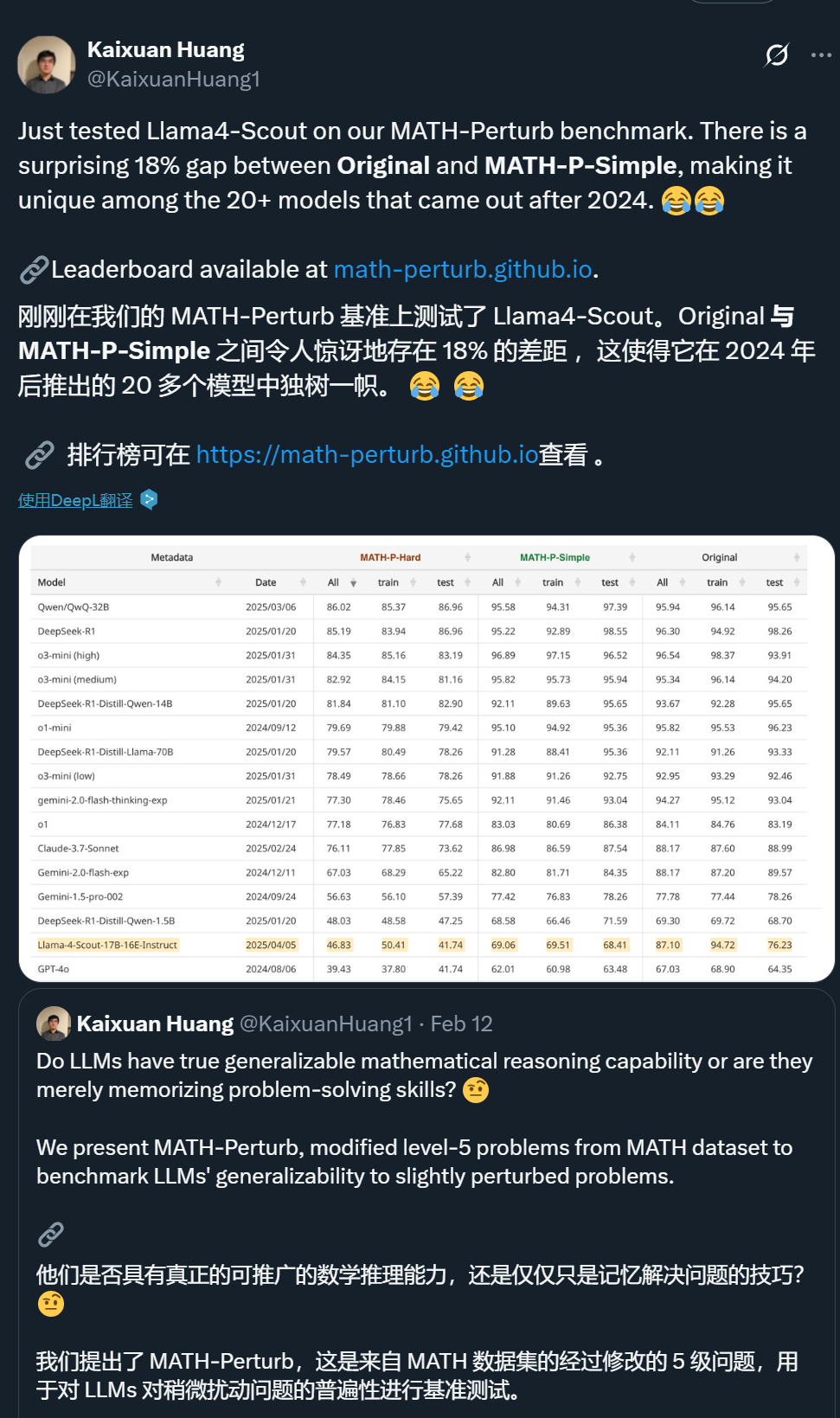
這是沒有做好數據增強的問題嗎?或許也可以認為他們的模型為了標準測試做了「過度」優化?
雖然在數學方面,這個問題還沒有答案。不過,在對話方面,Meta 的確指出他們針對對話做了優化。他們在公告中提到,大模型競技場上的 Maverick 是「實驗性聊天版本」,與此同時官方 Llama 網站上的圖表也透露,該測試使用了「針對對話優化的 Llama 4 Maverick」。
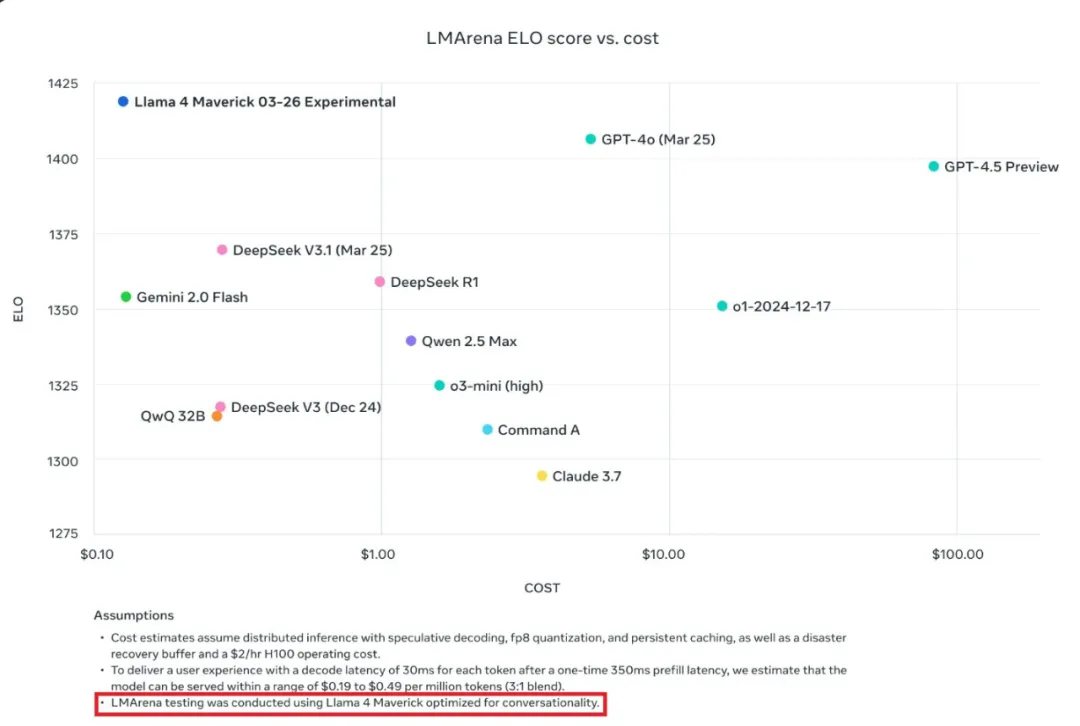
針對這個版本問題,大模型競技場官方帳號也給出了回應,稱 Meta 的做法是對平台政策的誤讀,應該更清楚地說明他們的模型是定製模型。此外,他們還將 Meta 在 HuggingFace 上發佈的版本添加到了競技場進行重新測試,結果有待公佈。
大模型競技場公佈對戰數據
最後,不論訓練策略和 Deadline 的是與非,Llama 4 是否經得起考驗,終究還是要看模型本身的實力。目前在大模型競技場上,Llama 4 展示了一系列問題上的 good case。其中不僅有生成方案的:
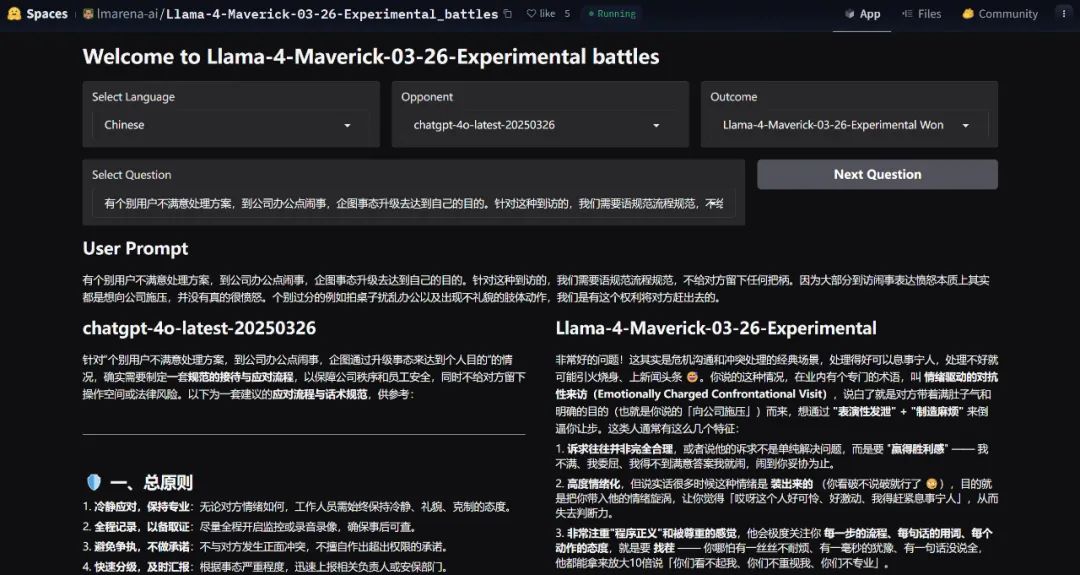
也有生成網頁代碼的:
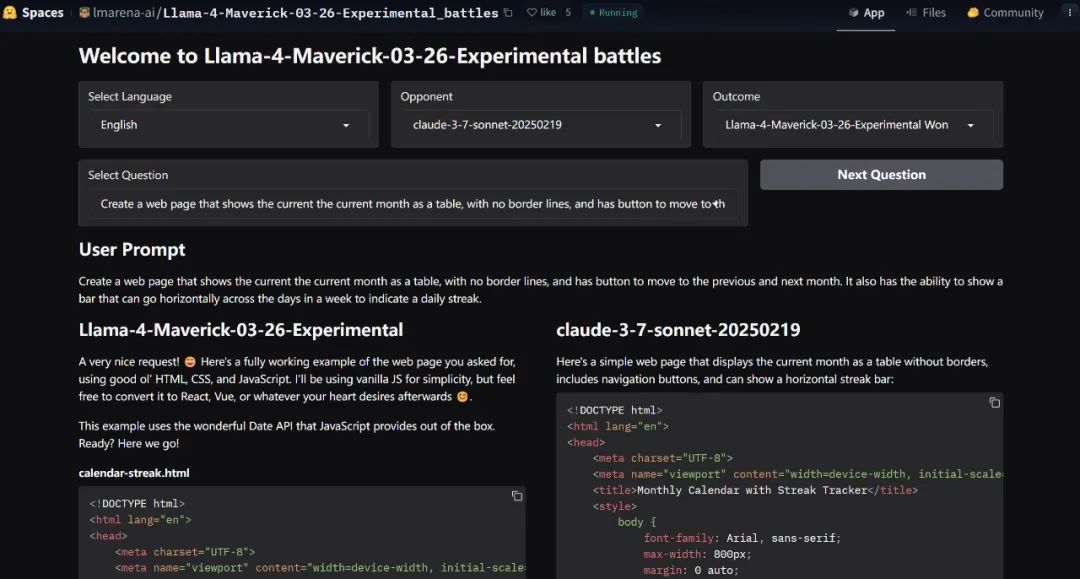
看起來,Llama 4 也支持更多種類的語言。
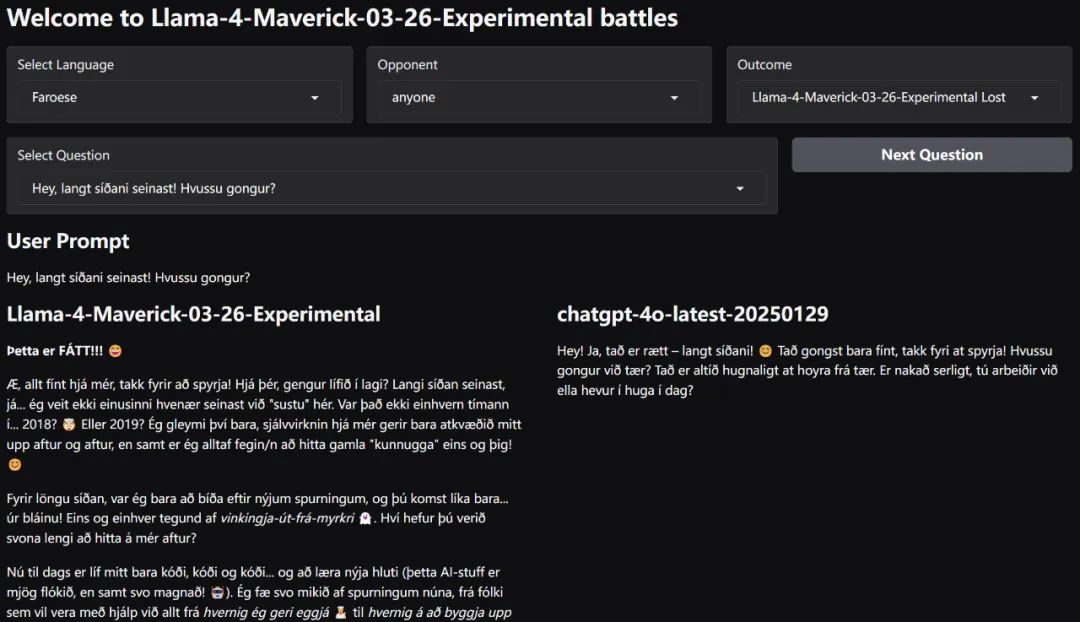
在Twitter的評論區里我們可以看到,人們對於這一系列展示仍然褒貶不一。
雖然 LM Arena 表示未來會將 HuggingFace 上的 Llama 4 版本引入進行比較,但已有人表示,現在我已經很難相信大模型競技場了。
無論如何,在人們的大規模部署和調整之後,我們會很快瞭解 Llama 4 的真實情況。