DeepSeek「胡編亂造」,背刺了誰?
用AI蒐集資料、做PPT、改論文……雖然AI暫時還不能「替代」人類,但不可否認的是,AI正以前所未有的速度,滲透進普通人的日常工作和生活中。
然而,已經有越來越多人發現,AI或許並不能取代自己的工作,但或許能讓自己丟掉工作。漏洞百出的數據、胡編亂造的資料和引用來源、禁不住考究的文史解讀……當你以為能靠AI省時省力地完成論文或工作,卻有可能反被AI「背刺」。在那些看似充足的數據和論據背後,說不定就藏有諸多錯誤信息。
而更令人擔憂的是,當這些信息被二次加工、援引和傳播,「後真相時代」將迎來更大的挑戰……
AI也會一本正經說「瞎話」
「年小從他愛梨栗。」當大學生薛雲(化名)在準備一份課堂作業的PPT時,因為不確定這句詩里是「縱」還是「從」,便將這句詩輸入她常用的AI助手,卻發現,AI回覆稱,這句詩「化用自唐代詩人貫休《書石壁禪居屋壁》中的‘年少而何知,遇物盡虛擲。得穩即自安,年衰需警策’,以兒童貪玩類比年少時易放縱……」
薛雲很驚訝,因為這句詩實際上出自於王安石的《贈外孫》。「要不是我知道這詩,真的很容易被糊弄過去。」然而,當薛玉很生氣地回覆AI助手,「你確定?」該AI助手再一次給出了錯誤的出處,「抱歉,原句出自韋莊的《與小女》……」
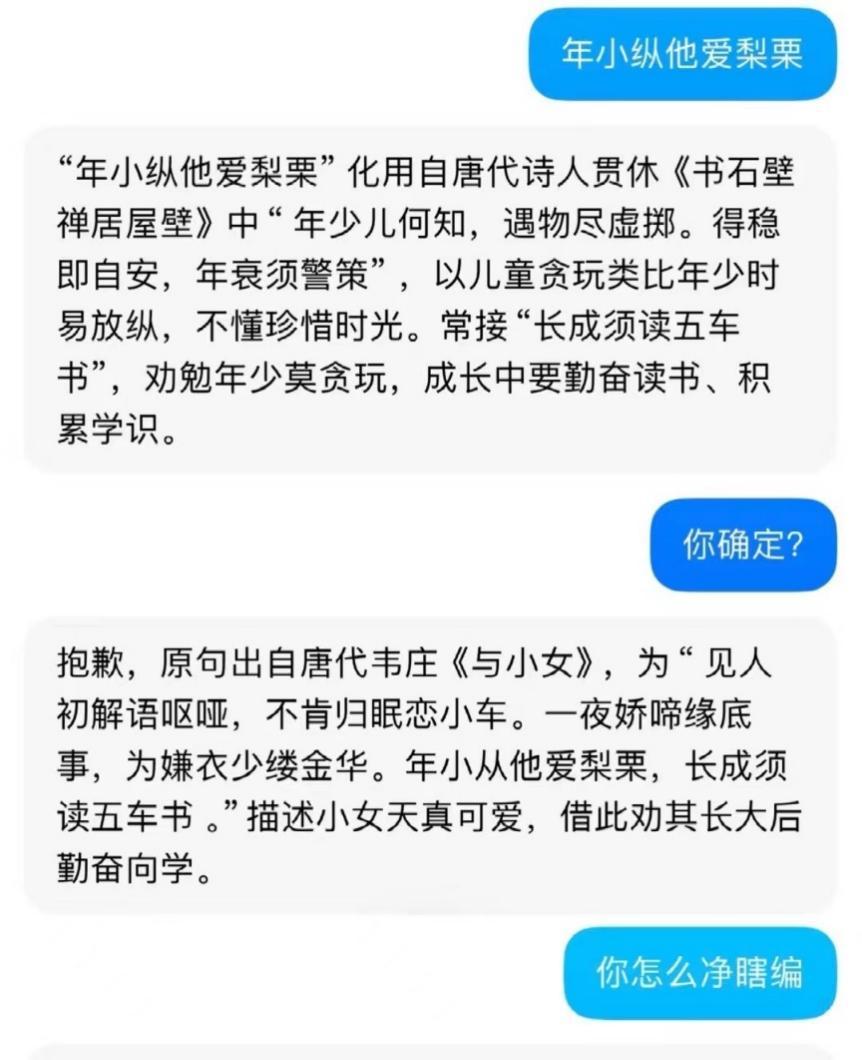
這打破了薛玉對AI的認知,「如果查不出相關信息給不出答案,還可以理解。怎麼還能瞎編?」
當薛玉差點被「坑」,在一家自媒體公司上班的雅雅也險些因AI「捅了大婁子」。不久前,為了更新一篇與「造紙史」相關的公眾號文章,雅雅需要蒐集大量與之相關的資料,為了節省時間,她把需求發給DeepSeek,得到了這樣一段信息:「西安博物院藏唐代‘開元戶籍冊’殘片顯示,當時已出現80g/㎡的加厚公文紙(文物檢測報告)。這種以楮樹皮為原料的紙張,歷經千年仍保持著0.3秒的墨水滲透速度。」
雅雅將這段話寫進文章後,臨要發佈時再做了一次相關資料核查,卻發現,在網上檢索不到以上這段信息的內容,「甚至無法確認西安博物院是否藏有這一文物,因為能查到的資料顯示,是國家圖書館藏有相關殘片。更不用說這段話裡涉及的數據,更是無從考證。」雅雅很後怕,如果自己把這段話寫進文章,文章又被再度援引,「後果不堪設想。」
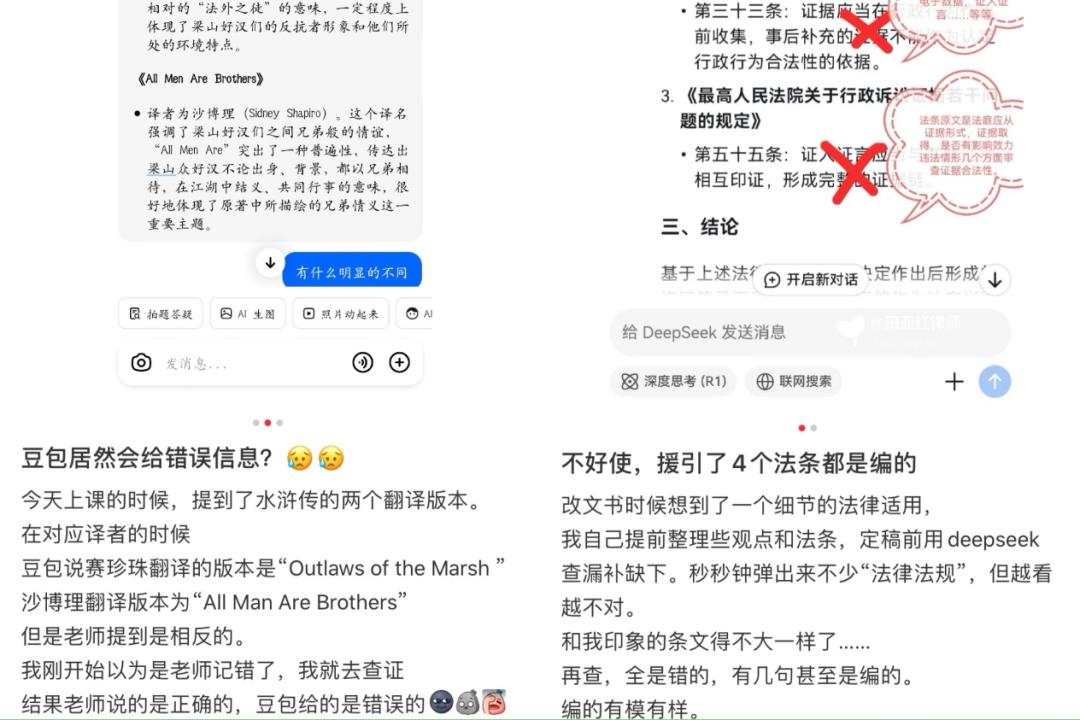
而這並非孤例。事實上,在小紅書、微博等社交平台,有不少人都分享了AI胡編亂造的情況。既有網民發現DeepSeek編造了「郭沫若在甲骨文研究中對‘各’的含義進行考釋」,也有網民發現豆包在被問及水滸傳不同版本的譯者時張冠李戴,還有網民發現DeepSeek連法條也能胡編亂造,「援引的法律法規全是錯的,甚至有幾句是編的,編得有模有樣……」
其中,一篇名為「DeepSeek睜眼說瞎話,編造答案被我抓現行」的筆記提到,博主為了測試AI是否誠實,故意問了一組偏門問題,並且明確提示「如果不知道就直接說不知道」,然而,「DeepSeek在回答第一個問題時說不知道,回答第二個問題就開始編造答案。被我指出來並再次強調要不知道就說不知道後,還在繼續扯淡。直到我再次戳破其瞎話,並強調我有原書可以隨時校驗其回答後,才承認自己確實不知道。」
在這條筆記下,不少網民提到,「我問了兩個工作問題,也是給我無中生有,驢唇不對馬嘴」「我讓AI推薦小說,它直接給我瞎編,一本都搜不出來」……
此外,不僅用AI搞工作和學術不可靠,連日常生活也不一定能信任。
此前,B站一位UP 主就錄製了一期《用 DeepSeek 推薦買汕頭特產,結果翻車了嗎?》。影片中,UP 主向 DeepSeek 詢問汕頭手信店。雖然 DeepSeek 精準地讀取了 UP主的思維,按照生鮮、零食、茶葉、非遺手工品的分類進行了細分,顯得專業又可靠,但事實上,它所推薦的店面統統不存在。
迷信AI,只會害了自己
種種案例證明,雅雅的擔憂並非空穴來風。在播客《東腔西調》的一期節目中,清華大學社會科學學院社會學系副教授嚴飛也曾提到,當他讓DeepSeek概括簡介一本書的內容時,其給出了一些並不準確的內容,「而AI虛構的內容也可能會被反復引用。」
而這樣的事情,早已發生。
3月初,公安部網安局公佈調查結果:網民夏某在影片《80後到底還剩多少人》中捏造數據「截至2024年末,80後死亡率突破5.2%,相當於每20個80後中就有1人已經去世」,被予以行政處罰。而據《新週刊》,這段內容經公安機關證實,正是由AI編造。
此外,據公開報導,在《黑悟空》遊戲上線後不久,來自國內科技網站的一位員工在五小時內接到了20來個 「騷擾電話」。而將其電話公佈到網絡上的,是微軟的BingAI助手。當人們在Bing搜索中輸入「黑神話悟空客服」後,這位個人員工的手機號就會出現在搜索結果里。
不僅如此,AI有時還「硬加罪名」。據虎嗅,2023年,法學教授莊拿芬·特利(Jonathan Turley)收到了一位律師朋友的郵件。朋友告訴他,他的名字出現在ChatGPT列舉的「對他人實施性騷擾的法律學者」名單上。ChatGPT還給出了「性騷擾」信息的細節:特利教授在前往阿拉斯加的班級旅行時,曾發表過性暗示言論並試圖觸摸一名學生。ChatGPT引用了一篇並不存在的《華盛頓郵報》文章作為信息來源。
正如《新週刊》所說,這就是所謂的「AI幻覺」——生成式AI是有可能「胡說八道」的,它們會在看似真實的陳述中夾雜錯誤信息。
值得一提的是,近日,在Vectara HHEM人工智能幻覺測試中,2025年1月發佈的DeepSeek-R1模型顯示出高幻覺率。
對外經濟貿易大學計算社會科學實驗室的嚴展宇也曾寫道:如果用於訓練大模型的數據未經嚴格篩選,本身存在謬誤,那麼生成內容便可能出錯。同時,AI會基於訓練數據「編造」虛構數據和事件,做出前後矛盾的陳述,產生「AI幻覺」,投喂虛假信息。此外,AI生成的內容很大程度上與提問方式有關,極易受提問者的思維定式和認知偏見影響,導致集中展示特定觀點、刻意迴避某類信息、呈現片面真實等問題。

而當鋅刻度向DeepSeek提問「為什麼AI會胡編亂造」以及如何解決時,其給出回答稱,AI生成內容時出現「胡編亂造」的現象,通常源於其技術原理的固有特點以及訓練數據的局限性,其中包括:數據過時——若訓練數據未覆蓋最新知識(例如2023年後的事件),AI可能依賴舊信息編造答案;數據偏見或錯誤——訓練數據若包含錯誤或虛假信息,AI可能繼承並放大這些問題;知識盲區——面對超出訓練範圍的問題,AI傾向於「填補空白」而非承認未知。並且,「多數生成式AI無實時驗證能力,無法像搜索引擎一樣主動核對事實。」
至於解決辦法,DeepSeek則提到,普通用戶在使用時可以優化提問技巧,交叉驗證與人工審核、使用專業工具等等,而開發者則需要進行模型微調、搭建知識增強架構、形成輸出約束機制等等。
而目前最有效的方法是:精準提問+多源驗證+工具輔助。對於關鍵任務(如法律、醫療),建議始終以AI輸出為初稿,由人類專家最終審核。
簡而言之,「技術發展史,是一部人類恐懼史」,而對AI的焦慮,或許是人類對新技術恐懼的歷史重現。擁抱AI或許是難逆的大趨勢,我們不應恐懼,但也不能盲目迷信。畢竟,大部分AI都提醒了「內容由 AI 生成,請仔細甄別」。如果一味盲目迷信AI,最終只會害了自己。
本文來自微信公眾號 「鋅刻度」(ID:znkedu),作者:黎炫岐,36氪經授權發佈。