Llama 4遭競技場背刺,實錘用特供版刷榜,2000+對戰記錄公開
Llama 4真要被錘爆了,這次是大模型競技場(Chatbot Arena)官方親自下場開懟:
競技場上,Meta提供給他們的是特供版!
以下是競技場背後lmarena.ai團隊的原話:

我們注意到社區對Llama-4最新版本在Arena平台的發佈存在疑問。為確保完全透明,現公開2000餘組模型對戰數據供公眾審閱,包含用戶提示詞、模型回覆及用戶偏好數據(鏈接詳見下一條推文)。
初步分析表明,模型回覆風格與語氣是重要影響因素(詳見風格控制排名),我們正在進行更深入的分析!(比如表情符號控制?)
此外,我們即將在Arena平台上線Llama-4-Maverick的HuggingFace版本,排行榜結果將稍後公佈。
Meta對我們平台政策的理解與我們對模型提供商的期待存在偏差——Meta本應明確標註“Llama-4-Maverick-03-26-Experimental”是經過人類偏好優化的定製模型。
為此,我們正在更新排行榜政策,以強化對公平性、可複現性評估的承諾,避免未來再出現此類混淆。
總結一下就是:
公開對戰數據,正分析排名受影響因素
譴責Meta未明確標註模型版本導致評測混淆
後續:上線Llama-4-Maverick的HuggingFace版、更新排行榜政策
官方下場表態後,Llama 4和Meta的路人緣進一步下降。
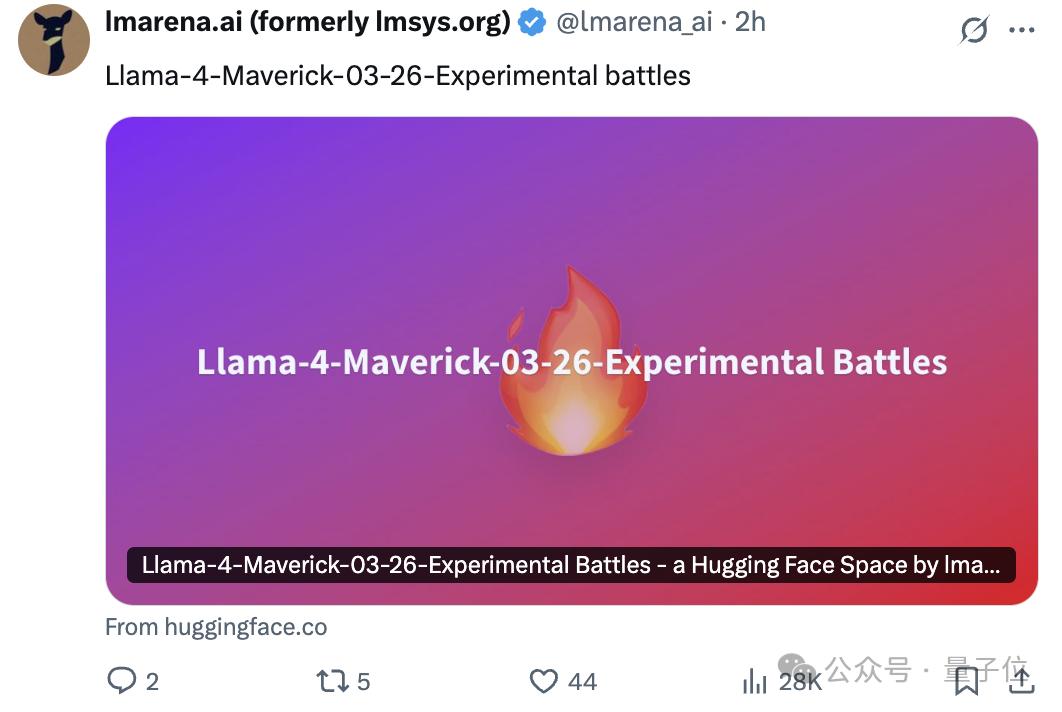
2000+輪對戰記錄完整公開
來看看lmarena.ai公開的模型對戰記錄詳情。
首先來看網民實測時對Llama 4抱怨較大的代碼生成任務。
競技場中Llama-4-Maverick-03-26-Experimental版本生成代碼的表現的確是OK的。
prompt:
create me fun web based game that i can just run the code and works(幫我創建一個有趣的網頁遊戲,我只需運行代碼就能玩)
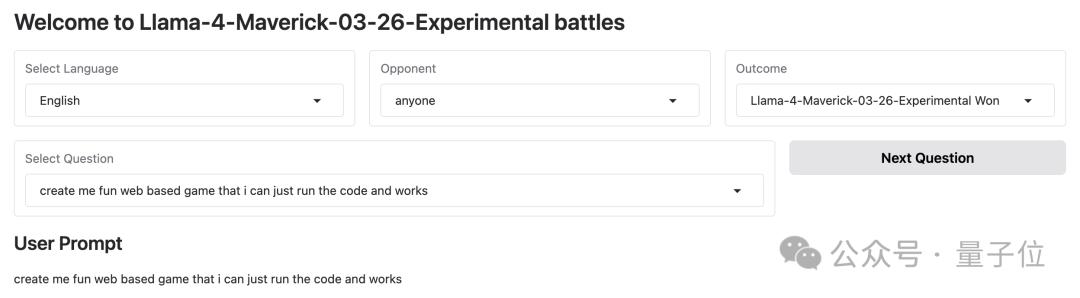
Llama-4-Maverick-03-26-Experimental對戰加拿大AI初創公司Cohere的command-a-03-2025。
上文lmarena.ai調查表示「模型回覆風格與語氣是重要影響因素」,從對戰數據中的確可以看出Llama-4-Maverick-03-26-Experimental的回覆中會增加如”A very nice and very direct request!” “That’s it!

“”Happy gaming!”等展示友好的語句以及表情包。
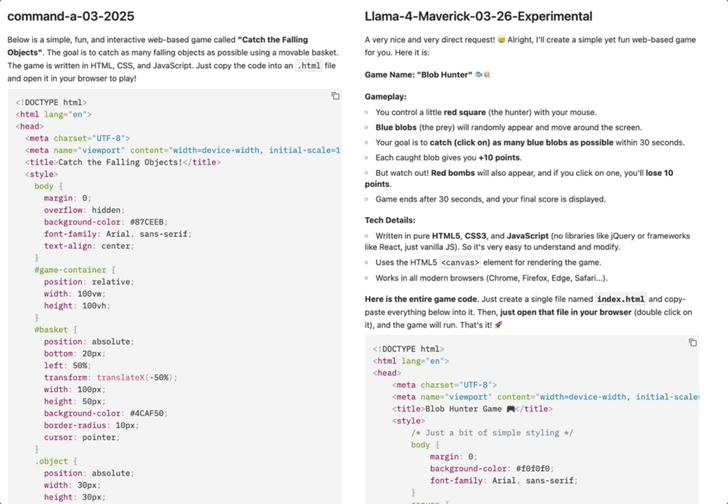
運行兩個模型生成的代碼。
command-a-03-2025生成的小遊戲是移動鼠標控制綠色籃子接住橙色小球,看效果顯然有bug,小球直接穿過籃子,分數也沒有變動:

Llama-4-Maverick-03-26-Experimental生成的小遊戲玩法是移動鼠標控制紅色方塊,點擊四處移動的藍色圓點+10分,點擊黑色炸彈-10分,每局遊戲30秒。
可以正常運行,計分也比較準確:

這局command-a-03-2025輸的不冤。
另外,之所以展示Llama-4-Maverick-03-26-Experimental和command-a-03-2025的對比,是因為有網民發現Llama 4聲稱的關鍵創新「interleaved no-RoPE attention」和command-a的如出一轍:

再看一個起標題的任務,prompt:
I will give a congress talk 「On Naevi」 — naevi are benign melanocytic lesions which are markers and every so often also precursors of melanoma. Do you have suggestions for a short and succinct title for my presentation(我將在一個學術會議上作關於「痣」的演講——痣是黑素細胞良性病變,可作為黑色素瘤的標誌物,有時甚至是其前驅病變。您能否為我的演講推薦一個簡潔有力的標題?)
Llama-4-Maverick-03-26-Experimental對戰的是claude-3-5-sonnet-20241022。
對比來看,claude-3-5-sonnet-20241022的回覆言簡意賅,直接給出5個標題:

Llama-4-Maverick-03-26-Experimental的回覆更為詳細。
不僅會提供情緒價值,如A very timely and relevant topic! Congrats on getting the slot at congress, by the way!(選題非常應景且切合實際!恭喜拿下大會報告機會),而且從不同角度分別提供了幾個標題:

這還沒完,Llama-4-Maverick-03-26-Experimental還會貼心地指出選擇標題時需要考慮的因素以及它自己選擇的top 3標題。

最後再來隨機看一道中文題目:
prompt:
解析一下這部微小說 題目 自駕遊 當年我自駕遊 不小心壓死了一頭羊 羊的主人好熱情 宰了羊給我們吃 還送我們到火車站 在回來的路上 看著火車外的風景 真的好感人

對戰o3-mini,Llama-4-Maverick-03-26-Experimental再次展現出超長輸出的特點,故事分析完了還拆解了作者為什麼要這樣設計,作者本人可能都沒想這麼多(doge):

對戰數據看下來,Llama-4-Maverick-03-26-Experimental的排名會這麼高,也不奇怪。
此前網民質疑Llama-4-Maverick-03-26-Experimental刷票的可能性降低。
Llama 4深陷「造假」醜聞
如開頭所述,Llama 4被lmarena.ai站出來抨擊的原因,是因為測試排名和實際表現不符。
在大模型競技場中,Llama 4得分1417,不僅大大超越了此前Meta自家的Llama-3-405B(提升了149分),還成為史上第4個突破1400分的模型。
而且跑分超越了DeepSeek-V3,直接成為榜單上排名第一的開源模型。
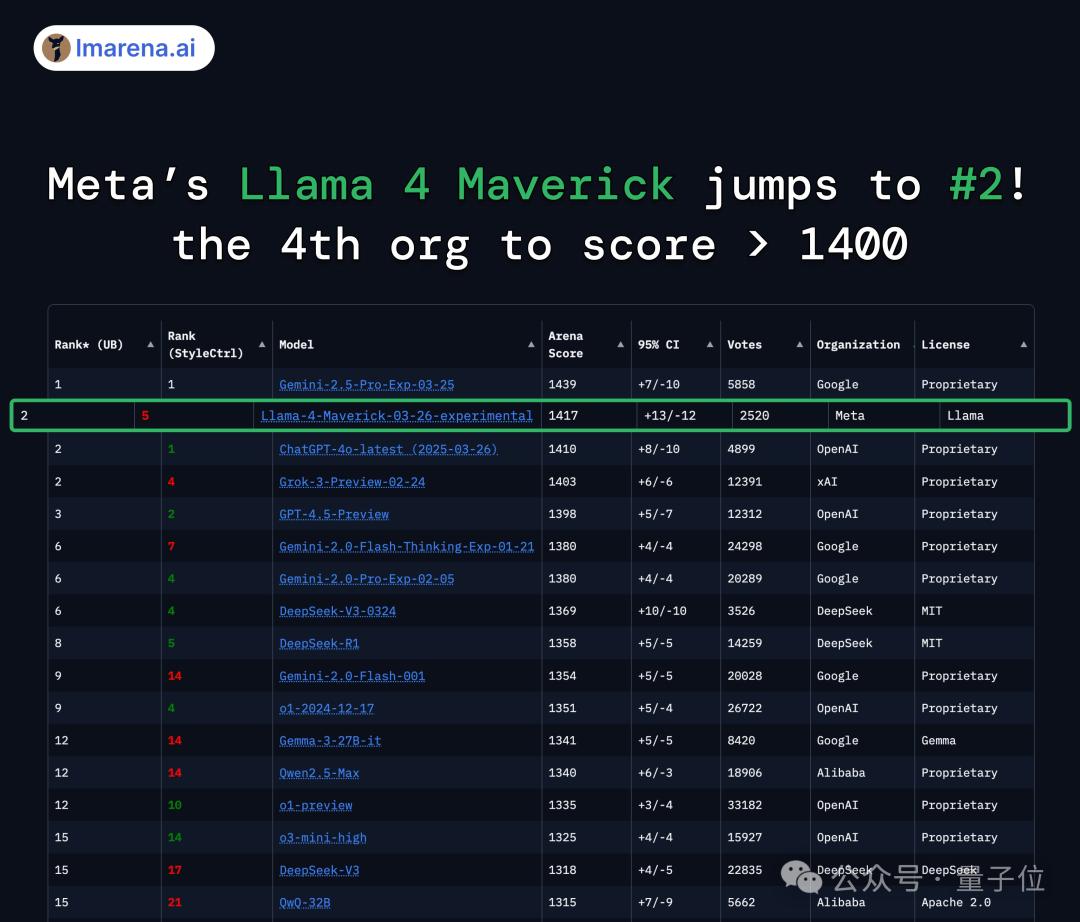
但沒過多久,人們就發現Llama 4的實際表現相當拉胯,一時間差評如潮,甚至還被做成了表情包。

比如經典「氛圍編程」小球反彈測試,小球直接穿過牆壁掉了下去。
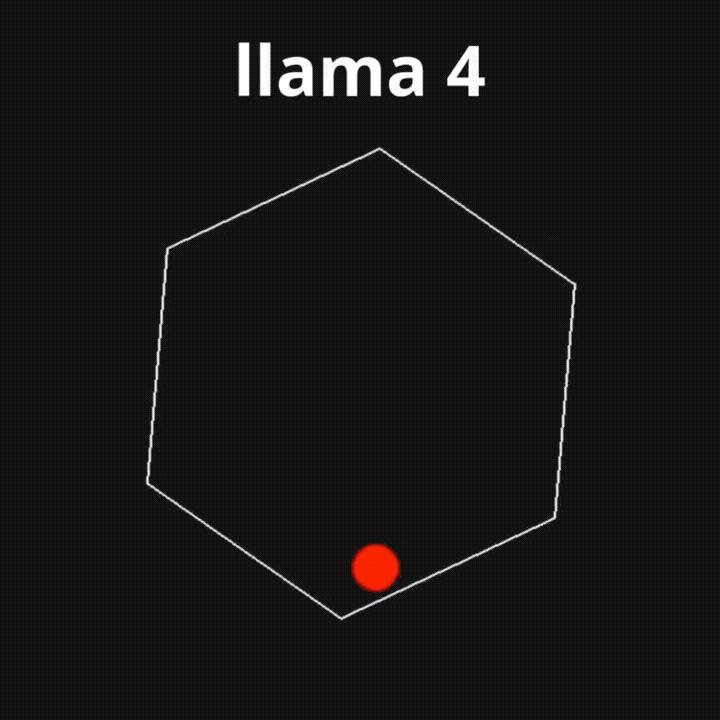
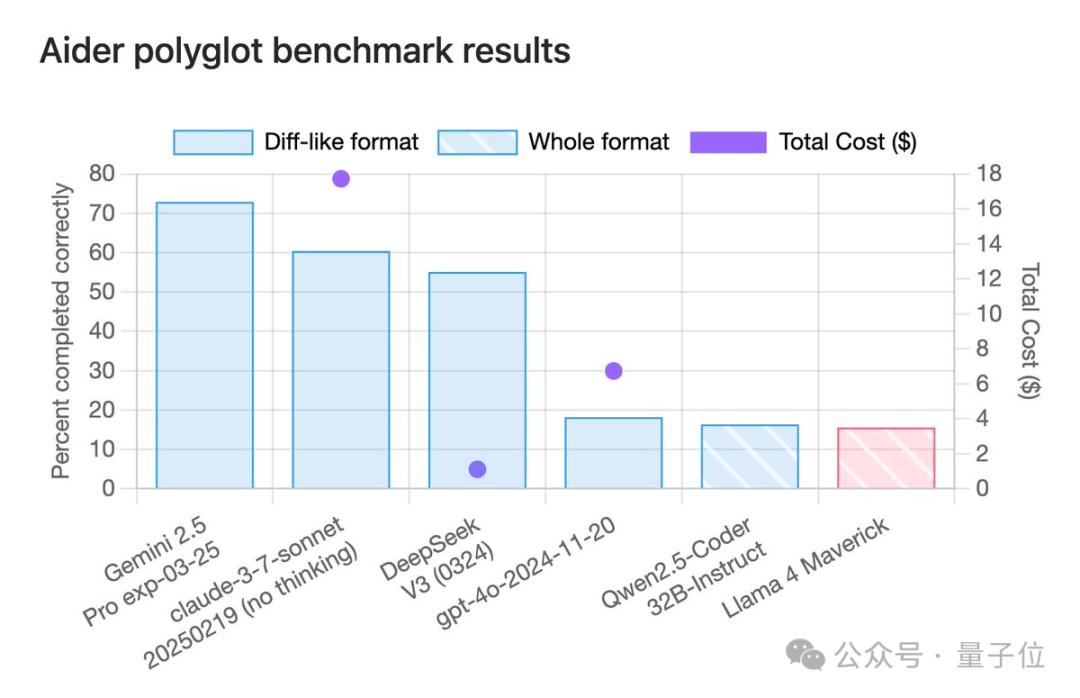
其它跑分方面,到了各種第三方基準測試中,情況也大多直接逆轉,排名掉到了末尾。
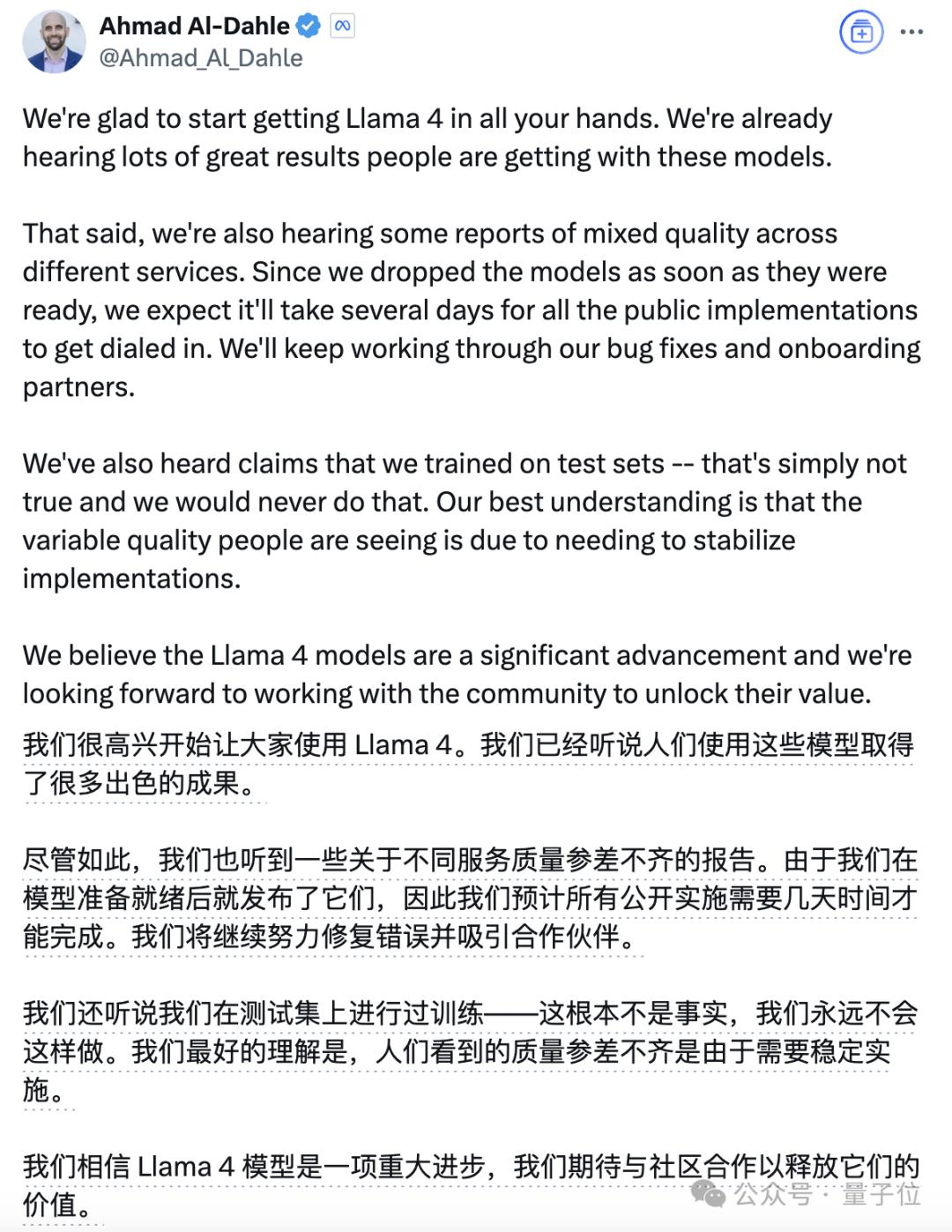
並且從Meta GenAI負責人Ahmad Al-Dahle的推文當中也能看懂,競技場中的Llama 4,確實是一個特殊版本。

而在最新的推文中,Ahmad表示Llama 4絕對沒有使用測試集進行訓練,表現存在差異的原因是還需要穩定的部署。
對於這一解釋,有人並不買賬,直言這種現像在其他模型當中從未見過。

Meta的支持者則表示,希望表現不佳真的是供應商的問題所致。
大模型競技場,還能信嗎?
被捲入這次漩渦的不僅是Llama 4和背後的Meta,涉及到的大模型競技場也引起了人們的廣泛討論。
畢竟Llama 4的「造假」風波就是發生在競技場上,所以也自然有人質疑起了榜單的權威性。
有人指出,競技場的偏差不只體現在Llama 4被高估上,還有Claude 3.7的表現被低估了。

當然,官方快速回應並公開了測試中的細節,這個做法獲得了網民的肯定,說明至少在態度和透明度上是說得過去的。
但也有人認為,無論官方態度端不端正,Llama 4事件說明這種「人類評價AI」的方法,本身已經不適用了。
人們日常生活中的問題,幾乎所有領先模型都能完美解答,誰還會去認真投票,這個基準已經過時了。
有人補充說,「人類偏好」不是評價高級大模型能力的可靠標準,產生較大偏差是正常的。

還有人表示,從官方發佈的消息來看,lmarena.ai自己都不清楚自己的基準。
這名網民解釋,特調版Llama 4獲得用戶投票的原因並非lmarena.ai所說的「表情符號」,而是因為更具親和力。
當然也有人提了些建設性的意見,比如更改ELO評分的算法,或者啟用強製風格轉換。
但總之,無論是迭代改進還是另闢蹊徑,都是時候更新對大模型的評價方式了。
參考鏈接:
[1]https://x.com/lmarena_ai/status/1909397817434816562
[2]https://x.com/Ahmad_Al_Dahle/status/1909302532306092107
[3]https://huggingface.co/spaces/lmarena-ai/Llama-4-Maverick-03-26-Experimental_battles
本文來自微信公眾號「量子位」,作者:基爾西 西風,36氪經授權發佈。