CVPR 2025 HighLight|打通影片到3D的最後一公里,清華團隊推出一鍵式影片擴散模型VideoScene

論文有兩位共同一作。汪晗陽,清華大學計算機系本科四年級,研究方向為三維視覺、生成模型,已在CVPR、ECCV、NeurIPS等會議發表論文。劉芳甫,清華大學電子工程系直博二年級,研究方向為生成模型 (3D AIGC和Video Generation等),已在CVPR、ECCV、NeurIPS、ICLR、KDD等計算機視覺與人工智能頂會發表過多篇論文。
 從影片到 3D 的橋樑:VideoScene 一步到位
從影片到 3D 的橋樑:VideoScene 一步到位隨著 VR/AR、遊戲娛樂、自動駕駛等領域對 3D 場景生成的需求不斷攀升,從稀疏視角重建 3D 場景已成為一大熱點課題。但傳統方法往往需要大量圖片、繁瑣的多步迭代,既費時又難以保證高質量的 3D 結構重建。
來自清華大學的研究團隊首次提出 VideoScene:一款 「一步式」 影片擴散模型,專注於 3D 場景影片生成。它利用了 3D-aware leap flow distillation 策略,通過跳躍式跨越冗餘降噪步驟,極大地加速了推理過程,同時結合動態降噪策略,實現了對 3D 先驗信息的充分利用,從而在保證高質量的同時大幅提升生成效率。

-
論文標題:VideoScene:Distilling Video Diffusion Model to Generate 3D Scenes in One Step
-
論文地址: https://arxiv.org/abs/2504.01956
-
項目主頁: https://hanyang-21.github.io/VideoScene
-
Github 倉庫: https://github.com/hanyang-21/VideoScene
稀疏視角重建方法挑戰
在稀疏視角重建領域,從少量圖像中精準恢復 3D 場景是個極具挑戰性的難題。傳統方法依賴多視角圖像間的匹配與幾何計算 ,但當視角稀疏時,匹配點不足、幾何約束缺失,使得重建的 3D 模型充滿瑕疵,像物體結構扭曲、空洞出現等。
為突破這一困境,一些前沿方法另闢蹊徑,像 ReconX 就創新性地借助影片生成模型強大的生成能力,把重建問題與生成問題有機結合。它將稀疏視角圖像構建成全局點雲,編碼為 3D 結構條件,引導影片擴散模型生成具有 3D 一致性的影片幀,再基於這些幀重建 3D 場景,在一定程度上緩解了稀疏視角重建的不適定問題。
不過,當前大多數 video to 3D 工具仍存在效率低下的問題。一方面,生成的 3D 影片質量欠佳,難以生成三維結構穩定、細節豐富、時空連貫的影片。在處理複雜場景時,模型容易出現物體漂移、結構坍塌等問題,導致生成的 3D 影片實用性大減價扣。另一方面,基於擴散模型的影片生成通常需要多步降噪過程,每一步都涉及大量計算,不僅耗時久,還帶來高昂的計算開銷,限制了其在實際場景中的應用。
繼承與超越:ReconX 理念的進化
此前研究團隊提出 video-to-3D 的稀釋視角重建方法 ReconX,核心在於將 3D 結構指導融入影片擴散模型的條件空間,以此生成 3D 一致的幀,進而重建 3D 場景。它通過構建全局點雲並編碼為 3D 結構條件,引導影片擴散模型工作 ,在一定程度上解決了稀疏視角重建中 3D 一致性的問題。
VideoScene 繼承了 ReconX 將 3D 結構與影片擴散相結合的理念,並在此基礎上實現了重大改進,堪稱 ReconX 的 「turbo 版本」。
在 3D 結構指導方面,VideoScene 通過獨特的 3D 躍遷流蒸餾策略,巧妙地跳過了傳統擴散模型中耗時且冗餘的步驟,直接從含有豐富 3D 信息的粗略場景渲染影片開始,加速了整個擴散過程。同時也使得 3D 結構信息能更準確地融入影片擴散過程。在生成影片幀時,VideoScene 引入了更強大的動態降噪策略,不僅僅依賴於固定的降噪模式,而是根據影片內容的動態變化實時調整降噪參數,從而既保證了生成影片的高質量,又極大地提高了效率。
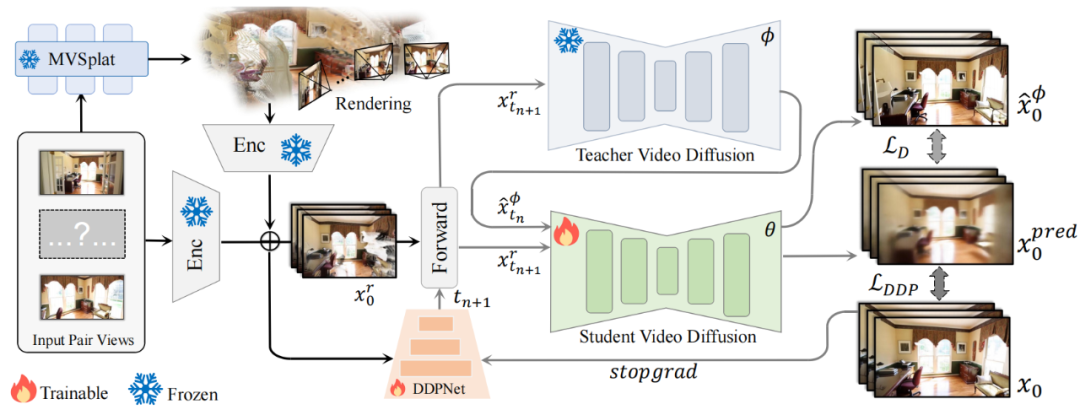 研究團隊提出的 VideoScene 方法流程圖
研究團隊提出的 VideoScene 方法流程圖實驗結果
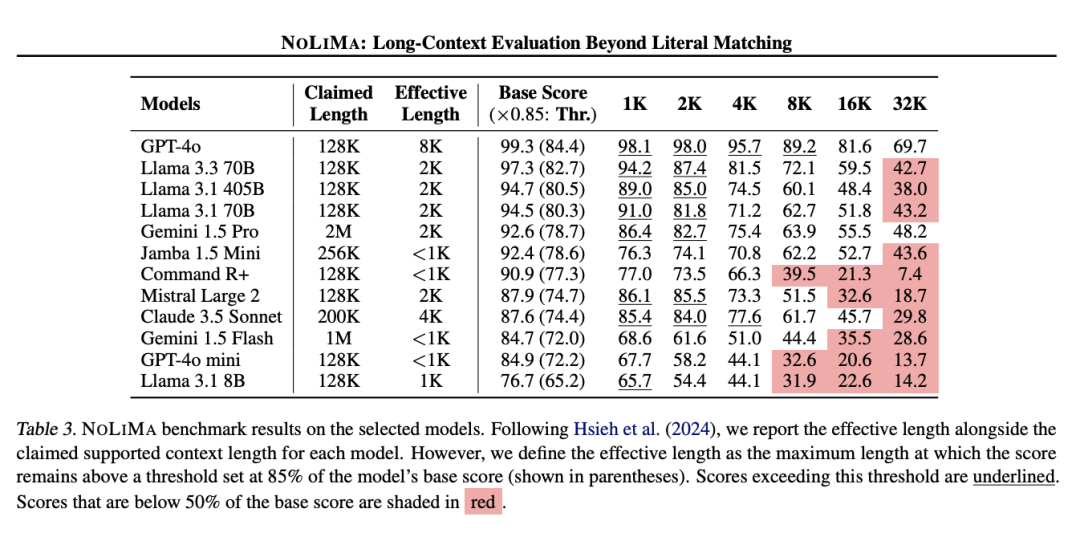
通過在多個真實世界數據集上的大量實驗,VideoScene 展示出了卓越的性能。它不僅在生成速度上遠超現有的影片擴散模型,而且在生成質量上也毫不遜色,甚至在某些情況下還能達到更好的效果。這意味著 VideoScene 有望成為未來影片到 3D 應用中的一個重要工具。在實時遊戲、自動駕駛等需要高效 3D 重建的領域,有潛力能發揮巨大的作用。
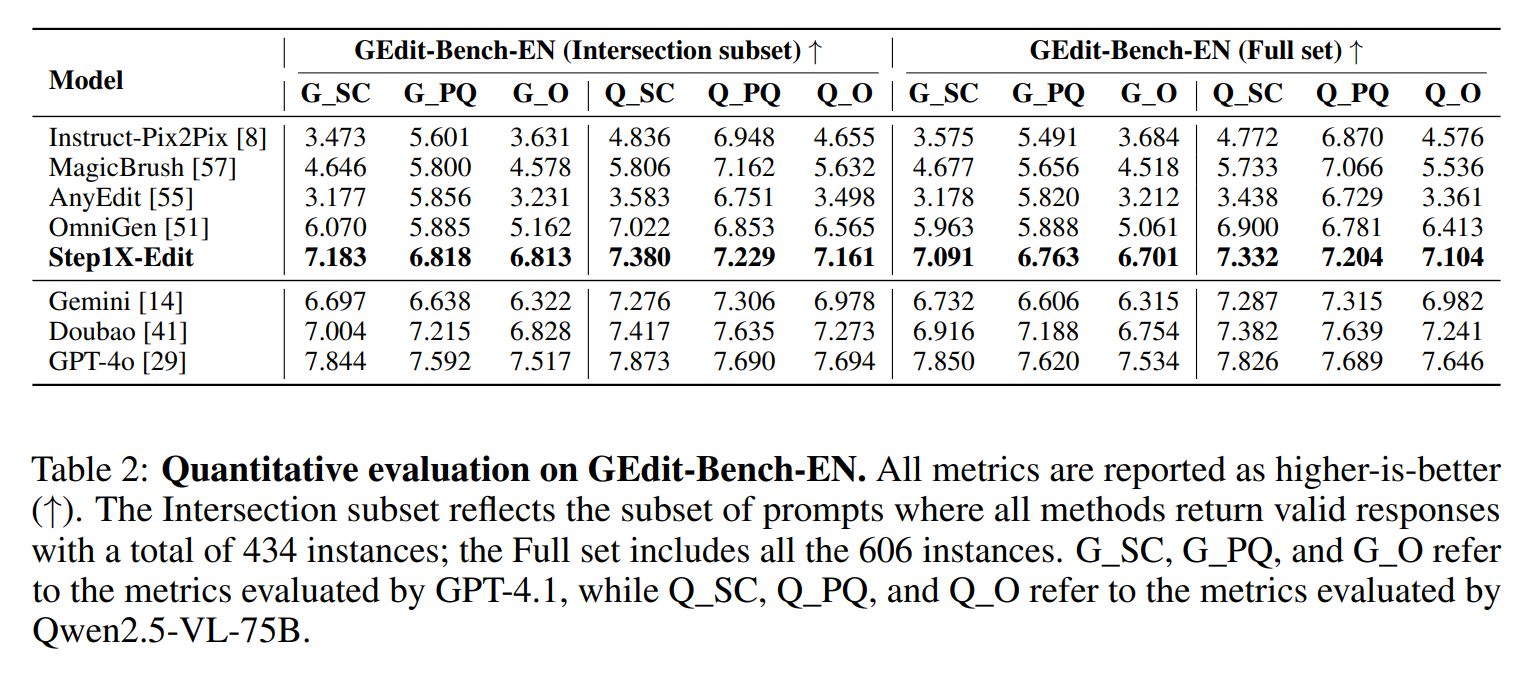
 VideoScene 單步生成結果優於 baseline 模型 50 步生成結果
VideoScene 單步生成結果優於 baseline 模型 50 步生成結果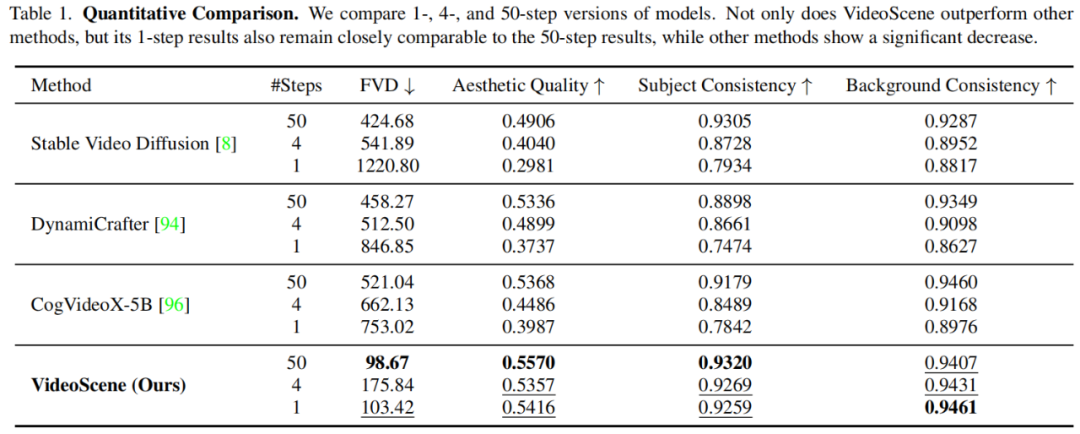 影片擴散模型在不同去噪步數下的表現
影片擴散模型在不同去噪步數下的表現如果你對 VideoScene 感興趣,想要深入瞭解它的技術細節和實驗結果,可訪問論文原文、項目主頁和 GitHub 倉庫。