首個統一多模態模型評測標準,DeepSeek Janus理解能力領跑開源,但和閉源還有差距
MME-Benchmarks團隊 投稿
量子位 | 公眾號 QbitAI
統一多模態大模型(U-MLLMs)逐漸成為研究熱點,近期GPT-4o,Gemini-2.0-flash都展現出了非凡的理解和生成能力,而且還能實現跨模態輸入輸出,比如圖像+文本輸入,生成圖像或文本。
相比傳統的多模態模型(比如 GPT-4V 或 DALL·E 3),這類模型在任務適應性和靈活性上更具優勢。然而,當前研究領域還存在幾個突出的問題:

1. 評測標準混亂:不同研究選用的評測數據集與指標各不相同,使得模型之間難以公平比較;
2. 混合模態生成能力缺乏評測體系:例如,在圖像中畫輔助線解題、根據推理結果生成圖像等案例雖然很有代表性,但沒有統一的 benchmark 能夠全面測評這類能力。
這些問題嚴重限制了U-MLLMs的發展和落地應用,因此迫切需要一個系統、標準的評測框架。
主要貢獻
MME-Unify(簡稱 MME-U)正是為瞭解決上述問題而提出的,具體貢獻如下:
首次提出統一評測框架:MME-U 是第一個涵蓋「理解」、「生成」與「統一任務(混合模態生成)」的 benchmark,支持從不同維度系統性評估 U-MLLMs 的綜合能力。
構建覆蓋廣泛的任務體系:
-
從12個現有數據集中篩選整理,形成10大類任務,包含30個子任務
-
理解類任務涵蓋:單圖感知、多圖推理、影片理解等;
-
生成類任務涵蓋:文本生成圖像、圖像編輯、圖像轉影片等。
統一評測標準:
-
將理解任務統一轉為多選題,使用準確率作為評測指標;
-
將生成任務的多種指標標準化、歸一化,輸出統一分數,便於橫向比較。
設計五類「統一任務」,考察模型對多模態信息的協同處理能力:
-
圖像編輯與解釋:
模型需理解編輯指令並執行;
-
常識問答生成圖像:
模型需根據問答內容生成合適圖像;
-
輔助線任務:
要求模型畫出解幾何題所需的輔助線並解題;
-
找不同(SpotDiff):
在兩張圖中找並畫出差異;
-
視覺鏈式推理(Visual CoT):
邊推理邊生成下一步圖像結果。
實測分析12個主流U-MLLMs表現:包括 Janus-Pro、EMU3、Gemini 2 等,發現它們在多項任務中差異顯著,尤其是在複雜生成任務和指令理解方面仍有很大提升空間。
揭示了開放模型與閉源模型之間的差距:閉源模型如GPT-4o、Gemini 2.0 Flash在生成質量與細節還原度方面甚至優於一些專用生成模型(如 DALL·E-3);而開放模型的性能則尚顯不足。

MME-Unify不僅為統一多模態大模型的評估提供了缺失已久的標準化工具,也進一步推動了這一方向從「炫技」向「實用」邁進,是當前U-MLLMs 領域不可或缺的基準評測體系。
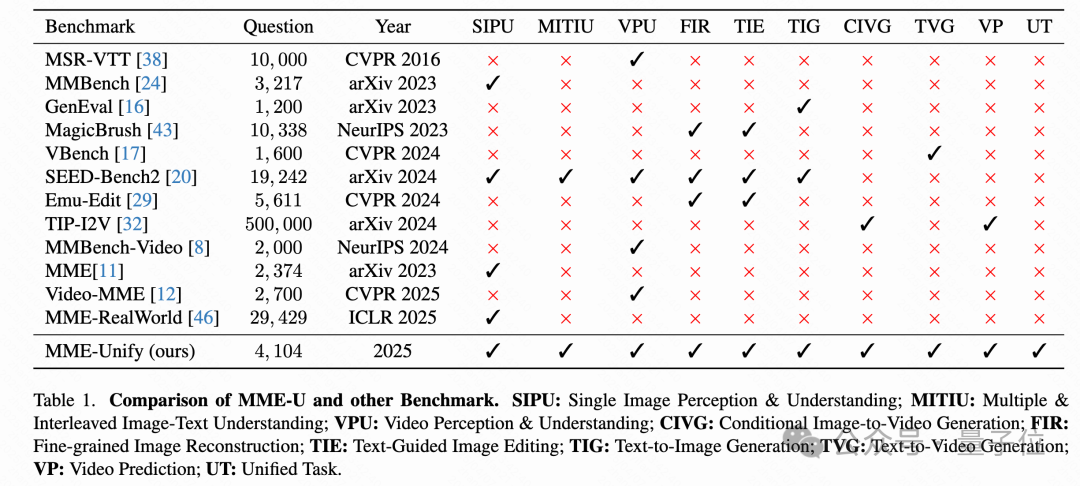
分為三個主要評測能力板塊,涵蓋數據構建、任務設計與評估策略,整體條理清晰、便於理解。
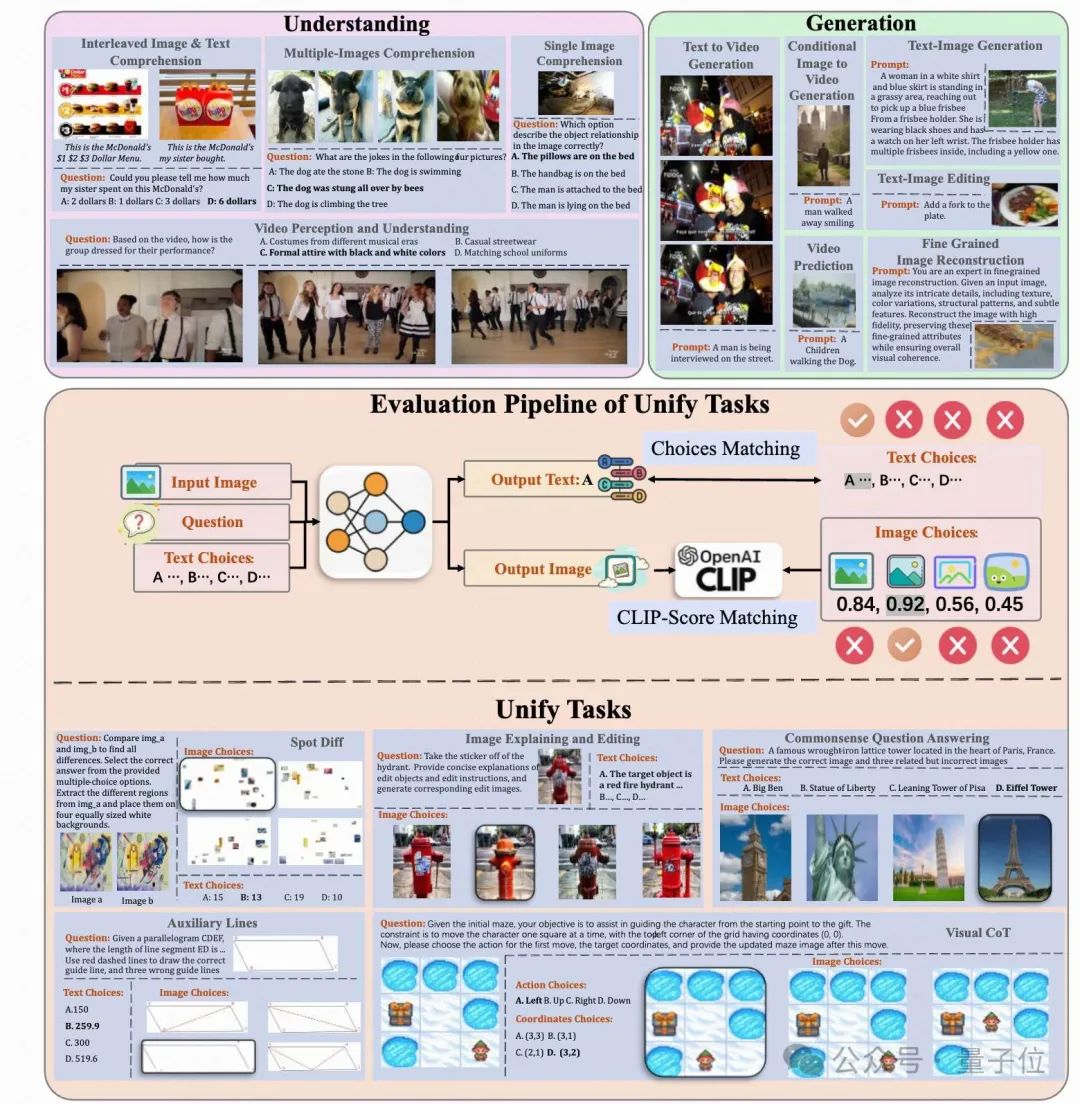
MME-Unify 評測框架設計詳解
本節介紹MME-Unify的數據構建方式、任務標註流程以及統一的評測方法。MME-U將多模態統一模型能力劃分為三大類:
– 多模態理解能力– 多模態生成能力– 統一任務能力
多模態理解(Multimodal Understanding)
數據構建
理解類任務根據視覺輸入類型劃分為三類:
– SIPU(單圖感知與理解):評估圖文對的理解能力。– MITIU(多圖/圖文交叉理解):評估模型處理多張圖和交替圖文輸入的能力。– VPU(影片感知與理解):評估模型的影片理解能力。
共收集1900個樣本,覆蓋OCR、圖表解析、空間感知、屬性/行為推理等24種任務,其中感知類任務1600條,推理類任務300條,每類子任務不少於50對 QA 樣本。
QA 標準化轉化
為統一評估標準,所有理解類任務轉為四選一多選題,干擾項與正確選項語義接近;無法處理影片的模型則使用關鍵幀,單圖模型取首圖。
評估策略
採用規則匹配法過濾答案(如 MME-Realworld),並隨機打亂選項順序以避免位置偏差。最終以平均準確率評估理解能力。
2.2 多模態生成(Multimodal Generation)
任務類型(6類)
1. FIR:圖像細節重建2. TIE:文本指導圖像編輯3. TIG:文本生成圖像4. CIVG:圖像+文本生成影片5. TVG:文本生成影片6. VP:影片預測(預測後續幀)
每類任務不少於 200 個樣本,數據來源包括 COCO、MSR-V湯臣、Pexel 等。
數據標準化流程
– 屬性統一:將 30 多種屬性統一為 Text Prompt、Src Image、Ref Image、Video 等。– 任務專屬提示語:為每類生成任務設計 prompt 模板,並統一數據格式。
評估策略
-
各任務先用專屬指標(如 CLIP-I、FID、FVD)評估;
-
再將所有指標標準化到 0–100 分數區間;
-
取標準化後的平均分作為最終生成能力分數,實現跨任務可比性。
2.3 統一任務能力(Unify Capability)
MME-Unify 精心設計了5類混合模態統一任務,每類任務包括文本與圖像雙重輸入輸出,體現 U-MLLMs 的綜合處理能力:
1. 常識問答生成圖像(CSQ)
-
任務:根據常識謎語類問題選出正確答案並生成相應圖像(如「國寶」 → 熊貓)。
-
流程:GPT-4o 生成問題,人工搜圖,模型需同時答題並作圖。
2. 圖像編輯與解釋(IEE)
-
任務:理解複雜編輯指令,生成修改圖,並解釋修改內容。
-
構建方式:
文本選項由 GPT-4o 生成,圖像干擾項由 InstructPix2Pix 生成。
模型需先解釋修改內容(文本問答),再輸出修改圖(圖像問答)。
3. 找不同任務(SpotDiff)
-
來源:SpotDiff 網站
-
模型需識別圖像對的不同區域,輸出數目和定位圖,考察空間記憶和視覺推理能力。
4. 幾何題輔助線任務(Auxiliary Lines)
-
來源:Geometry3K
-
模型需在圖上畫出解題輔助線,並作答(含邏輯和視覺兩部分),考察推理+生成整合能力。
5. 視覺鏈式推理(Visual CoT)
-
任務:通過逐步生成導航動作、坐標和迷宮圖像來走迷宮,模擬現實中的多步視覺決策過程。
-
每一步包括動作、坐標和圖像輸出,後續步驟包含歷史信息,實現逐步 reasoning。
統一任務評估策略
-
文本部分:
用 CLIP-T 相似度判斷模型生成解釋與正確選項的接近程度;或直接選擇選項。
-
圖像部分:
用 CLIP-I 計算生成圖與選項圖像的相似度,選出最高者。
acc 與 acc+:
acc:文本準確率與圖像準確率的平均值;acc+:文本和圖像都答對的樣本佔比;
對於 Visual CoT,則分別統計動作、坐標、圖像的 acc,再取平均。
最終,MME-U 總得分為理解分 + 生成分 + 統一任務分的平均值,構成系統的、全面的模型評估體系。
有趣的實驗發現總結
本文對多模態大模型(MLLMs)和統一多模態大模型(U-MLLMs)進行了系統性評測,總共涵蓋了22個主流模型。研究重點集中在三個維度:理解能力(Understanding)、生成能力(Generation)以及統一能力(Unify Capability)。評估採用MME-U評分體系,并包含多個細粒度子任務。以下為實驗中的關鍵發現與亮點總結:
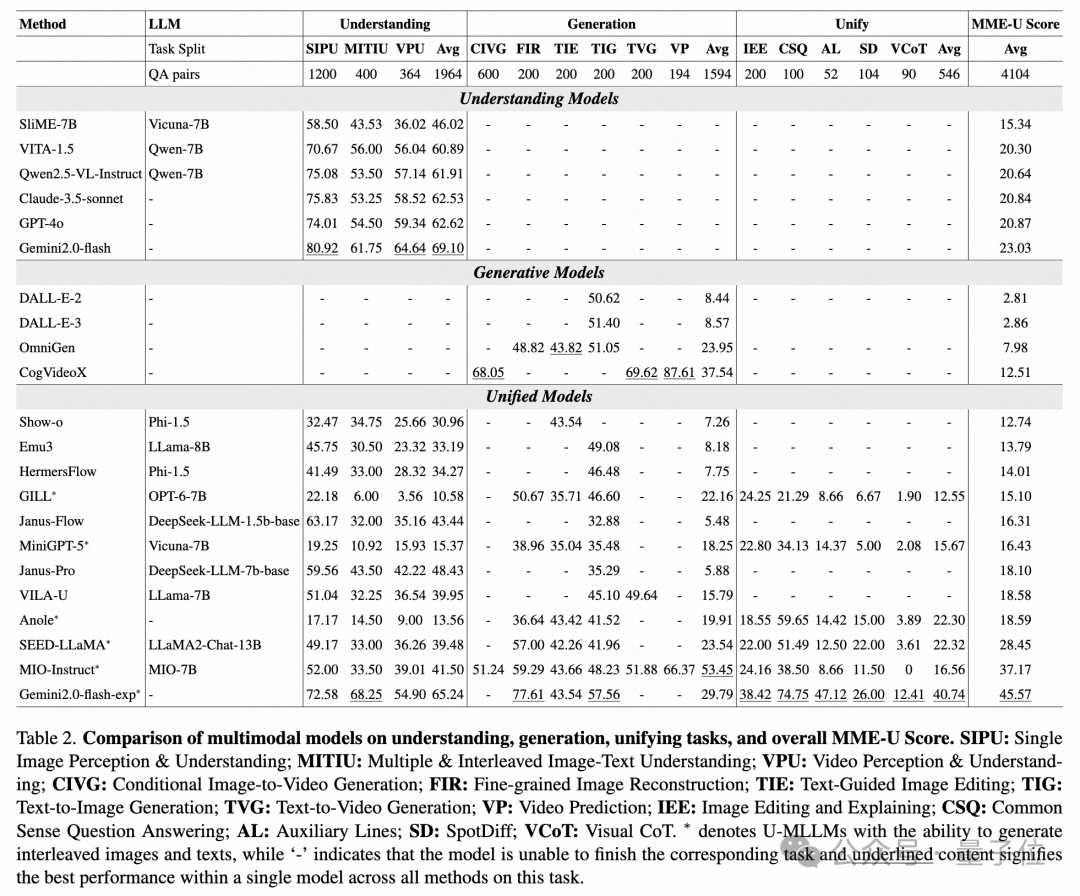
理解能力方面
-
表現最強的模型
是閉源的 Gemini2.0-flash-exp,在所有理解類任務中遙遙領先。
-
開源陣營中表現最好的是Janus-Flow與Janus-Pro
,它們採用了兩個獨立的視覺編碼器,分別用於理解與生成任務,成功避開了如VQGAN等通用 tokenizer 在圖像理解上的局限。
-
採用單一tokenizer 的模型(如 Emu3、Show-o)在理解任務上表現普遍較差
,即便模型體量相當,也難以達到Janus系列的水準。
-
MIO-Instruct展現了強大的理解能力
,其背後是海量多模態數據(包含圖像、影片、音頻)與複雜三階段訓練流程的支持,強調了數據多樣性在理解任務中的重要性。
生成能力方面
-
在圖像生成任務中,U-MLLMs的表現與專注型生成模型的差距不如理解任務那麼大。
-
舉例來說,Gemini2.0-flash-exp 在Text-to-Image任務中甚至超過了DALL·E 3 六個點,展現出強大的生成潛力。
-
多數U-MLLMs(如 EMU3、HermersFlow、GILL)在圖像生成任務的平均得分均高於48,顯示基礎圖像生成已具一定可用性。
-
不過,在影片生成任務上仍是短板。儘管如Emu3聲稱具備影片生成能力,但由於缺乏相應 checkpoint,暫時無法驗證。
-
從圖像細節還原的角度看,當前開源U-MLLMs與DALL·E等模型仍有顯著差距,尤其是在特定文本細節(如T恤號碼、背景標語等)上的還原。

統一能力方面(Unify Tasks)
-
統一任務對模型提出了更高要求——既要生成合理圖像,又要完成對應文本推理。
-
目前,開源模型中表現最好的 Anole 在簡單任務上也僅有約60%的準確率
,在複雜統一任務上幾乎沒有模型超過30%準確率。
-
在視覺鏈式推理(Visual CoT)任務中,無一模型能夠成功完成多步推理與圖像生成結合的完整流程。
-
分析顯示,統一任務對模型的多模態交叉能力提出了極高要求,目前仍是行業技術瓶頸。
深入分析與趨勢觀察
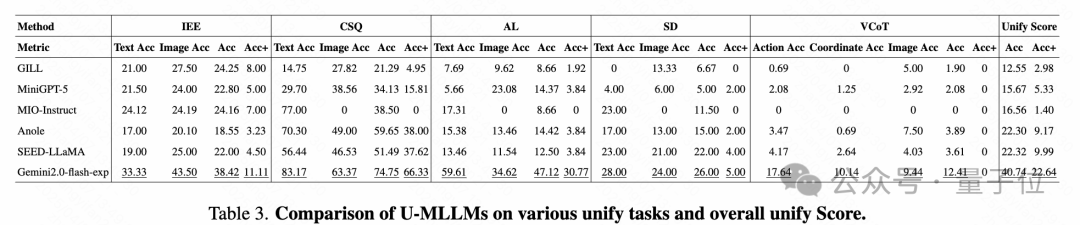
-
當前模型在基礎能力(理解/生成)與統一能力之間普遍存在 「性能權衡困境」:
例如,MiniGPT-5、GILL、Anole 在統一任務設計上更激進,但犧牲了基礎理解與生成能力,導致整體分數偏低。
而如MIO-Instruct雖然在基礎能力上表現優秀,但在圖文交錯生成的統一任務中表現不佳。
這種表現差異提示:現有訓練範式未能有效整合基礎任務與跨模態任務的學習目標,可能需要重新設計對齊策略或任務混合訓練流程。
總結
整體來看,U-MLLMs雖然展示了多模態統一任務的潛力,但距離實際可用仍有明顯距離。特別是在如何協調理解與生成、單步與多步、圖文協同等維度,仍存在諸多技術挑戰。MME-Unify提供了一套系統性測評框架,並量化了主流模型的能力上限,為未來模型設計提供了清晰參照與方向指引。
項目地址:
https://mme-unify.github.io
一鍵三連「點讚」「轉發」「小心心」
歡迎在評論區留下你的想法!