英偉達突然開源新模型,直逼DeepSeek-R1成推理天花板
Llama 4誕生不過3天,反手就被超越了。
剛剛,英偉達官宣開源「超大杯」Llama Nemotron推理模型,共有253B參數,基於Llama-3.1-405B微調而來。
在多項基準測試中,Llama Nemotron一舉擊敗了兩款Llama 4模型。而且僅用一半的參數,性能直逼DeepSeek R1。
尤其是,在複雜數學推理AIME(2024/2025)、科學推理GPQA Diamond、編碼LiveCodeBnech中,新模型取得SOTA。
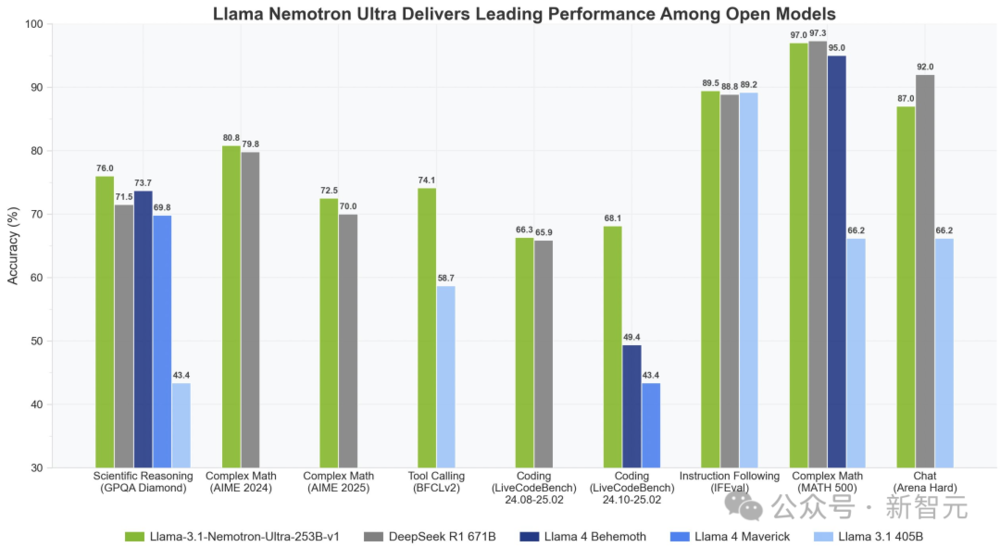
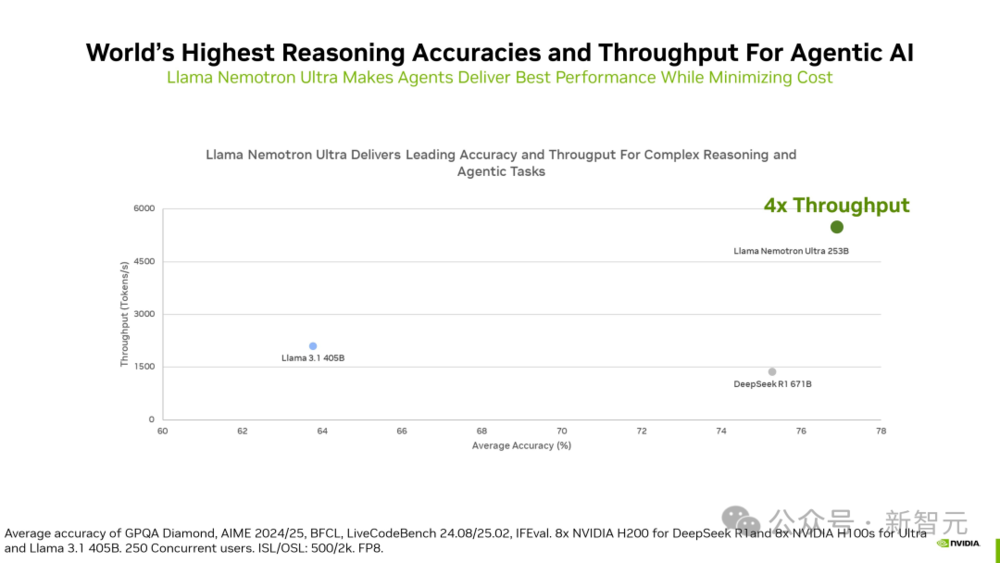
相比DeepSeek R1 671B,它的推理吞吐量提升了4倍。
Llama-3.1-Nemotron-Ultra-253B-v1經過後期訓練,專注於推理、人類聊天偏好和任務,如RAG(檢索增強生成)和工具調用。
它能支持128Ktoken的上下文長度,且能夠在單個8xH100芯片節點上進行推理。
這個模型之所以能達到如此強的推理性能,是因為在模型精度和效率之間取得了良好平衡,讓效率(吞吐量)直接轉化為成本節省。
通過採用一種新穎的神經架構搜索(NAS)方法,研究者大大減少了模型的內存佔用,從而支持更大的工作負載,並減少了在數據中心環境中運行模型所需的GPU數量。
現在,該模型已準備好支持商用。
Llama Nemotron超大杯上線,推理開源天花板
今年3 月,英偉達首次亮相了Llama Nemotron系列推理模型。
它一共包含三種規模:Nano、Super 和 Ultra,分別針對不同場景和計算資源需求,供開發者使用。
Nano
Nano(8B)基於Llama 3.1 8B微調而來,專為PC和邊緣設備而設計。
如下圖,Llama Nemotron Nano在GPQA Diamond、AIME 2025、MATH-500、BFCL、IFEval、MBPP和MTBench等多項基準測試中,展現出領先性能。
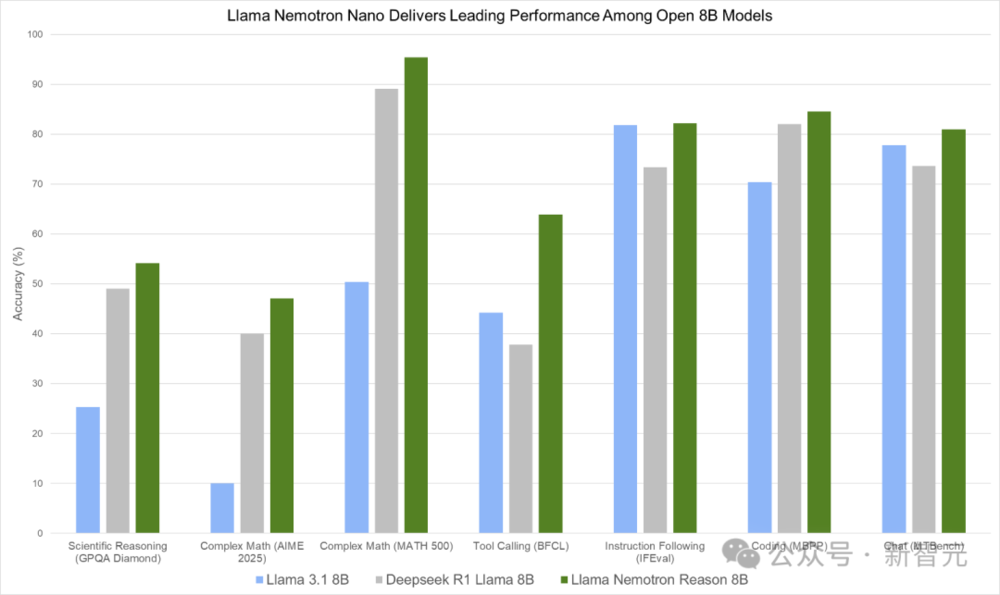 圖 1. Llama Nemotron Nano在一系列推理和智能體基準測試中提供同類最佳性能
圖 1. Llama Nemotron Nano在一系列推理和智能體基準測試中提供同類最佳性能Super
Super(49B)是從Llama 3.3 70B蒸餾而來,針對數據中心GPU進行了優化,便可實現最高吞吐量下的最佳準確性。
下圖顯示,Llama Nemotron Super在GPQA Diamond、AIME 2024/2025、MATH-500、MBPP、Arena Hard、BFCL和IFEval等多項基準測試,取得了最優性能。
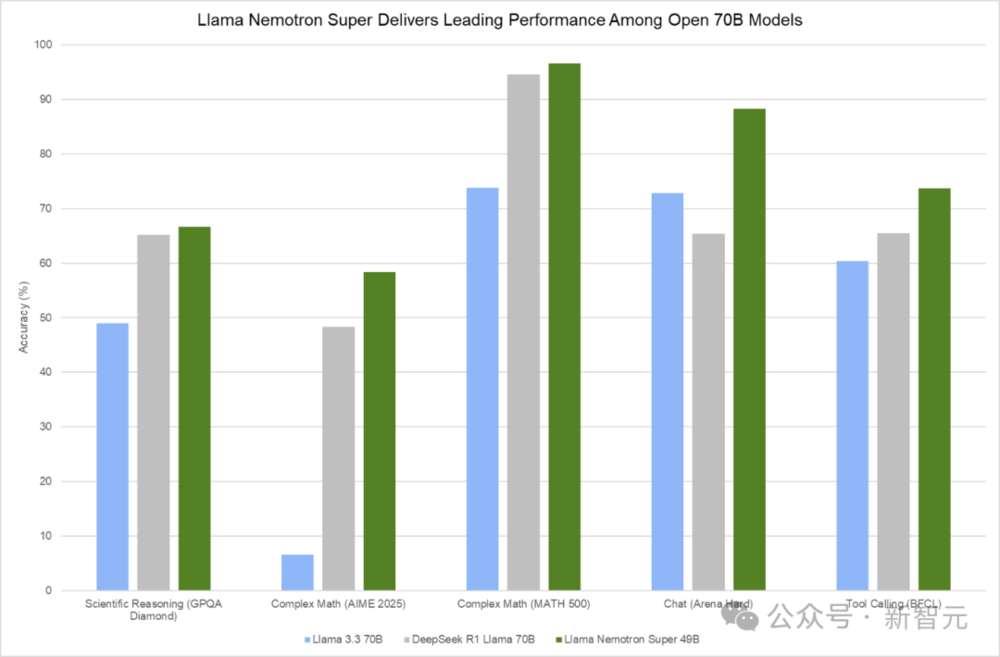 圖 2. Llama Nemotron Super在一系列推理和智能體基準測試中提供領先性能
圖 2. Llama Nemotron Super在一系列推理和智能體基準測試中提供領先性能Ultra
Ultra(253B)是從Llama 3.1 405B蒸餾而來,專為多GPU數據中心打造最強智能體而設計,
圖表顯示,採用FP8精度的Llama Nemotron Ultra 253B在GPQA、Complex Math、BFCL、LiveCodeBench以及IFEval上表現出色。
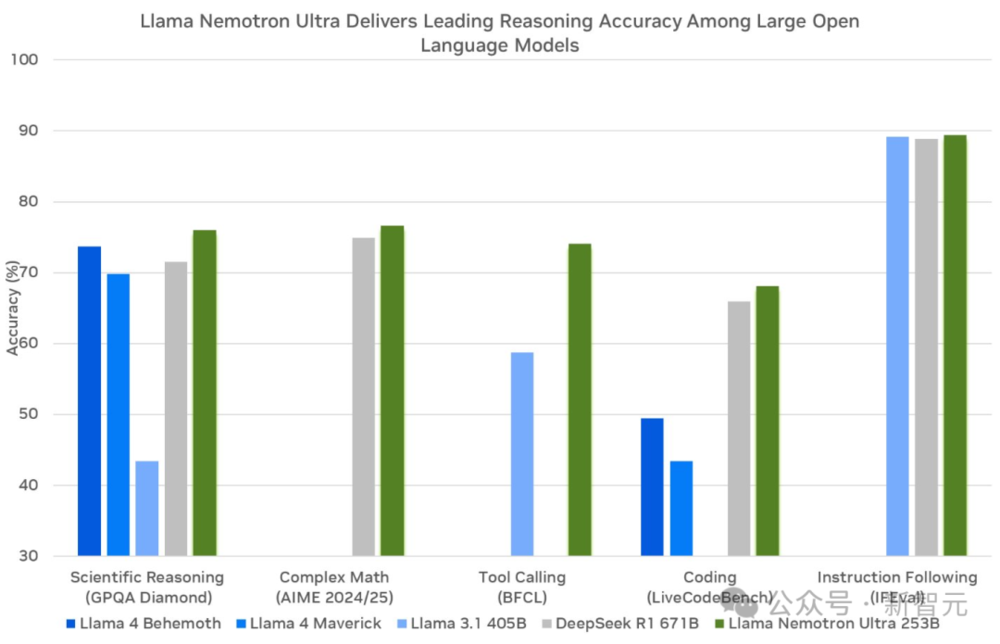 圖3. FP8精度的Llama Nemotron Ultra提供同類最佳的推理和智能體基準測試性能
圖3. FP8精度的Llama Nemotron Ultra提供同類最佳的推理和智能體基準測試性能Llama Nemotron家族模型均是基於開源 Llama構建,並採用英偉達審核後的數據集合成數據,因此全部可以商用。
秘密武器:測試時Scaling
英偉達是如何訓練出性能如此卓越的模型的?背後的關鍵,就在於「測試時scaling」(或稱推理時scaling)和「推理」。
測試時scaling這項技術,會在模型推理階段投入更多計算資源,用以思考和權衡各種選項,來提升模型響應質量,這就使得模型在關鍵下遊任務上的性能得以提升。
對問題進行推理是一項複雜的任務,而測試時投入的計算資源,正是使這些模型能達到前述需推理水平的關鍵因素。
它能讓模型在推理期間利用更多資源,開闢更廣闊的可能性空間,從而增加模型建立起必要關聯、找到原本可能無法獲得的解決方案的機率。
儘管「推理」和「測試時scaling」對智能體工作流如此重要,但有一個共同問題,卻普遍困擾著如今最先進的推理模型:
開發者無法選擇何時讓模型進行推理,也就是說,做不到在「推理開啟」和「推理關閉」之間自由切換。
而Llama Nemotron系列模型則攻破了這一難題,用「系統提示詞」來控制推理開關!
如何構建?
Llama 3.3 Nemotron 49B Instruct以Llama 3.3 70B Instruct為基礎模型,經歷了一個廣泛的後訓練階段後,不僅模型尺寸減小,還讓原始能力保留甚至增強了。
三個後訓練階段如下。
1. 通過神經架構搜索 (NAS) 和知識蒸餾進行蒸餾。
2. 監督微調:使用了由英偉達創建的600億Token 合成數據(代表了所生成的 3000萬樣本中的400萬),以確保在「推理關閉」和「推理開啟」兩種模式下內容的高質量。在此階段,團隊利用了NVIDIA NeMo框架,有效且高效地擴展了後訓練流程。
3. 強化學習:這個階段是利用NVIDIA NeMo完成的,模型的對話能力和指令遵循性能得以增強,從而在廣泛的任務中都能提供高質量的響應。
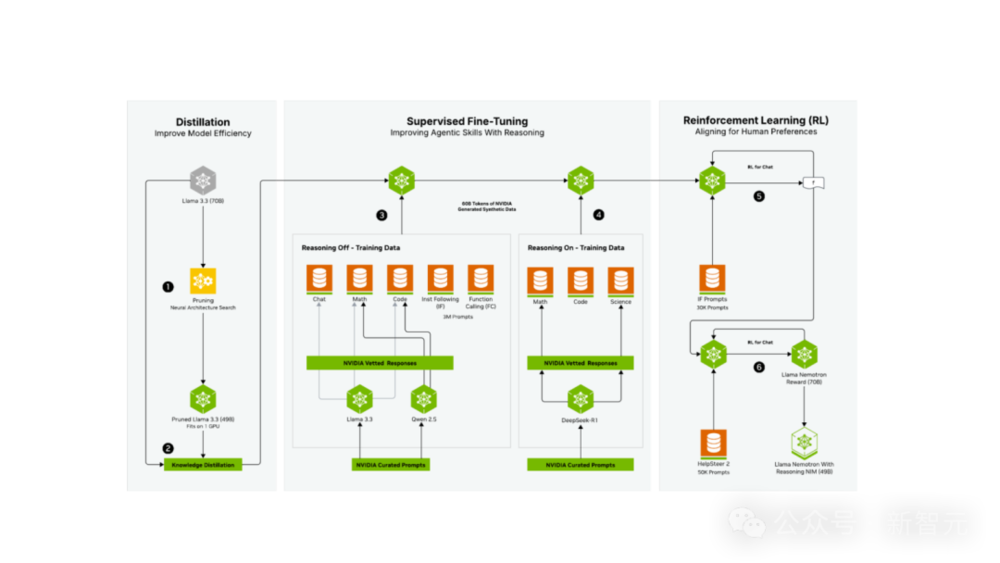
第一個階段(步驟1和2)已在神經架構搜索 (NAS) 技術報告中詳細闡述。
簡而言之,該階段可被視為通過多種蒸餾和NAS方法,依據特定的旗艦硬件,將各模型的參數量「調整至合適尺寸」,從而達到預選的最優值。
模型後訓練的第二個階段(步驟3和4)則涉及由合成數據驅動的監督微調,目的在於實現幾個關鍵目標。
首要目標,就是提升模型在多種任務上的非推理性能。
後訓練流程的這一環節(步驟3)利用了團隊精選的提示詞,通過基線模型 (Llama 3.3 70B Instruct) 以及Qwen2.5 7B Math和Coder模型生成合成數據。
這些數據隨後經過團隊的精選與審核,用於增強模型在聊天、數學和代碼任務上的「推理關閉」模式下的性能。
同時,團隊也投入大量精力,確保在此階段,「推理關閉」模式下的指令遵循和函數調用性能達到同類最佳水平。
第二個目標(步驟4)是通過在精選的DeepSeek-R1數據(僅限數學、代碼和科學領域)上進行訓練,打造出同類最佳的推理模型。
每一個提示詞和響應都經過嚴格篩選,確保在推理能力增強過程中僅使用高質量數據,並輔以NVIDIA NeMo框架的支持。這就能確保團隊可以選擇性地從 DeepSeek-R1中蒸餾出它在優勢領域所具備的強大推理能力。
「推理開啟」/「推理關閉」兩種模式的訓練(步驟3和4)是同時進行的,兩者唯一的區別在於系統提示詞。
這意味著,最終生成的模型既能作為推理模型運行,也能作為傳統的LLM運行,並通過一個開關(即系統提示詞)在兩種模式間切換。
這種設計,使得組織機構能夠將單個尺寸適宜的模型同時用於推理任務和非推理任務。
最後一個階段(步驟5和6)則採用了強化學習來更好地對齊用戶意圖與期望。
模型首先利用REINFORCE算法和基於啟髮式的驗證器,針對指令遵循和函數調用這兩個任務進行RL以提升性能(步驟5)。
隨後,採用RLHF技術,結合HelpSteer2數據集和NVIDIA Llama 3.1 Nemotron獎勵模型,對最終模型進行面向聊天應用場景的對齊(步驟6)。
最終,這些後訓練步驟打造出了同類最佳的推理模型,並且通過提供在兩種範式(推理與非推理)間切換的機制,確保了模型在函數調用和指令遵循方面的性能不受影響。
模型則能高效支持智能體AI工作流中的各個,同時還能保持針對旗艦級英偉達硬件優化的最佳參數量。
性能刷新SOTA,吞吐量最高5倍提升
Llama Nemotron Super
Llama Nemotron融合了DeepSeek-R1等模型強大的推理能力,以及Llama 3.3 70B Instruct具備的強大世界知識與對可靠工具調用及指令遵循,最終打造出在關鍵智能體任務上表現領先的模型。
結果顯示,Llama Nemotron 49B準確性最高,且吞吐量提升達5倍。
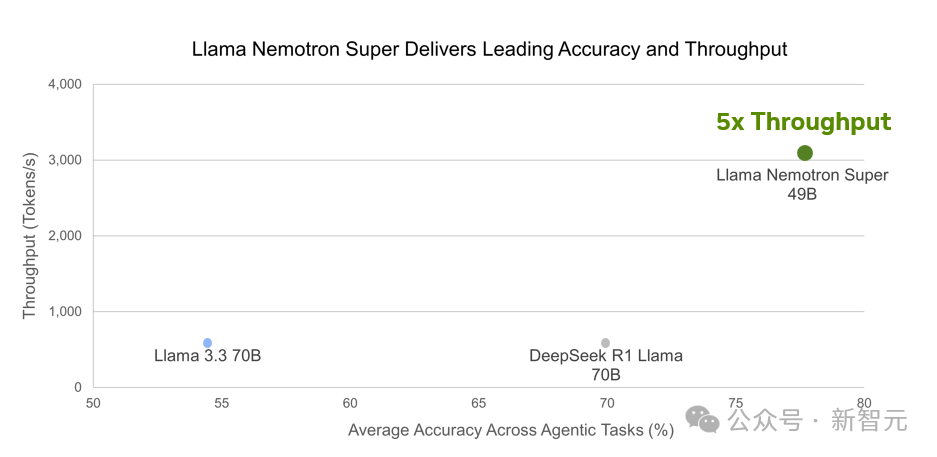 圖 5. Llama Nemotron Super為智能體任務提供了最高的準確性和吞吐量,從而降低了推理成本
圖 5. Llama Nemotron Super為智能體任務提供了最高的準確性和吞吐量,從而降低了推理成本Llama Nemotron Ultra 253B
Llama Nemotron Ultra總參數量僅為253B,但其推理性能已達到甚至超越DeepSeek-R1等頂級開放推理模型。
與此同時,憑藉優化的模型尺寸實現了顯著更高的吞吐量,並保留了優秀的工具調用能力。
這種卓越推理能力與毫不妥協的工具調用能力的結合,使其成為智能體工作流領域的同類最佳模型。
除了應用Llama Nemotron Super的完整後訓練流程外,Llama Nemotron Ultra還額外經歷了一個專注的RL階段,旨在進一步增強其推理能力。
結果表明,相較於DeepSeek-R1 671B,Llama Nemotron Ultra的吞吐量提升高達4倍,並且在GPQA、AIME 2024、AIME 2025、BFCL、LiveCodeBench、MATH500和IFEval的等權重平均準確性方面取得最高分。
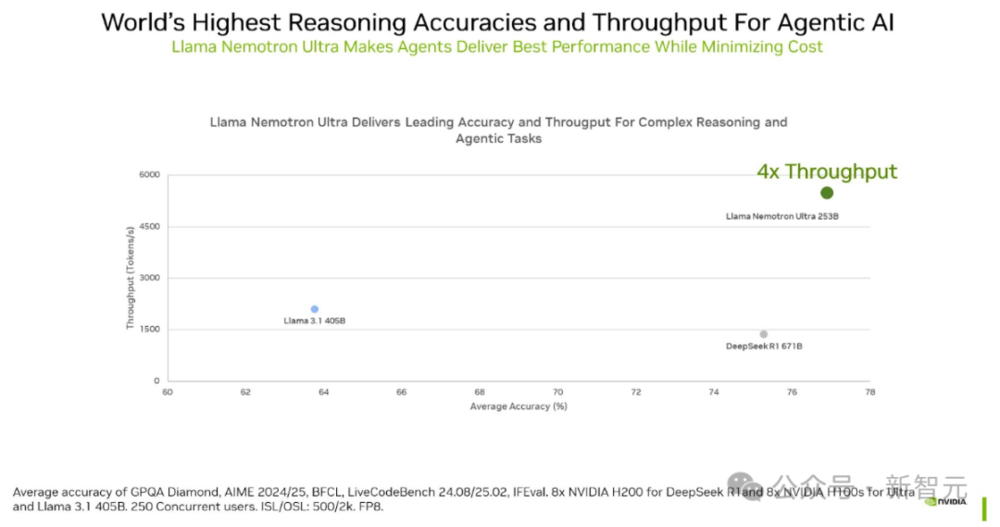 圖6. Llama Nemotron Ultra同時提供卓越的準確性和驚人的吞吐量
圖6. Llama Nemotron Ultra同時提供卓越的準確性和驚人的吞吐量打造多智能體系統,搞掂複雜任務
由Llama 3.3 Nemotron 49B Instruct驅動的多智能體協作系統,在Arena Hard 基準測試中,拿下了驚豔的92.7分。
傳統的測試時計算scaling方法,大多聚焦於那些有明確答案的問題,比如數學題、邏輯推理、編程競賽。
現實中,許多重要任務缺乏可驗證的解決方案,比如提出創新研究思路、撰寫學術論文,或是為複雜的軟件產品開發有效的交付策略。
這些問題,往往更具挑戰性,也更貼近實際需求。
Llama Nemotron測試時計算scaling系統正是為此而生,它模仿了人類解決複雜問題寫作模式,通過以下幾個步驟實現:
1. 集思廣益:針對問題初步構思一個或多個解決方案。
2. 獲取反饋:就初步方案徵求朋友、同事或其他專家的意見。
3. 編輯修訂:根據收集到的反饋對初步方案進行修改。
4. 擇優選取:在整合修訂意見後,選出最具潛力的最終解決方案。
這種方法使得測試時計算scaling技術能夠應用於更廣泛的通用領域任務。
要形象地理解這個多智能體協作系統,可以將其類比為一個團隊協同工作,為一個沒有標準答案的開放式問題尋找最佳解決方案。
與之相對,「長思考」則好比訓練單個人深度、持久地鑽研一個問題,最終得出一個可以對照標準答案進行驗證的結果。
因此,多智能體系統強大之處在於,不僅提升解決複雜問題效率,還能通過協作挖掘更多可能性。
參考資料:
https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
Build Enterprise AI Agents with Advanced Open NVIDIA Llama Nemotron Reasoning Models
https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1?ncid=so-twit-273200
本文來自微信公眾號:新智元,作者:新智元