用梯度下降求解整數規劃,中科大等提出無監督訓練整數規劃求解器新範式 | ICLR 2025 Spotlight
DiffILO團隊 投稿
量子位 | 公眾號 QbitAI
無監督學習訓練整數規劃求解器的新範式來了。
中國科學技術大學王傑教授團隊(MIRA Lab)提出了一種全新的整數規劃求解方法——DiffILO(Differentiable Integer Linear Programming Optimization),相關論文已被人工智能頂級國際會議ICLR 2025接收為Spotlight。
結果顯示:與現有主流的監督學習方法對比,DiffILO不僅顯著加快訓練速度,還能生成更高質量的可行解。

引言:用機器學習解ILP,為何如此困難?
整數線性規劃(ILP) 是組合優化中最基礎也是最關鍵的一類問題,廣泛應用於工業調度、物流運輸、網絡規劃、芯片布圖等現實場景。然而 ILP 的求解非常困難 —— 變量離散、可行域複雜、搜索空間指數爆炸,本質上屬於 NP 難問題。
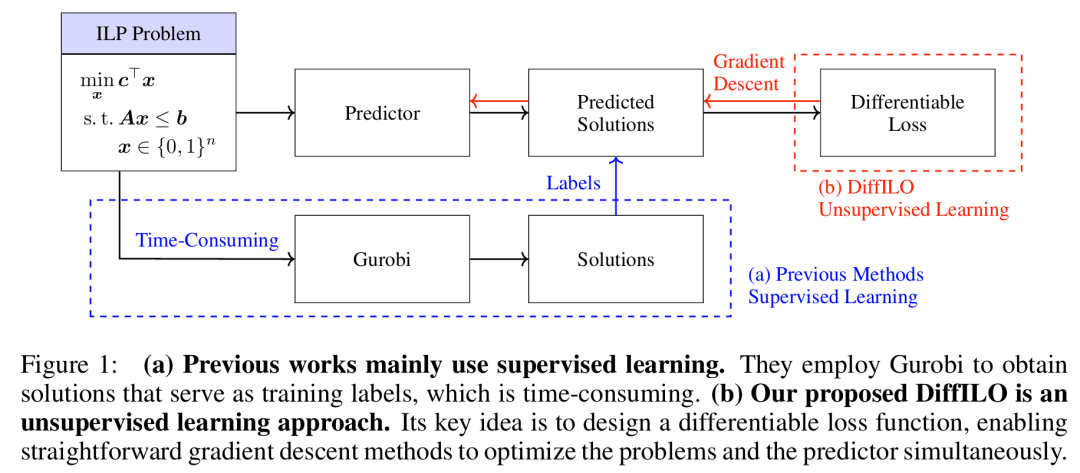
近年來,機器學習逐漸被引入這一過程,嘗試通過數據驅動的方式加速求解器。但當前主流做法大多依賴監督學習:先用傳統求解器(如Gurobi)生成一批解作為標籤,然後訓練模型去「模仿」這些解。這種做法存在兩大瓶頸:
-
高昂的訓練成本:每個樣本都需調用求解器生成標籤;
-
訓練目標與測試目標不一致:只優化預測誤差,無法保障最終解的可行性與質量。
有沒有可能完全擺脫標籤依賴,直接讓模型「自己」學會求解ILP問題?
答案是:可以!該論文提出了DiffILO方法,可以用梯度下降來「解整數規劃」!
核心方法:DiffILO是如何做到的?
DiffILO,全稱 Differentiable Integer Linear Programming Optimization,是一種無監督、端到端、可微分的ILP求解新範式。它的核心創新是將離散、帶約束的整數規劃問題,轉化為連續、可微、無約束的問題,並借助深度學習模型來直接預測高質量解。
方法流程如下圖所示:
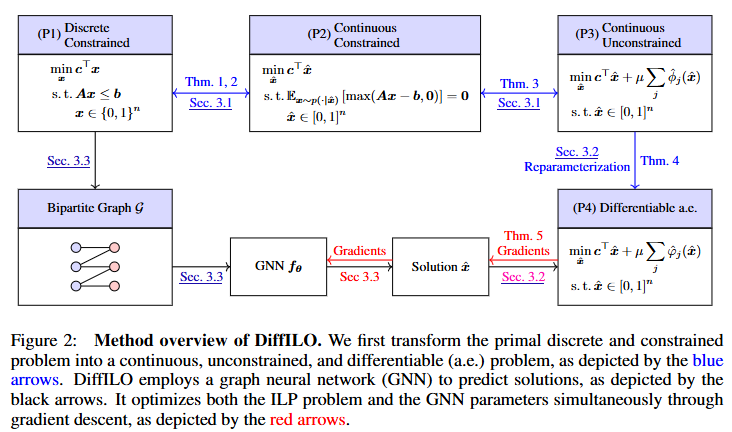
方法大致可以分為三個步驟:
Step 1:從離散到連續——概率建模與約束期望化
ILP問題的形式通常如下:
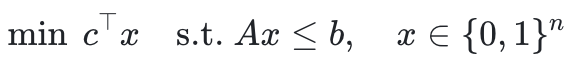
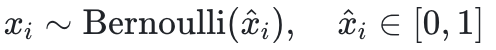
其中是需要優化的概率值。
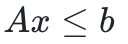 被轉化為「期望約束違背為零」:
被轉化為「期望約束違背為零」: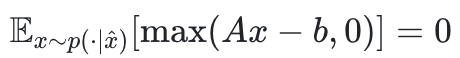
這種期望建模方式有兩個好處:
-
仍能保留原問題的最優解結構;
-
易於被懲罰函數進一步轉化為無約束形式。
Step 2:從約束到目標——懲罰函數與可微重參數化
該方法使用懲罰函數法將上述期望約束合入目標函數:
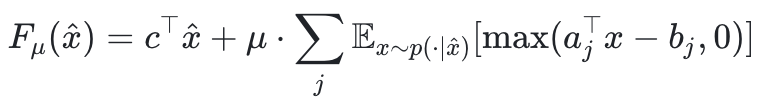
但由於該函數的采樣項並不可微,DiffILO採用了Gumbel-Softmax + 重參數技巧,將離散采樣近似為一個連續可導的函數:
-
使用

,實現對伯努利的可微近似;
-
使用

保留組合結構;
-
梯度通過
回傳,值通過
保留,兼顧
「可微」和「離散」的雙重需求。
最終得到一個幾乎處處可導的目標函數,可以直接用梯度下降
進行優化。
Step 3:從圖中學——GNN建模與端到端訓練
每個ILP實例本質上可以被表示為一個二分圖:左邊是變量,右邊是約束,邊代表變量出現在對應約束中。
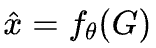 ,再接入一個MLP進行最終預測。
,再接入一個MLP進行最終預測。訓練過程完全無監督,目標是最小化上述可微目標函數
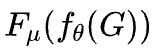
。還引入了三種訓練技巧來增強穩定性:
-
樣本歸一化:對目標函數做歸一處理,適應不同實例規模;
-
餘弦退火:自適應學習率調度;
-
懲罰係數調控:動態調整μ,平衡解質量與可行性。
實驗結果
作者在多個標準 ILP 數據集(如 Set Covering、Independent Set、Combinatorial Auction)上進行了系統評估。結果顯示:與現有主流的監督學習方法對比,DiffILO不僅顯著加快訓練速度,還能生成更高質量的可行解,並且在與Gurobi、SCIP結合使用時,顯著提升求解器的整體性能。
作者介紹
本論文作者耿子介是中國科學技術大學MIRA實驗室2022級博士生,師從王傑教授。此前,他於2022年畢業於少年班學院,取得數學與應用數學專業學士學位。他的主要研究方向包括機器學習在運籌優化與芯片設計等領域的應用、大語言模型等。他在NeurIPS、ICML、ICLR等人工智能頂級會議上發表論文十餘篇,其中五篇論文入選Oral/Spotlight。他曾獲2024年度國家獎學金;曾兩次獲得丘成桐大學生數學競賽優勝獎;曾在微軟亞洲研究院實習,獲得「明日之星」稱號;曾多次擔任頂會審稿人,獲評NeurIPS 2023 Top審稿人;參與創辦南京真則網絡科技有限公司。
論文地址:
openreview.net/pdf?id=FPfCUJTsCn