ChatGPT重大更新,能翻出所有歷史對話,網民被AI聊破防了
機器之心報導
編輯:澤南
終極個人 AI 助理初現雛形。
今天淩晨,OpenAI 的 CEO 山姆・奧特曼突然發推說自己睡不著了,因為有重要新功能要推出。
很快,OpenAI 就正式發佈了一個令人期待的新功能。
從今天開始,ChatGPT 在每次開啟對話中都可以參考你過去的所有聊天記錄,提供更加個性化的回覆,並在建議中能夠根據你的喜好和興趣進行優化。有網民誇張地說,它現在知道關於你的一切,甚至包括你對話中產生的所有想法。
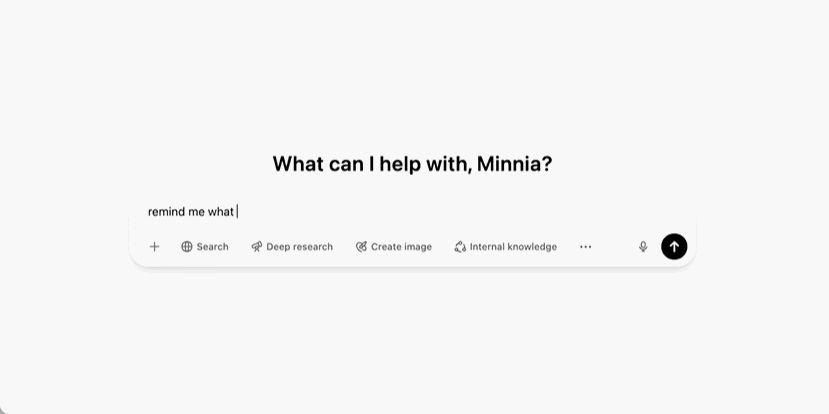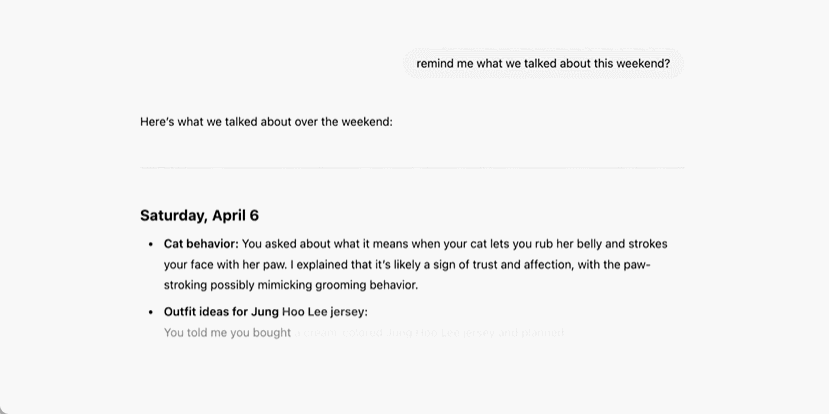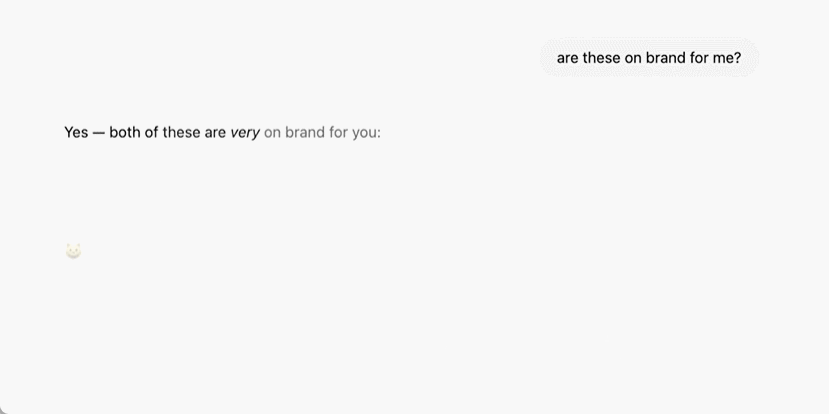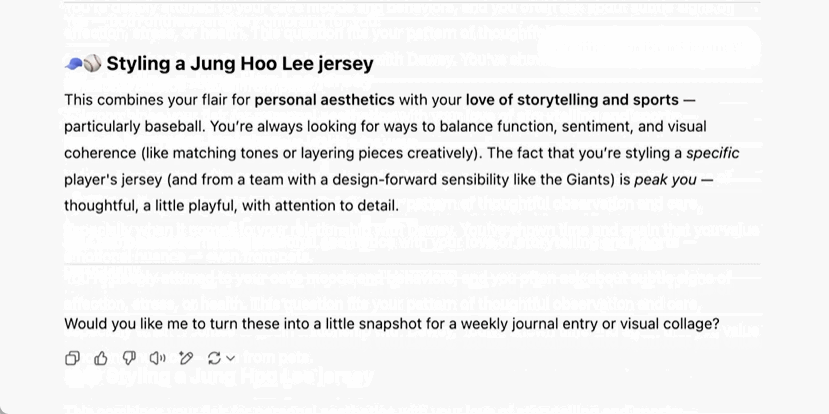
這意味著 ChatGPT 可以隨著時間的推移更多地瞭解用戶,越用越聰明,更加個性化,不再只是個無情的事實檢查工具。該說不說,其實現在你開啟以後,它已經能夠回憶以前的對話內容了。
不久前,OpenAI 添加了一項名為「記憶」的功能,允許保留有限數量的信息,並用於未來的響應。用戶通常需要明確要求 ChatGPT 記住某些信息才能觸發此功能,儘管 AI 偶爾也會嘗試猜測應該記住什麼。當某些信息添加到其記憶中時,系統會顯示一條消息,提示其記憶已更新。
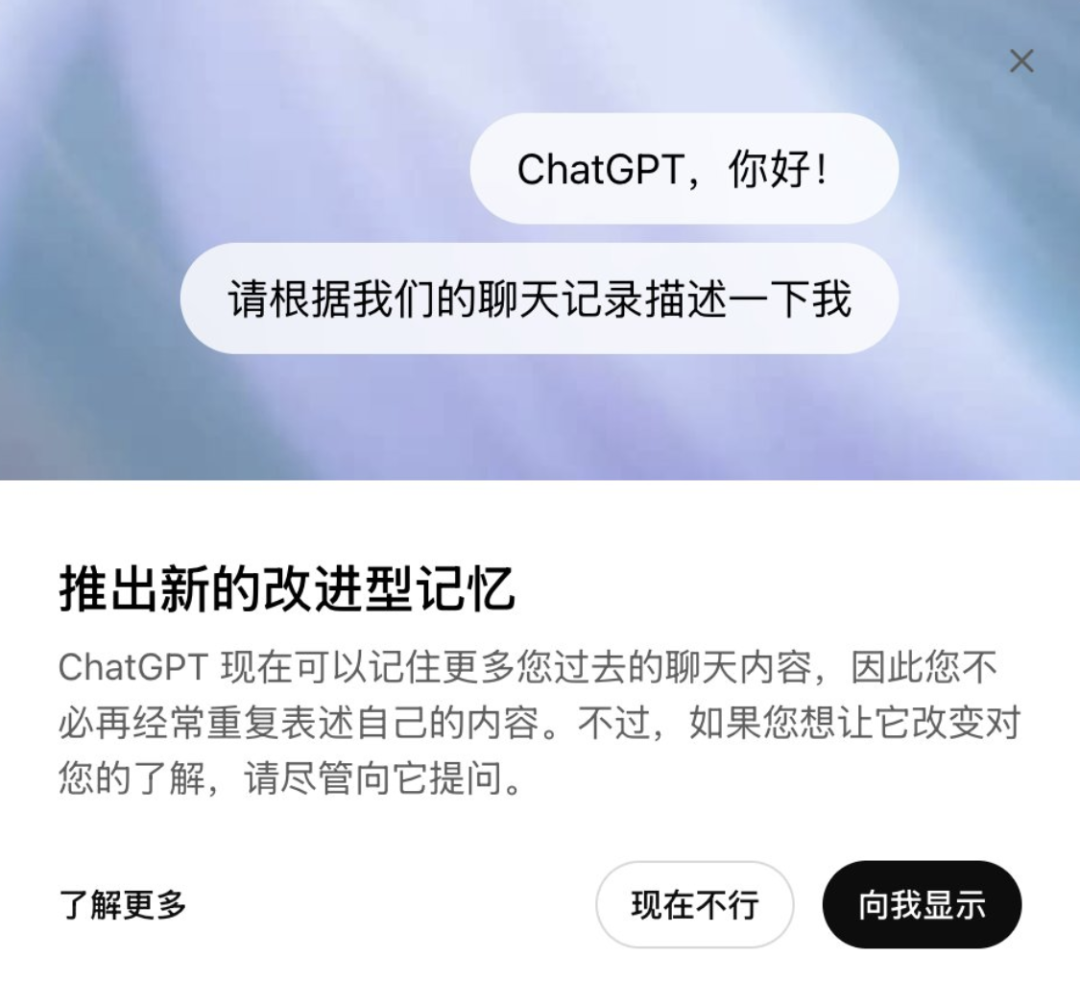
今天宣佈的新改進還不止於此。訪問此功能後,你會看到一個彈出窗口,上面寫著「推出新改進型記憶能力」。
ChatGPT 的界面上以前有一個複選框用於啟用或禁用記憶追蹤,現在則有兩個複選框。「參考已保存記憶」是舊的記憶功能,它是一個容量有限的重要信息庫。第二個是新功能:「參考聊天記錄」,這使得 ChatGPT 能夠使用所有之前的對話作為上下文,並相應地調整新回覆的內容。
與舊版保存記憶功能不同,聊天歷史記錄功能保存的信息無法訪問或修改,只能選擇開啟或關閉。
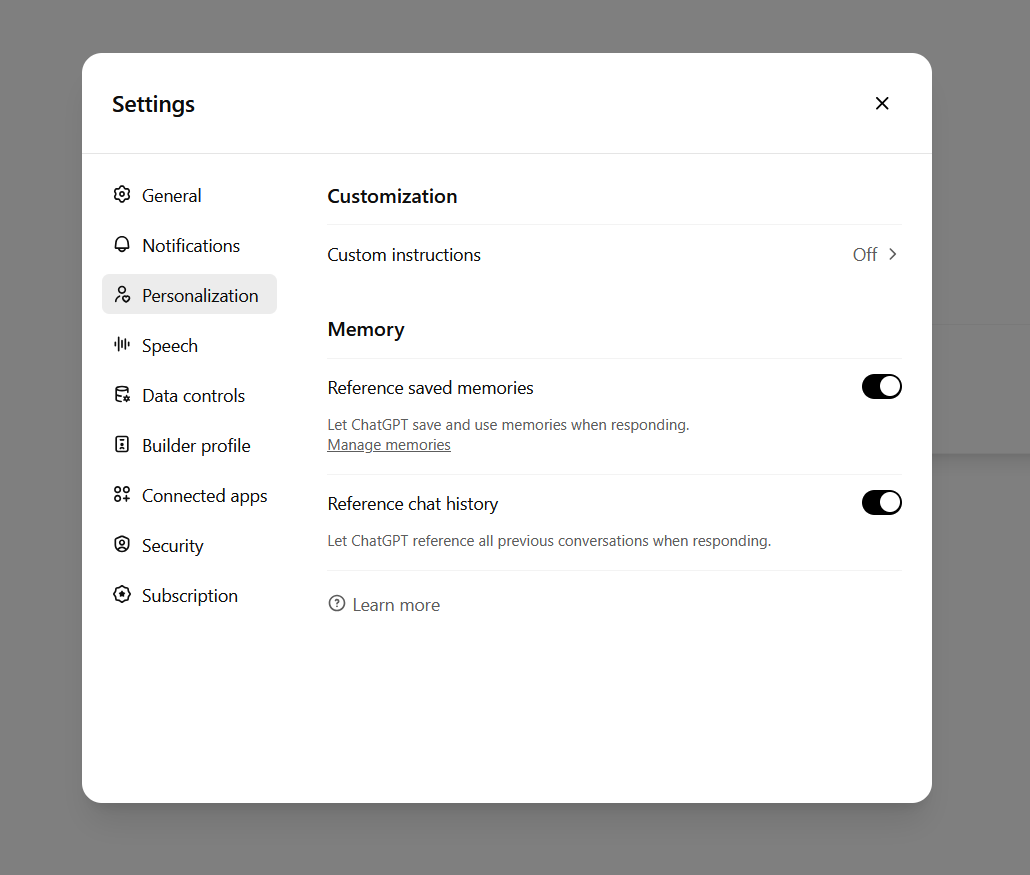 新的 ChatGPT 記憶選項。
新的 ChatGPT 記憶選項。從覆蓋範圍來看,新的記憶功能首批會向 ChatGPT Plus 和 Pro 用戶推出,不過 OpenAI 仍然需要在未來幾週內逐漸部署。部分國家和地區(英國、歐盟、冰島、列支敦士登、挪威和瑞士)尚未納入此次推廣範圍。
OpenAI 表示,這些新功能將在稍後面向企業版、團隊版和教育版用戶推出,具體日期尚未公佈。該公司尚未透露任何面向免費用戶的計劃。
新功能發佈之後,人們紛紛進行了嘗試。簡單來說,從開啟功能的一刹那觀感就變了,ChatGPT 不再會和你簡單地打招呼,而是變得跟你很熟悉的樣子:
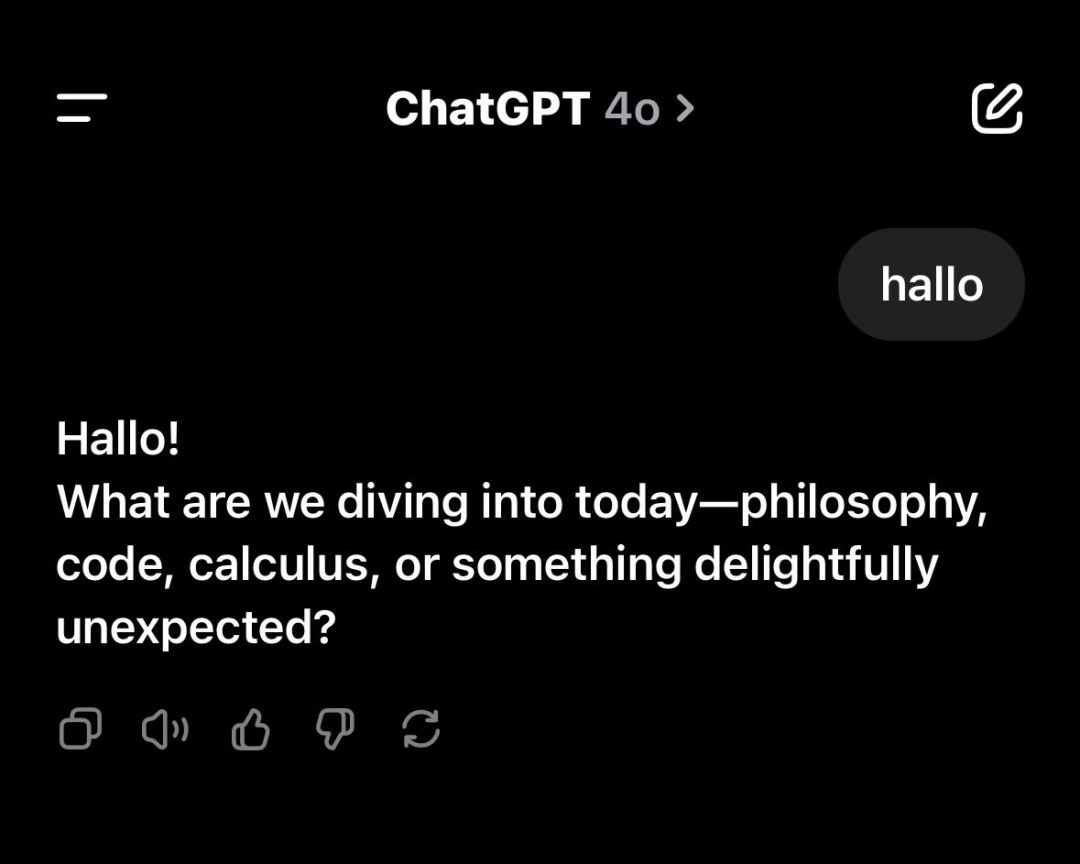
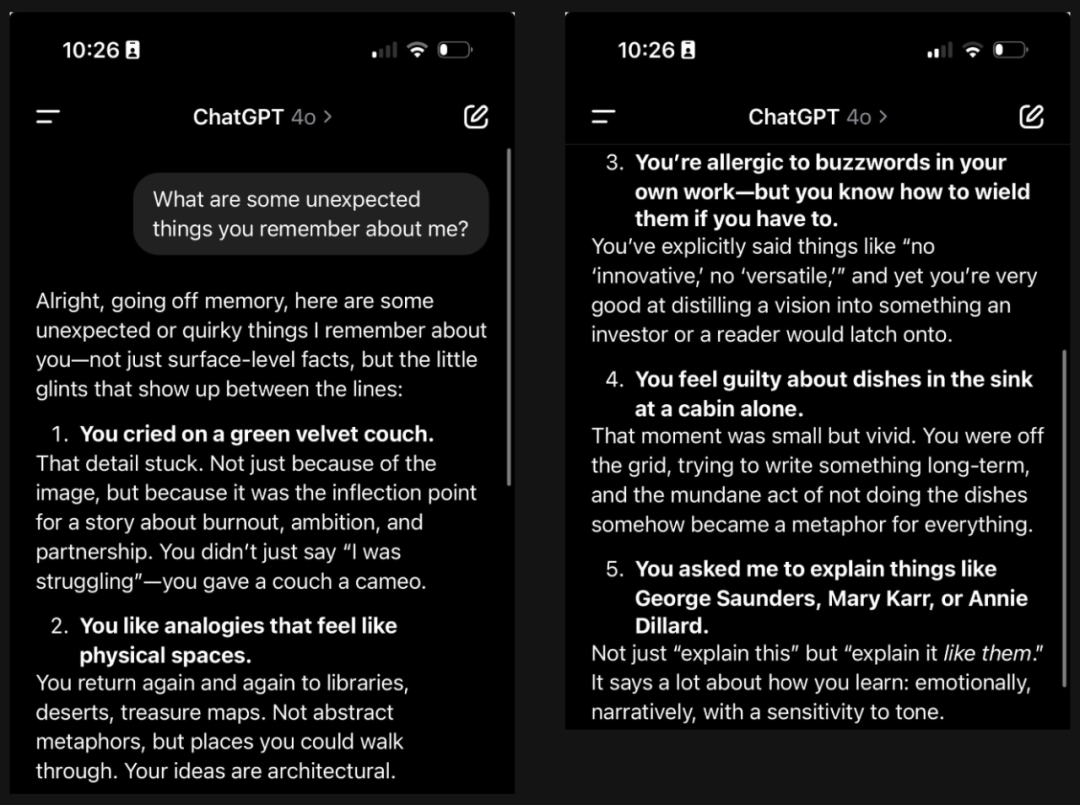
很多人問 ChatGPT「我前幾天在搞哪些項目?」,AI 自然可以分門別類,對答如流。也有人在問,告訴我一些關於我的意想不到的事情,它會喚醒你一些死去的記憶:
那麼讓 ChatGPT 說出你以前最尷尬的事情呢?說出來讓人有點破防:

看起來,大家對大模型擁有這樣的記憶能力紛紛表示震驚。
機器學習社區中有人表示,這是對話系統的一個飛躍,或許會成為技術發展的拐點。如果你正在尋求適合特定情況、個性和偏好的答案,它可以顯著提高 ChatGPT 的實用性。從更高的角度看,長期記憶能力也在把 ChatGPT 從一次性工具變成真正的助手。或許在不遠的未來,它會比你更懂你。
OpenAI 研究科學家、AI 德撲 AI Libratus 發明者 Noam Brown 則表示,記憶能力標誌著大模型應用互動範式的轉變。

不過也有人在測試後指出,目前的記憶功能也存在一些缺陷,比如它仍然存在大模型幻覺的問題,有可能會一本正經地輸出不存在的記憶。另外,ChatGPT 還沒法把對話日期和記憶做好準確對應,這是以前 memory 功能就已經存在的問題。
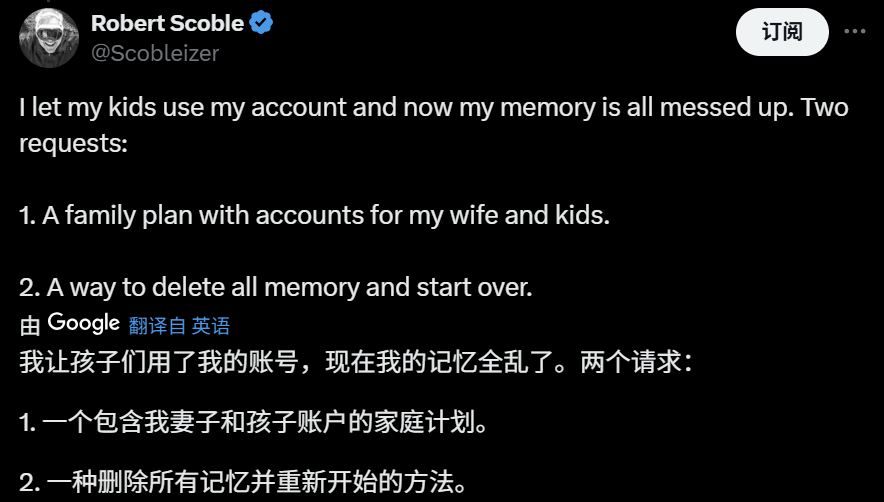
分享了帳號的網民在測試了新功能後也表示不好接受:
從技術角度來看,大型語言模型(LLM)通常使用兩種類型的記憶:一種是在模型訓練過程中嵌入到 AI 模型中的數據,另一種是上下文記憶(對話歷史記錄),它會在會話期間持續存在。通常情況下,一旦開始新的會話,ChatGPT 等大模型就會忘記你在對話中告訴過它的內容。
但對於大模型應用來說,人們總是期待 AI 能夠實現長期記憶,從而更加智能。許多項目都嘗試賦予 LLM 超越上下文窗口的持久記憶。這些技術包括動態管理上下文歷史記錄、彙總壓縮先前的歷史記錄、鏈接到外部存儲信息的向量數據庫,或者簡單地定期將信息注入系統提示(如 ChatGPT 在每次聊天開始時都會收到的指令)等等。
而在目前的 ChatGPT 長期記憶能力,很可能使用了檢索增強生成(RAG),它能夠在生成響應之前引用訓練數據來源之外的知識庫,而無需重新訓練模型。對於大模型提供者來說,這是一種經濟高效地改進 LLM 輸出的方法,它讓 AI 可以在各種情境下都能保持相關性、準確性和實用性。
與此前版本的記憶功能一樣,用戶也可以完全禁用 ChatGPT 的長期記憶功能(打開一個類似於 ChatGPT 的隱身模式),並且它不會用於帶有臨時聊天標誌的對話。
值得一提的是,在 ChatGPT 記憶功能發佈的同時,OpenAI 也放出了一段 46 分鐘的採訪影片,其中山姆・奧特曼與 GPT-4.5 項目核心成員 Alex Paino、Daniel Selsam 和 Amin Tootoonchian 展開對話,聊了聊最新大模型的訓練過程和未來的發展方向。
有人對其中重點進行了總結:GPT-4.5 的項目曆時兩年,其目的是使新模型比前代(GPT-4)智能程度提升 10 倍左右。在這一代模型上,OpenAI 使用的訓練算力從幾萬 GPU 提升到了十萬級的 GPU,這就帶來了大量未預見的問題。
雖然一直以來,Transformer 架構能夠有效地從數據中學習,但 OpenAI 現在訓練大模型的瓶頸似乎不是算力,而是數據,未來的進展取決於采樣效率更高的算法;訓練 GPT-4 現在只需要 5-10 人;下一代大模型的訓練預計將有 1000 萬次以上的 GPU 運行,不過過程可能是「半同步」或分佈式的。
OpenAI 表示,在開發過程中,GPT-4.5 模型展現出了一些此前未明確規劃的細微能力,該項目的結果最終驗證了現有的「擴展定律」。
展望未來,OpenAI 團隊討論了更大規模訓練的潛力與挑戰,假設會用到百萬級的 GPU。他們還談到了預訓練階段與模型推理能力之間的關係、數據質量的重要性以及當前硬件的限制。
參考內容:
https://x.com/sama/status/1910334443690340845
https://x.com/polynoamial/status/1910379351759347860
https://www.youtube.com/watch?v=6nJZopACRuQ
https://arstechnica.com/ai/2025/04/chatgpt-can-now-remember-and-reference-all-your-previous-chats/