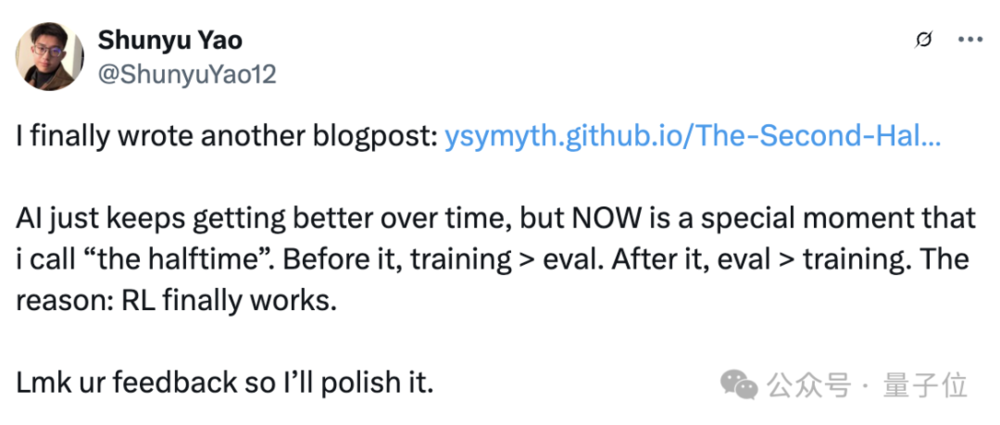
面對雜亂場景,靈巧手也能從容應對!NUS邵林團隊發佈DexSinGrasp基於強化學習實現物體分離與抓取統一策略

本文的作者均來自新加坡國立大學 LinS Lab。本文的共同第一作者為新加坡國立大學實習生許立昕和博士生劉子軒,主要研究方向為機器人學習和靈巧操縱,其餘作者分別為碩士生桂哲瑋、實習生郭京翔、江澤宇以及博士生徐誌軒、高崇凱。本文的通訊作者為新加坡國立大學助理教授邵林。
在物流倉庫、生產線或家庭場景中,機器人常常需要在大量雜亂擺放的物體中高效地抓取目標。
在這些場景中,如果使用機械夾爪,由於其自由度有限、靈活性不足,需要多次對場景進行操作;而高自由度的靈巧手雖然具有潛在優勢,但因控制複雜和訓練難度大,在密集遮擋與複雜排列場景下往往表現不佳。
現有方法常採用先分離、後抓取的策略,存在策略切換不夠靈活,執行效率低下的問題。
為解決這一挑戰,來自新加坡國立大學的邵林團隊提出了 DexSinGrasp——一種基於強化學習的統一策略,通過整合物體分離與抓取任務,令靈巧手在雜亂環境中能夠自適應調整分離與抓取策略,顯著提高抓取成功率和操作效率。該項研究已投稿至 IROS 2025。

-
論文標題:DexSinGrasp: Learning a Unified Policy for Dexterous Object Singulation and Grasping in Cluttered Environments
-
論文鏈接:https://arxiv.org/abs/2504.04516
-
項目主頁:https://nus-lins-lab.github.io/dexsingweb/
-
代碼鏈接:https://github.com/davidlxu/DexSinGrasp
為了讓機器人在多變的雜亂環境中高效分離物體並抓取目標,DexSinGrasp 提出了「統一策略」的設計。該方法通過強化學習構建了一體化的策略框架,實現了「分離—抓取」動作的無縫銜接。該項研究的主要貢獻有:
-
統一強化學習策略:提出一種統一的強化學習策略,實現靈巧手在雜亂環境中對物體的有效分離和抓取。
-
課程學習與策略蒸餾:融入雜亂環境課程學習以提升不同場景下的策略性能,並通過策略蒸餾獲得適用於實際部署的視覺抓取策略。
-
多難度抓取任務設計:設計一系列不同難度與排列的雜亂抓取任務,通過大量實驗驗證所提方法的高效性與有效性。
方法
統一強化學習策略
DexSinGrasp 的核心在於構建一個統一的策略框架,引入分離獎勵項,將「分離障礙」、「抓取目標」整合為一個連續的動作決策過程,充分利用了分離與抓取融合的優勢,避免傳統多階段方法中各模塊間效率低下和動作銜接不暢的問題。為此,我們設計了一個分段式獎勵函數,其關鍵組成包括:
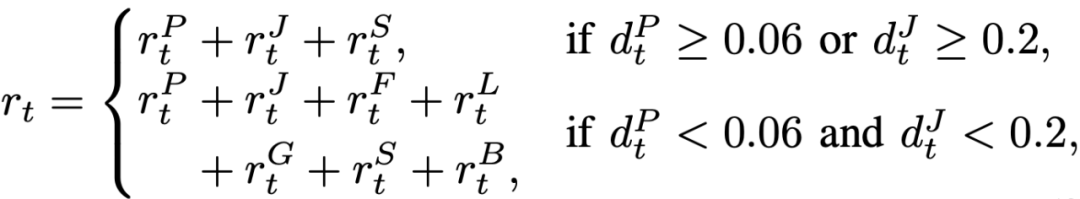
-
接近獎勵:獎勵項

引導手掌和手指在初始階段向目標物體靠近,從而確保機器人迅速定位目標。
-
抬升與目標對齊獎勵:在目標接觸後,獎勵項

鼓勵機器人將物體抬升至預設位置,實現準確對齊。
-
分離獎勵:通過獎勵項,使機器人在抓取過程中主動推動、滑動或輕推周圍障礙物,從而為抓取創造足夠空間。
獎勵函數依據手掌與手指到目標物體的距離
來自動轉換,從「接近」階段逐步過渡到「抓取」階段,使整個過程更加平滑和高效。該統一策略不僅提升了訓練樣本的利用效率,還使機器人能根據實時場景動態選擇微調指尖、輕推障礙或直接抓取,從而在雜亂環境下實現穩定的抓取操作。
雜亂環境課程學習
在高度雜亂的場景中直接訓練機器人往往容易陷入局部最優,導致成功率低下。為此,我們引入了「雜亂環境課程學習」的機制,具體包括:
-
任務分級設計:從最簡單的單目標抓取任務開始,逐步引入障礙物。我們設計了不同難度的任務,例如:
-
密集排列任務:用 D-4、D-6、D-8 表示,不同數字代表環境中障礙物數量的遞增;
-
隨機排列任務:用 R-4、R-6、R-8 表示,以驗證策略在非規則分佈場景下的泛化能力。
-
循序漸進訓練:先在障礙物較少且排列較規則的環境中訓練出初步策略,然後逐步過渡到障礙物數量更多、排列更隨機的複雜場景。這樣的訓練策略能顯著提高策略的穩定性和泛化性能,確保機器人在極端密集的環境下也能有效分離並抓取目標。
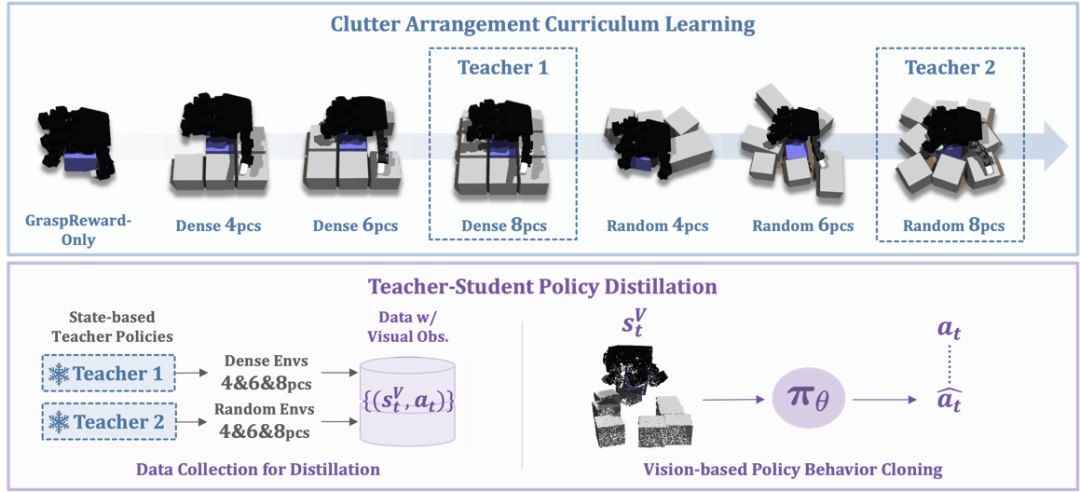
教師—學生策略蒸餾
在仿真環境中,我們能夠利用精確的物體位置、力反饋等特權信息訓練出高性能的教師策略。但在真實場景中,這些信息難以獲取,為此我們設計了教師—學生策略蒸餾方案:
-
教師策略:利用仿真中豐富的特權信息訓練出性能優異的策略,能夠精細地控制物體的分離和抓取動作。
-
數據採集與行為複製:通過教師策略生成大量示範數據(包括視覺觀測、點雲數據以及動作指令),並採用行為複製的方法訓練出只依賴攝像頭採集的點雲和機器人自感知數據的學生策略。這樣,在真實環境中,機器人無需額外傳感器信息也能保持高成功率,完成從仿真到實機的平滑遷移。
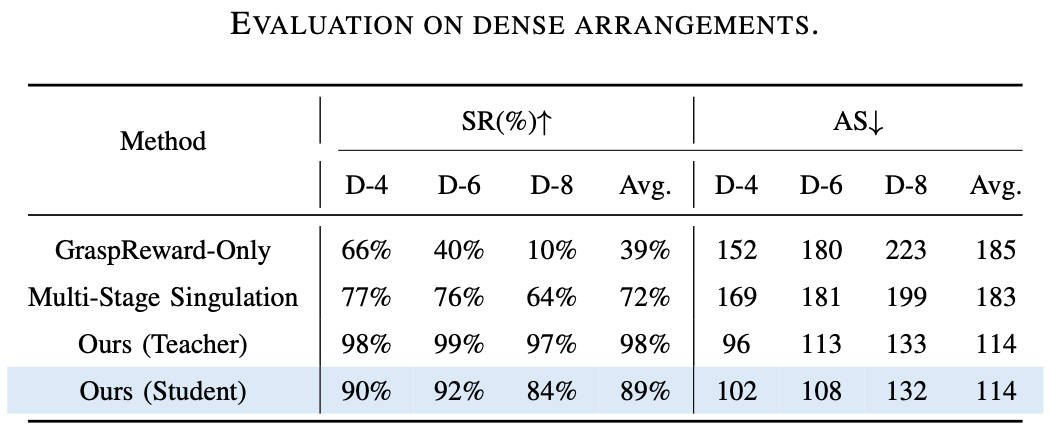
實驗結果
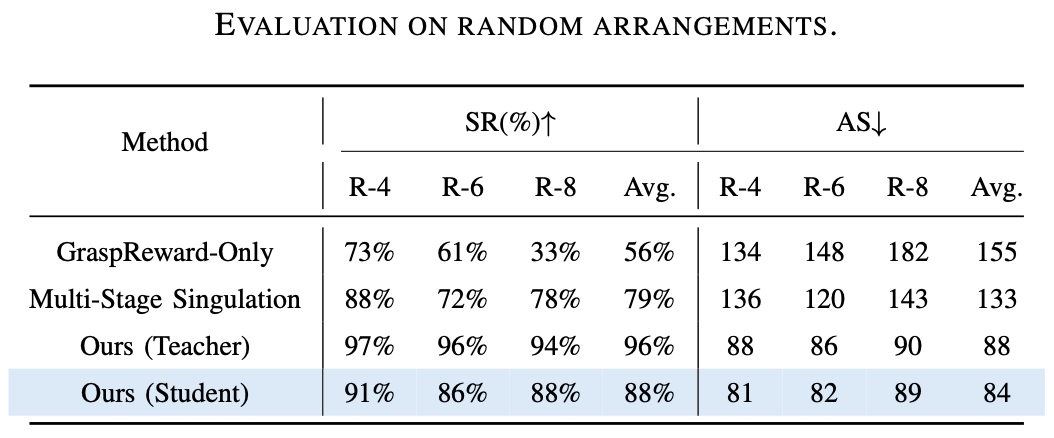
為了測試 DexSinGrasp 策略在分離抓取時的有效性和泛化性,以及雜亂環境課程學習的有效性,設計了三組實驗進行測試,並與兩種基線比較。
基線 1 僅訓練了一個抓取策略,沒有鼓勵對周圍物體進行分離。基線 2 將分離和抓取策略分開且分階段進行。
評價指標為抓取成功率(SR)和平均步數(AS)。抓取成功率越高,說明策略的有效性越高,平均步數越少,說明策略的效率越高。
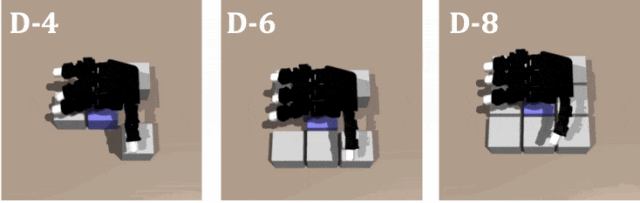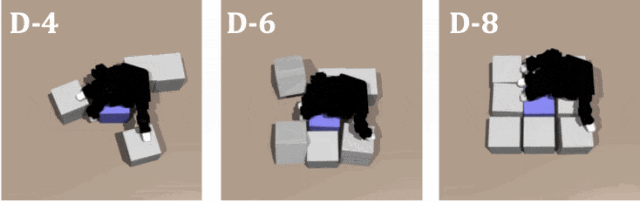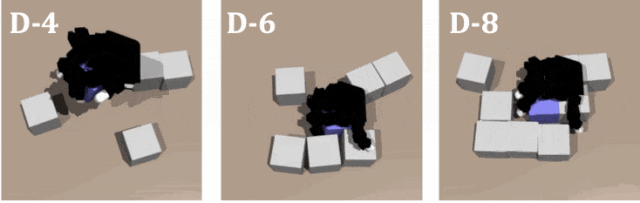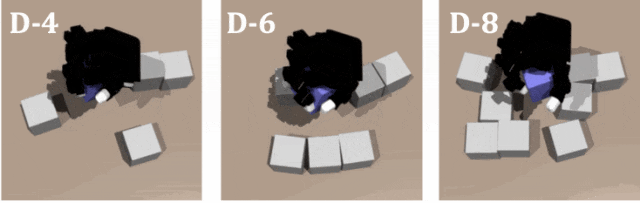
實驗 1
對教師策略和學生策略在不同數量障礙的緊密排列進行測試,證明了 DexSinGrasp 的有效性和高效率。圖示是教師策略在密集擺放模式下障礙物數量為 4、6、8 時的仿真演示。
實驗 2
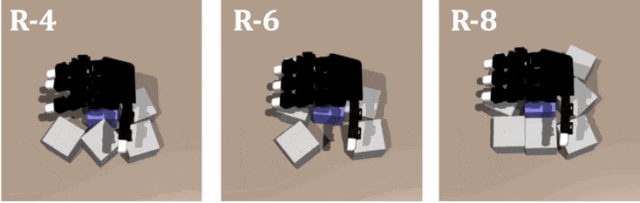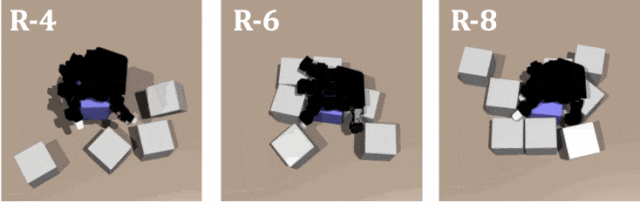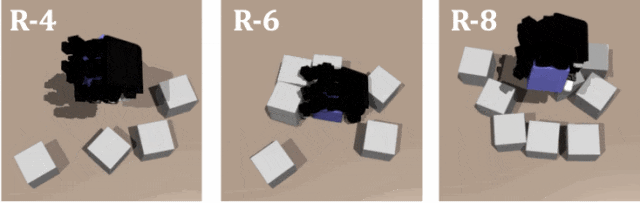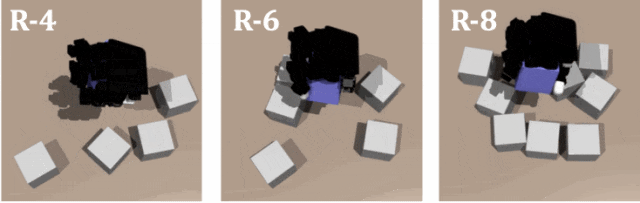
對教師策略和學生策略在不同數量障礙的隨機排列進行測試,結果證明了 DexSinGrasp 在隨機物體擺放下也可以實現成功分離抓取,對不同的場景有一定泛化性。圖示是教師策略在隨機擺放模式下障礙物數量為 4、6、8 時的仿真演示。
實驗 3
對雜亂環境課程學習的方式進行測試。我們嘗試了無課程學習、先隨機排列再緊密排列的課程學習,以及先緊密排列再隨機排列的課程學習的訓練模式。
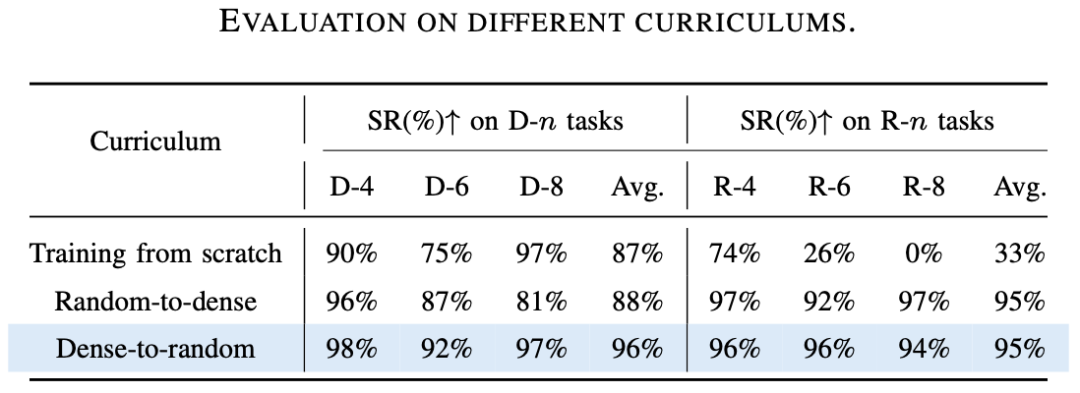
我們發現,無課程學習訓練的各個策略中,隨機排列的任務表現不佳;先隨機排列再緊密排列的課程學習獲得的各個策略中,緊密排列的任務表現不佳;而先緊密排列再隨機排列的課程學習在不同的任務上均取得了不錯的成功率,證實了所提出的課程學習機制在不同場景下的有效性。
此外,研究團隊還在實機平台上進行了驗證。使用 uFactory xArm6 搭載 LEAP 手,並配備兩台 Realsense RGB-D 攝像頭以進行實時點雲數據融合與濾波處理。圖示為實機實驗中對密集與隨機擺放的 4、6、8 個物體場景下成功分離與抓取的演示。實驗表明,經過教師—學生策略蒸餾後的視覺策略在實際操作中也能有效完成雜亂環境的有效分離與抓取。


總結
研究團隊所提出的 DexSinGrasp 是一種基於強化學習的統一框架,通過整合物體分離與抓取任務,實現了靈巧手在雜亂環境中的高效操作。
該方法突破以往直接抓取或多階段分割的策略,利用推移、滑動等動作在抓取過程中直接調整障礙物佈局,結合環境複雜度遞進式的雜亂環境課程學習與教師—學生策略蒸餾技術,有效提升視覺策略的泛化能力與仿真到現實的遷移效果。
實驗表明,該方法在多種測試場景中展現出優於傳統方法的抓取成功率和操作效率。未來研究將拓展至動態複雜場景下的多形態物體操作,增強抗干擾能力,進一步提高系統在非結構化環境中的泛化性與適應性。