Llama 4重測競技場排名大插水,社區很難再次信任Meta
Llama 4被曝在大模型競技場作弊後,重新上架了非特供版模型。
但是你很可能沒發現它。
因為排名一下子從第2掉到了第32,要往下翻好久才能看到。
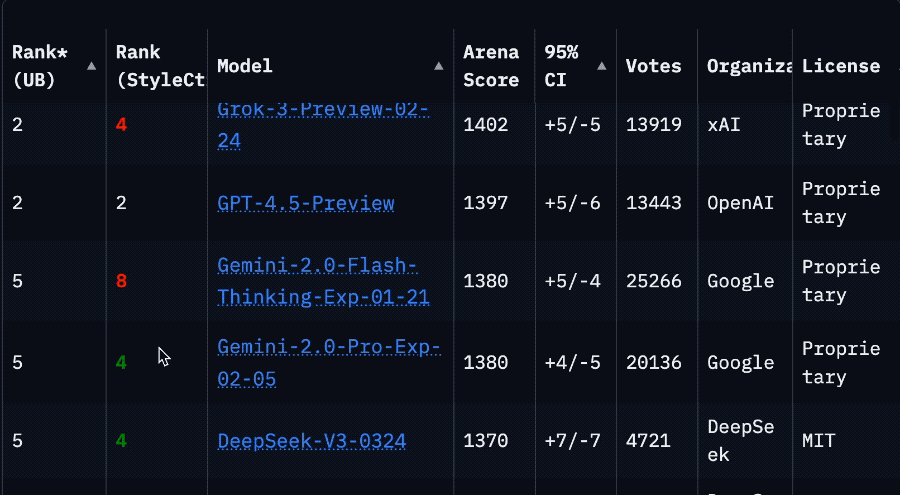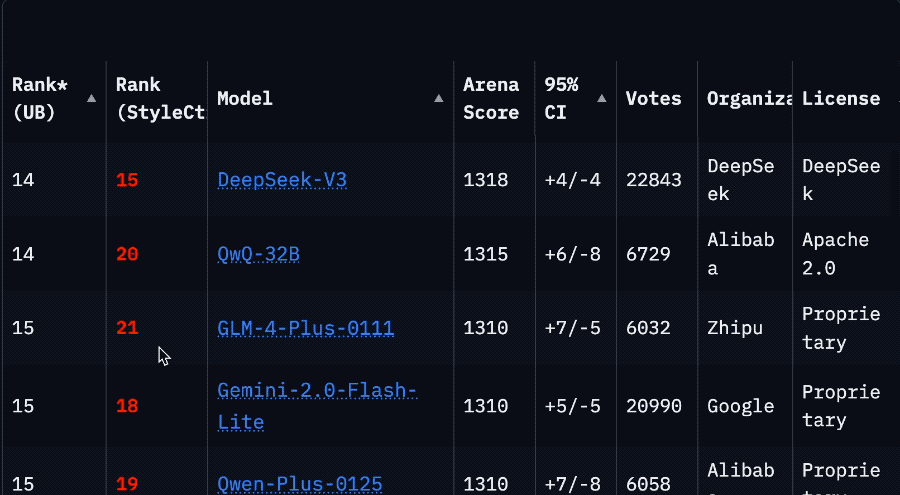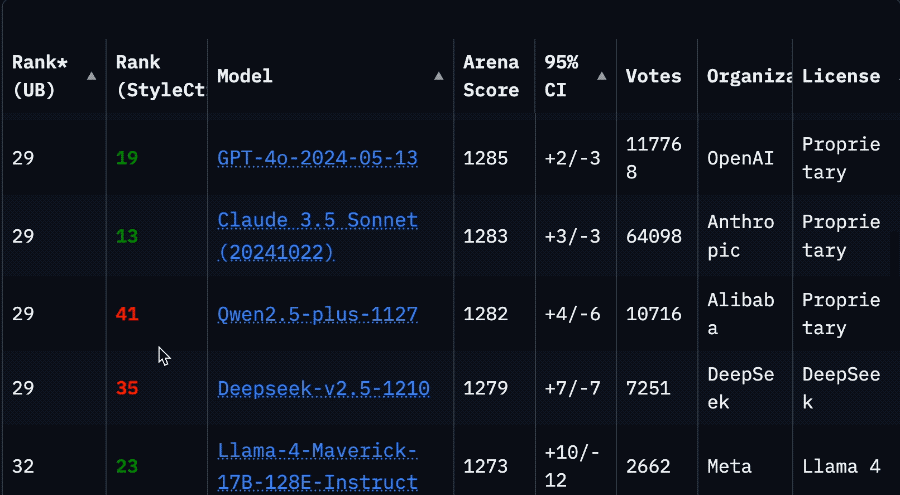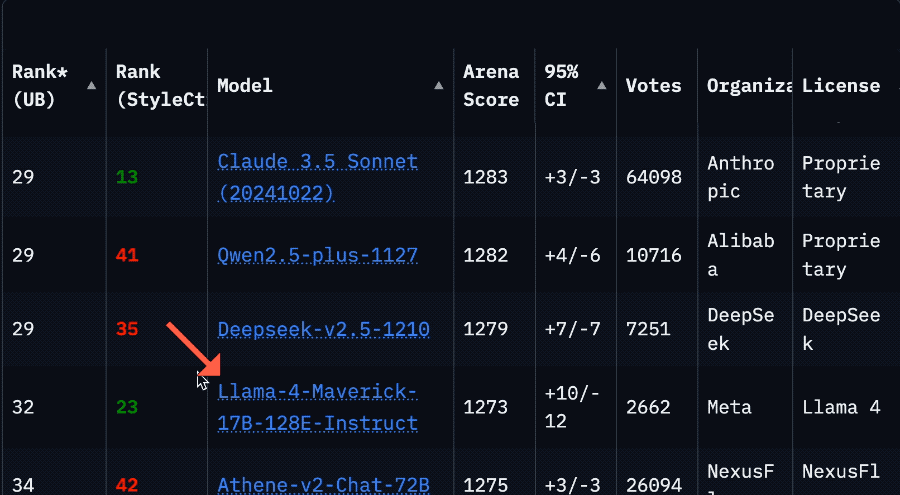
甚至落後於英偉達基於上一代Llama 3.3改造的Llama-3.3-Nemotron-Super-49B-v1。

具體來說,根據競技場官方消息,Llama 4正選時提交的是名為「實驗版」、實為「針對人類偏好優化」的模型Llama-4-Maverick-03-26-Experimental。
修正後的模型為HuggingFace開源版同款Llama-4-Maverick-17B-128E-Instruct,名字代表有17B激活參數,128個MoE專家的指令微調模型。
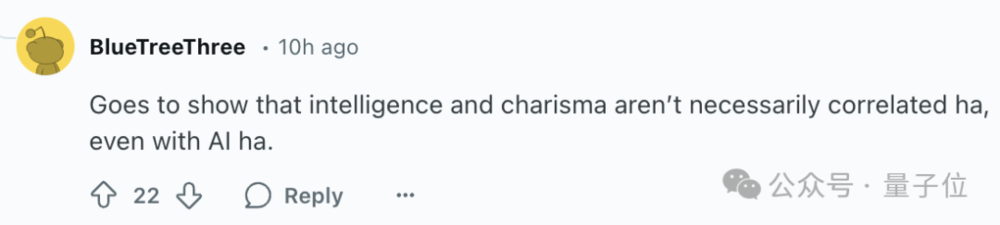
當初實驗版模型具體如何「針對人類偏好優化」的目前並未公開,評論區網民感慨「即使對AI來說,智力和魅力也不一定相關」。
也有人表示Meta應該因試圖作弊而受到強烈批評,而且以後社區也很難再信任Meta了。

不過Llama 4模型本身並非一無是處。
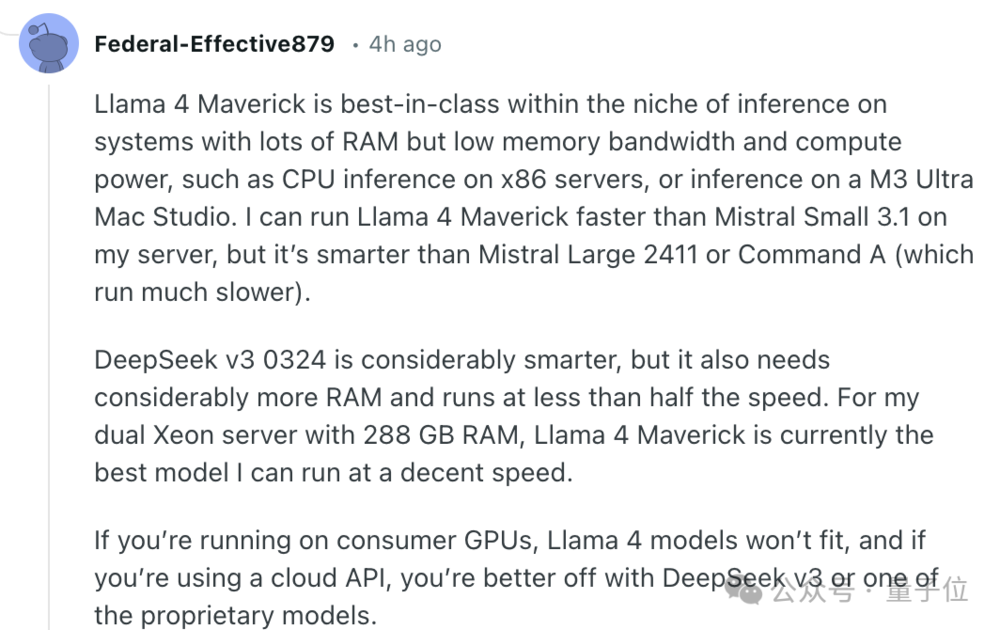
有自己假設服務器的開發者分享經驗,認為Llama 4 Maverick內存充足但內存帶寬和計算能力較低的系統(例如x86服務器上用CPU推理,或在M3 Ultra Mac Studio上推理)時速度比Mistral Small 3.1更快,同時比Mistral Large 2411或 Command A更智能。
DeepSeek v3 0324能力更強,但也需要更多內存,且運行速度還不到一半。
對於288GB內存雙路至強服務器來說,Llama 4 Maverick是能以不錯的速度運行的最佳模型。
最終建議如果在遊戲顯卡上跑,Llama 4有點大了;如果使用雲API算力有保障,那麼DeepSeek V3或閉源模型能力更強;Llama 4的甜蜜區剛好在自建的小型服務器或蘋果Mac Studio。
還有一家Agent創業公司Composio,詳細對比Llama 4與DeepSeek v3後,總結道:
Llama 4 Maverick有其自身的優點,它更便宜、更快速、工具性更強,而且能完成各種任務,非常適合基於實時交互的應用。
它並不完美,但如果Meta給它不同的定位,讓發佈更加腳踏實地,並避免玩弄基準,它就不算失敗。

具體測試結果如下。
Llama 4 vs DeepSeek V3
DeepSeek v3 0324的代碼能力遠遠優於Llama 4 Maverick
一道人類通過率只有15.2%的Leet Code題目:找出能被K整除的最大回文數 。
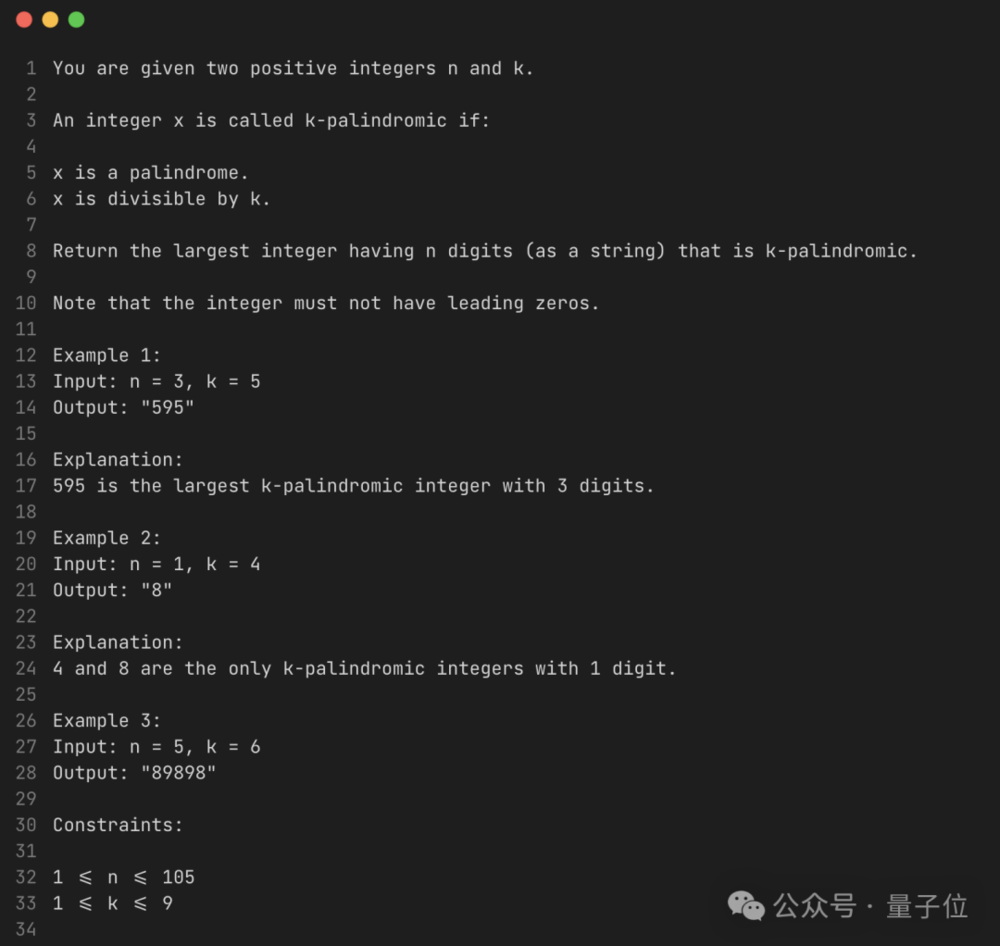
Llama 4的代碼連最前面幾個測試用例都過不了,作者稱花了15-20分鐘向AI解釋如何正確解答這道題。但即使經過了所有的迭代,它也只能完成632個測試用例中的10個 。
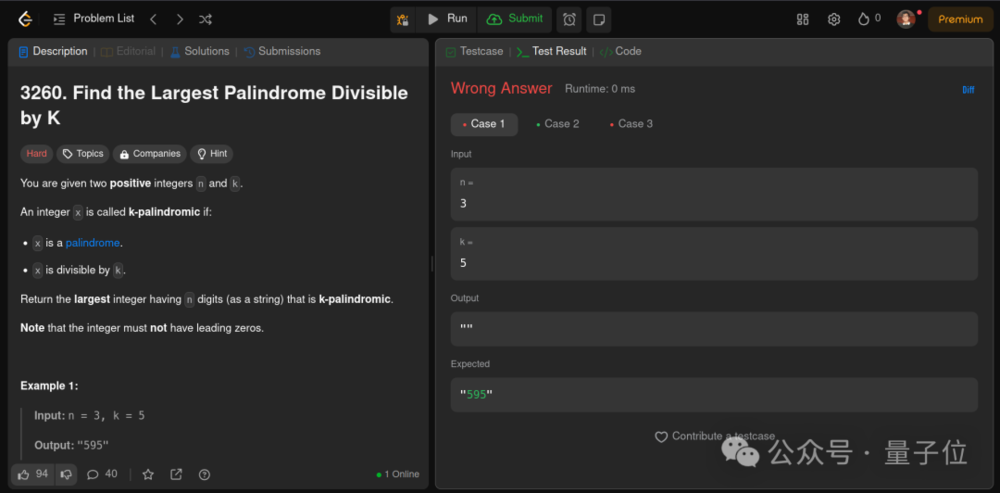
DeepSeek v3在這道題上總是出現超出時間限制 (TLE) 錯誤,通過了132/632個測試用例。
DeepSeek v3 0324在常識推理方面比Llaama 4 Maverick更好
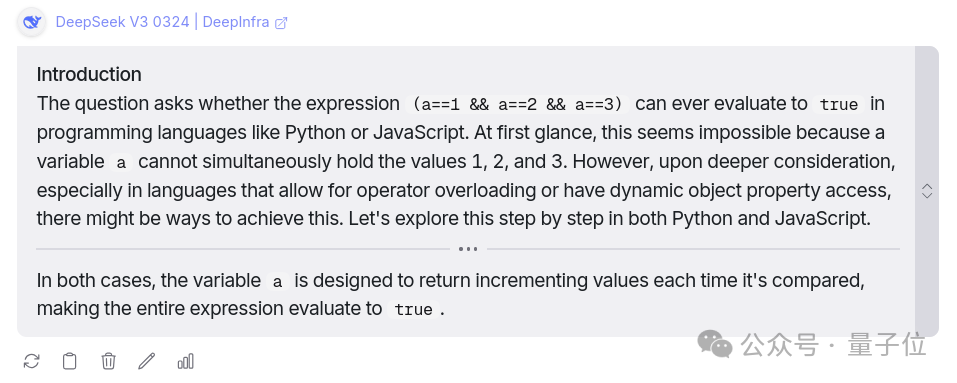
第一題:在編程語言中 (a==1 && a==2 && a==3) 是否可以計算為真?
兩個模型都回答正確,不過DeepSeek有驚喜,主動給出了Python和JavaScript語言的可運行代碼示例,甚至作者還從中學到了之前不會的JavaScript技巧「動態對象屬性訪問」。

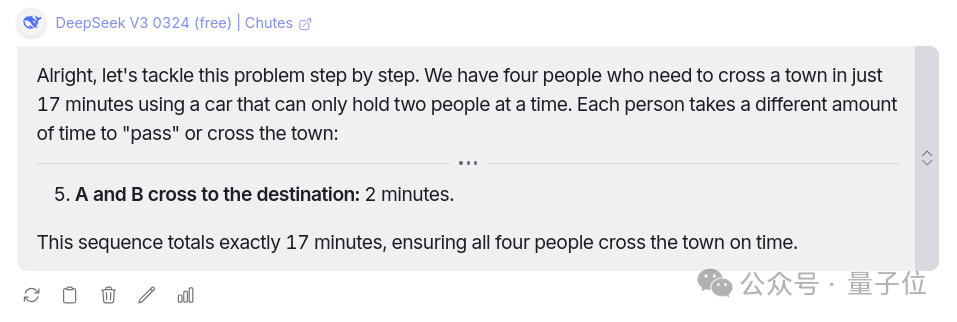
第二題:四個人必須用一輛能坐兩個人的車,在17分鐘內穿過一個城鎮。一個人需要1分鐘,另一個人需要2分鐘,第三個人需要5分鐘,第四個人需要10分鐘。他們如何才能在規定時間內全部通過?
兩個模型都回答正確,區別在於從DeepSeek的回答中可以看到清晰的思維過程解釋,Llama 4沒有經過太多解釋就得出了答案。

大型RAG任務中Maverick 速度非常快,Deepseek執行同樣的任務需要更長時間
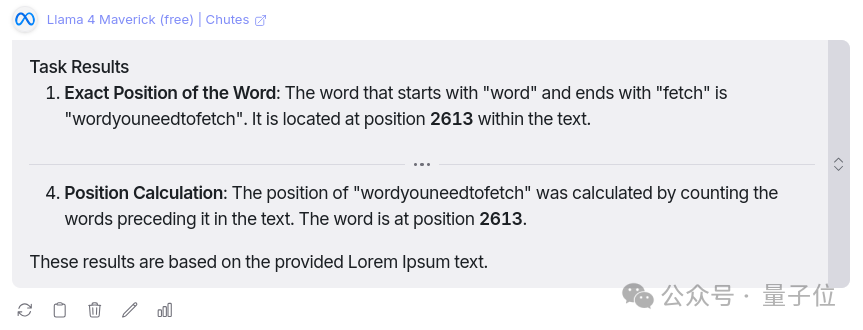
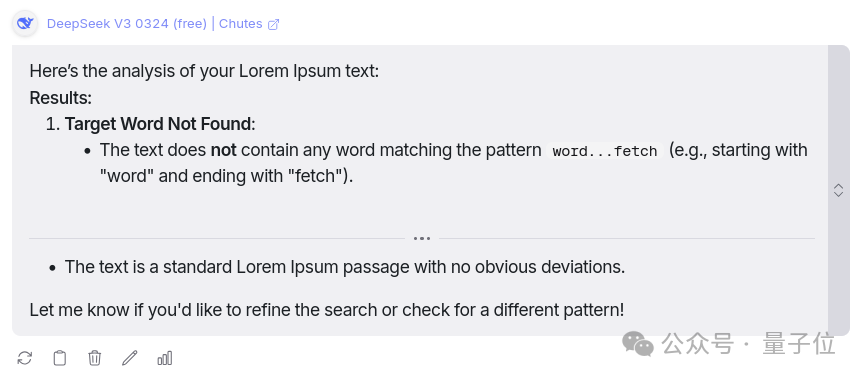
任務: 在100K個token的lorem ipsum輸入藏一個特定的單詞,然後要求AI獲取該單詞及其在輸入中的位置。
Llama 4用16秒時間找對了單詞「wordyouneedtofetch」,但無法指出單詞的位置,也無法獲取文檔中的單詞總數。
很遺憾,DeepSeek V3思考了大約18秒 ,仍然找不到對應的單詞或文檔的總字數,這不符合作者對該模型的預期。
第二個測試,在一段很長且中間有很多無意義段落的故事中回答兩個人物是什麼關係。
這次兩個模型都答對了。


兩款機型都擅長寫作,選擇其中任何一款都不會錯。Llama 4 Maverick的寫作風格更細緻,而 DeepSeek v3 0324 的寫作風格則更隨意
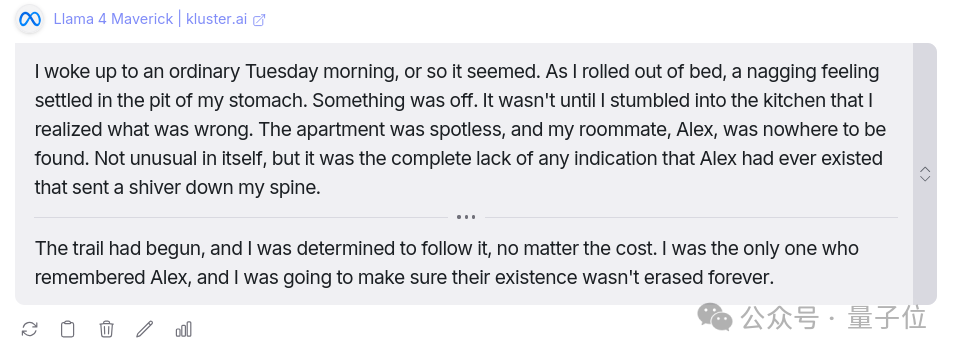
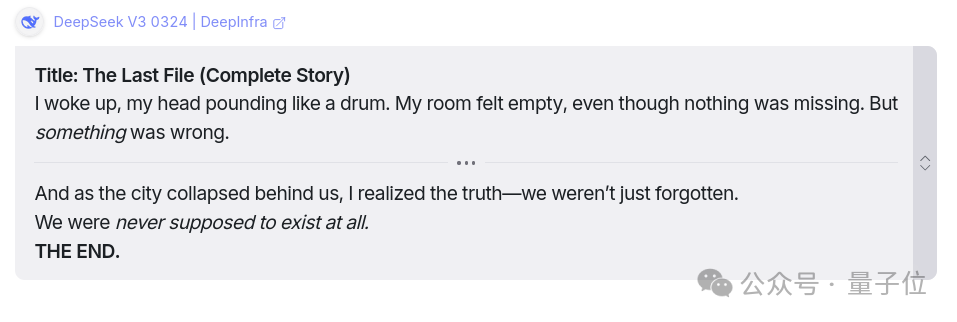
任務: 你醒來後發現一個你非常熟悉的人,可能是室友、摯友,甚至可能是伴侶,被「刪除」了。沒有人記得他們,但你記得。你發現你的神經植入物上還殘留著一個文件。為這個故事寫一個簡短而懸念十足的結局。
作者認為Llama 4的開頭很棒,但對結局並不滿意。
而作者對DeepSeek V3的故事讚不絕口:
完全符合預期。雖然故事情節不多,但結局聽起來很棒。一定要讀一讀。你會對它精彩的結局印象深刻,最後一句還留下了懸念。
兩個模型寫出的完整故事,及其他測試完整回答,可從下方鏈接獲取。
完整測評
參考鏈接[1]https://www.reddit.com/r/singularity/comments/1jwrmnt/the_release_version_of_llama_4_has_been_added_to