謝賽寧等新作上線,多模態理解生成大一統!思路竟與GPT-4o相似?

新智元報導
編輯:編輯部 HXZ
【新智元導讀】來自Meta和NYU的團隊,剛剛提出了一種MetaQuery新方法,讓多模態模型瞬間解鎖多模態生成能力!令人驚訝的是,這種方法竟然如此簡單,就實現了曾被認為需要MLLM微調才能具備的能力。
現在的大模型都有一個「理想」,那就是將各種模態大一統,一個模型就能生文、生圖、生影片,可以稱之為「全干模型」!
GPT-4o發佈了自己原生的多模態繪圖能力著實火了一把,OpenAI還給模型起了一個新的名字「全能模型」。
統一的多模態模型旨在整合理解(文本輸出)和生成(像素輸出),但在單個架構內校準這些不同的模態通常需要複雜的訓練方案和仔細的數據平衡。
在剛剛發佈的一項研究中,來自Meta和紐約大學的研究人員探索了一種簡單但尚未得到充分探索的、用於統一多模態建模的替代方法。
 論文地址:https://arxiv.org/pdf/2504.06256
論文地址:https://arxiv.org/pdf/2504.06256項目主頁:https://xichenpan.com/metaquery/
新的方法MetaQuery橋接了凍結的(Frozen)多模態大語言模型(MLLM)骨幹和擴散模型(DiT)。
實驗表明,MetaQuerie實現了所有曾被認為需要MLLM微調才能具備的能力,同時其訓練過程也更為簡便。
簡而言之就是,具備理解能力的MLLM可以直接和負責生成圖片的DiT進行SOTA水平的多模態生成。

文本到圖像生成
 一個巨大的人形,由蓬鬆的藍色棉花糖製成,踩在地上,咆哮著衝向天空,身後是湛藍的天空
一個巨大的人形,由蓬鬆的藍色棉花糖製成,踩在地上,咆哮著衝向天空,身後是湛藍的天空 一個穿著褲子和夾克的生鏽舊機器人在超市里騎滑雪板
一個穿著褲子和夾克的生鏽舊機器人在超市里騎滑雪板 一隻亮藍色鸚鵡的羽毛在燈光下閃閃發光,顯示出它獨特的羽毛和鮮豔的色彩
一隻亮藍色鸚鵡的羽毛在燈光下閃閃發光,顯示出它獨特的羽毛和鮮豔的色彩指令微調
 同一個機器人,但在「我的世界」
同一個機器人,但在「我的世界」 同樣一種車型,但在紐約
同樣一種車型,但在紐約
同一個
碗藍莓,但俯視圖
推理和知識增強生成
 最高的建築主宰著這座被稱為光之城的城市的天際線
最高的建築主宰著這座被稱為光之城的城市的天際線 新月之夜的夜空
新月之夜的夜空 這個在春季節日中備受讚頌的花,是壽司發源國所特有的
這個在春季節日中備受讚頌的花,是壽司發源國所特有的橋接MLLM與DiT,實現大一統
通常來說,創建一個「既要又要」的模型——既要最先進的多模態理解能力,同時又要強大的生成圖像能力——有些困難。
目前的一些方案依賴於精細微調基礎多模態大語言模型(MLLM)來處理理解和生成任務。
但這個過程涉及複雜的架構設計、數據/損失平衡、多個訓練階段以及其他複雜的訓練方案,若不靠考慮這些,優化一種能力可能會損害另一種能力——「按下葫蘆又起了瓢」。
如何有效地將自回歸多模態大語言模型(MLLM)中的潛在世界知識轉移到圖像生成器中?
說來也簡單,將生成任務交給擴散模型,將理解任務交給大語言模型——「讓凱撒的歸凱撒」。
換句話說,不是設法從頭開始構建一個單體系統,而是專注於在專門針對不同輸出模態的最先進的預訓練模型之間有效地轉移能力。
為了實現這一點,研究團隊讓MLLM凍結(Frozen),以便可以專注於它們最擅長的事情——理解,同時將圖像生成委託給擴散模型。
即使在這種凍結條件下,只要有合適的架構橋樑,MLLM固有的世界知識、強大的推理能力和上下文學習能力確實可以轉移到圖像生成中。
這樣的系統可以解鎖協同能力,其中理解為生成提供信息,反之亦然。
 戴著墨鏡的英國短毛貓
戴著墨鏡的英國短毛貓MetaQuery將一組可學習的查詢直接輸入到凍結的MLLM中,以提取用於多模態生成的條件。
實驗表明,即使沒有進行微調或啟用雙向注意力,凍結的LLM也能充當強大的特徵重采樣器,為多模態生成產生高質量的條件。
使用MetaQueries訓練統一模型僅需要少量圖文對數據,即可將這些提示條件連接到任何條件擴散模型。
由於整個MLLM在理解方面保持不變,訓練目標仍然是原始的去噪目標——就像微調擴散模型一樣高效和穩定。
思路與GPT-4o原生生圖相似
相比訓練單個自回歸Transformer骨幹來聯合建模的統一模型,MetaQuery選擇使用token→Transformer→擴散→像素的範式。
這一思路,可能與同期的GPT-4o圖像生成系統所體現的理念相似。
通過將MLLM的自回歸先驗與強大的擴散解碼器相結合,MetaQuery直接利用凍結MLLM在建模壓縮語義表示方面的強大能力,從而避免了直接生成像素這一更具挑戰性的任務。
統一所有模態的前景並非止步於並行處理多模態理解和文本到圖像的生成。
更深層次的協同作用值得期待——一種能夠利用MLLM的高級能力(如推理、內部知識、多模態感知和上下文學習)來增強生成的能力。
 比如生成一個和「9條命」相關的動物——通過推理,得出是九命的是貓妖
比如生成一個和「9條命」相關的動物——通過推理,得出是九命的是貓妖MetaQuery
概括來說就是,MetaQuery方法能夠無損地為僅具理解能力的多模態大語言模型(MLLM)賦予多模態生成能力,同時保持其原始架構設計和參數不變。
架構
具體到架構層,研究人員首先使用隨機初始化的可學習查詢Q∈R^(N×D)來查詢獲取用於生成的條件C。其中,N是查詢的數量,D是查詢的維度(與MLLM的隱藏維度相同)。
為簡單起見並保持兼容性,繼續對整個序列使用因果掩碼(causal masking),而不是專門為查詢Q啟用全注意力(full attention)。
然後將條件C輸入一個可訓練的連接器(trainable connector),從而與文本到圖像擴散模型的輸入空間對齊。
這些擴散模型可以是任意類型,只要它們具有條件輸入接口即可。需要做的,就只是將模型的原始條件替換為生成的C。
雖然模型目前專注於圖像生成任務,但也可輕鬆擴展至其他模態,如音頻、影片、3D等。
設計選擇
架構涉及兩個核心設計選擇:使用可學習查詢(learnable queries)和保持MLLM骨幹凍結(frozen)。
· 可學習查詢
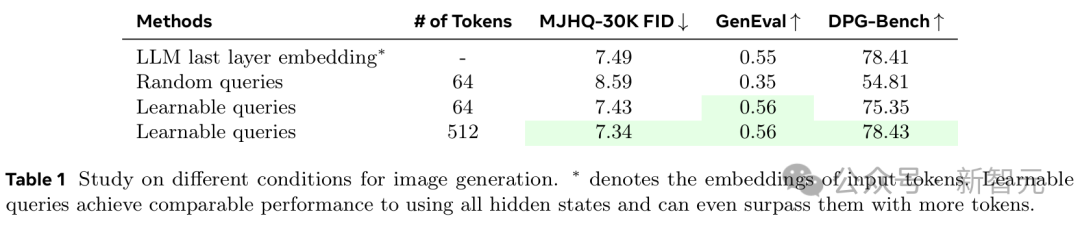
目前,很多模型會使用(M)LLM輸入Token的最後一層嵌入(last layer embedding)作為圖像生成條件。但這與統一建模中的許多期望任務並不兼容,如上下文學習或生成多模態、交錯的輸出。
而且,隨機查詢(random queries)雖然能產生不錯的FID分數,但它們在提示詞的對齊方面表現不佳。
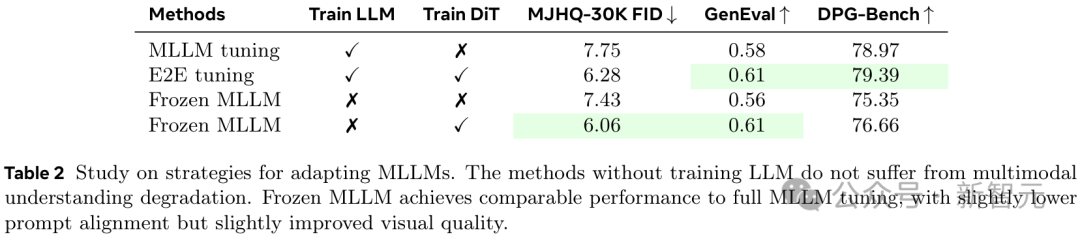
如表1所示,僅使用N=64個Token的可學習查詢,即可實現與這些模型相當的圖像生成質量。當N=512個Token時,性能則直接超越了最後一層嵌入方法。
· 凍結 MLLM
現有的統一模型通過訓練MLLM來聯合建模p(文本, 像素),但這樣會讓訓練過程更複雜,甚至會降低模型的理解性能。
相比之下,MetaQuery可在原始MLLM架構和參數不變的情況下,保留SOTA的理解能力。
如表2所示,雖然可調的參數顯著更少,但凍結MLLM能夠實現與MLLM全量微調相當的性能,其提示詞對齊能力略低,但視覺質量略有提高。
訓練方案
接下來,團隊進一步研究了MetaQuery兩個主要組件的關鍵訓練選項:可學習查詢(learnable queries)和連接器(connectors)。
· Token數量
如圖2所示,對於文本到圖像生成任務,視覺質量在64個Token後開始趨於收斂,而更多的Token能持續帶來更好的提示詞對齊效果。
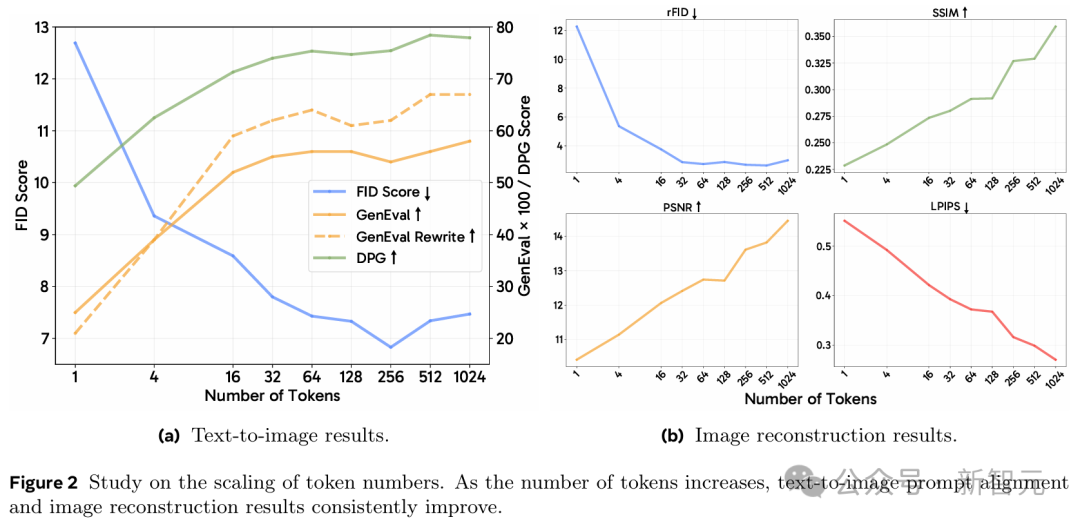
對於長標註(long captions)來說,這一點更為明顯,因為隨著Token數量的增加,使用重寫提示詞(rewritten prompts)的GenEval分數增長得更快。
而對於圖像重建任務,更多的Token則能持續提高重建圖像的質量。

· 連接器設計
在這裏,團隊研究了兩種不同的設計:編碼器前投影(Projection Before Encoder, Proj-Enc)和編碼器後投影(Projection After Encoder, Enc-Proj)。
-
Proj-Enc首先將條件投影到擴散解碼器的輸入維度,然後使用Transformer編碼器來對齊條件
-
Enc-Proj首先使用Transformer編碼器在與MLLM隱藏狀態相同的維度上對齊條件,然後將條件投影到擴散解碼器的輸入維度
如表3所示,Enc-Proj比Proj-Enc實現了更好的性能,同時參數更少。
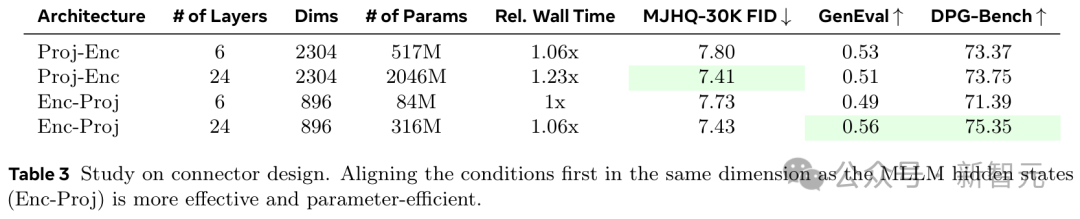
值得一提的是,研究人員使用的是與Qwen2.5相同的架構,並為連接器啟用了雙向注意力(bi-directional attention)。
模型訓練
MetaQuery的訓練分兩個階段:預訓練和指令微調。
其中,每個訓練階段都保持MLLM凍結,並微調可學習查詢、連接器和擴散模型。
MLLM骨幹則有三種不同的規模:Base(LLaVAOneVision 0.5B)、Large(Qwen2.5-VL 3B)和X-Large(Qwen2.5-VL 7B)。
所有模型的Token數量都為N=256,並採用具有Enc-Proj架構的24層連接器。
· 預訓練
研究人員在2500萬個公開可用的圖文對上對我們的模型進行了8個epoch的預訓練,學習率為1e-4,全局批大小為4096。學習率遵循餘弦衰減策略,並設有4000步的預熱期,之後逐漸降低至1e-5。
· 指令微調
受MagicLens的啟發,研究人員使用網絡語料庫中自然出現的圖像對來構建指令微調數據。
這些語料庫不僅包含豐富的多模態上下文,其中的圖像對也展現出了更有意義的關聯(從直接的視覺相似性到更微妙的語義聯繫),從而為指令微調提供了極好且多樣化的監督信號。

接著,研究人員開發了一個數據構建流程,用於挖掘圖像對並利用MLLM生成開放式指令來捕捉它們圖像間的關係。
-
首先,從mmc4核心的人臉子集中收集分組圖像,其中每張圖像都附有圖說。
-
然後,使用SigLIP聚類具有相似圖說的圖像。每組中,與其他圖像平均相似度最低的圖像被指定為目標圖像,而其餘圖像則作為源圖像。這個過程總共產生了240萬個圖像對。
-
最後,使用Qwen2.5-VL 3B為每對圖像生成指令,描述如何將源圖像變換為目標圖像。
實驗
圖像理解與生成
如表4所示,這個模型家族在理解和生成任務上都展示了強大的能力。
得益於允許利用任意SOTA凍結MLLM的靈活訓練方法,所有不同規模的模型在所有理解基準上都有著相當不錯的表現。
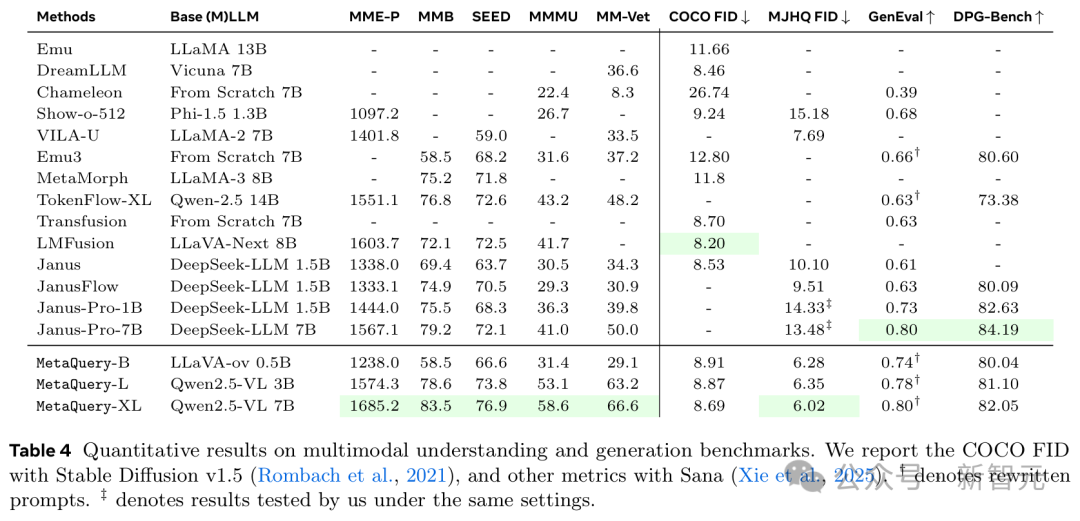
在圖像生成方面,MetaQuery在MJHQ-30K上實現了SOTA視覺質量,並在GenEval和DPG-Bench上與SOTA提示對齊結果非常接近。
鑒於MetaQuery使用凍結MLLM,就可以自然地連接任意數量的擴散模型。
由於基礎的Sana-1.6B模型已經在美學數據上進行了微調,研究人員採用Stable Diffusion v1.5進行COCO FID評估。
結果表明,在將其適配到強大的MLLM後,可以獲得改進的視覺質量。這也為所有基於Stable Diffusion v1.5的統一模型(包括MetaMorph和Emu)建立了新的SOTA COCO FID分數。

在提示詞對齊方面,MetaQuery在GenEval上也取得了有競爭力的性能,擊敗了所有基於擴散模型的方法,包括Transfusion和JanusFlow。
此外,研究人員還發現MetaQuery實現了比Janus-Pro好得多的世界知識推理能力。
圖像重建
如圖6所示,MetaQuery可以在凍結MLLM的情況下輕鬆微調以執行圖像重建任務。
其中,微調後的MetaQuery-B所生成的質量,與現有的最佳開源模型Emu2基本相當。

圖像編輯
如圖7所示,MetaQuery可以遷移其圖像重建能力來執行圖像編輯。
方法是保持MLLM骨幹凍結,並在公開可用的圖像編輯數據上僅對預訓練的Base模型進行1000步微調。
定性結果表明,MetaQuery在這些圖像編輯場景中表現有效。

指令微調
在240萬數據集上進行指令微調後,MetaQuery可以實現令人印象深刻的零樣本學習主體驅動生成性能,即使有多個高度定製化的主體也能生成連貫的結果(圖8第一行)。
使用各種監督信號,經過指令微調的MetaQuery-B模型出人意料地解鎖了超越複製黏貼的新穎能力,如視覺關聯和標誌設計(圖8第二行)。
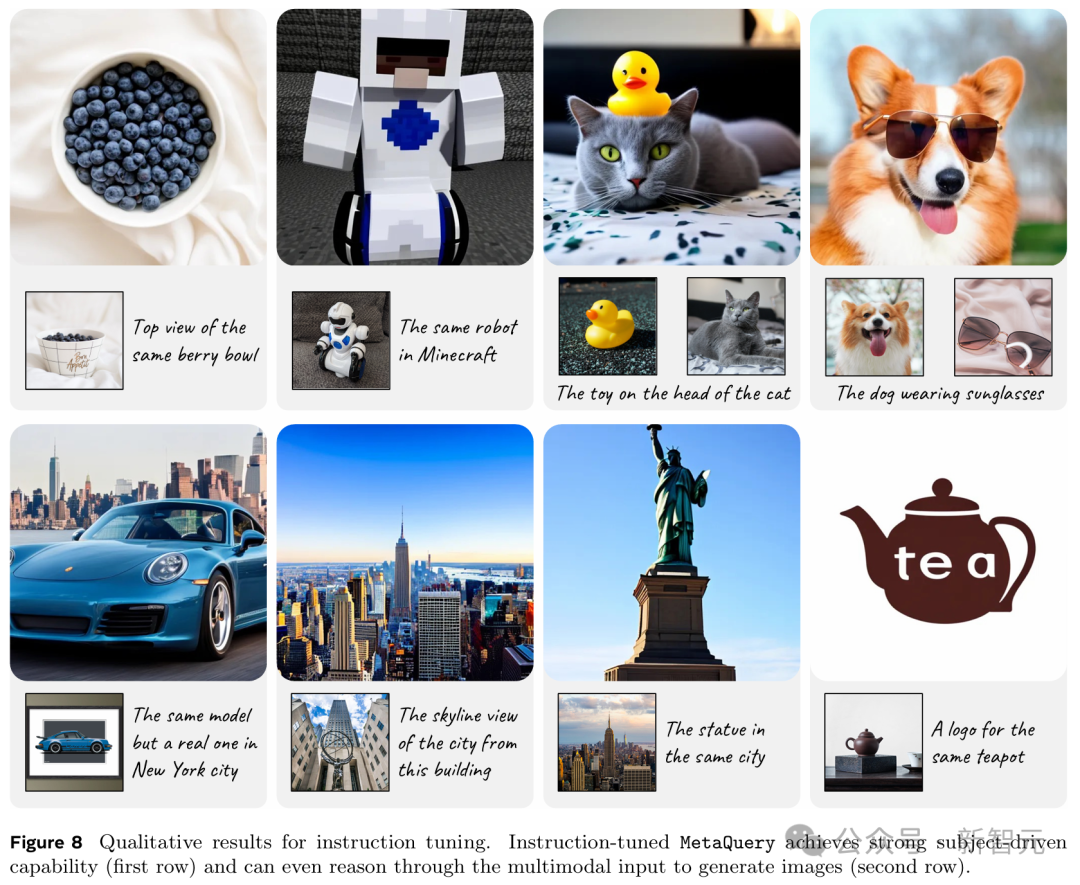
例如,在第一個案例中,模型識別出了輸入的保時捷911汽車圖像的具體型號,然後正確地為該型號生成了一個新穎的正面視圖。
在第二個案例中,模型識別出洛克菲勒中心的輸入圖像,並構想出從洛克菲勒中心頂部的紐約市景觀。
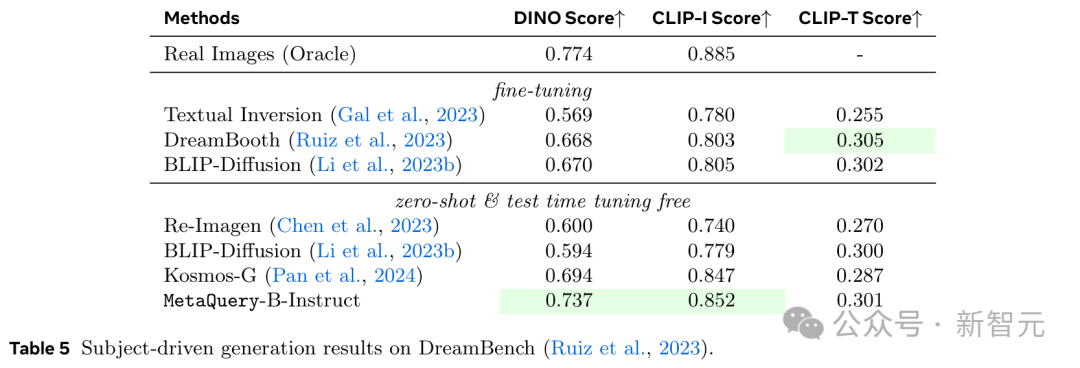
研究人員還遵循DreamBooth的方法,採用DINO、CLIP-I和CLIP-T分數在DreamBench數據集上對模型進行了定量評估。
如表5所示,MetaQuery-BInstruct模型達到了SOTA性能,優於像Kosmos-G這樣為進行主體驅動生成而在構建的替換任務上明確訓練的現有模型。
推理與知識增強生成
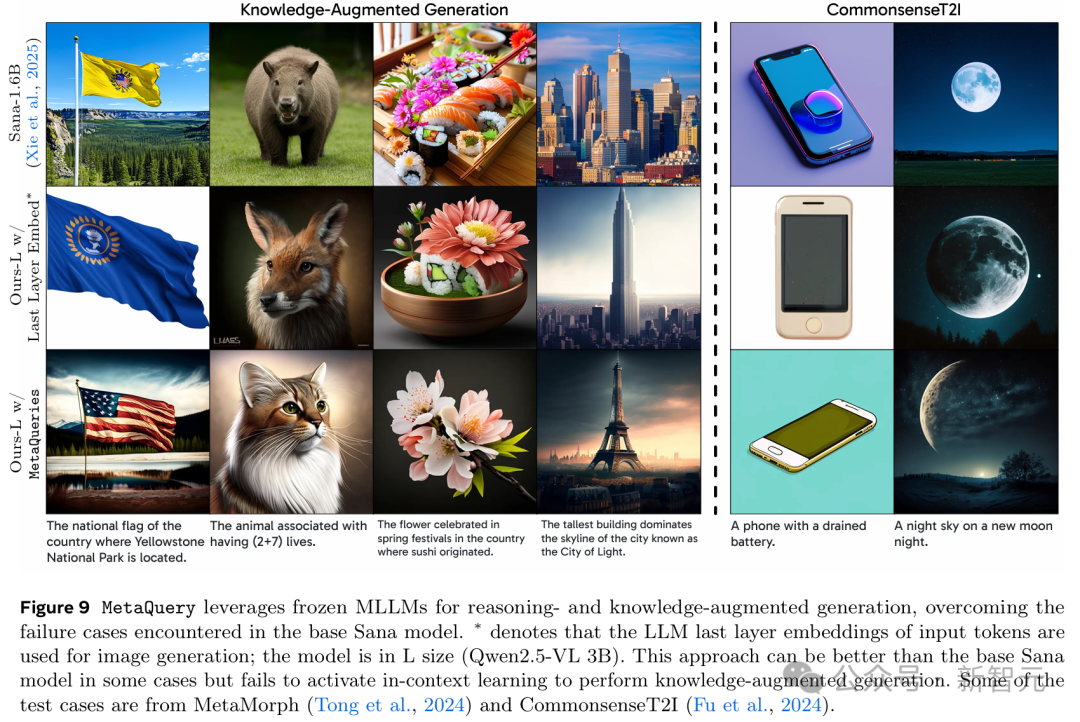
研究人員展示了可學習查詢可以有效利用凍結LLM的能力。這使得模型能夠更好地理解和遵循複雜提示詞,包括那些需要世界知識和推理的提示詞。
如圖9所示,對於左側的知識增強生成案例,MetaQuery-L可以利用來自凍結MLLM的世界知識並通過輸入問題進行推理以生成正確答案。
對於來自CommonsenseT2I的右側常識知識案例,LLM提供了更好的常識知識,並使MetaQuery能夠生成與事實一致的圖像。
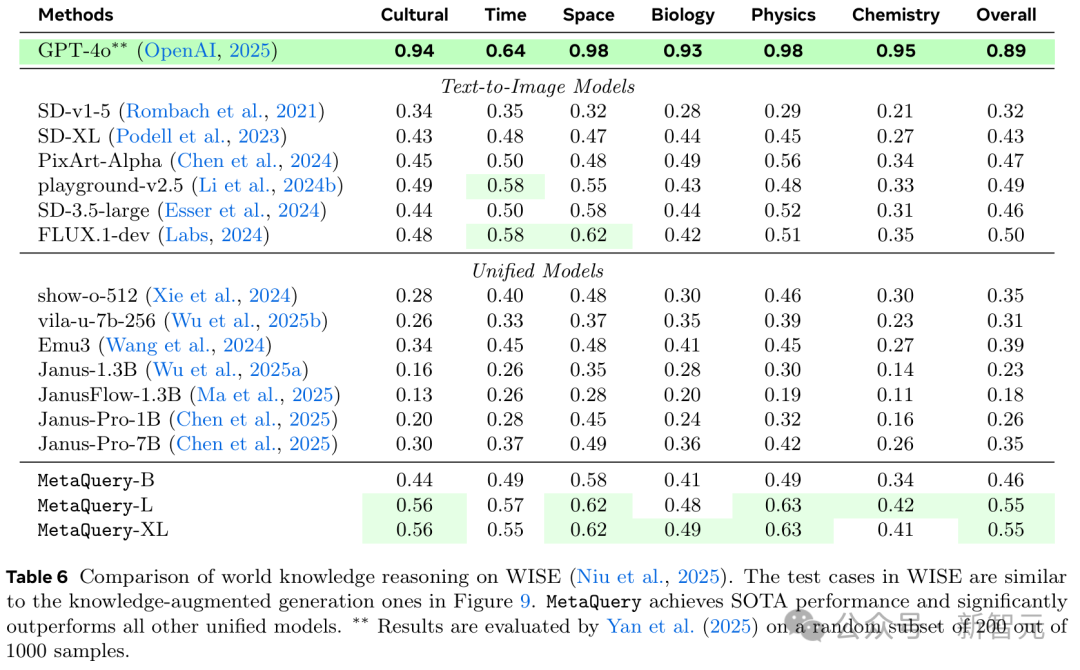
為了定量評估MetaQuery的世界知識推理能力,研究人員採用了WISE基準,該基準包含與圖9所示的知識增強生成示例類似的測試案例。
如表6所示,MetaQuery達到了SOTA性能,顯著優於所有其他統一模型。
值得注意的是,在這項工作之前,現有的統一模型難以有效利用強大的MLLM進行推理和知識增強生成,導致其性能劣於文本到圖像模型。
MetaQuery是第一個成功將凍結MLLM的先進能力遷移到圖像生成,並超越SOTA文本到圖像模型性能的統一模型。
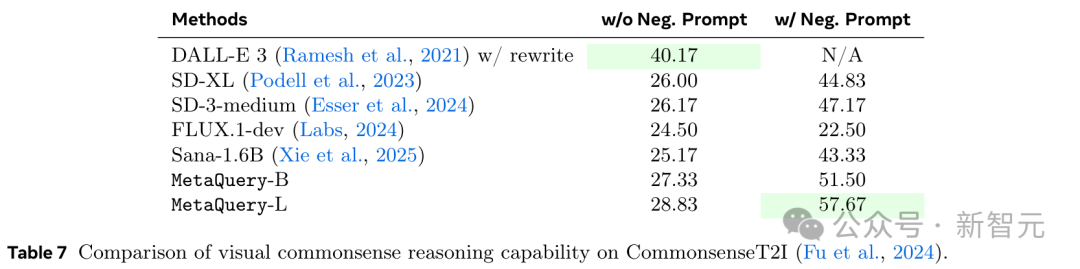
研究人員還在表7中對CommonsenseT2I基準上的MetaQuery的常識推理能力進行了定量評估。
為簡單起見,他們遵循其原始實現,使用CLIP作為評估器。結果顯示,MetaQuery顯著提高了基礎Sana模型的性能,達到了SOTA性能。
討論
如表8所示,研究人員測試了不同LLM骨幹對MetaQuery的影響,包括預訓練LLM(Qwen2.5-3B)、指令微調LLM(Qwen2.5-3B-Instruct)和指令微調MLLM(Qwen2.5-VL-3B-Instruct)。
實驗結果表明,指令微調可以實現更好的(多模態)理解能力。但當用於提供多模態生成條件時,這些改進與圖像生成性能是正交的。

最後一層嵌入方法本質上是將僅解碼器的LLM視為文本編碼器,這固有地限制了其上下文學習能力。
相比之下,MetaQuery與LLM原生集成,可以自然地利用上下文學習能力,使模型能夠通過問題進行推理並生成適當的圖像。
如表9所示,MetaQuery在WiScore和CommonsenseT2I基準上都顯著優於最後一層嵌入方法。

結論
MetaQueries,一個可以鏈接MLLM和DiT的簡單接口,即使在MLLM被凍結時依然有效。
這種方法非常簡單,但很好地實現了最先進的能力和SOTA級別的生成能力。
通過實現模態之間的轉換,MetaQueries成功地將MLLM的知識和推理能力引導至多模態圖像生成中。
這個方法很有效,但想要彌合與領先的專有系統之間賸餘的差距可能仍然需要進一步的數據擴展。
最終,MetaQueries能為未來的統一多模態模型開發提供一個強大、易於獲取的基線。
作者介紹
Xichen Pan

Xichen Pan是紐約大學庫朗特學院計算機科學系的二年級博士生,由謝賽寧教授指導。
曾在Meta GenAI Emu團隊,微軟亞洲研究院,阿里巴巴集團,以及地平線Horizon Robotics等實習。
在上海交通大學獲得了計算機科學學士學位,並獲得了最佳論文獎。
Ji Hou (侯驥)

侯驥是Meta GenAI的一名研究科學家,致力於基礎模型。
在此之前侯驥是Meta Reality Labs中的XR Tech的一名研究科學家,專注於3D場景理解。
在加入Meta之前,侯驥在TUM 視覺計算組攻讀博士學位,在那裡從事計算機視覺和3D場景理解的研究。在博士期間,曾經在FAIR實習。
侯驥對圖像/影片/3D生成模型的研究和應用感興趣,以及3D計算機視覺,例如3D重建、VR/AR、機器人和自動駕駛等。
Saining Xie(謝賽寧)

謝賽寧是紐約大學庫朗計算機科學系的助理教授,同時也是CILVR研究組的成員。此外,還隸屬於紐約大學數據科學中心。
曾是Facebook AI Research(FAIR)門洛帕加研究所的研究科學家。在加州大學聖地亞哥分校計算機科學與工程係獲得了博士和碩士學位,導師是Zhuowen Tu。
攻讀博士期間,曾在NEC實驗室、Adobe、Facebook、Google和DeepMind實習。在上海交通大學獲得了本科學位。主要研究方向是計算機視覺和機器學習。
參考資料:
https://xichenpan.com/metaquery/
https://arxiv.org/abs/2504.06256