微軟研究:AI 編程助手軟件調試能力堪憂
IT之家 4 月 13 日消息,OpenAI、Anthropic 和其他頂尖人工智能實驗室的人工智能模型越來越多地被用於協助編程任務,Google首席執行官桑達爾・皮查伊在去年 10 月透露,該公司 25% 的新代碼由 AI 生成;而 Meta 首席執行官馬克・朱克伯格也表達了在公司內部廣泛部署 AI 編碼模型的雄心壯誌。
然而,即便是一些目前最先進的 AI 模型,在解決軟件漏洞這一問題上,仍然無法與經驗豐富的開發者相媲美。微軟研究院(微軟的研發部門)的一項新研究表明,包括 Anthropic 的 Claude 3.7 Sonnet 和 OpenAI 的 o3-mini 在內的多款模型,在一個名為 SWE-bench Lite 的軟件開發基準測試中,無法成功調試許多問題。
研究的共同作者們測試了九種不同的模型,這些模型作為「基於單個提示詞的智能體」的核心,能夠使用包括 Python 調試器在內的一系列調試工具。他們給這個智能體分配了一組經過篩選的 300 項軟件調試任務,這些任務均來自 SWE-bench Lite。
據共同作者們介紹,即使配備了更強大、更先進的模型,他們的智能體成功完成的調試任務也極少超過一半。其中,Claude 3.7 Sonnet 的平均成功率最高,為 48.4%;其次是 OpenAI 的 o1,成功率為 30.2%;而 o3-mini 的成功率為 22.1%。
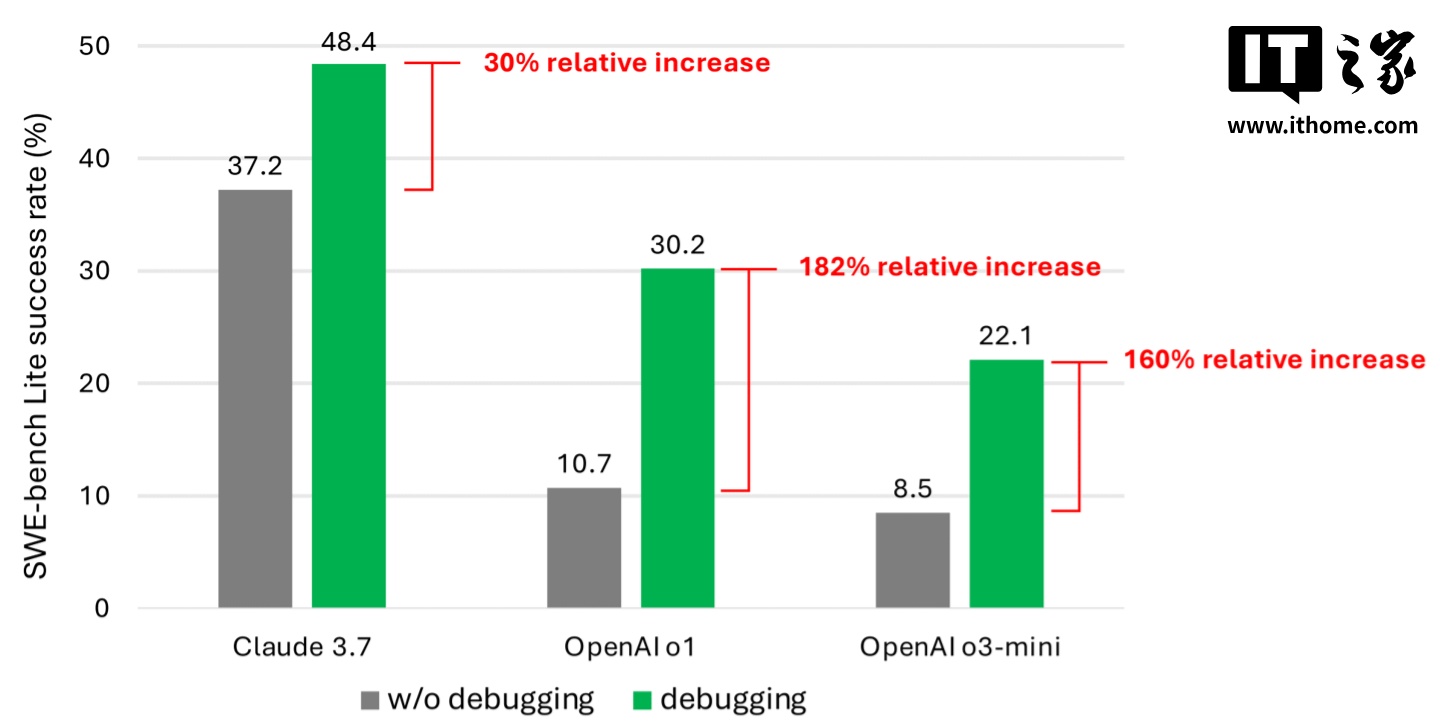
為何這些 AI 模型的表現如此不盡如人意?部分模型在使用可用的調試工具以及理解不同工具如何幫助解決不同問題方面存在困難。然而,共同作者們認為,更大的問題在於數據稀缺。他們推測,當前模型的訓練數據中,缺乏足夠多的「順序決策過程」數據,即人類調試痕跡的數據。
「我們堅信,訓練或微調這些模型可以使它們成為更好的交互式調試器。」共同作者們在研究報告中寫道,「然而,這需要專門的數據來滿足此類模型訓練的需求,例如記錄智能體與調試器交互以收集必要信息、隨後提出漏洞修復建議的軌跡數據。」
這一發現其實並不令人意外。許多研究都表明,代碼生成型 AI 往往會引入安全漏洞和錯誤,這是由於它們在理解編程邏輯等領域的薄弱環節所導致的。最近對一款流行的 AI 編程工具 Devin 的評估發現,它只能完成 20 項編程測試中的 3 項。
不過,微軟的這項研究是迄今為止對模型在這一持續存在問題領域最為詳細的剖析之一。儘管它可能不會削弱投資者對 AI 輔助編程工具的熱情,但願它能讓開發者及其上級領導三思而後行,不再輕易將編程工作完全交給 AI 來主導。
IT之家注意到,越來越多的科技界領袖對 AI 會取代編程工作的觀點提出了質疑。微軟聯合創始人比爾・蓋茨曾表示,他認為編程作為一種職業將會長期存在。與他持相同觀點的還有 Replit 首席執行官阿姆賈德・馬莎德、 Okta 首席執行官托德・麥金農以及 IBM 首席執行官阿爾溫德・基歷治納。
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。