強化學習帶來的改進只是「噪音」?最新研究預警:冷靜看待推理模型的進展
機器之心報導
編輯:蛋醬、+0
「推理」已成為語言模型的下一個主要前沿領域,近期學術界和工業界都取得了突飛猛進的進展。
在探索的過程中,一個核心的議題是:對於模型推理性能的提升來說,什麼有效?什麼無效?
DeepSeek – R1 論文曾提到:「我們發現將強化學習應用於這些蒸餾模型可以獲得顯著的進一步提升」。3 月 20 日,論文《Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t》再次驗證了 RL 對於蒸餾模型是有效的。
儘管這些論文的結論統統指向了強化學習帶來的顯著性能提升,但來自圖賓根大學和劍橋大學的研究者發現,強化學習導致的許多「改進」可能只是噪音。

-
論文標題:A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility
-
論文鏈接:https://arxiv.org/pdf/2504.07086
「受推理領域越來越多不一致的經驗說法的推動,我們對推理基準的現狀進行了嚴格的調查,特別關注了數學推理領域評估算法進展最廣泛使用的測試平台之一 HuggingFaceH4,2024;AI – MO。」
論文指出,在 AIME24 等小型基準測試中,結果極不穩定:僅僅改變一個隨機種子就足以使得分發生幾個百分點的變化。 當在更可控和標準化的設置下評估強化學習模型時,其收益會比最初報告的要小得多,而且通常不具有統計顯著性。
然而,一些使用強化學習訓練的模型確實表現出了適度的改進,但這些改進通常比監督微調所取得的成果更弱,而且它們通常不能很好地推廣到新的基準。

研究者係統分析了造成這種不穩定性的根本原因,包括采樣差異、解碼配置、評估框架和硬件異質性。我們表明,如果不仔細控制,這些因素會嚴重扭曲結論。與此同時,研究者提出了一套最佳實踐,旨在提高推理基準的可重覆性和嚴謹性。
AI 研究者 Sebastian Raschka 表示:「儘管強化學習在某些情況下可能有助於改進較小的蒸餾模型,但它的好處被誇大了,需要更好的評估標準來瞭解哪些方法真正有效。此外,這不僅僅是強化學習和推理模型的問題,我認為 LLM 研究整體上都受到了影響。」

探索推理的設計空間:什麼最重要?
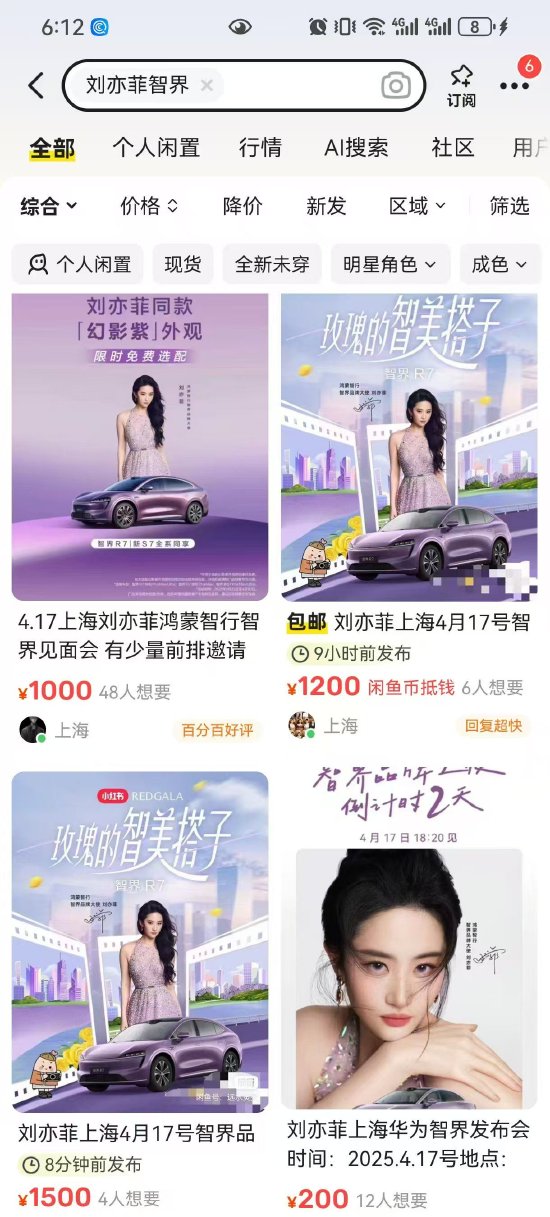
最近的以推理為重點的語言模型是在非常不同的條件下進行評估的,包括評估框架和硬件、隨機種子數量、溫度和核采樣參數(top_p)的差異(見表 1)。
雖然此前的研究已經考察了采樣參數在多選題和編碼任務中的影響,但這些選擇對開放式推理模型(特別是那些用強化學習訓練的模型)的影響仍未得到充分探索。
本文的研究者係統地評估了這些設計選擇如何影響性能,並強調了對結果可靠性影響最大的變異來源。
評估中的種子方差
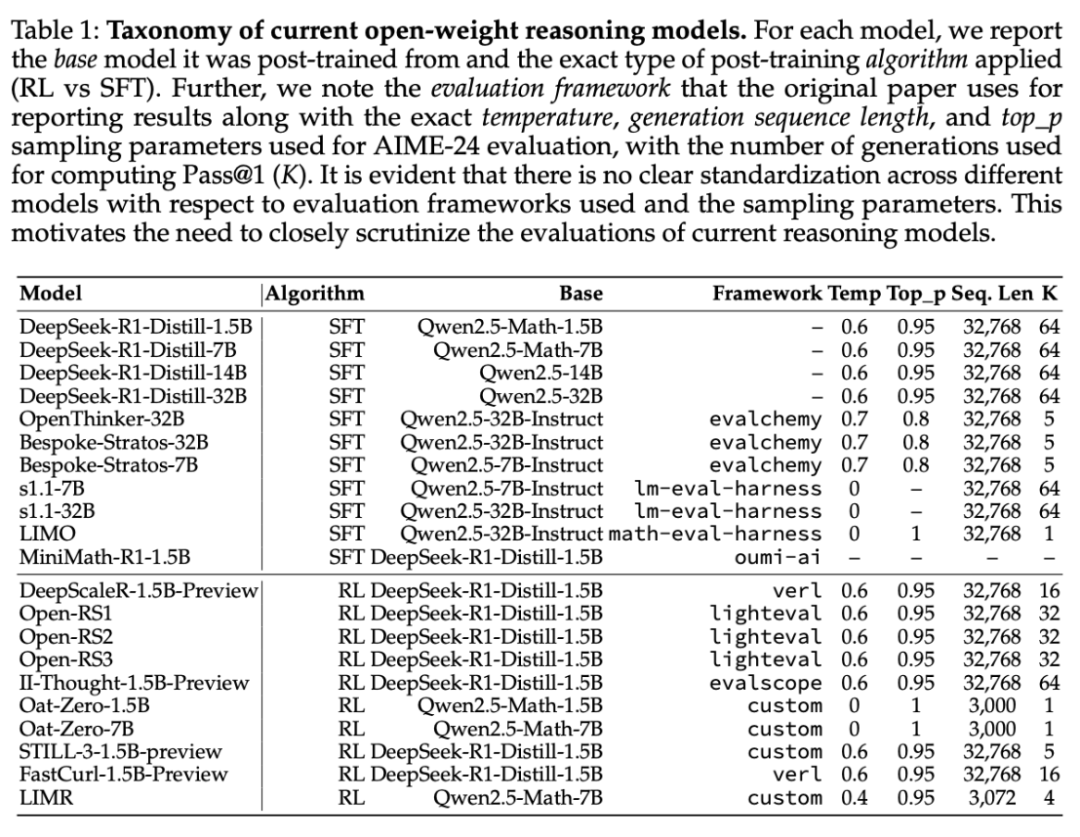
研究者首先分析了評估過程中使用的隨機種子所引起的方差,這是基準測試實踐中經常被忽視的一個方面。近期的工作儘管要求統計的嚴謹性(如使用誤差棒和多次運行),但評估經常依賴於單種子運行,從而掩蓋了潛在的變異性。本文評估了九種模型中,每種模型在 20 次獨立評估運行中種子引起的變異。結果如圖 2 所示。
可以看到,Pass@1 值的標準偏差出奇地高,各種子的標準偏差從 5 個百分點到 15 個百分點不等。這一問題在 AIME’24 和 AMC’23 中尤為嚴重,這兩個考試分別只有 30 和 40 個測試樣本。僅一個問題的變化就會使 Pass@1 偏移 2.5 – 3.3 個百分點。
硬件和軟件因素造成的差異
硬件和評估框架等非顯而易見的因素也會造成性能差異,但這一點很少得到承認。模型通常在異構系統上進行測試,並使用不同的工具鏈進行評估。
-
硬件差異
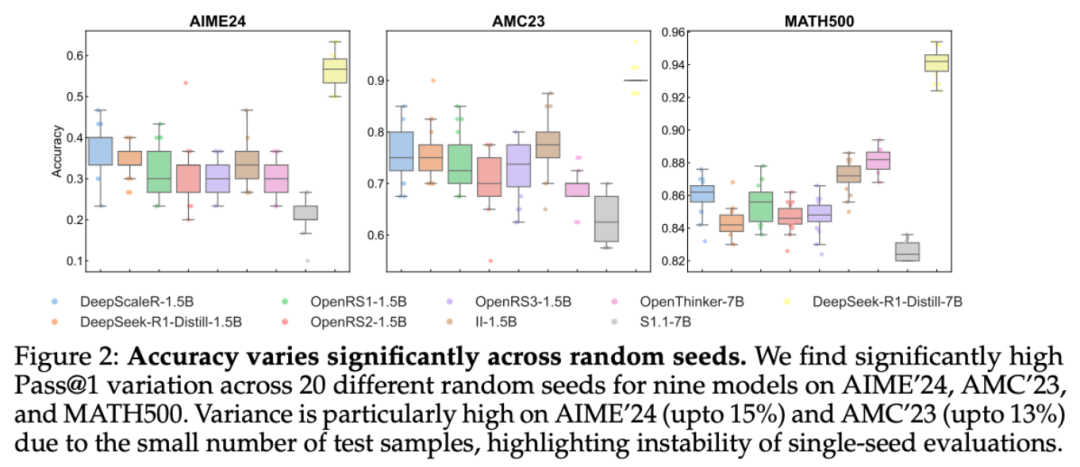
研究者在五個不同的計算集群上對同一模型進行了評估,每個集群的 GPU 類型和內存配置各不相同。
如圖 8 所示,在 AIME’24 上,OpenRS – 1.5B 的性能差異高達 8%,DeepSeek – R1 – Distill – 7B 的性能差異為 6%,在 AMC’23 上也觀察到了類似的趨勢。眾所周知,vLLM 等推理引擎對硬件差異非常敏感,而 PyTorch 或 CUDA 中的底層優化可能會引入非確定性,但結果表明,即使對多個種子進行平均,這些影響也會對基準精度產生顯著影響。
-
不同 Python 框架下的評估
為了評估這種影響,研究者對 lighteval 和 evalchemy 進行了比較,同時保持所有其他變量固定不變:模型、數據集、硬件、解碼參數和隨機種子(每個模型 3 個)。
為了進行公平比較,研究者在單個 GPU 上以預設溫度和 top_p 參數值對 DeepSeek – R1 – Distill – 1.5B 和 S1.1 – 7B 這兩個模型進行了評估。為了提高魯棒性,本文給出了三個種子的平均結果。
如表 2 所示,框架引起的差異通常很小(1 – 2pp),但在緊密聚類的情況下仍會影響模型排名。

Prompt 格式和上下文長度的影響
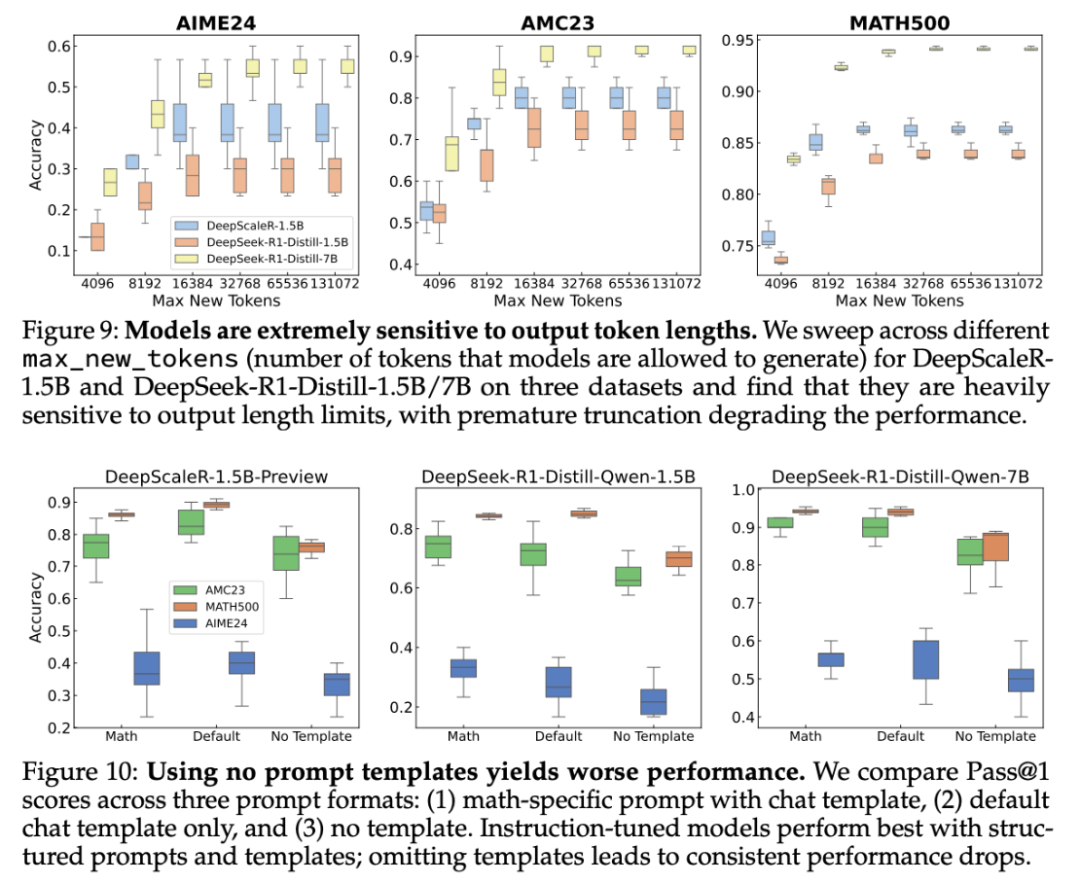
最大輸出 token。如圖 9 所示,減少 max_new_tokens 會降低性能,尤其是在長表單問題上。這種敏感度因模型和數據集而異。雖然減少這一設置可以降低成本,但可能會導致過早停止,從而導致錯誤答案。
Prompt 格式。提示格式對準確性有顯著影響。如圖 10 所示,模型在使用數學特定 Prompt 及其本地聊天模板時表現最佳。省略模板會導致性能下降,特別是對於經過指令調優的模型。
(一級)怎麼解決?答案是「評估的標準化」
在本節中,研究者將對評估框架進行標準化,並對現有方法進行全面評估。關鍵結論如下:
-
大多數通過強化學習(RL)訓練的 DeepSeek R1 – Distill 模型的變體未能顯著提高性能(DeepscaleR 除外),這表明仍缺乏可靠和可擴展的強化學習訓練方案。
-
儘管通過強化學習訓練的方法通常能顯著改善基礎模型的性能,但指令調優依然優於強化學習訓練的方法(Open Reasoner Zero 除外),這再次表明仍缺乏可靠和可擴展的強化學習訓練方案。
-
在較大模型的推理軌跡上進行監督微調可在基準測試中獲得顯著且可推廣的提升,且隨著時間推移進展得以成功複製——這突顯了其作為訓練範式的穩健性和成熟性。
-
當前基於強化學習的方法非常容易過擬合,強調了需要更嚴格的異域基準測試。相比之下,SFT(監督微調)模型表現出更強的泛化能力和韌性。
-
較長的響應與較高的錯誤概率相關聯,響應長度在 consensus@k 中是識別低置信度或失敗生成的一種實用啟髮式思路。
-
準解碼策略似乎足以捕捉模型在有效推理路徑上的完整分佈,反駁了多樣性坍縮假說。
清醒的觀察:結果
表 3 展示了實驗結果,並對結果的不同方面進行了分析。
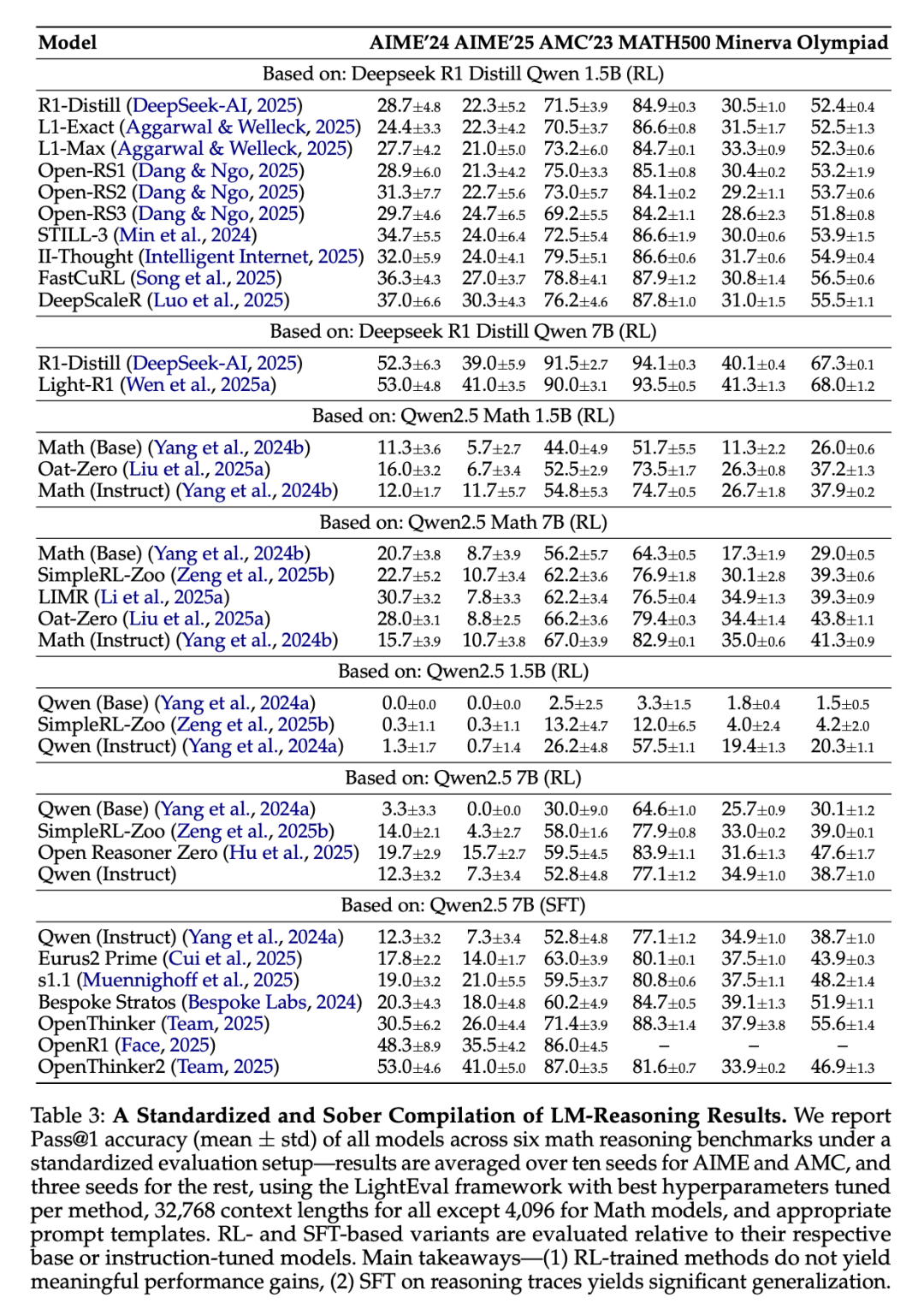
研究者在標準化評估環境中,對六個數學推理基準測試進行了模型評估,並針對這些模型的 Pass@1 準確率(均值 ± 標準差)進行了報告。在 AIME 和 AMC 基準測試中,結果採用了十個隨機種子的平均值,而其他基準測試則使用了三個隨機種子的平均值。研究者採用了 LightEval 框架,並為每種方法調試了最佳超參數。
需要指出的是,除了數學模型的上下文長度為 4096 之外,其他模型的上下文長度均設定為 32768,並使用了適宜的提示模板。同時,基於強化學習(RL)和監督微調(SFT)的模型變體分別針對各自的基礎模型或指令調優模型進行了評估。
主要結論如下:
-
通過強化學習訓練的方法未能顯著提升性能。
-
在推理路徑上,SFT 展現了顯著的泛化能力。
發現的現像是否可複現?詳細分析
研究者進一步調查了最近注意到的兩種現象,以驗證它們是否在實驗中得以複現:
-
響應長度與性能之間的關係。
-
以推理為重點的訓練後,響應的多樣性是否有所下降。
1、錯誤響應是否更長?
較長的響應是否意味著錯誤答案的可能性更高?他們比較了在六個數據集(AIME24、AIME25、AMC23、MATH500、Minerva 和 OlympiadBench)中正確和錯誤答案的響應長度分佈,並在每個模型的隨機種子上進行了平均。
圖 11 展示了按響應長度分組的每個種子的平均響應數量直方圖。
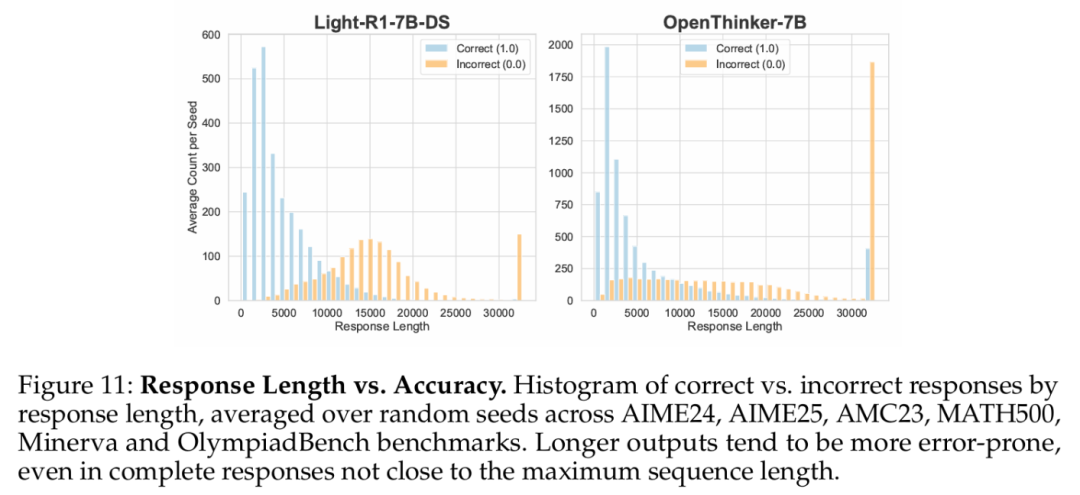
數據顯示了一個明顯趨勢:較短的響應更可能是正確的,而較長的響應則逐漸表現出更高的錯誤率。這一模式在所有種子中都保持一致,特別是在超過 10000 個 token 的響應中表現得最為顯著。研究者就此提出兩個關鍵問題:
Q1:這一模式是否同時適用於基於 RL 和 SFT 訓練的模型?
分析結果表明,這一趨勢在 RL 和 SFT 訓練的模型中均存在。具體而言:
-
RL 訓練模型(左側顯示)中這一效應更為顯著
-
SFT 訓練模型(右側顯示)中這一效應相對較弱
-
Qwen 2.5 Math 基礎模型也表現出輕微的長度相關性,但這種相關性在 R1 – distill 及後續的 RL 訓練模型中更為突出
Q2. 這種現像是否主要由截斷或不完整的響應導致?
儘管接近 32000 token 限制的響應幾乎總是錯誤的(由上下文長度限制所致),但即便是較短的完整響應,這一趨勢依然存在——較長的響應與較高的錯誤概率相關。
2、在推理訓練中是否存在多樣性坍縮?
為了驗證這些主張,研究者比較了 RL 訓練模型在所有數據集中的 Pass@k 性能(對於 k∈1, 5, 10)與其相應的基礎模型(如 DeepSeek – R1 – Distill – Qwen – 1.5B)。表 4 呈現了各方法的 Pass@k 相對於基礎模型的變化情況。
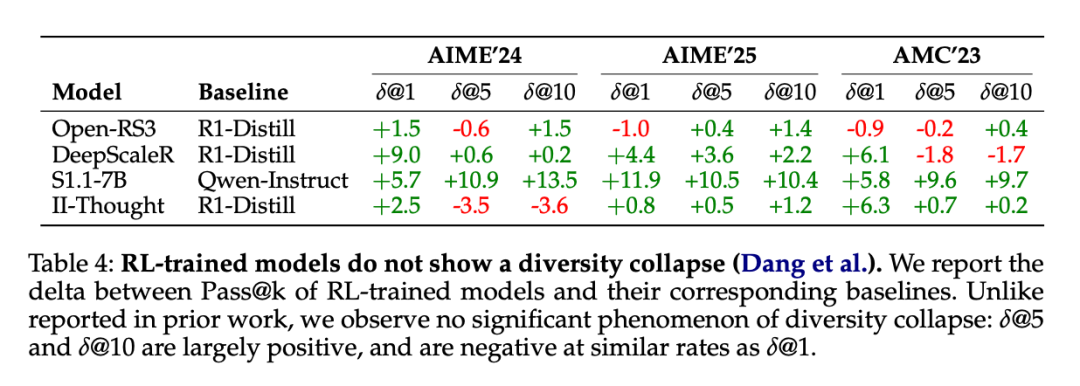
結果顯示,並未觀察到一致的多樣性坍縮現象。Pass@1 的提升通常伴隨著 Pass@k 的整體改善,儘管不同指標的提升幅度存在差異。在 Pass@k 性能下降的情況下,這種下降往往與 Pass@1 的偶發性下降同時出現,而非獨立發生,這一發現並不支持多樣性坍縮的假設。