3710億數學tokens,全面開放!史上最大高質量開源數學預訓練數據集MegaMath發佈

在大模型邁向推理時代的當下,數學推理能力已成為衡量語言模型智能上限的關鍵指標。
近日,LLM360 推出了 MegaMath:全球目前最大的開源數學推理預訓練數據集,共計 3710 億(371B)tokens,覆蓋網頁、代碼和高質量合成數據三大領域。

-
報告標題:MegaMath: Pushing the Limits of Open Math Corpora
-
技術報告:https://arxiv.org/abs/2504.02807
-
數據集地址:https://hf.co/datasets/LLM360/MegaMath
-
GitHub 代碼:https://github.com/LLM360/MegaMath
這不僅是首次在規模上超越 DeepSeek-Math Corpus(120B)的開源數據集,更代表從「只靠網頁」到「面向推理」的重大跨越。短短數日時間,數據集下載量已經來到 3 萬餘次,並且持續在 Hugging Face 趨勢榜上名列前茅。
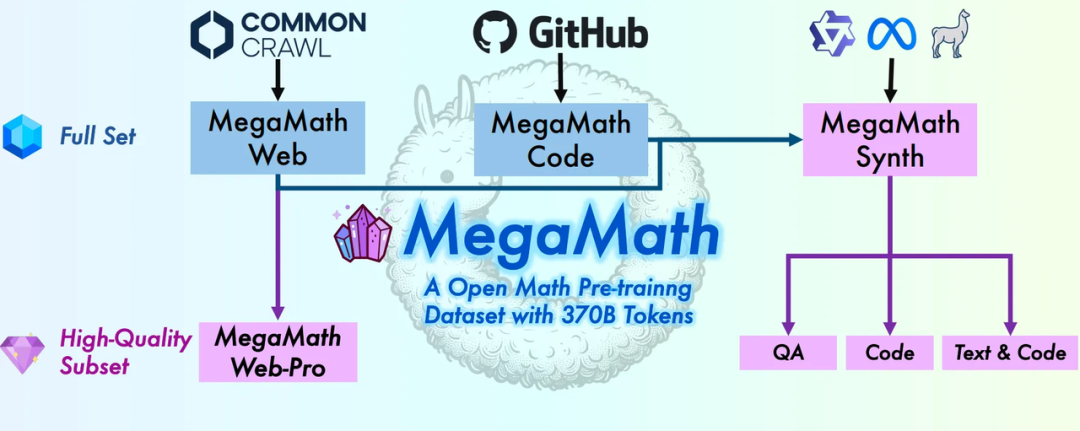 MegaMath數據集總覽
MegaMath數據集總覽為什麼我們需要 MegaMath?
在現有主流閉源數學語料如 Qwen-2.5-Math(1T)和 DeepSeekMath(120B)持續展現卓越數學能力的同時,開源研究社區長期缺乏等量級、等質量的數學數據。當前可用的開源數據集(如 OpenWebMath、FineMath)規模過小,無法支撐更大規模的模型訓練;過濾過度,導致數學樣本量缺失多樣性不足。
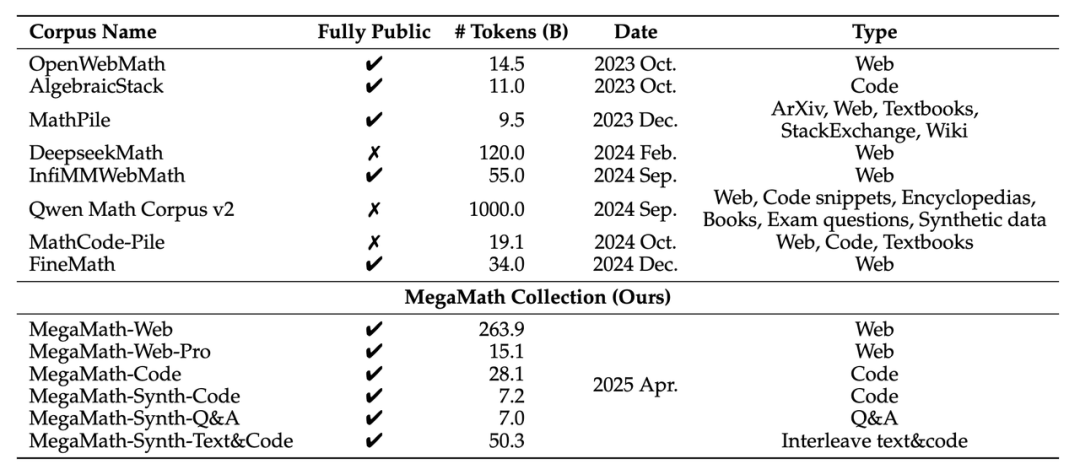 MegaMath和其他數據集的統計數據對比
MegaMath和其他數據集的統計數據對比為解決這一痛點,MegaMath 團隊本著「做困難而正確的事情」為目標,以規模 × 質量 × 多樣性為核心設計,曆時 9 個月時間,構建了全面開放的數學推理數據底座。
MegaMath 數據集共計 3710 億 tokens,是之前經典開源數學數據,如 OpenWebMath 的約 20 倍。數據集共分為三大部分:
-
2790 億 tokens:數學密集網頁數據(Math-rich Web)
-
281 億 tokens:數學相關代碼(Math Code)
-
640 億 tokens:高質量合成數據(Synthetic Data)
每部分數據均經過多輪篩選、清洗並通過下遊預訓練實驗充分驗證,以確保實用性與泛化能力並存。
構建 MegaMath 的秘方
如何構建這樣一個龐大的推理數據集呢?作者將他們主要分為 3 塊內容,並精心設計了不同的數據「流水線」,確保高效、高質量的數據開發。
高質量的網頁數據構建
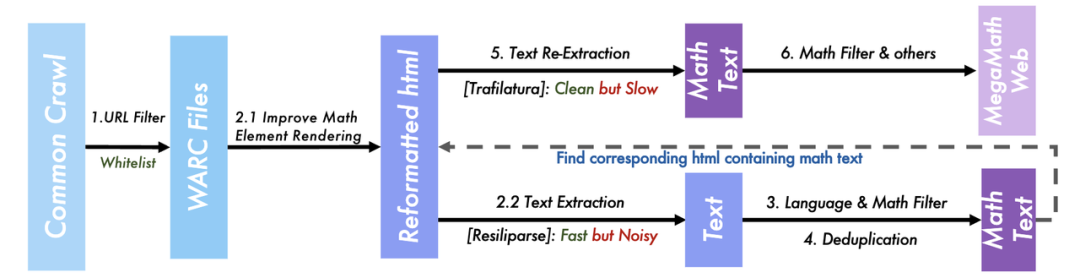 MegaMath的網頁數據處理流程
MegaMath的網頁數據處理流程為了徹底優化數學文本的處理流程,作者重新下載處理了 2014–2024 年間所有的 99 個 Common Crawl 文件包,並對互聯網的數學文本提取進行一系列大量的工程優化來確保數據質量:
-
當前常用的開源文本抽取工具對 HTML 中數學的元素並沒有很好地處理,團隊因此開發了一套 HTML 結構優化的腳本,在抽取前就提取和優化 LaTeX、KaTeX、mathml 等元素中的公式信息進行重構,以確保在抽取時充分保留文本中的數學符號、公式和定理。
-
由於不同抽取器的處理速度有區別,團隊創新地採用了兩段式提取方法,第一階段注重效率,用快速的抽取器進行抽取 + 篩除非數學樣本;第二階段注重精度,用包含更多規則的處理器進一步移除文本噪音和精細篩選出和數學強相關的數據。這使得 MegaMath 最終保留出數學強相關、且更乾淨的大規模數學文本數據。
-
對於如何訓練穩健而準確的文本分類器,團隊也發現了因為種子數據收集帶來的分佈偏移問題,因此在第一階段的粗篩之後通過重新收集種子數據訓練分類器來進行二階段篩選。
-
考慮到目前研究社區對於續訓練(Continual Pre-training)、中期訓練(Mid-Training)的廣泛需求,作者還利用語言模型對文本的教育價值進行動態打分,再次過濾得到包含極高教育價值的數學子集,並進一步用 LLM 進行精煉,得到了遠超開源任何數據集質量的子集;在和現存最高質量的數據 FineMath 進行一對一公平對比時,也能顯著超過 4% 的下遊性能。
這一系列的工程優化和技術迭代最終形成了:
-
MegaMath-Web:包含 263B tokens 的最大規模互聯網數學語料
-
MegaMath-Web-Pro:包含 15B tokens 的 LLM 優化後的超高質量數學語料
精確的數學代碼數據召回
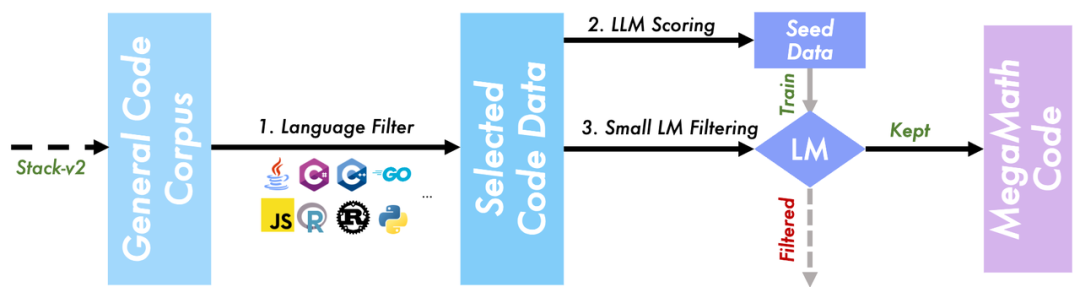 MegaMath-Code的多步召回流程
MegaMath-Code的多步召回流程代碼數據被廣泛驗證,有利於提升模型的數學表現、提升模型利用「生成代碼 + 執行求解」範式進行解題的能力。
因此,這是一份寶貴的數據領域。MegaMath 在現存最大的代碼預訓練數據集 Stack v2 中挖掘了數學相關代碼塊,同時結合團隊之前提出的 Programming Every Example(ProX)方法,利用(1)大模型評分(LLM scoring);(2)微調小模型快速篩選(SLM filtering)的方式,高效清洗出了包括科學計算、符號推理、邏輯程序等領域的代碼數據,形成 MegaMath-Code,一個包含 28.1B tokens 的數學相關語料,包含了共 11 種編程語言,進一步加強了數據集的豐富程度。
大規模數學數據合成
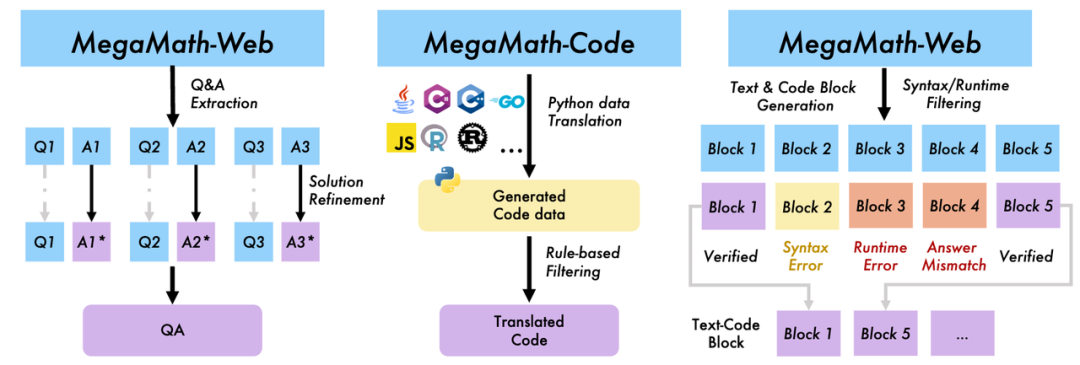 MegaMath-Synth的三種大規模合成方法
MegaMath-Synth的三種大規模合成方法近年來,合成數據已經成為大模型訓練不可缺失的一部分數據;尤其是當傳統的數據已經被大量發掘和利用的情況下,合成數據代表了一類可持續被開發的高質量數據源。這在之前的開源預訓練數據集中,通常是沒有被探索的。
MegaMath 團隊積極擁抱合成數據,並開源了預訓練規模的高質量文本,包含(1)Q&A 問答形式(解決數學題);(2)合成代碼(跨語言轉為 Python);(3)文本 + 代碼交錯數據(更貼近真實解題場景);所有樣本都經過質量檢測(包括代碼塊的可執行性校驗)。團隊通過不斷優化 Prompt、簡化工程設計,達到在消融實驗中表現全面優於現有合成的基線。
效果如何,表現說話
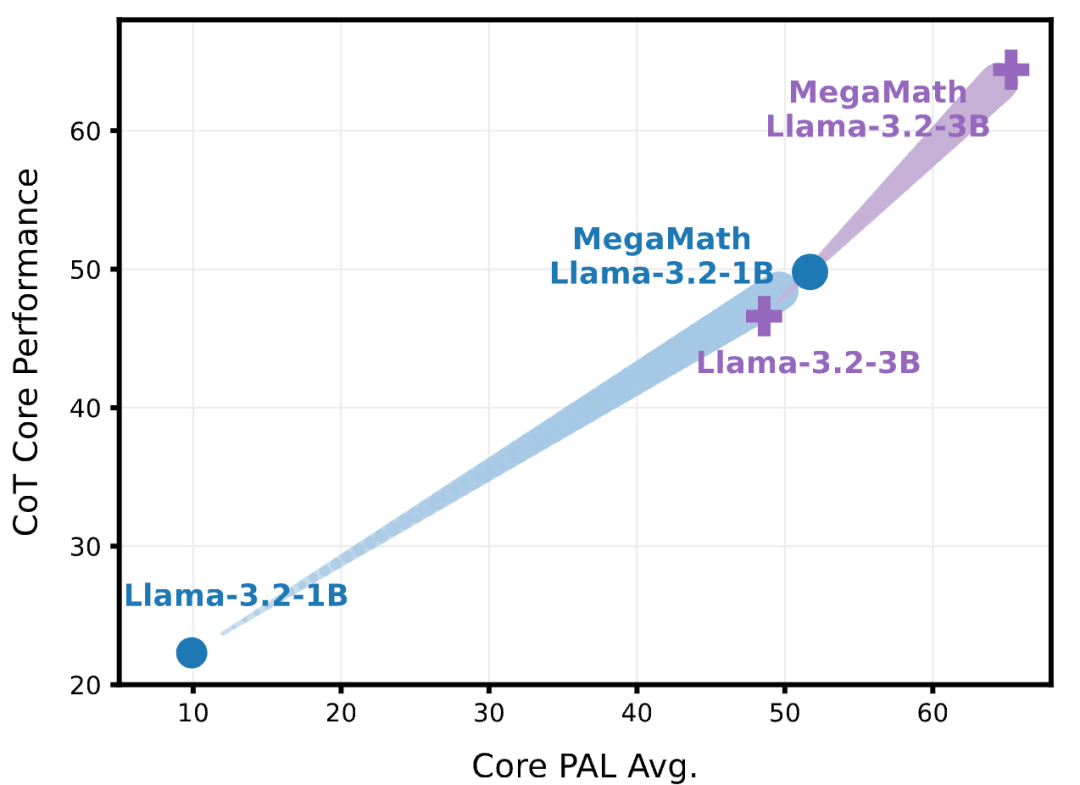
MegaMath-Llama-3.2 1B / 3B的表現在CoT和PAL測試上均提升顯著。
MegaMath 不是單純地「堆數據」拚大小,而是對每一步都進行了嚴謹驗證以確保數據質量。
這包括:(1)文本抽取流程驗證;(2)去重策略對比(在機器承受範圍內尋求最優的 MinHash 去重策略);(3)fastText 過濾閾值、訓練策略調優;(4)代碼數據比重 & SLM 召回率消融;(5)合成策略的迭代。
為了檢驗這些策略,所有的實驗都在足夠大的尺度下進行了預訓練 + 下遊評測的驗證實驗,用來為最終的方案和策略提供足夠顯著的實驗信號。
最終,MegaMath 共進行了超過 50 次的預訓練驗證,並最終在 Llama-3.2(1B & 3B)上進行了 100B 的預訓練。
實驗表明,MegaMath 能夠在 GSM8K、MATH 等數 10 個標準數學任務上取得 15–20% 的絕對提升。這些數字實打實地說明了 MegaMath 數據集在數學推理上的顯著效果。
作者的願景
作者希望,MegaMath 的發佈,能在一定程度上推動開源數學預訓練數據集在規模、質量與多樣性上的進一步發展,也希望 MegaMath 能成為構建更強數學語言模型的一個堅實起點,激發更多來自學術界與工業界的合作與創新。
在邁向更強推理能力與更高智能上限的過程中,MegaMath 只是初步階段的嘗試。作為一個致力於開放科學與開源研究的團隊,團隊深知這項工作的挑戰與局限,也非常感激開源社區給予的諸多啟發與幫助。
特別感謝 Hugging Face、DeepSeek、Qwen 等優秀開源團隊長期以來提供的模型、工具和數據方案,讓團隊有機會站在巨人的肩膀上持續打磨和完善這個工作。