擴散模型獎勵微調新突破:Nabla-GFlowNet讓多樣性與效率兼得

本文作者劉圳是香港中文大學(深圳)數據科學學院的助理教授,肖鎮中是德國馬克思普朗克-智能系統研究所和圖賓根大學的博士生,劉威楊是德國馬克思普朗克-智能系統研究所的研究員,Yoshua Bengio 是蒙特利爾大學和加拿大 Mila 研究所的教授,張鼎懷是微軟研究院的研究員。此論文已收錄於 ICLR 2025。
在視覺生成領域,擴散模型(Diffusion Models)已經成為生成高質量圖像、影片甚至文本的利器。然而,生成結果往往離我們所偏好的不一致:結果不美觀,圖文不符,等等。
雖然我們可以像大語言模型中的 RLHF(基於人類反饋的強化學習)一樣直接用傳統強化學習來微調擴散模型,但收斂速度往往慢;而基於可微計算圖直接最大化獎勵函數的方法又往往陷入過擬合和多樣性缺失的問題。
有沒有一種方法,既能保留生成樣本的多樣性,又能快速完成微調?我們基於生成流網絡(Generative Flow Network,GFlowNet)提出的 Nabla-GFlowNet 實現了這一速度和質量間的平衡。

-
論文標題:Efficient Diversity-Preserving Diffusion Alignment via Gradient-Informed GFlowNets
-
論文地址:https://arxiv.org/abs/2412.07775
-
代碼地址:https://github.com/lzzcd001/nabla-gfn

利用 Nabla-GFlowNet 在 Aesthetic Score 獎勵函數(一個美學指標)上高效微調 Stable Diffusion 模型。
擴散過程的流平衡視角
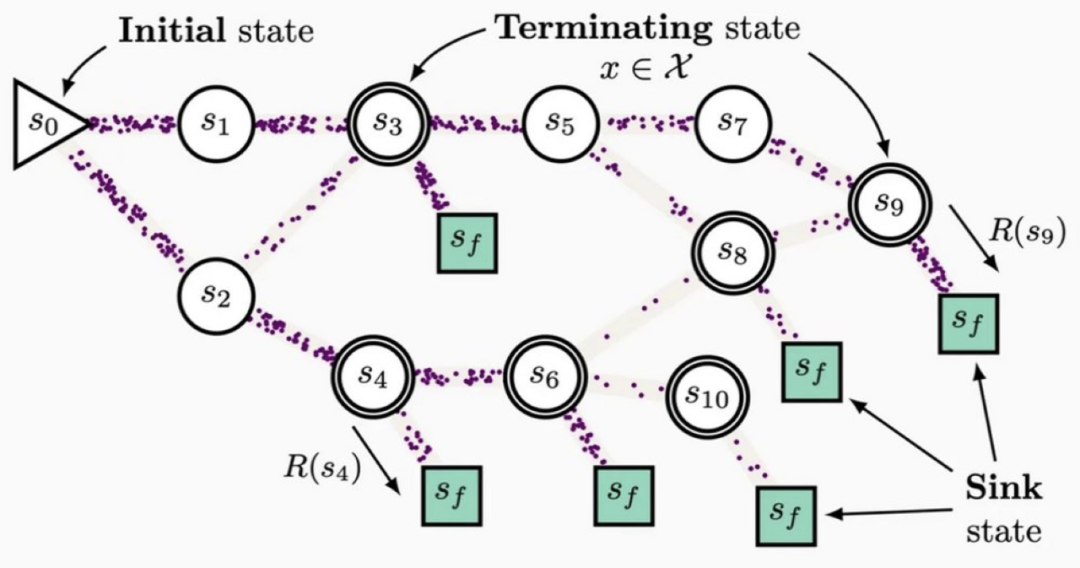
生成流網絡 GFlowNet 示意圖。初始節點中的「流」通過向下遊的轉移概率流經不同節點,最後彙聚到終端節點。每個終端節點所對應的流應匹配該終端節點對應的獎勵。
在生成流網絡(Generative Flow Network, GFlowNet)的框架下,擴散模型的生成過程可以視為一個「水流從源頭流向終點」的動態系統:
-
從標準高斯分佈采樣的噪聲圖像作為初始狀態,其「流量」為

;
-
去噪過程

如同分配水流的管道網絡,把每一個
節點的水流分配給下遊每一個
節點;
-
而加噪過程
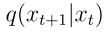
則可以回溯每一個的水流來自哪裡;
-
最終生成的圖像
將累積總流量
 擴散模型示意圖
擴散模型示意圖流梯度平衡條件
在 GFlowNet 框架下,前後向水流需要滿足一定的平衡條件。我們通過推導提出我們稱為 Nabla-DB 的平衡條件:
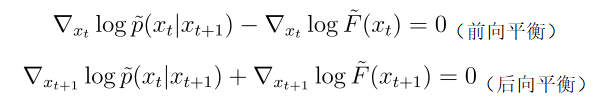
其中
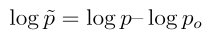
是這個殘差過程對應的對數流函數。
分別是微調模型和預訓練模型的去噪過程。
和
是殘差去噪過程,
這個殘差去噪過程應該滿足
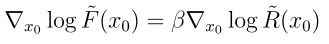
,其中 β 控制微調模型在獎勵函數和預訓練模型之間的平衡。如果 β 為零,那麼殘差過程為零,也就是微調網絡等於預訓練網絡。
稍作變換,就可以得到我們提出的 Nabla-GFlowNet 對應的損失函數 Residual Nabla-DB(其中 sg 為 stop-gradient 操作):
前向匹配損失:
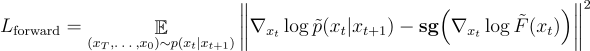
後向匹配損失:
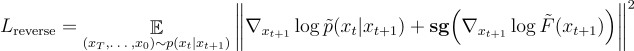
終端匹配損失:
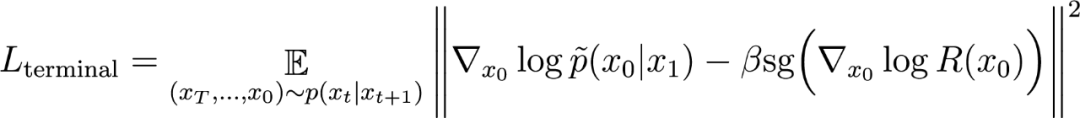
對數流梯度參數化設計
上述損失函數需要用一個額外的網絡估計 做單步預測得到不準確的去噪結果
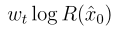
是一個權重常數。因此,我們提出如下參數化:
是一個很好的估計,其中
,那麼
,但我們觀察到:如果我們對
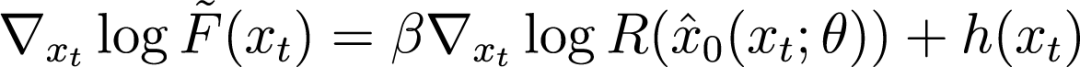
其中
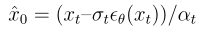
是擴散模型ε-預測參數化的網絡)。
是用 U-Net 參數化的殘差梯度,而單步去噪估計為
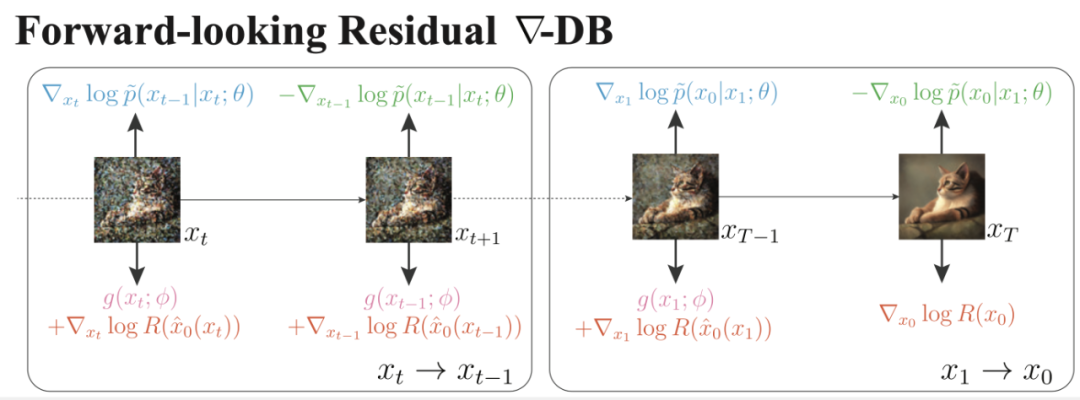 方法示意圖。每條采樣路徑的每個轉移對
方法示意圖。每條采樣路徑的每個轉移對中每張圖的上下兩個「力」需要相互平衡。
直觀解釋
如果我們只計算
這一轉移對的前向匹配損失對擴散模型參數的梯度,我們有:
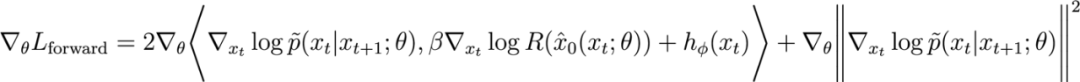
其中第一項是基於內積的匹配度函數(殘差擴散模型與獎勵梯度估計之間的匹配),第二項是讓微調模型趨近於預訓練模型的正則化。
偽代碼實現

實驗結果
我們分別用以下獎勵函數微調 Stable Diffusion 網絡:
-
Aesthetic Score,一個在 Laion Aesthetic 數據集上訓練的美學評估獎勵函數;
-
HPSv2 和 ImageReward,衡量指令跟隨能力的獎勵函數。
定性實驗結果表明,通過 Nabla-GFlowNet 微調,我們可以快速得到獎勵更高但避免過擬合的生成圖像。
ReFL 和 DRaFT 等直接獎勵優化的方法雖然收斂速度快,但很快會陷入過擬合;而 DDPO 這一基於傳統策略梯度的強化學習微調方法由於沒有理由梯度信息,微調速度顯著劣於其他方法。
同時,我們的定量實驗表明,我們的 Nabla-GFlowNet 可以更好保持生成樣本的多樣性。

Aesthetic Score 獎勵函數上的微調結果(微調 200 步,取圖片質量不坍塌的最好模型)。Nabla-GFlowNet(對應 Residual Nabla-DB 損失函數)方法微調的網絡可以生成平均獎勵更高且不失自然的生成圖片。
 相較於 ReFL,DRaFT 等直接獎勵優化的方法,Nabla-GFlowNet 更難陷入過擬合。
相較於 ReFL,DRaFT 等直接獎勵優化的方法,Nabla-GFlowNet 更難陷入過擬合。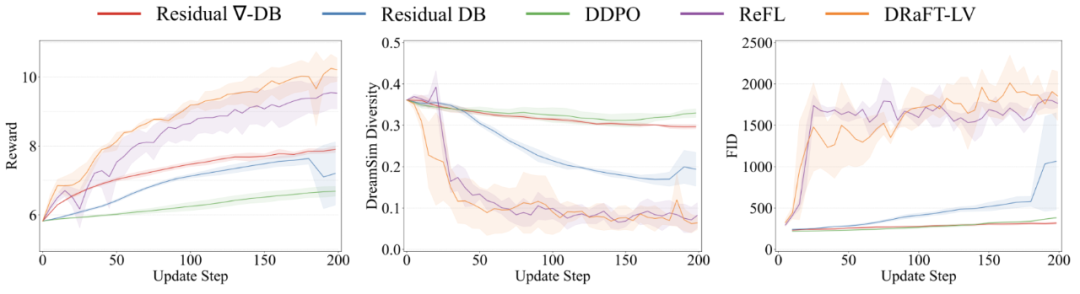
Aesthetic Score 獎勵函數上的定量結果 Nabla-GFlowNet 在獎勵收斂快的同時,保持更高的 DreamSim 多樣性指標(越高代表多樣性越好)和更低的 FID 分數(越低代表越符合預訓練模型的先驗)。
 HPSv2 獎勵函數上的微調結果
HPSv2 獎勵函數上的微調結果 ImageReward 獎勵函數上的微調結果
ImageReward 獎勵函數上的微調結果結語
我們利用生成流網絡(GFlowNet)的框架,嚴謹地得到一個可以更好保持多樣性和先驗的高效的擴散模型獎勵微調方法,並且在 Stable Diffusion 這一常用的文生圖擴散模型上顯示出相較於其他方法的優勢。