只因論文「碰瓷」,ICLR 2025區域主席直接拒稿!最強rebuttal,贏回榮耀

新智元報導
編輯:KingHZ
【新智元導讀】1%合成數據,就能讓AI模型瞬間崩潰!如此顛覆性發現,只因未引用他人論文,ICLR區域主席直接拒稿,好在作者成功rebuttal,論文最終選為Spotlight。而背後,竟是一樁圖靈獎得主Yann Lecun關注的學界爭議!
ICLR 2025,公開審稿,多級反轉!
只因沒有引用COLM 2024會議的一篇論文,區域主席根據公開評論,竟建議拒絕投稿論文!
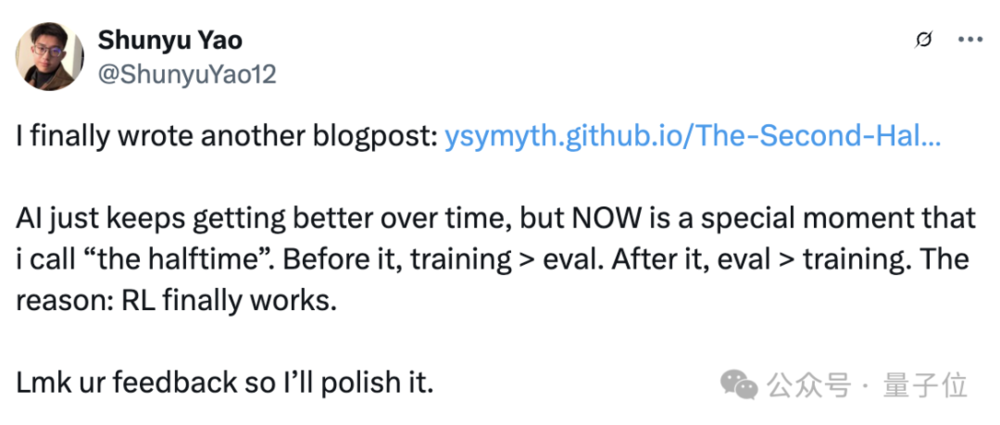
雖然最終論文《強模型崩潰》(Strong Model Collapse)被接受,並選為亮點論文(Spotlight),但過程可謂危險至極!

來自Meta等研究機構證實:1%合成數據,就能讓模型瞬間崩潰。
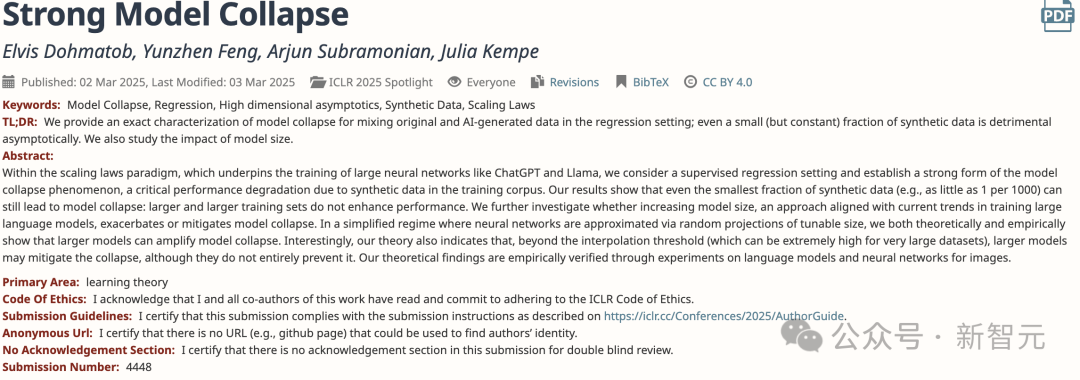
作者將文章投稿ICLR 2025後,審稿人對這篇論文的評價一致為正面。
區域主席(Area Chair),基於公開評論建議拒絕該論文,只因缺少對COLM 2024論文的引用。
即便在OpenReview上的私下討論(公眾無法查看)中,審稿人最終決定,缺少這篇引用不能成為拒絕的唯一依據。
但區域主席推翻了審稿人的意見,建議拒絕了此論文。
收到投訴後,ICLR決定審查此案。
調查後,一致決定支持審稿人的意見,因此最終接受了這篇論文。
任何平均得分高於閾值的論文,將自動考慮作為亮點論文。
 評審意見主頁:https://openreview.net/forum?id=et5l9qPUhm
評審意見主頁:https://openreview.net/forum?id=et5l9qPUhm公開評審:李鬼倒打李逵?
對ICLR論文提出疑問的史丹福大學CS博士生Rylan Schaeffer,他是COLM 2024下列論文的作者。

他強調,ICLR 2025的論文《強模型崩潰》作者,故意不引用COLM 2024論文:
1.他們明確知曉有一篇先前的已發佈工作,直接與他們的敘述和科學主張相矛盾;
2.他們使用了該先前工作中提出的方法論,而同時又侮辱了該工作並未給予應有的致謝。
他堅持認為ICLR 2025投稿論文是故意壓制矛盾證據,混淆對模型崩潰(潛在)危害的理解。
ICLR的作者就是赤裸裸的學術不端,是科學界的恥辱!
特別是對於ICLR沒有引用他寫作的COLM 2024論文,他認為這無法忍受。
我們懇請評審專家和區域主席要求《強模型崩潰》的作者解決以下問題:
1.此項工作與現有關於避免模型崩潰文獻的關係,
2.如何解釋看似矛盾的結論產生的不同建模假設,以及哪種假設最能反映現實場景。
評估哪些假設最符合現實場景對於評估這項工作的實際影響至關重要。
在去年,Rylan Schaeffer就表示,如果對模型崩潰(model collapse)有興趣,強烈要求閱讀他們的COLM 2024論文。

反駁:Rylan Schaeffer才是抄襲者
在得到會議程序委員會及曆任主席一致認同後,ICLR論文一作Elvis Dohmatob,在X上公開回應了Rylan Schaeffer的指責,認為Rylan Schaeffer存在嚴重的不當行為:
抄襲我們的先前工作,
論文內容主要由人工智能生成(是的,作者將我們的論文輸入到LLM中生成了另一篇論文),
違反倫理審查委員會(IRB)規定等。
在長時間的雙方溝通中,這些問題逐步被揭露出來。
在帖子後,ICLR 2025官方帳號,澄清了提交論文4488評審的過程,真如開頭所言。

NYU教授還原全過程
去年,《強模型崩潰》的作者Julia Kempe和「李鬼」Rylan Schaeffer多次溝通,公開了論文其他作者的道歉郵件。
特別是,模型崩潰、混合原始數據與合成數據等領域已有很多優秀論文的情況下(包括在《自然》雜誌上發表的文章),當Gerstgrasser等人首次向發送他們《模型崩潰是不可避免的嗎?》的v1版本時,很少有對一發表論文的相關討論。
甚至有Rylan Schaeffer的合著者表示論文粗製濫造, 就是趕鴨子上架:
他們史丹福的導師跟他們來往並不密切。
學生趕在截止日期前,馬上提交論文。我們對論文粗製濫造的關切,幾乎被漠視了。
可悲的是,這已經成為他們的文化的一部分。
至於沒有引用相關論文的原因,我直到現在仍然不明白。

更加驚訝的是,「李鬼」Rylan Schaeffer所謂的「模型坍塌必讀理論」,是Julia Kempe之前定理的一個微不足道的推論,而且Rylan Schaeffer的論文還具有誤導性。
但奇怪的是,這些公式化的表述與論文中的語言相似,符號也古怪地相似:
 左:「李逵」的論文符號,右:「李鬼」的論文符號
左:「李逵」的論文符號,右:「李鬼」的論文符號然而,隨後Julia Kempe等明白了!
在指出了最明顯的遺漏後,「李鬼」論文的作者等人發送了一份報告,暗示Julia Kempe等人的反饋,被AI用來合成論文。

Julia Kempe等人被當作免費勞動力使用,這令Julia Kempe大開眼界!
但可悲的是,Rylan Schaeffer等人的論文雖被COLM 2024接受,但仍然包含誤導性結論。
在涉及到個人學術聲譽的鬥爭中,Julia Kempe也得到了同事的支持,甚至得到了圖靈獎得主、AI大佬Yann Lecun的關注和支持!
模型崩潰與合成數據
雙方的焦點在於「模型崩潰」。
第1點:關於Gerstgrasser等人的論文與先前工作的科學矛盾。
Gerstgrasser等人的論文,並沒有以任何有意義的方式避免模型崩潰。
正方Julia Kempe等人,在ICLR 2025論文中,明確將「模型崩潰」定義為「AI模型性能的重大下降」。
避免模型崩潰意味著:縮小使用真實數據和合成數據訓練時的性能差距。
反方Rylan Schaeffer、Gerstgrasser等人,將避免模型崩潰定義為:「在多次訓練模型時,防止發生遞歸性退化」。
該論文承認,儘管當樣本逐漸積累時,性能退化是有界的,但仍然存在性能損失。
這一定義僅代表了縮小真實數據和合成數據之間差距的部分條件。從這個意義上講,Gerstgrasser等人並未解決或緩解模型崩潰問題。
在關於模型崩潰的大多數文獻中,主流觀點認為,縮小性能差距是避免模型崩潰的主要標準。
從實際角度來看,縮小真實數據與合成數據之間的差距,是避免模型崩潰的更具操作性和相關性的定義。
僅僅確保性能不出現發散,仍然可能導致模型無法匹配合成數據生成器的質量,從而使合成數據對性能造成損害。
只有當性能差距完全縮小時,合成數據的負面影響才能完全減輕。
由於定義和理由上的差異,考慮到縮小性能差距是正確的定義,通過這一廣泛接受的視角,正方Julia Kempe等人已經重新審視了所有關於模型崩潰的相關工作。
第二點:與Gerstgrasser等人的先前互動
不幸的是,公開評論似乎破壞了審稿過程的匿名性。
正反雙方的確有過互動。
以下是該互動的簡要總結:
技術上不足:Gerstgrasser等人的論文只是增量性的技術貢獻,而且非常薄弱。它不過是對已有論文的已有設定和論點的輕微修改。其結果是已有定理的簡單推論。
誤導性/不準確的結論:Gerstgrasser等人的論文並未以任何合理的方式解決模型崩潰問題(請參見上文關於定義的討論)。
不幸的是,Gerstgrasser等人,基本上忽視了互動的建設性批評,甚至將評論僅作為腳註,附在論文的末尾。
因此,在目前的狀態下,正方仍然認為Gerstgrasser等人的論文,在科學上並不成立,因此沒有覺得有必要引用。
最終的論文結果,說明榮耀應該歸於Julia kempe等人。
這也與此前領域內專家的意見一致。
 參考資料:
參考資料:https://x.com/dohmatobelvis/status/1911107171078615088
https://x.com/KempeLab/status/1817135401124934089
https://x.com/RylanSchaeffer/status/1911153029509992859